Python高级应用程序设计任务
Posted 毛雨捷
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python高级应用程序设计任务相关的知识,希望对你有一定的参考价值。
Python高级应用程序设计任务要求
用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
携程旅游页面景点信息爬取和分析
2.主题式网络爬虫爬取的内容与数据特征分析
获取携程旅游页面的景点信息,包括景点名称、景点地址、景点评级、景点评分、景点点评数量、景点价格等信息
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
实现思路:
(1)利用requests库中进行get请求,获得旅游页面响应内容。
(2)使用bs4解析库进行网页解析,从旅游页面响应内容中提取景点信息。
(3)使用xlwt模块将数据保存到excel文件中,实现数据可持久化。
技术难点:
(1)破解携程网反爬处理
(2)解决携程网信息乱码问题
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
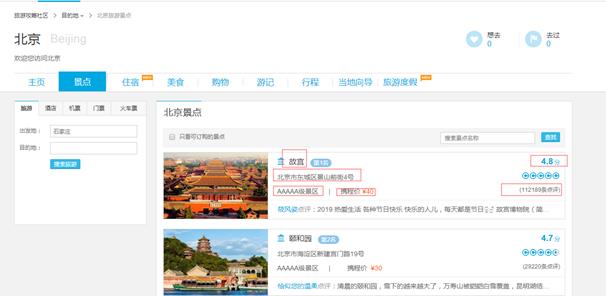
2.Htmls页面解析

3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
使用bs4解析库的find_all方法获取特定class值的网页标签元素,使用text方法获取网页标签元素中的文本信息。
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
import requests import json import pickle from bs4 import BeautifulSoup import time import xlwt global rest rest=[] \'\'\'携程国内旅游景点爬虫\'\'\' def SightSpider(): print(\'[INFO]:正在爬取北京景点信息....\') #构造请求头和请求url headers = {\'User-Agent\': \'user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36\'} url = \'https://you.ctrip.com/sight/beijing1/s0-p%s.html#sightname\' #爬取网页页数 max_pages = 10 page_count = 1 results = {} while True: #发送request的get请求,获得旅游页面响应 res = requests.get(url % page_count, headers=headers) #使用bs4解析库解析响应页面 soup = BeautifulSoup(res.text, features=\'lxml\') list_wide_mod2 = soup.find_all(\'div\', class_=\'list_wide_mod2\')[0] for each1, each2,each3 in zip(list_wide_mod2.find_all(\'dl\'), list_wide_mod2.find_all(\'ul\', class_=\'r_comment\'),list_wide_mod2.find_all(\'p\', class_=\'bottomcomment\')): #获得景点名称 name = each1.dt.a.text #获得景点地址 addr = each1.find_all(\'dd\')[0].text.strip() #获得景点评级以及评级信息处理 level = each1.find_all(\'dd\')[1].text.strip().split(\'|\')[0].strip() if \'携程\' in level: level = \'\' #获得景点价格以及价格信息处理 try: price = each1.find_all(\'span\', class_=\'price\')[0].text.strip().replace(\'¥\', \'\') except: price = \'\' #获得景点评分 score = each2.find_all(\'a\', class_=\'score\')[0].text.strip().replace(\'\\xa0分\', \'\') #获得景点点评数量 num_comments = each2.find_all(\'a\', class_=\'recomment\')[0].text.strip()[1: -3] results[name] = [addr, level, price, score, num_comments] rest.append([name,addr, level,score, price,num_comments]) page_count += 1 print(\'[INFO]:爬取进度: %s/%s...\' % (page_count-1, max_pages)) time.sleep(10) if page_count == max_pages: break print(\'[INFO]:数据爬取完毕, 保存在sight.xls中...\') WriteExcel(rest) #景点信息保存至data.pkl以便后续数据分析 with open(\'data.pkl\', \'wb\') as f: pickle.dump(results, f) #将爬取到存储到Excel中 def WriteExcel(slist): #创建一个workbook Workbook = xlwt.Workbook() #在workbook中新建一个名字为sight.xls文件 sheet = Workbook.add_sheet(\'携程景点\') infos = [\'名称\',\'地址\',\'评级\',\'评分\',\'价格\',\'评论数\'] #定义输出格式,及放置在哪一行哪一列 for i in range(0, len(infos) + 0): sheet.write(0, i, infos[i - 0]) for i in range(1, len(slist) + 1): sheet.write(i, 0, slist[i - 1][0]) sheet.write(i, 1, slist[i - 1][1]) sheet.write(i, 2, slist[i - 1][2]) sheet.write(i, 3, slist[i - 1][3]) sheet.write(i, 4, slist[i - 1][4]) sheet.write(i, 5, slist[i - 1][5]) Workbook.save(\'sight.xls\') if __name__ == \'__main__\': SightSpider()
2.对数据进行清洗和处理
清洗前数据:
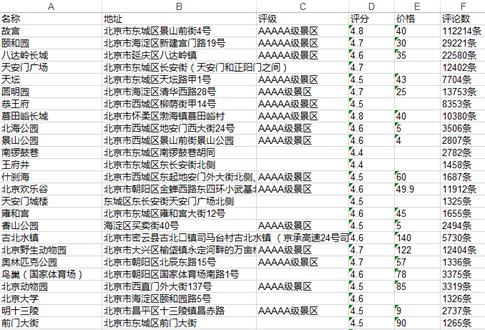
def clean(): sights = pd.DataFrame(pd.read_excel(r\'sight.xls\')) #删除数据表中的重复值 sights = sights .drop_duplicates() #对数据库表的数据进行空值处理 sights = sights.fillna(\'unknown\') sights.to_excel(\'sight.xls\') if __name__ == \'__main__\': #SightSpider() clean() #drawPic()
清洗后数据:
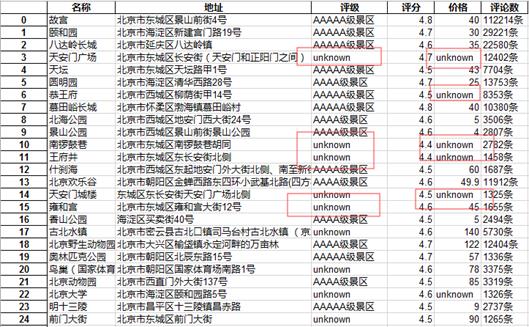
3.文本分析(可选):jieba分词、wordcloud可视化
#绘制词云 def drawWordCloud(words, title, savepath=\'./results\'): if not os.path.exists(savepath): os.mkdir(savepath) wc = WordCloud(font_path=\'data/simkai.ttf\', background_color=\'white\', max_words=2000, width=1920, height=1080, margin=5) wc.generate_from_frequencies(words) wc.to_file(os.path.join(savepath, title+\'.png\')) #统计词频 def statistics(texts, stopwords): words_dict = {} for text in texts: temp = jieba.cut(text) for t in temp: if t in stopwords or t == \'unknown\': continue if t in words_dict.keys(): words_dict[t] += 1 else: words_dict[t] = 1 return words_dict #根据景点地址绘制词云 def drawPic(): with open(\'data.pkl\', \'rb\') as f: all_data = pickle.load(f) stopwords = open(\'stopwords.txt\', \'r\', encoding=\'utf-8\').read().split(\'\\n\')[:-1] texts = [each[1][0] for each in all_data] words_dict = statistics(texts, stopwords) drawWordCloud(words_dict, \'景点地址词云\', savepath=\'./results\')

4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
#绘制柱状图(2维) def drawBar(title, data, savepath=\'./results\'): if not os.path.exists(savepath): os.mkdir(savepath) bar = Bar(title, title_pos=\'center\') attrs = [i for i, j in data.items()] values = [j for i, j in data.items()] bar.add(\'\', attrs, values, xaxis_rotate=15, yaxis_rotate=10) bar.render(os.path.join(savepath, \'%s.html\' % title)) #根据评论量绘制热门景区分布柱状图 comments = {} for key, value in all_data.items(): if value[-1] == \'暂无\' or not value[-1]: continue value[-1] = value[-1].replace(\'条\', \'\') if len(comments.keys()) < 6: comments[key] = int(value[-1]) continue if int(value[-1]) > min(list(comments.values())): comments[key] = int(value[-1]) abandoned_key = list(comments.keys())[list(comments.values()).index(min(list(comments.values())))] del comments[abandoned_key] drawBar(\'热门景区分布柱状图\', comments)
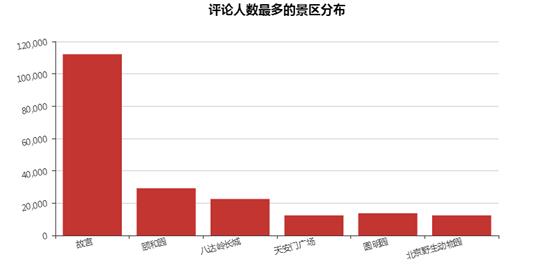
#绘制漏斗图 def drawFunnel(title, data, savepath=\'./results\'): if not os.path.exists(savepath): os.mkdir(savepath) funnel = Funnel(title, title_pos=\'center\') attrs = [i for i, j in data.items()] values = [j for i, j in data.items()] funnel.add("", attrs, values, is_label_show=True, label_pos="inside", label_text_color="#fff", funnel_gap=5, legend_pos="left", legend_orient="vertical") funnel.render(os.path.join(savepath, \'%s.html\' % title)) #根据价格分布绘制漏斗图 prices = {\'50元以下\': 0, \'50-100元\': 0, \'100-200元\': 0, \'200元以上\': 0} for key, value in all_data.items(): if value[2] == \'unknown\' or not value[2]: continue price = float(value[2]) if price < 50: prices[\'50元以下\'] += 1 elif price >= 50 and price < 100: prices[\'50-100元\'] += 1 elif price >= 100 and price < 200: prices[\'100-200元\'] += 1 elif price >= 200: prices[\'200元以上\'] += 1 drawFunnel(\'景区价格分布\', prices)
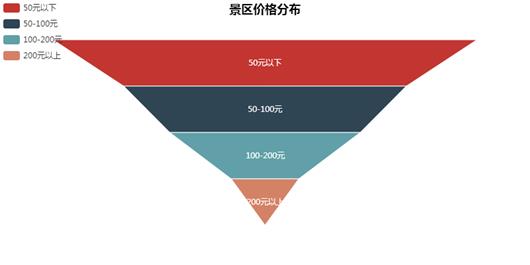
#绘制饼图 def drawPie(title, data, savepath=\'./results\'): if not os.path.exists(savepath): os.mkdir(savepath) pie = Pie(title, title_pos=\'center\') attrs = [i for i, j in data.items()] values = [j for i, j in data.items()] pie.add(\'\', attrs, values, is_label_show=True, legend_orient="vertical", legend_pos="left", radius=[30, 75], rosetype="area") pie.render(os.path.join(savepath, \'%s.html\' % title)) #根据评分绘制饼图 scores = {} for key, value in all_data.items(): if value[3] in scores: scores[value[3]] += 1 else: scores[value[3]] = 1 drawPie(\'景区评分分布\', scores)
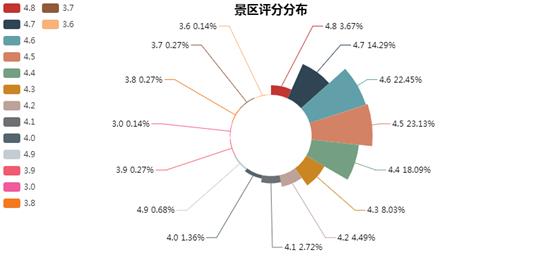
5.数据持久化
#将爬取到存储到Excel中 def WriteExcel(slist): #创建一个workbook Workbook = xlwt.Workbook() #在workbook中新建一个名字为sight.xls文件 sheet = Workbook.add_sheet(\'携程景点\') infos = [\'名称\',\'地址\',\'评级\',\'评分\',\'价格\',\'评论数\'] #定义输出格式,及放置在哪一行哪一列 for i in range(0, len(infos) + 0): sheet.write(0, i, infos[i - 0]) for i in range(1, len(slist) + 1): sheet.write(i, 0, slist[i - 1][0]) sheet.write(i, 1, slist[i - 1][1]) sheet.write(i, 2, slist[i - 1][2]) sheet.write(i, 3, slist[i - 1][3]) sheet.write(i, 4, slist[i - 1][4]) sheet.write(i, 5, slist[i - 1][5]) Workbook.save(\'sight.xls\')
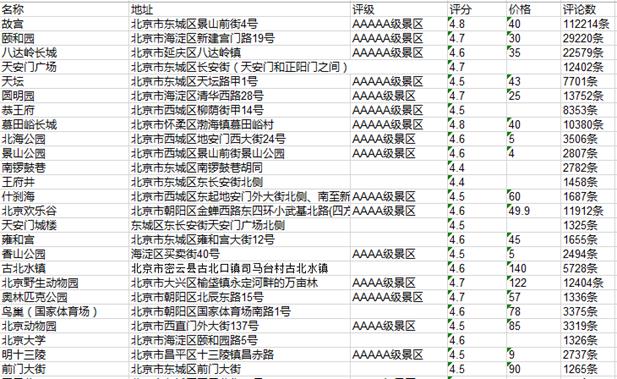
6.附完整程序代码
import requests import json import pickle from bs4 import BeautifulSoup import time import csv import os import pandas as pd import jieba from pyecharts import Bar from pyecharts import Pie from pyecharts import Funnel from wordcloud import WordCloud global rest rest=[] \'\'\'携程国内旅游景点爬虫\'\'\' def SightSpider(): print(\'[INFO]:正在爬取北京景点信息....\') #构造请求头和请求url headers = {\'User-Agent\': \'user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36\'} url = \'https://you.ctrip.com/sight/beijing1/s0-p%s.html#sightname\' #爬取网页页数 max_pages = 100 page_count = 1 results = {} while True: #发送request的get请求,获得旅游页面响应 res = requests.get(url % page_count, headers=headers) #使用bs4解析库解析响应页面 soup = BeautifulSoup(res.text, features=\'lxml\') list_wide_mod2 = soup.find_all(\'div\', class_=\'list_wide_mod2\')[0] for each1, each2,each3 in zip(list_wide_mod2.find_all(\'dl\'), list_wide_mod2.find_all(\'ul\', class_=\'r_comment\'),list_wide_mod2.find_all(\'p\', class_=\'bottomcomment\')): #获得景点名称 name = each1.dt.a.text #获得景点地址 addr = each1.find_all(\'dd\')[0].text.strip() #获得景点评级以及评级信息处理 level = each1.find_all(\'dd\')[1].text.strip().split(\'|\')[0].strip() if \'携程\' in level: level = \'\' #获得景点价格以及价格信息处理 try: price = each1.find_all(\'span\', class_=\'price\')[0].text.strip().replace(\'¥\', \'\') except: price = \'\' #获得景点评分 score = each2.find_all(\'a\', class_=\'score\')[0].text.strip().replace(\'\\xa0分\', \'\') #获得景点点评数量 num_comments = each2.find_all(\'a\', class_=\'recomment\')[0].text.strip()[1: -3] results[name] = [addr, level, price, score, num_comments] data={\'名称\':name,\'地址\':addr,\'评级\':level,\'评分\':score,\'价格\':price,\'评论数\':num_comments} rest.append([name,addr, level, score, price, num_comments]) page_count += 1 print(\'[INFO]:爬取进度: %s/%s...\' % (page_count-1, max_pages)) time.sleep(10) if page_count == max_pages: break print(\'[INFO]:数据爬取完毕, 保存在sight.csv中...\') write_info_xls(rest) #景点信息保存至data.pkl以便后续数据分析 with open(\'data.pkl\', \'wb\') as f: pickle.dump(results, f) #将爬取到存储到Excel中 def write_info_xls(slist): #创建一个workbook Workbook = xlwt.Workbook() #在workbook中新建一个名字为sight.xls文件 sheet = Workbook.add_sheet(\'携程景点\') infos = [\'名称\',\'地址\',\'评级\',\'评分\',\'价格\',\'评论数\'] #定义输出格式,及放置在哪一行哪一列 for i in range(0, len(infos) + 0): sheet.write(0, i, infos[i - 0]) for i in range(1, len(slist) + 1): sheet.write(i, 0, slist[i - 1][0]) sheet.write(i, 1, slist[i - 1][1]) sheet.write(i, 2, slist[i - 1][2]) sheet.write(i, 3, slist[i - 1][3]) sheet.write(i, 4, slist[i - 1][4]) sheet.write(i, 5, s[i - 1][5]) Workbook.save(\'sight.xls\') \'\'\'使用pyecharts对景点数据进行分析及可视化\'\'\' #绘制柱状图(2维) def drawBar(title, data, savepath=\'./results\'): if not os.path.exists(savepath): os.mkdir(savepath) bar = Bar(title, title_pos=\'center\') attrs = [i for i, j in data.items()] values = [j for i, j in data.items()] bar.add(\'\', attrs, values, xaxis_rotate=15, yaxis_rotate=10) bar.render(os.path.join(savepath, \'%s.html\' % title)) #绘制饼图 def drawPie(title, data, savepath=\'./results\'): if not os.path.exists(savepath): os.mkdir(savepath) pie = Pie(title, title_pos=\'center\') attrs = [i for i, j in data.items()] values = [j for i, j in data.items()] pie.add(\'\', attrs, values, is_label_show=True, legend_orient="vertical", legend_pos="left", radius=[30, 75], rosetype="area") pie.render(os.path.join(savepath, \'%s.html\' % title)) #绘制漏斗图 def drawFunnel(title, data, savepath=\'./results\'): if not os.path.exists(savepath): os.mkdir(savepath) funnel = Funnel(title, title_pos=\'center\') attrs = [i for i, j in data.items()] values = [j for i, j in data.items()] funnel.add("", attrs, values, is_label_show=True, label_pos="inside", label_text_color="#fff", funnel_gap=5, legend_pos="left", legend_orient="vertical") funnel.render(os.path.join(savepath, \'%s.html\' % title)) #绘制词云 def drawWordCloud(words, title, savepath=\'./results\'): if not os.path.exists(savepath): os.mkdir(savepath) wc = WordCloud(font_path=\'data/simkai.ttf\', background_color=\'white\', max_words=2000, width=1920, height=1080, margin=5) wc.generate_from_frequencies(words) wc.to_file(os.path.join(savepath, title+\'.png\'))以上是关于Python高级应用程序设计任务的主要内容,如果未能解决你的问题,请参考以下文章