Python高级应用程序设计任务
Posted 庄启源
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python高级应用程序设计任务相关的知识,希望对你有一定的参考价值。
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
基于xpath的瓜子二手车网数据爬取和分析
2.主题式网络爬虫爬取的内容与数据特征分析
爬取内容:瓜子二手车网上每一辆车的标题信息、上牌的时间、表显里程、排量、变速箱类型、价格和新车的指导价格。数据特征分析:在获取的数据中,可以把汽车的上牌时间、表显里程、排量和价格进行数据统计和可视化,其中可以把上牌时间、价格、表显里程进行可视化,构建数据分析模型,进行分析。
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
实现思路:
(1)验证请求头信息User-Agent,使用requests请求网页,运行并观察返回值,是200,表示正确,进行下一步操作。否则检查程序再操作。
(2)利用lxml库中etree解析网页
(3)观察HTML网页结构,注意父节点和子节点,同时利用xpath获取ul标签下的li标签。
(4)遍历li标签,获取li标签下的每一辆车详情页面的url
(5)遍历每一辆车详情页面的url,利用xpath语法获取所需要的数据,并利用循环翻页获取更多数据。
(6)使用DataFrame把数据写入特定位置
技术难点:
(1)要注意在获取数据时xpath语法的正确表示,否则会出错;
(2)网页可能遭遇反爬,需进行相关反爬操作;
(3)需使用xpath进行双重遍历;
①首先遍历获取li标签下的url;
②再对每个获取到的url进行遍历。
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
按F12打开页面,观察html代码,可以清楚的看到每一辆汽车对应着代码上的一个li标签,同时每一个li标签下都包含每一辆车详情页面的url。
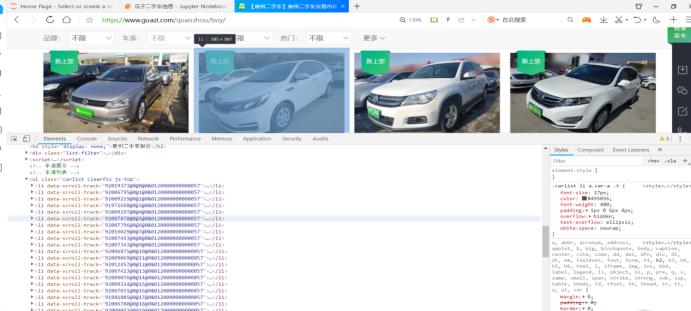
2.Htmls页面解析
利用lxml库中etree解析网站页面,观察详情页面代码结构并使用xpath获取需要内容。

3.节点(标签)查找方法与遍历方法
节点查找方法是利用xpath获取ul下的li标签,要注意xpath使用的语法规则,要按照规则编写代码,获取内容。遍历方法采用循环遍历,包括遍历li标签、遍历详情页面url、实现翻页操作。
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
#!/usr/bin/python3 #_*_coding:utf-8 _*_ #@Author:zhuangqiyuan #@title:瓜子二手车数据的爬取和分析 #导入包 import requests from lxml import etree from bs4 import BeautifulSoup from pandas import DataFrame import os page=1 #添加标识请求头 headers ={ \'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400\', \'Cookie\': \'uuid=8bcc429c-029f-4d45-8de8-f88fb0ca2c78; cityDomain=quanzhou; user_city_id=79; ganji_uuid=3211364230579822430047; lg=1; antipas=58B0581931382V16140z6Q; clueSourceCode=%2A%2300; preTime=%7B%22last%22%3A1575860416%2C%22this%22%3A1575789163%2C%22pre%22%3A1575789163%7D; sessionid=276e0d0e-d04f-4bea-f47d-41826a7e8721; cainfo=%7B%22ca_a%22%3A%22-%22%2C%22ca_b%22%3A%22-%22%2C%22ca_s%22%3A%22seo_baidu%22%2C%22ca_n%22%3A%22default%22%2C%22ca_medium%22%3A%22-%22%2C%22ca_term%22%3A%22-%22%2C%22ca_content%22%3A%22-%22%2C%22ca_campaign%22%3A%22-%22%2C%22ca_kw%22%3A%22%22%2C%22ca_i%22%3A%22-%22%2C%22scode%22%3A%22-%22%2C%22keyword%22%3A%22-%22%2C%22ca_keywordid%22%3A%22-%22%2C%22display_finance_flag%22%3A%22-%22%2C%22platform%22%3A%221%22%2C%22version%22%3A1%2C%22client_ab%22%3A%22-%22%2C%22guid%22%3A%228bcc429c-029f-4d45-8de8-f88fb0ca2c78%22%2C%22ca_city%22%3A%22quanzhou%22%2C%22sessionid%22%3A%226b581614-2868-43a0-d015-508d9830fd27%22%7D; Hm_lvt_936a6d5df3f3d309bda39e92da3dd52f=1575789164,1575793823,1575860415; Hm_lpvt_936a6d5df3f3d309bda39e92da3dd52f=1575860415; close_finance_popup=2019-12-09\' } #csv文件命名 file_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), \'guaziershou_data.csv\') #定义获取li标签下详情页面url的函数 def get_detail_urls(url): # 获取页面数据 resp = requests.get(url, headers=headers) text = resp.content.decode(\'utf-8\') # print(text) # 解析网页 html = etree.HTML(text) # print(html) #获取网页下的ul标签 ul=html.xpath(\'//ul[@class="carlist clearfix js-top"]\')[0] # print(ul) #获取ul标签下的全部li标签 lis = ul.xpath(\'./li\') # print(lis) detail_urls = [] #循环获取li标签下的所有详细页面的url for li in lis: detail_url = li.xpath(\'./a/@href\') detail_url = \'https://www.guazi.com\' + detail_url[0] # print(detail_url) detail_urls.append(detail_url) return detail_urls #定义获取详情页面数据的函数 def xiangxi_url(url): text = requests.get(url, headers=headers) resp = text.content.decode(\'utf-8\') html = etree.HTML(resp) # print(html) # 根据xpath语法规则编写程序,获取车辆的名称 title = html.xpath(\'//div[@class="product-textbox"]/h2/text()\')[0] title = title.replace(r\'\\r\\n\', \'\').strip() # print(title) title1=title.split(r\' \') print(title) #定义一个字典用于存放表格标题 infos ={} #获取二手车辆的上牌时间 shangpai = html.xpath(\'//ul[@class="assort clearfix"]/li/span/text()\')[0] # print(shangpai) shangpai1 =shangpai.split(r\'-\') #进行数据分割,获取需要数据 spdata=shangpai1[0] print(spdata) #获取二手车辆的表显里程信息 biaoxian = html.xpath(\'//ul[@class="assort clearfix"]/li/span/text()\')[1] # print(biaoxian) biaoxian1=biaoxian.split(r\'万\') oldkm=biaoxian1[0] print(oldkm) #获取二手车辆的排量情况 pailiang = html.xpath(\'//ul[@class="assort clearfix"]/li/span/text()\')[2] print(pailiang) #获取二手车辆的变速箱类型(自动/手动) biansu = html.xpath(\'//ul[@class="assort clearfix"]/li/span/text()\')[3] print(biansu) #获取二手车辆的价格 jiage = html.xpath(\'//span[@class="pricestype"]/text()\')[0] # print(jiage) jiage1 = jiage.split(r\'¥\') # print(jiage1) jiage2 = jiage1[1] print(jiage2) #获取二手车辆的新车指导价格 newjiage = html.xpath(\'//span[@class="newcarprice"]/text()\')[0] newjiage = newjiage.replace(r\'\\r\\n\', \'\').strip() # print(newjiage) newjiage1 = newjiage.split(r\'万\') # print(newjiage1) newjiage2 = newjiage1[0] print(newjiage2) infos[\'title\']=title infos[\'spdata\'] = spdata infos[\'oldkm\'] = oldkm infos[\'pailiang\'] = pailiang infos[\'biansu\'] = biansu infos[\'jiage\'] = jiage2 infos[\'newjiage\'] =newjiage2 df = DataFrame(infos, index=[0]) return infos def main(): base_url = \'https://www.guazi.com/quanzhou/buy/o{}/\' # 循环实现翻页效果 for x in range(1,50): url=base_url.format(x) # 调用get_detail_urls函数获取详情页面的全部url detail_urls = get_detail_urls(url) # print(detail_urls) #遍历详情页面的url,并调用xiangxi_url函数获取需要的信息 for detail_url in detail_urls: infos=xiangxi_url(detail_url) df = DataFrame(infos, index=[0]) if os.path.exists(file_path): #写入数据保存,字符编码采用utf-8 df.to_csv(file_path, header=False, index=False, mode="a+", encoding="utf_8_sig") else: df.to_csv(file_path, index=False, mode="w+", encoding="utf_8_sig") # 程序执行时调用主程序main() if __name__ == \'__main__\': main()
2.对数据进行清洗和处理
2.1使用DataFrame进行数据加载
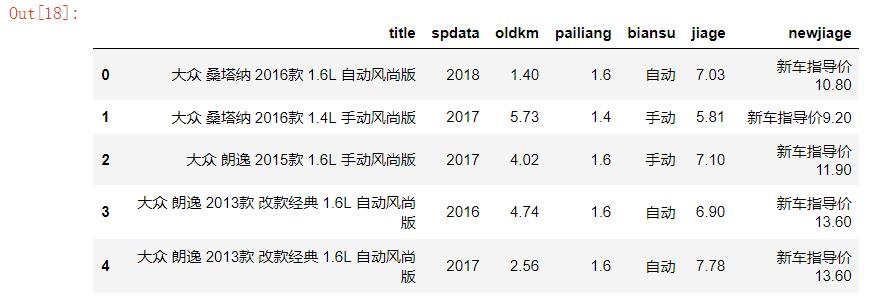
#使用DataFrame进行数据加载 import pandas as pd df = pd.read_excel(r\'E:\\untitled\\guaziershou\\guaziershou_data.xlsx\') df.name="瓜子二手车信息" df.head()
2.2删除无效列
#删除无效列 df.drop(\'biansu\',axis=1,inplace=True) df.head()

2.3数据重复值处理
#数据重复值处理 df.duplicated()
2.4删除重复值
#删除重复值 df =df.drop_duplicates() df.tail()
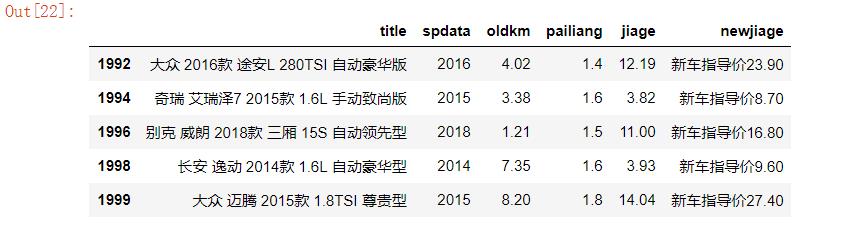
2.5对数据进行空值处理
#对数据进行空值处理 df[\'newjiage\'].isnull().value_counts()

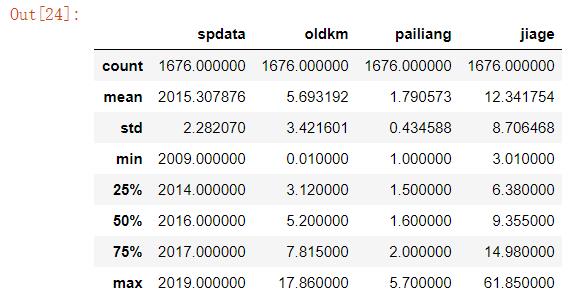
2.6异常值处理
#异常值处理 df.describe()
3.数据分析与可视化
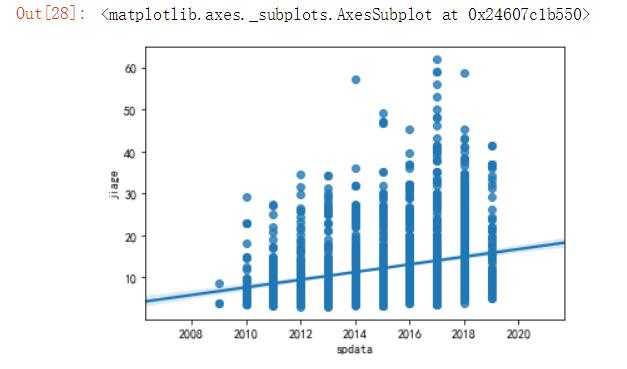
3.1用regplot方法绘制回归图
#绘制回归图,并构建数据分析模型 import seaborn as sns import pandas as pd #用数据分析模型查看上牌时间和价格之间的分布情况 import matplotlib.pyplot as plt df=pd.read_excel(r\'E:\\untitled\\guaziershou\\guaziershou_data.xlsx\') plt.rcParams[\'font.sans-serif\']=[\'SimHei\'] plt.rcParams[\'axes.unicode_minus\'] = False sns.regplot( df.spdata,df.jiage)
3.2查看表显里程和价格之间的分布情况
#用数据分析模型查看表显里程和价格之间的分布情况 import seaborn as sns import pandas as pd import matplotlib.pyplot as plt df=pd.read_excel(r\'E:\\untitled\\guaziershou\\guaziershou_data.xlsx\') plt.rcParams[\'font.sans-serif\']=[\'SimHei\'] plt.rcParams[\'axes.unicode_minus\'] = False sns.regplot( df.oldkm,df.jiage)

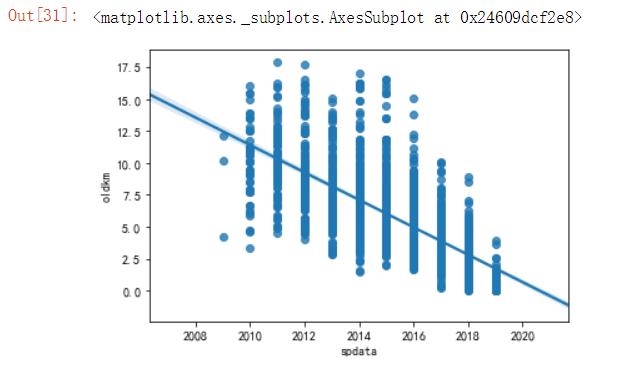
3.3查看上牌时间和表显里程之间的分布情况
#用数据分析模型查看上牌时间和表显里程之间的分布情况 import seaborn as sns import pandas as pd import matplotlib.pyplot as plt df=pd.read_excel(r\'E:\\untitled\\guaziershou\\guaziershou_data.xlsx\') plt.rcParams[\'font.sans-serif\']=[\'SimHei\'] plt.rcParams[\'axes.unicode_minus\'] = False sns.regplot( df.spdata,df.oldkm)
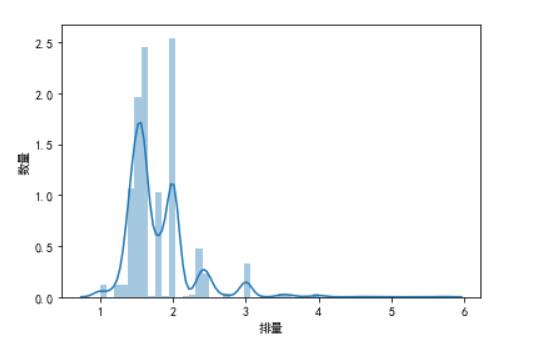
3.4查看汽车排量情况的分布
#查看汽车排量情况的分布 import pandas as pd df = pd.read_excel(r\'E:\\untitled\\guaziershou\\guaziershou_data.xlsx\') df[\'pailiang\'].value_counts()
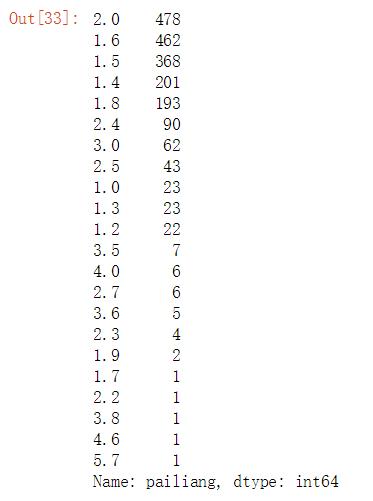
#根据排量情况绘图 import pandas as pd import numpy as np import matplotlib.pyplot as plt plt.rcParams[\'font.sans-serif\']=[\'SimHei\'] plt.rcParams[\'axes.unicode_minus\'] = False plt.ylabel(\'数量\') plt.xlabel(\'排量\') plt.bar([\'1.4T\',\'1.5T\',\'1.6T\',\'1.8T\',\'2.0T\'],[201,368,462,193,478]) plt.show() plt.ylabel(\'数量\') plt.xlabel(\'排量\') plt.xticks(range(0,24,1),rotation=70) plt.bar(["1.0T","1.2T","1.3T","1.4T","1.5T","1.6T","1.7T","1.8T","1.9T","2.0T","2.2T","2.3T","2.4T","2.5T","2.7T","3.0T","3.5T","3.6T","3.8T","4.0T","4.6T","5.7T"],[23,22,23,201,368,462,1,193,2,478,1,4,90,43,6,62,7,5,1,6,1,1]) plt.show() plt.ylabel(\'数量\') x = pd.Series(df[\'pailiang\'], name="排量") ax = sns.distplot(x) plt.show()

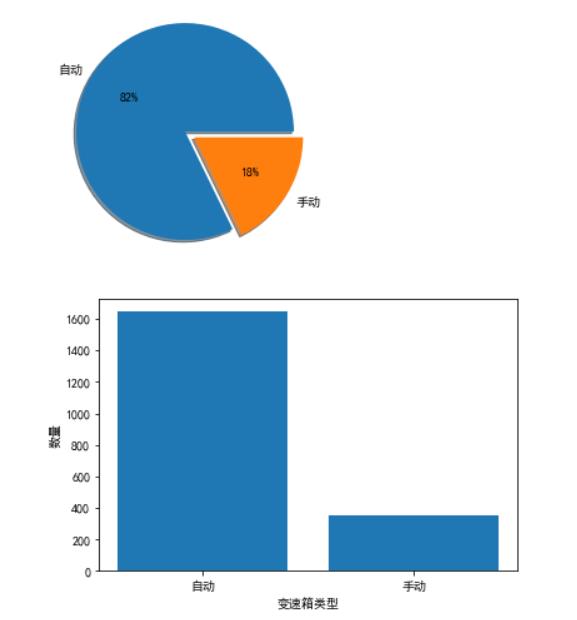
3.5查看变速箱类型的分布情况
#查看变速箱类型的分布情况 import pandas as pd df = pd.read_excel(r\'E:\\untitled\\guaziershou\\guaziershou_data.xlsx\') df[\'biansu\'].value_counts()
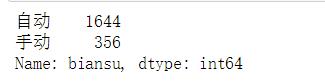
#绘制变速箱类型的统计情况图 import matplotlib.pyplot as plt import pandas as pd import matplotlib.pyplot as plt plt.rcParams[\'font.sans-serif\']=[\'SimHei\'] df = pd.read_excel(r\'E:\\untitled\\guaziershou\\guaziershou_data.xlsx\') labes=[\'自动\',\'手动\'] fracs=[1644,356] explode=[0,0.1] plt.pie(x=fracs,labels=labes,autopct="%.0f%%",explode=explode,shadow=True) plt.show() plt.rcParams[\'axes.unicode_minus\'] = False plt.ylabel(\'数量\') plt.xlabel(\'变速箱类型\') plt.bar([\'自动\',\'手动\'],[1644,356]) plt.show()
4.数据持久化
5.源代码
#!/usr/bin/python3 #_*_coding:utf-8 _*_ #@Author:zhuangqiyuan #@title:瓜子二手车数据的爬取和分析 #导入包 import requests from lxml import etree from bs4 import BeautifulSoup from pandas import DataFrame import os page=1 #添加标识请求头 headers ={ \'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400\', \'Cookie\': \'uuid=8bcc429c-029f-4d45-8de8-f88fb0ca2c78; cityDomain=quanzhou; user_city_id=79; ganji_uuid=3211364230579822430047; lg=1; antipas=58B0581931382V16140z6Q; clueSourceCode=%2A%2300; preTime=%7B%22last%22%3A1575860416%2C%22this%22%3A1575789163%2C%22pre%22%3A1575789163%7D; sessionid=276e0d0e-d04f-4bea-f47d-41826a7e8721; cainfo=%7B%22ca_a%22%3A%22-%22%2C%22ca_b%22%3A%22-%22%2C%22ca_s%22%3A%22seo_baidu%22%2C%22ca_n%22%3A%22default%22%2C%22ca_medium%22%3A%22-%22%2C%22ca_term%22%3A%22-%22%2C%22ca_content%22%3A%22-%22%2C%22ca_campaign%22%3A%22-%22%2C%22ca_kw%22%3A%22%22%2C%22ca_i%22%3A%22-%22%2C%22scode%22%3A%22-%22%2C%22keyword%22%3A%22-%22%2C%22ca_keywordid%22%3A%22-%22%2C%22display_finance_flag%22%3A%22-%22%2C%22platform%22%3A%221%22%2C%22version%22%3A1%2C%22client_ab%22%3A%22-%22%2C%22guid%22%3A%228bcc429c-029f-4d45-8de8-f88fb0ca2c78%22%2C%22ca_city%22%3A%22quanzhou%22%2C%22sessionid%22%3A%226b581614-2868-43a0-d015-508d9830fd27%22%7D; Hm_lvt_936a6d5df3f3d309bda39e92da3dd52f=1575789164,1575793823,1575860415; Hm_lpvt_936a6d5df3f3d309bda39e92da3dd52f=1575860415; close_finance_popup=2019-12-09\' } #csv文件命名 file_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), \'guaziershou_data.csv\') #定义获取li标签下详情页面url的函数 def get_detail_urls(url): # 获取页面数据 resp = requests.get(url, headers=headers) text = resp.content.decode(\'utf-8\') # print(text) # 解析网页 html = etree.HTML(text) # print(html) #获取网页下的ul标签 ul=html.xpath(\'//ul[@class="carlist clearfix js-top"]\')[0] # print(ul) #获取ul标签下的全部li标签 lis = ul.xpath(\'./li\') # print(lis) detail_urls = [] #循环获取li标签下的所有详细页面的url for li in lis: detail_url = li.xpath(\'./a/@href\') detail_url = \'https://www.guazi.com\' + detail_url[0] # print(detail_url) detail_urls.append(detail_url) return detail_urls #定义获取详情页面数据的函数 def xiangxi_url(url): text = requests.get(url, headers=headers) resp = text.content.decode(\'utf-8\') html = etree.HTML(resp) # print(html) # 根据xpath语法规则编写程序,获取车辆的名称 title = html.xpath(\'//div[@class="product-textbox"]/h2/text()\')[0] title = title.replace(r\'\\r\\n\', \'\').strip() # print(title) title1=title.split(r\' \') print(title) #定义一个字典用于存放表格标题 infos ={} #获取二手车辆的上牌时间 shangpai = html.xpath(\'//ul[@class="assort clearfix"]/li/span/text()\')[0] # print(shangpai) shangpai1 =shangpai.split(r\'-\') #进行数据分割,获取需要数据 spdata=shangpai1[0] print(spdata) #获取二手车辆的表显里程信息 biaoxian = html.xpath(\'//ul[@class="assort clearfix"]/li/span/text()\')[1] # print(biaoxian) biaoxian1=biaoxian.split(r\'万\') oldkm=biaoxian1[0] print(oldkm) #获取二手车辆的排量情况 pailiang = html.xpath(\'//ul[@class="assort clearfix"]/li/span/text()\')[2] print(pailiang) #获取二手车辆的变速箱类型(自动/手动) biansu = html.xpath(\'//ul[@class="assort clearfix"]/li/span/text()\')[3] print(biansu) #获取二手车辆的价格 jiage = html.xpath(\'//span[@class="pricestype"]/text()\')[0] # print(jiage) jiage1 = jiage.split(r\'¥\') # print(jiage1) jiage2 = jiage1[1] print(jiage2) #获取二手车辆的新车指导价格 newjiage = html.xpath(\'//span[@class="newcarprice"]/text()\')[0] newjiage = newjiage.replace(r\'\\r\\n\', \'\').strip() # print(newjiage) newjiage1 = newjiage.split(r\'万\') # print(newjiage1) newjiage2 = newjiage1[0] print(newjiage2) infos[\'title\']=title infos[\'spdata\'] = spdata infos[\'oldkm\'] = oldkm infos[\'pailiang\'] = pailiang infos[\'biansu\'] = biansu infos[\'jiage\'] = jiage2 infos[\'newjiage\'] =newjiage2 df = DataFrame(infos, index=[0]) return infos def main(): base_url = \'https://www.guazi.com/quanzhou/buy/o{}/\' # 循环实现翻页效果 for x in range(1,50): url=base_url.format(x) # 调用get_detail_urls函数获取详情页面的全部url detail_urls = get_detail_urls(url) # print(detail_urls) #遍历详情页面的url,并调用xiangxi_url函数获取需要的信息 for detail_url in detail_urls: infos=xiangxi_url(detail_url) df = DataFrame(infos, index=[0]) if os.path.exists(file_path): #写入数据保存,字符编码采用utf-8 df.to_csv(file_path, header=False, index=False, mode="a+", encoding="utf_8_sig") else: df.to_csv(file_path, index=False, mode="w+", encoding="utf_8_sig") # 程序执行时调用主程序main() if __name__ == \'__main__\': main()
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
(1)二手车上牌的时间越早,车的价格越低,表显里程数越大;
(2)二手车排量集中分布于1.4T-2.0T,这说明市场主流的排量是1.4-2.0T范围;
(3)二手车的变速箱类型分自动和手动,其中自动类型的车占比较高,说明大部分人更青睐自动挡;
(4)二手车的价格普遍分布在6-9万左右,表显里程分布在4万公里左右。
2.对本次程序设计任务完成的情况做一个简单的小结。
本次作业遇见了好几个问题,给我留下最深印象的就是处理反爬问题。我在爬取数据的过程中总是报错(IndexError: list index out of range),开始的时候我去搜索了这个错误,但是网上的解释都是关于空元素等的,这与我的情况不相符合,最后通过查询资料得知,一些网站 以上是关于Python高级应用程序设计任务的主要内容,如果未能解决你的问题,请参考以下文章