图像识别—CIFAR-10/CIFAR-100数据集解析
Posted AI研习图书馆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图像识别—CIFAR-10/CIFAR-100数据集解析相关的知识,希望对你有一定的参考价值。
AI研习图书馆,发现不一样的世界
CIFAR-10/CIFAR-100数据集解析
一、CIFAR-10数据集
数据集分为五个训练批次和一个测试批次,每个批次有10000个图像。测试批次包含来自每个类别的1000个随机选择的图像。训练批次以随机顺序包含剩余图像,但一些训练批次可能包含来自一个类别的图像比另一个更多。总体来说,五个训练集之和,包含来自每个类的正好5000张图像。
以下是数据集中的类别示例,以及来自每个类的10个随机图像示例:

这些类完全相互排斥。例如,汽车和卡车之间没有重叠。“汽车”包括轿车,SUV,这类车辆。“卡车”只包括大卡车,而且它们都不包括皮卡车。十个类别英文名称如下:
airplane/automobile/bird/cat/deer/dog/frog/horse/ship/truck
1. CIFAR-10下载
CIFAR-10 python版本
CIFAR-10 Matlab版本
CIFAR-10二进制版本(适用于C程序)
2. 数据集布局
(1)Python / Matlab版本
这里描述数据集的Python版本的布局。Matlab版本的布局是相同的。
该存档包含文件data_batch_1,data_batch_2,...,data_batch_5以及test_batch。这些文件中的每一个都是用cPickle生成的Python“pickled”对象
def unpickle(file):import cPicklewith open(file, 'rb') as fo:dict = cPickle.load(fo)return dict
def unpickle(file):import picklewith open(file, 'rb') as fo:dict = pickle.load(fo, encoding='bytes')return dict
(2)二进制版本
二进制版本包含文件data_batch_1.bin,data_batch_2.bin,...,data_batch_5.bin以及test_batch.bin。这些文件中的每一个格式如下:
<1×标签> <3072×像素>...<1×标签> <3072×像素>
二、CIFAR-100数据集
这个数据集类似于CIFAR-10,除了它有100个类,每个类包含600个图像。每类各有500个训练图像和100个测试图像。CIFAR-100中的100个类被分成20个超类。每个图像都带有一个“精细”标签(它所属的类)和一个“粗糙”标签(它所属的超类)
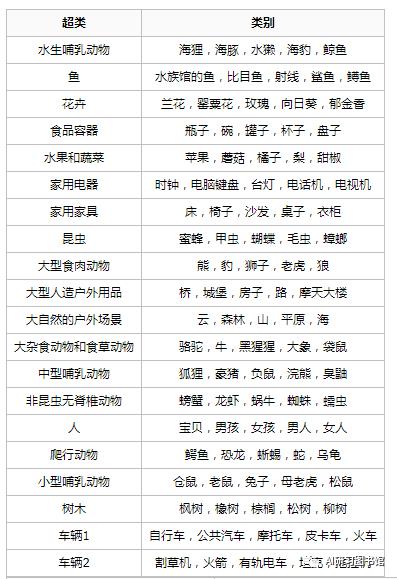
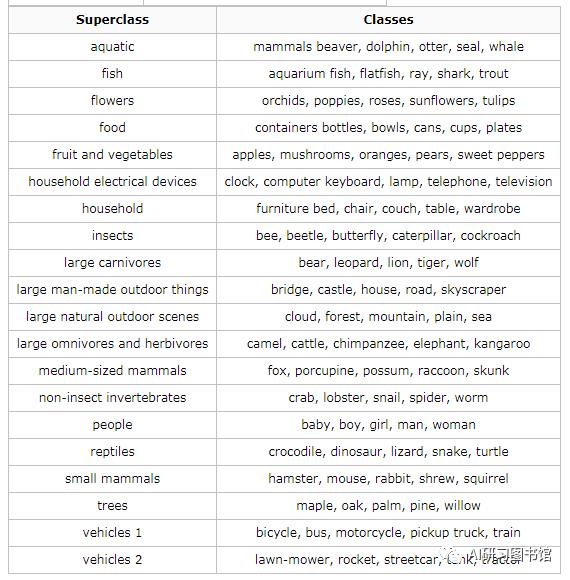
1. CIFAR-100下载
CIFAR-100 python版本
CIFAR-100 Matlab版本
CIFAR-100二进制版本(适用于C程序)
2. 数据集布局
(1)Python/matlab版本
(2)二进制版本
CIFAR-100的二进制版本与CIFAR-10的二进制版本相似,只是每个图像都有两个标签字节(粗略和细小)和3072像素字节,所以二进制文件如下所示:
<1 x粗标签> <1 x精标签> <3072 x像素>...<1 x粗标签> <1 x精标签> <3072 x像素>
祝你深度学习快乐~~
点击阅读原文,可跳转至CSDN博客继续学习~
推荐阅读文章
[1]
[2]
[3]
[4]
[5]
[6]
[7]
[8]
[9]
[10]
[11]
[12]
[13]
[14]
[15]
[16]
[17]
[18]
......





关注AI研习图书馆,发现不一样的精彩世界
以上是关于图像识别—CIFAR-10/CIFAR-100数据集解析的主要内容,如果未能解决你的问题,请参考以下文章