ElasticSearch03_Mapping字段映射常用类型数据迁移ik分词器自定义分词器
Posted 所得皆惊喜
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ElasticSearch03_Mapping字段映射常用类型数据迁移ik分词器自定义分词器相关的知识,希望对你有一定的参考价值。
文章目录
- ①. Mapping字段映射概述
- ②. 常用类型如下 - text、keyword
- ③. 映射中对时间类型详解
- ④. ES的keyword的属性ignore_above
- ⑤. 映射的查看、创建 - _mapping
- ⑥. 数据迁移 - reindex
- ⑦. ik_max_word、ik_smart分词器
- ⑧. 自定义分词器
①. Mapping字段映射概述
-
①. 映射(Mapping)相当于数据表的表结构。ElasticSearch中的映射(Mapping)用来定义一个文档,可以定义所包含的字段以及字段的类型、分词器及属性等等
-
②. 映射可以分为动态映射和静态映射
- 动态映射(dynamic mapping):在关系数据库中,需要事先创建数据库,然后在该数据库实例下创建数据表,然后才能在该数据表中插入数据。而ElasticSearch中不需要事先定义映射(Mapping),文档写入ElasticSearch时,会根据文档字段自动识别类型。这种机制称之为动态映射
- 静态映射 :在ElasticSearch中也可以事先定义好映射,包含文档的各个字段及其类型等,这种方式称之为静态映射
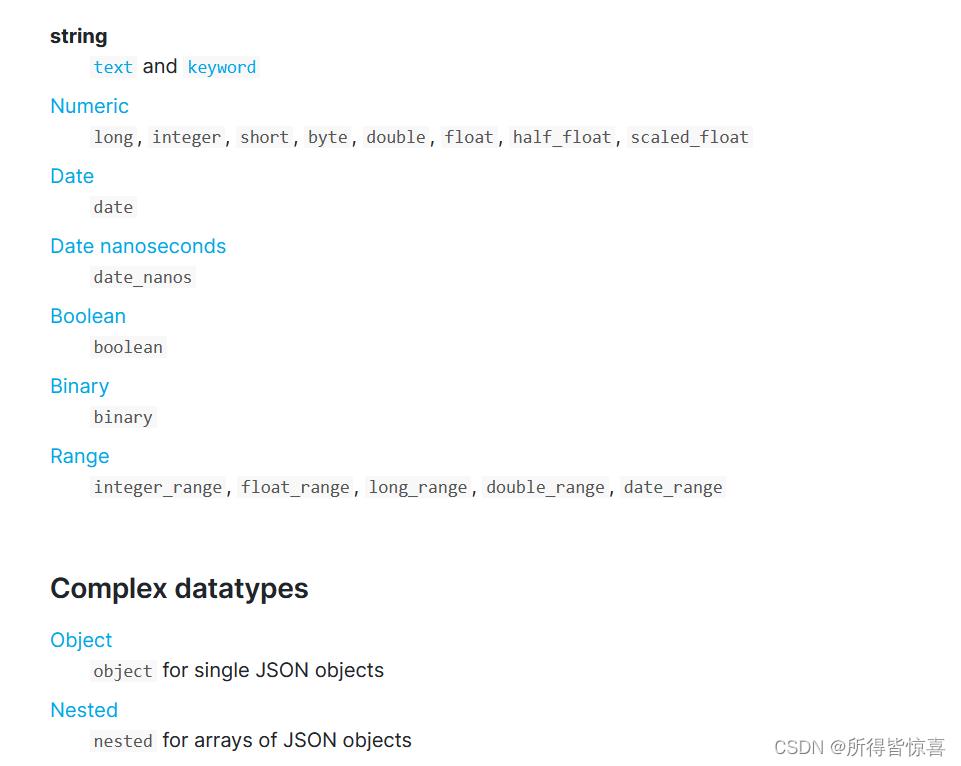
②. 常用类型如下 - text、keyword
- text:可分词,不可参与聚合
- keyword:不可分词,数据会作为完整字段进行匹配,可以参与聚合
| 类型 | 描述 |
|---|---|
| text | 当一个字段要是被全文搜索的,比如Email内容、产品描述,应该使用text类型。设置text类型以后,字段内容会被分析,在生成倒排索引以前,字符串会被分析器分成一个个的词项。text类型的字段不用排序,很少用于聚合 |
| keyword | keyword类型适用于索引结构化的字段,比如email地址、主机名、状态码和标签。如果字段需要进行过滤(比如查找已发布博客中status属性为published的文章)、排序、聚合。keyword类型的字段只能通过精确值搜索到 |
- ②. 整数类型
| 类型 | 取值范围 |
|---|---|
| byte | -128 - 127 |
| short | -32768 - 32767 |
| integer | -2的31次方 – 2的31-1 |
| long | -2的63次方 - 2的63次方-1 |
- ③. 浮点类型
| 类型 | 取值范围 |
|---|---|
| doule | 64位双精度浮点类型 |
| float | 32位单精度浮点类型 |
| half_float | 16位半精度浮点类型 |
| scaled_float | 缩放类型的浮点数 |
- ④. date类型,日期类型表示格式可以是以下几种:
- 日期格式的字符串,比如"2018-01-13"或"2018-01-13 12:10:30"
- long类型的毫秒数(从1970年开始)
- integer的秒数
-
⑤. boolean类型:逻辑类型(布尔类型)可以接受true/false
-
⑥. binary类型
二进制字段是指base64来表示索引中储存的二进制数据,可用来储存二进制形式的数据,例如图像。默认情况下,该类型的字段只储存不索引。二进制只支持index_name属性 -
⑦. array类型
-
⑧. object类型:JSON天生具有层级关系,文档会包含嵌套的对象
- index影响字段的索引情况
true:字段会被索引,则可以用来进行搜索。默认值就是true
false:字段不会被索引,不能用来搜索
(index的默认值就是true,也就是说你不进行任何配置,所有字段都会被索引。
但是有些字段是我们不希望被索引的,比如企业的logo图片地址,就需要手动设置index为false) - store:是否将数据进行独立存储
原始的文本会存储在_source里面,默认情况下其他提取出来的字段都不是独立存储的,是从_source里面提取出来的。当然你也可以独立的存储某个字段,只要设置store:true即可,获取独立存储的字段要比从_source中解析快得多,但是也会占用更多的空间,所以要根据实际业务需求来设置,默认为false - analyzer:指定分词器
一般我们处理中文会选择ik分词器 ik_max_word、ik_smart
PUT /索引库名/_mapping
"properties":
"字段名":
"type": "类型", # type:类型,可以是text、long、short、date、integer、object等
"index": true, # index:是否索引,默认为true
"store": false, # store:是否存储,默认为false
"analyzer": "分词器" # analyzer:指定分词器
PUT /company-index/_mapping
"properties":
"name":
"type": "text",
"index": true,
"analyzer": "ik_max_word"
,
"job":
"type": "text",
"analyzer": "ik_max_word"
,
"logo":
"type": "keyword",
"index": false
,
"payment":
"type": "float"
③. 映射中对时间类型详解
- ①. 假如我们有如下索引tax,保存了一些公司的纳税或资产信息,单位为"万元"。当然这里面的数据是随意填写的。多少为数据统计的时间,当前这个例子里。索引达的含义并不重要。关键点在于字段的内容格式。我们看到date字段其中包含了多种日期的格式:“yyyy-MM-dd”,"yyyy-MM-dd"还有时间戳。如果按照dynamic mapping,采取自动映射器来映射索引。我们自然而然的都会感觉字段应该是一个date类型
POST tax/_bulk
"index":
"date": "2021-01-25 10:01:12","company": "中国烟草","ratal": 5700000
"index":
"date": "2021-01-25 10:01:13","company": "华为","ratal": 4034113.182
"index":
"date": "2021-01-26 10:02:11","company": "苹果","ratal": 7784.7252
"index":
"date": "2021-01-26 10:02:15","company": "小米","ratal": 185000
"index":
"date": "2021-01-26 10:01:23","company": "阿里","ratal": 1072526
"index":
"date": "2021-01-27 10:01:54","company": "腾讯","ratal": 6500
"index":
"date": "2021-01-28 10:01:32","company": "蚂蚁金服","ratal": 5000
"index":
"date": "2021-01-29 10:01:21","company": "字节跳动","ratal": 10000
"index":
"date": "2021-01-30 10:02:07","company": "中国石油","ratal": 18302097
"index":
"date": "1648100904","company": "中国石化","ratal": 32654722
"index":
"date": "2021-11-1 12:20:00","company": "国家电网","ratal": 82950000
- ②. 我们以上代码查看tax索引的mapping,会惊奇的发现date居然是一个text类型。这是为什么呢?
"properties" :
"date" :
"type" : "text","fields" :
"keyword" :
"type" : "keyword","ignore_above" : 256
- ③. 原因就在于对时间类型的格式的要求是绝对严格的。要求必须是一个标准的UTC时间类型。上述字段的数据格式如果想要使用,就必须使用yyyy-MM-ddTHH:mm:ssZ格式(其中T个间隔符,Z代表 0 时区),以下均为错误的时间格式(均无法被自动映射器识别为日期时间类型):
- yyyy-MM-dd HH:mm:ss
- yyyy-MM-dd
- 时间戳
- 需要注意的是时间说是必须的时间格式,但是需要通过手工映射方式在索引创建之前指定为日期类型,使用自动映射器无法映射为日期类型
- ④. 我们现在已经知道要求其类型必须为UTC的时间格式,那么我们把下面索引通过自动映射,date字段会被映射什么类型呢?
PUT test_index/_doc/1
"time":"2022-4-30T20:00:00Z"
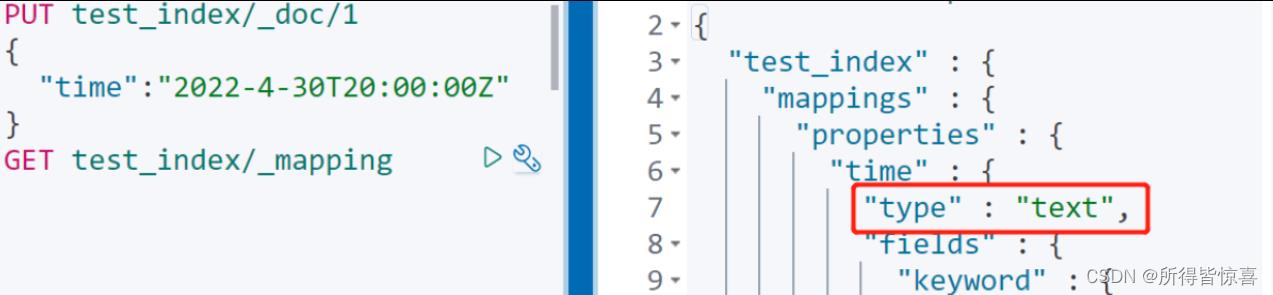
- ⑤. 历史总是惊人的相似,映射结果居然依然是文本类型。这就是又一个我们很容易踩的坑,日期字段并非严格符合要求格式,注意观察下面两者区别:
- 2022-4-30T20:00:00Z 错误
- 2022-04-30T20:00:00Z 正确
- ⑥. 如果我们换一个思路,使用手工映射提前指定日期类型,那会又是一个什么结果呢?
第一个(写入失败):2021-01-30 10:02:07
第二个(写入成功):1648100904
第三个(写入失败):2021-11-1T12:20:00Z
第四个(写入成功):2021-01-30T10:02:07Z
第五个(写入成功):2021-01-25
PUT tax
"mappings":
"properties":
"date":
"type": "date"
POST tax/_bulk
"index":
"date": "2021-01-30 10:02:07","ratal": 32654722
"index":
"date": "2021-11-1T12:20:00Z","ratal": 82950000
"index":
"date": "2021-01-30T10:02:07Z","ratal": 18302097
"index":
"date": "2021-01-25","ratal": 5700000
# 执行以上代码,以下为完整的执行结果:
"took" : 17,"errors" : true,"items" : [
"index" :
"_index" : "tax","_type" : "_doc","_id" : "f4uyun8B1ovRQq6Sn9Qg","status" : 400,"error" :
"type" : "mapper_parsing_exception","reason" : "Failed to parse field [date] of type [date] in document with id 'f4uyun8B1ovRQq6Sn9Qg'. Preview of field's value: '2021-01-30 10:02:07'","caused_by" :
"type" : "illegal_argument_exception","reason" : "Failed to parse date field [2021-01-30 10:02:07] with format [strict_date_optional_time||epoch_millis]","caused_by" :
"type" : "date_time_parse_exception","reason" : "date_time_parse_exception: Failed to parse with all enclosed parsers"
,
"index" :
"_index" : "tax","_id" : "gIuyun8B1ovRQq6Sn9Qg","_version" : 1,"result" : "created","_shards" :
"total" : 2,"successful" : 2,"Failed" : 0
,"_seq_no" : 3,"_primary_term" : 1,"status" : 201
,"_id" : "gYuyun8B1ovRQq6Sn9Qg","reason" : "Failed to parse field [date] of type [date] in document with id 'gYuyun8B1ovRQq6Sn9Qg'. Preview of field's value: '2021-11-1T12:20:00Z'","reason" : "Failed to parse date field [2021-11-1T12:20:00Z] with format [strict_date_optional_time||epoch_millis]","_id" : "gouyun8B1ovRQq6Sn9Qg","_seq_no" : 4,"_id" : "g4uyun8B1ovRQq6Sn9Qg","_seq_no" : 5,"status" : 201
]
- ⑦. 总结:
- 对于yyyy-MM-dd HH:mm:ss或2021-11-1T12:20:00Z,ES 的自动映射器完全无法识别,即便是事先声明日期类型,数据强行写入也会失败
- 对于时间戳和yyyy-MM-dd这样的时间格式,ES 自动映射器无法识别,但是如果事先说明了日期类型是可以正常写入的
- 对于标准的日期时间类型是可以正常自动识别为日期类型,并且也可以通过手工映射来实现声明字段类型
- ⑧. ES的时间类型为什么这么难用,有没有什么办法可以解决?
只需要在字段属性中添加一个参数:
“format”: “yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis”,这样就可以避免因为数据格式不统一而导致数据无法写入的窘境。代码如下:
PUT test_index
"mappings":
"properties":
"time":
"type": "date","format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
④. ES的keyword的属性ignore_above
-
①. 在es的5.x版本,keyword类型字段可以设置ignore_above,表示最大的字段值长度,超出这个长度的字段将不会被索引,但是会存储
-
②. 举个例子:设置message 的长度最长为20,超过20的不被索引,这里的不被索引是这个字段不被索引,但是其他字段有的话仍然被索引到
PUT my_index
"mappings":
"my_type":
"properties":
"message":
"type": "keyword",
"ignore_above": 20
# 下面造点数据
PUT my_index/my_type/3
"message": "123456789"
PUT my_index/my_type/5
"message": "123456789012345678901"
- ③. 如果你做全部查询是可以查到超过ignore_above的doc的,如下图:

- ④. 如果你用模糊匹配是搜索不到的(注意上面的数据最后带个1是21位下图是20位的)

- ⑤. 用精确匹配前面20个仍然搜索不到
⑤. 映射的查看、创建 - _mapping
- ①. 查看mapping信息:GET bank/_mapping
"bank" :
"mappings" :
"properties" :
"account_number" :
"type" : "long" # long类型
,
"address" :
"type" : "text", # 文本类型,会进行全文检索,进行分词
"fields" :
"keyword" : # addrss.keyword
"type" : "keyword", # 该字段必须全部匹配到
"ignore_above" : 256
,
"age" :
"type" : "long"
,
"balance" :
"type" : "long"
,
"city" :
"type" : "text",
"fields" :
"keyword" :
"type" : "keyword",
"ignore_above" : 256
,
"email" :
"type" : "text",
"fields" :
"keyword" :
"type" : "keyword",
"ignore_above" : 256
,
"employer" :
"type" : "text",
"fields" :
"keyword" :
"type" : "keyword",
"ignore_above" : 256
,
"firstname" :
"type" : "text",
"fields" :
"keyword" :
"type" : "keyword",
"ignore_above" : 256
,
"gender" :
"type" : "text",
"fields" :
"keyword" :
"type" : "keyword",
"ignore_above" : 256
,
"lastname" :
"type" : "text",
"fields" :
"keyword" :
"type" : "keyword",
"ignore_above" : 256
,
"state" :
"type" : "text",
"fields" :
"keyword" :
"type" : "keyword",
"ignore_above" : 256
- ②. 新版本改变:ElasticSearch7-去掉type概念
- 关系型数据库中两个数据表示是独立的,即使他们里面有相同名称的列也不影响使用,但ES中不是这样的。elasticsearch是基于Lucene开发的搜索引擎,而ES中不同type下名称相同的filed最终在Lucene中的处理方式是一样的
(1). 两个不同type下的两个user_name,在ES同一个索引下其实被认为是同一个filed,你必须在两个不同的type中定义相同的filed映射。否则,不同type中的相同字段名称就会在处理中出现冲突的情况,导致Lucene处理效率下降。
(2). 去掉type就是为了提高ES处理数据的效率。 - Elasticsearch 7.x URL中的type参数为可选。比如,索引一个文档不再要求提供文档类型
- Elasticsearch 8.x 不再支持URL中的type参数
- 解决:
将索引从多类型迁移到单类型,每种类型文档一个独立索引
将已存在的索引下的类型数据,全部迁移到指定位置即可。详见数据迁移
- ③. 创建映射PUT /my_index
PUT /my_index
"mappings":
"properties":
"age":
"type": "integer"
,
"email":
"type": "keyword" # 指定为keyword
,
"name":
"type": "text" # 全文检索。保存时候分词,检索时候进行分词匹配
输出:
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "my_index"
查看映射GET /my_index
输出结果:
"my_index" :
"aliases" : ,
"mappings" :
"properties" :
"age" :
"type" : "integer"
,
"email" :
"type" : "keyword"
,
"employee-id" :
"type" : "keyword",
"index" : false
,
"name" :
"type" : "text"
,
"settings" :
"index" :
"creation_date" : "1588410780774",
"number_of_shards" : "1",
"number_of_replicas" : "1",
"uuid" : "ua0lXhtkQCOmn7Kh3iUu0w",
"version" :
"created" : "7060299"
,
"provided_name" : "my_index"
# 添加新的字段映射PUT /my_index/_mapping
PUT /my_index/_mapping
"properties":
"employee-id":
"type": "keyword",
"index": false # 字段不能被检索。检索
这里的 "index": false,表明新增的字段不能被检索,只是一个冗余字段。
-
④. 不能更新映射:对于已经存在的字段映射,我们不能更新。更新必须创建新的索引,进行数据迁移
以上是关于ElasticSearch03_Mapping字段映射常用类型数据迁移ik分词器自定义分词器的主要内容,如果未能解决你的问题,请参考以下文章