ElasticSearch学习 ④ IK分词器(elasticsearch插件)+自定义字典
Posted H&&Q
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ElasticSearch学习 ④ IK分词器(elasticsearch插件)+自定义字典相关的知识,希望对你有一定的参考价值。
ES默认的分词器把中文每个字看作一个词,比如说:“我爱喝水”会被划分为“我”,“爱”,“喝”,“水”。显然不是很符合要求,所以我们需要安装中文分词器ik来解决这个问题。
ik分词器提供了两个分词算法:ik_smart和ik_max_word ,其中ik_smart为最少切分, ik_max_word为最细粒度划分
1.下载(版本要与ElasticSearch版本对应)
https://github.com/medcl/elasticsearch-analysis-ik/releases
2.安装(解压,重启es即可)
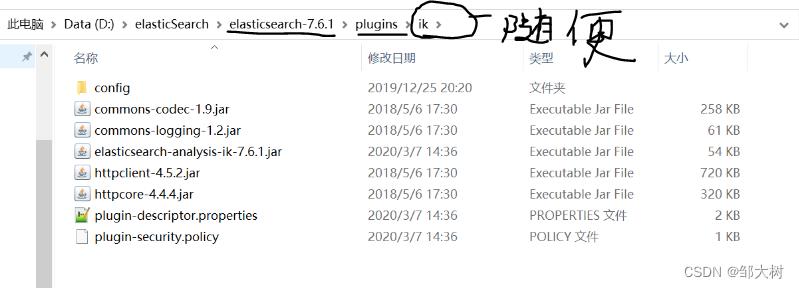
3.使用kibana进行测试
ik_smart:最少切分: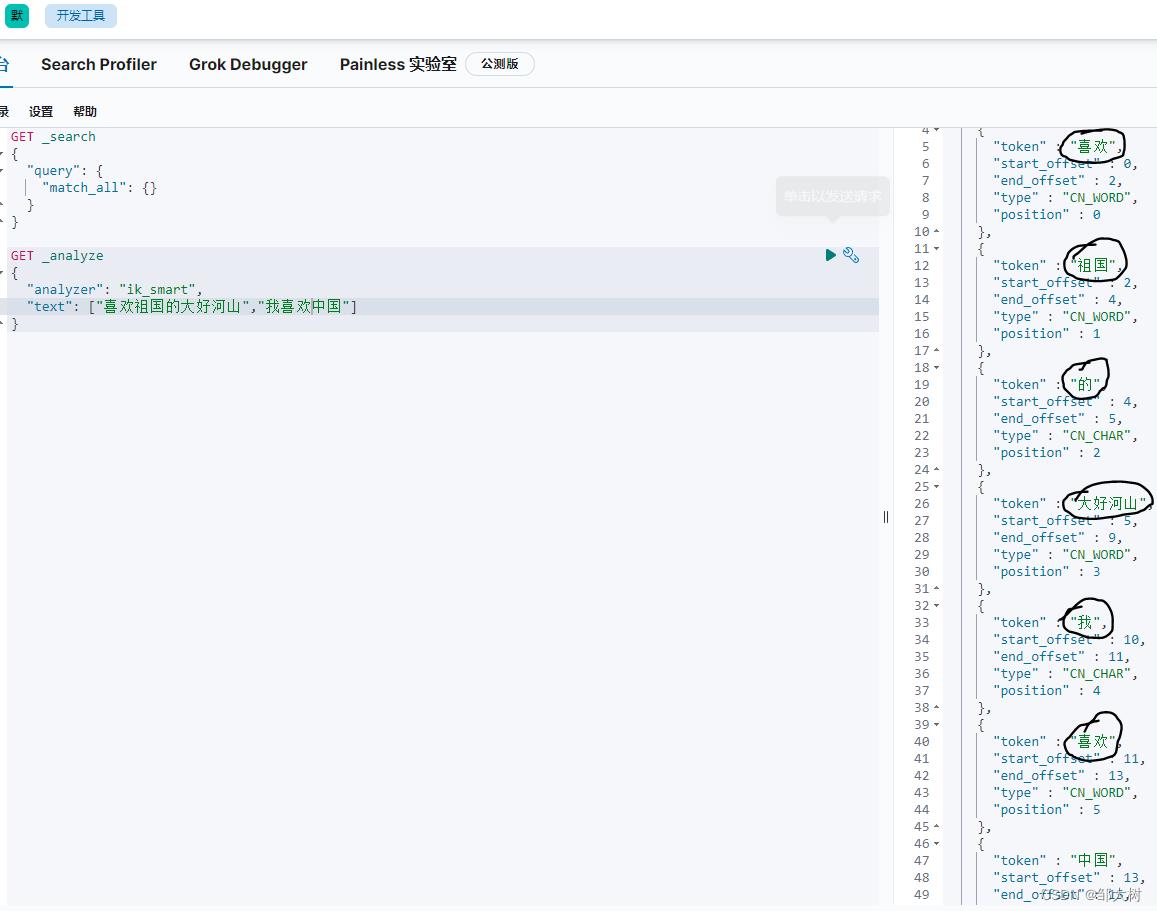
ik_max_word:最细粒度划分(穷尽词库的可能)
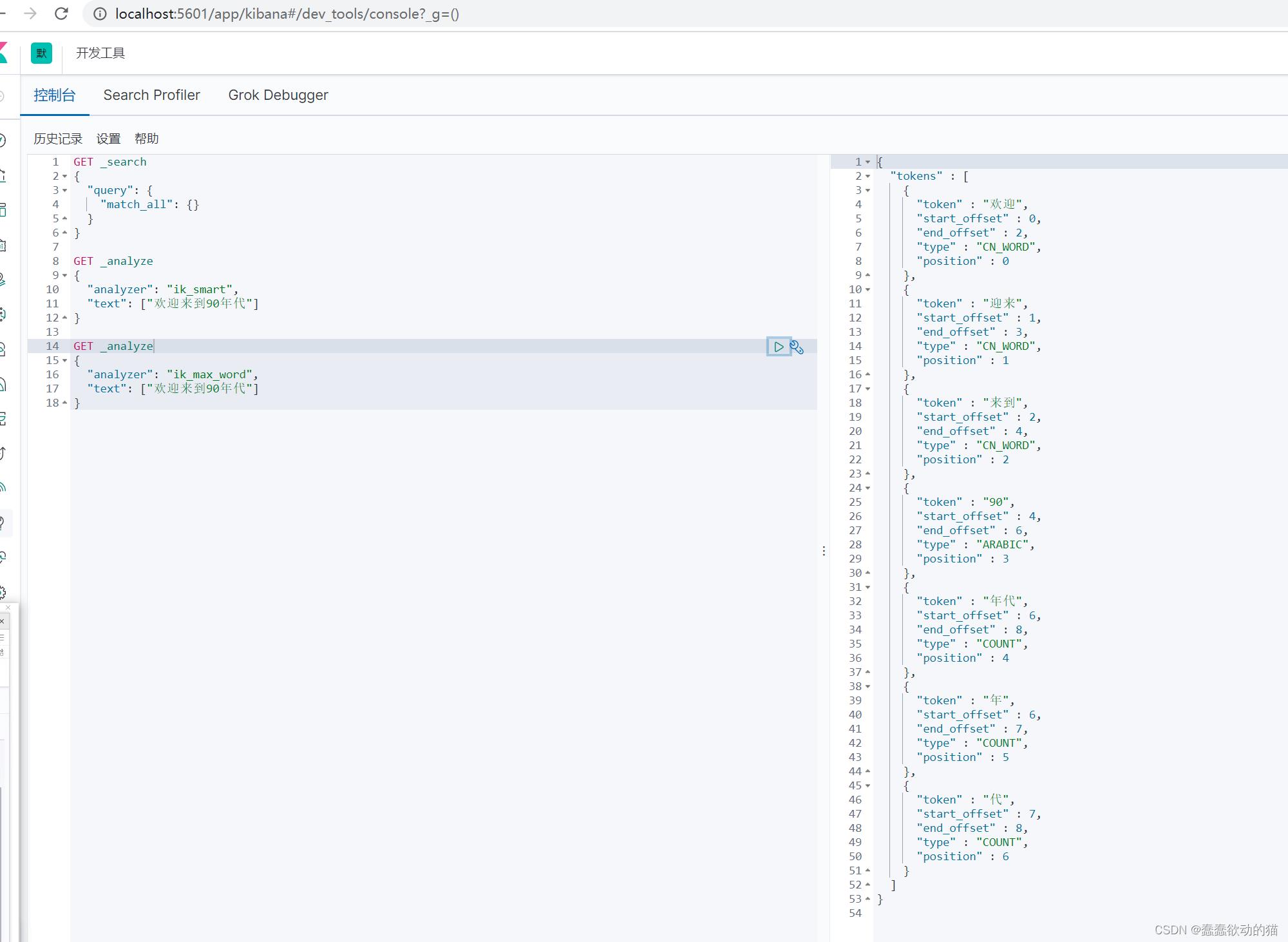
从上面看,感觉分词都比较正常,但是大多数,分词都满足不了我们的想法,如下例:(金毛狮王是一个完整的词,不想让他乱分)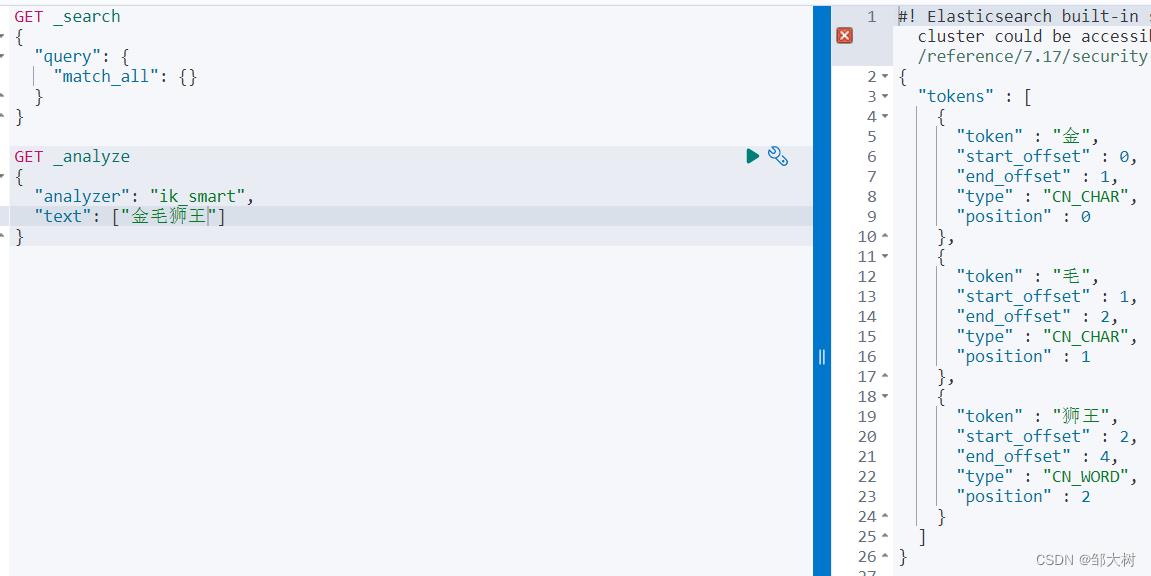
根据默认拆分的结果,发现我们需要增加“金毛”和“金毛狮王”2个词条并删除“金”和“毛”2个词条。这里就可以用自定义字典来实现
打开 ..\\elasticsearch-7.12.1\\plugins\\ik\\config\\IKAnalyzer.cfg.xml
可以看到有2个配置 ext_dict 和 ext_stopwords。分别是扩展和停用字典

参照默认的dic文件,在config目录新建 my_ext.dic 和 my_stop.dic

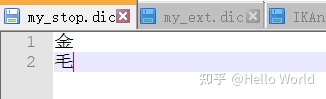
然后配置到 IKAnalyzer.cfg
重启ES 测试
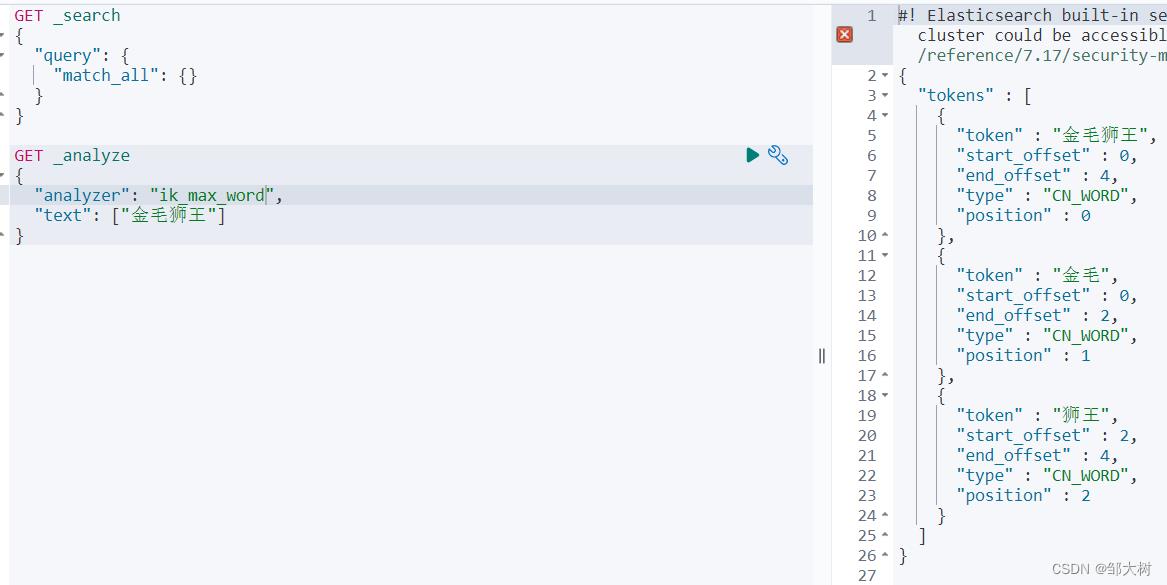
自定义字典:
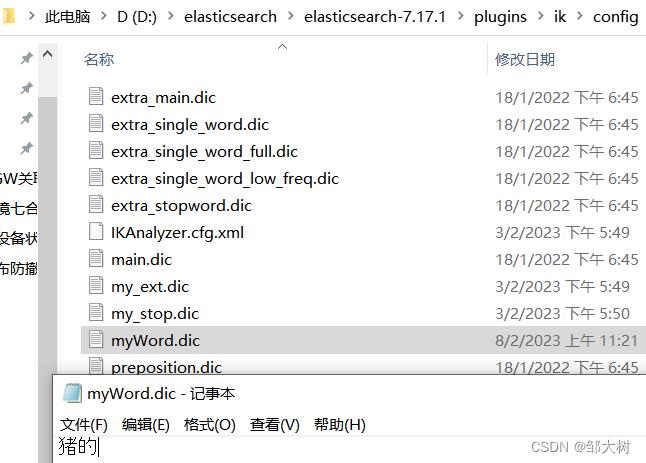
比如说“母猪的产后护理”,我想自定义“猪的”为一组词,这样的话,默认的分词并不能满足我们的要求,所以我们需要自定义词。
1.新建自定义字典文档
2.添加新词汇到自定义字典文档
3.配置
编写配置文件,将新增的字典注入到配置文件中(注意 不可以配置两个自定义字典,会报错)

4.重启ES和kibana
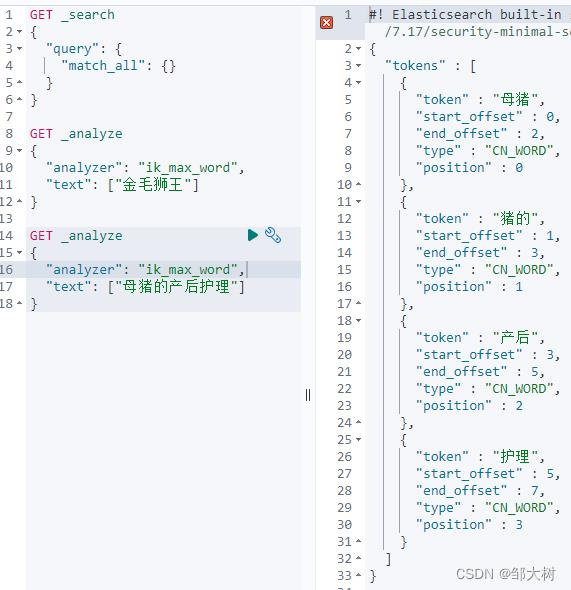
以上是关于ElasticSearch学习 ④ IK分词器(elasticsearch插件)+自定义字典的主要内容,如果未能解决你的问题,请参考以下文章
ElasticSearch03_Mapping字段映射常用类型数据迁移ik分词器自定义分词器
ElasticSearch03_Mapping字段映射常用类型数据迁移ik分词器自定义分词器
虚拟化docker部署ElasticSearch,下载IK分词器
docker 部署 Elasticsearch kibana 以及 ik分词器