CIFAR-10数据集图像分类PCA+基于最小错误率的贝叶斯决策
Posted klausage
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CIFAR-10数据集图像分类PCA+基于最小错误率的贝叶斯决策相关的知识,希望对你有一定的参考价值。
CIFAR-10和CIFAR-100均是带有标签的数据集,都出自于规模更大的一个数据集,他有八千万张小图片。而本次实验采用CIFAR-10数据集,该数据集共有60000张彩色图像,这些图像是32*32,分为10个类,每类6000张图。这里面有50000张用于训练,构成了5个训练批,每一批10000张图;另外10000用于测试,单独构成一批。测试批的数据里,取自10类中的每一类,每一类随机取1000张。抽剩下的就随机排列组成了训练批。注意一个训练批中的各类图像并不一定数量相同,总的来看训练批,每一类都有5000张图。
下面这幅图就是列举了10各类,每一类展示了随机的10张图片:

我的数据集一共有三个文件,分别是训练集train_data,测试集test_data以及标签名称labels_name,而标签名称中共有5个类,‘airplane‘, ‘automobile‘, ‘bird‘, ‘cat‘, ‘deer’.我现在准备对前三类‘airplane‘, ’automobile‘, ’bird‘,(即标签为1, 2, 3的数据 )进行分类。
经过之前大量测试,得到在累计方差贡献率为0.79时,基于最小错误率的贝叶斯决策用于图像分类最佳,以下为代码:

#CIFAR-10数据集:包含60000个32*32的彩色图像,共10类,每类6000个彩色图像。有50000个训练图像和10000个测试图像。
import scipy.io
train_data=scipy.io.loadmat("F:\\模式识别\\最小错误率的贝叶斯决策进行图像分类\\data\\train_data.mat")
print (type(train_data))
print (train_data.keys())
print (train_data.values())
print (len(train_data[‘Data‘]))
#单张图片的数据向量长度:32X32X3=3072
#内存占用量=3072*4*9968=116M 假定一个整数占用4个字节
print (len(train_data[‘Data‘][0]))
print (train_data)
x = train_data[‘Data‘]
y = train_data[‘Label‘]
print (y)
print (len(y))
print (y.shape)
print (y.flatten().shape)
#labels_name:共5个标签,分别为airplane、automobile、bird、cat、deer
import scipy.io
labels_name=scipy.io.loadmat("F:\\模式识别\\最小错误率的贝叶斯决策进行图像分类\\data\\labels_name.mat")
print (type(labels_name))
print (labels_name)
print (len(labels_name))
#test_data:共5000个图像,5类,每类1000个图像
import scipy.io
test_data=scipy.io.loadmat("F:\\模式识别\\最小错误率的贝叶斯决策进行图像分类\\data\\test_data.mat")
print (test_data[‘Label‘])
print (test_data[‘Data‘])
print (len(test_data[‘Label‘]))
datatest = test_data[‘Data‘]
labeltest = test_data[‘Label‘]
print (datatest.shape)
print (labeltest.shape)
test_index=[]
for i in range(len(labeltest)):
if labeltest[i]==1:
test_index.append(i)
elif labeltest[i]==2:
test_index.append(i)
elif labeltest[i]==3:
test_index.append(i)
#print (test_index)
labeltest=test_data[‘Label‘][:3000]
#print (labeltest)
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
print (x)
print (x.shape)
print (type(x))
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.decomposition import PCA
pca=PCA(n_components=0.79)
#训练模型
pca.fit(x)
x_new=pca.transform(x)
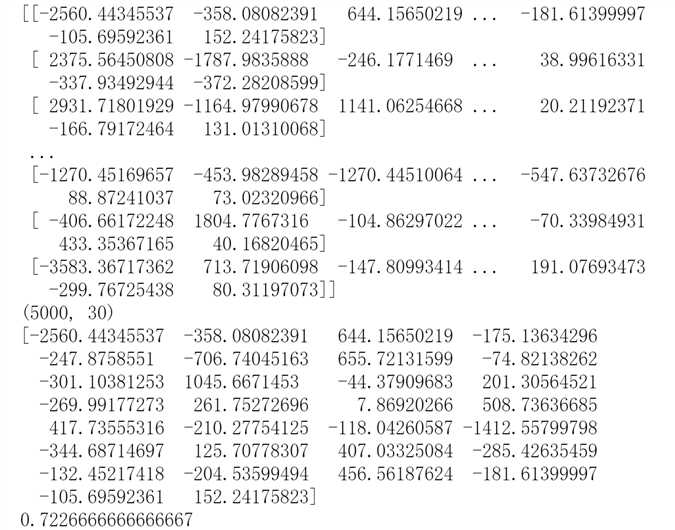
print("降维后各主成分的累计方差贡献率:",pca.explained_variance_ratio_)
print("降维后主成分的个数:",pca.n_components_)
print (x_new)
index_1=[]
index_2=[]
index_3=[]
index_num=[]
for i in range(len(y)):
if y[i]==1:
index_1.append(i)
elif y[i]==2:
index_2.append(i)
elif y[i]==3:
index_3.append(i)
index_num=[len(index_1),len(index_2),len(index_3)]
print(len(index_1))
print(len(index_2))
print(len(index_3))
print (index_num)
import numpy as np
class1_feature=[]
class2_feature=[]
class3_feature=[]
#index_1
for i in index_1:
class1_feature.append(x_new[i])
print (len(class1_feature))
for i in index_2:
class2_feature.append(x_new[i])
print (len(class2_feature))
for i in index_3:
class3_feature.append(x_new[i])
print (len(class3_feature))
#计算第一类的类条件概率密度函数的参数
class1_feature=np.mat(class1_feature)
print (class1_feature.shape)
miu1=[]
sigma1=[]
for i in range(30):
miu=class1_feature[:,i].sum()/len(index_1)
miu1.append(miu)
temp=class1_feature[:,i]-miu
class1_feature[:,i]=temp
sigma1=(class1_feature.T*class1_feature)/len(index_1)
print (miu1)
print (sigma1)
print (sigma1.shape)
#计算第二类类条件概率密度函数的参数
class2_feature=np.mat(class2_feature)
miu2=[]
sigma2=[]
for i in range(30):
miu=class2_feature[:,i].sum()/len(index_2)
miu2.append(miu)
temp=class2_feature[:,i]-miu
class2_feature[:,i]=temp
sigma2=(class2_feature.T*class2_feature)/len(index_2)
print (miu2)
print (sigma2)
print (sigma2.shape)
#计算第三类类条件概率密度函数的参数
class3_feature=np.mat(class3_feature)
miu3=[]
sigma3=[]
for i in range(30):
miu=class3_feature[:,i].sum()/len(index_3)
miu3.append(miu)
temp=class3_feature[:,i]-miu
class3_feature[:,i]=temp
sigma3=(class3_feature.T*class3_feature)/len(index_3)
print (miu3)
print (sigma3)
print (sigma3.shape)
#计算三个类别的先验概率:
prior_index1=len(index_1)/len(y)
prior_index2=len(index_2)/len(y)
prior_index3=len(index_3)/len(y)
print (prior_index1)
print (prior_index2)
print (prior_index3)
import math
#降维
x_test = pca.transform(datatest)
print (x_test)
print (x_test.shape)
print (x_test[0])
#print ((np.mat(x_test[0]-miu1))*sigma1.I*(np.mat(x_test[0]-miu1).T))
#print (((np.mat(x_test[0]-miu1))*sigma1.I*(np.mat(x_test[0]-miu1).T))[0,0])
predict_label=[]
for i in range(3000):
g1=-0.5*((np.mat(x_test[i]-miu1))*sigma1.I*(np.mat(x_test[i]-miu1).T))[0,0]-0.5*math.log(np.linalg.det(sigma1))+math.log(prior_index1)
g2=-0.5*((np.mat(x_test[i]-miu2))*sigma2.I*(np.mat(x_test[i]-miu2).T))[0,0]-0.5*math.log(np.linalg.det(sigma2))+math.log(prior_index2)
g3=-0.5*((np.mat(x_test[i]-miu3))*sigma3.I*(np.mat(x_test[i]-miu3).T))[0,0]-0.5*math.log(np.linalg.det(sigma3))+math.log(prior_index3)
if g1>g2:
max=1
if g1>g3:
max=1
else:
max=3
else:
max=2
if g2>g3:
max=2
else:
max=3
predict_label.append(max)
from sklearn.metrics import accuracy_score
print (accuracy_score(predict_label,labeltest))
可以看到分类结果的准确率高达73%,这一数值在贝叶斯决策用于图像分类中已经是极值了。
以上是关于CIFAR-10数据集图像分类PCA+基于最小错误率的贝叶斯决策的主要内容,如果未能解决你的问题,请参考以下文章
Computer Vision基于ResNet-50实现CIFAR10数据集分类
小白学习PyTorch教程六基于CIFAR-10 数据集,使用PyTorch 从头开始构建图像分类模型
基于CIFAR10图像数据集和SVM的图像分类算法matlab仿真