Python高级应用程序设计任务
Posted 星辰_雨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python高级应用程序设计任务相关的知识,希望对你有一定的参考价值。
Python高级应用程序设计任务要求
用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
一、主题式网络爬虫设计方案(15分)1.主题式网络爬虫名称
名称:爬取58同城房产租售信息
2.主题式网络爬虫爬取的内容与数据特征分析
这次爬虫主要是爬取58同城泉州区域的房屋交易价格和房屋信息。
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
实现思路:获取58同城目标的HTML页面,使用requests爬取数据,BeautifulSoup解析页面,使用records进行数据存储、读取,最后打印出来数据
技术难点:爬取数据,遍历标签属性。存储数据表格信息
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
1.主题页面的结构特征
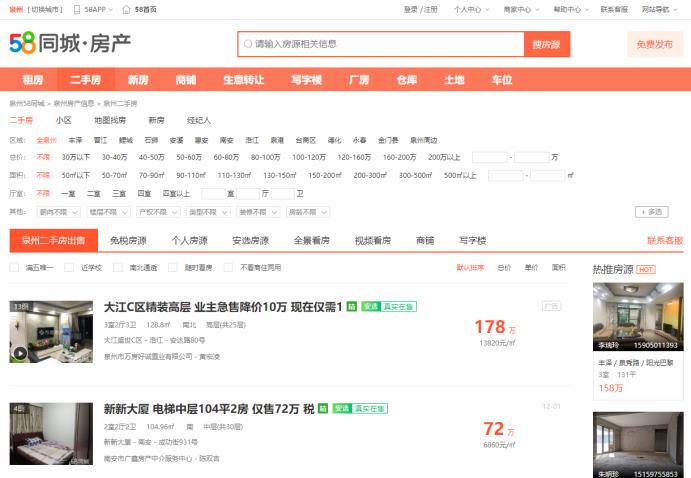

2.Htmls页面解析
用鼠标右键点击查看“查看元素”选项或者按“F12”

3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
查找:select函数

遍历:for循环嵌套
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集

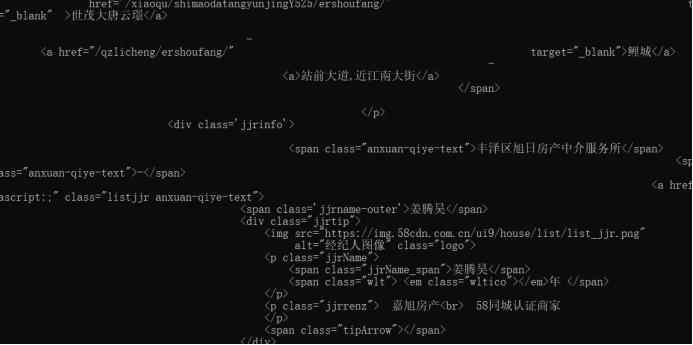
2.对数据进行清洗和处理

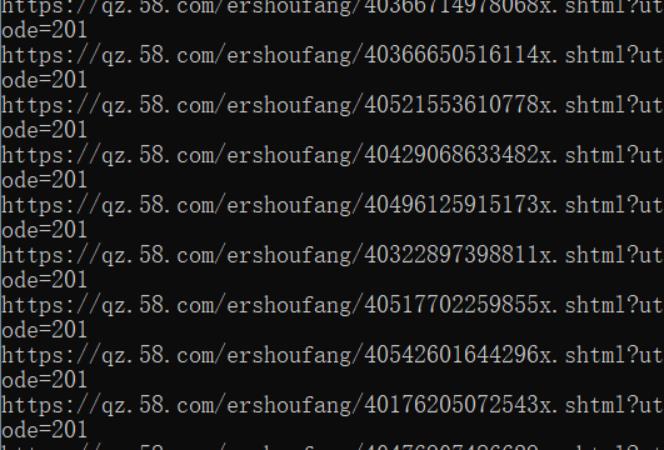
3.文本分析(可选):jieba分词、wordcloud可视化
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)

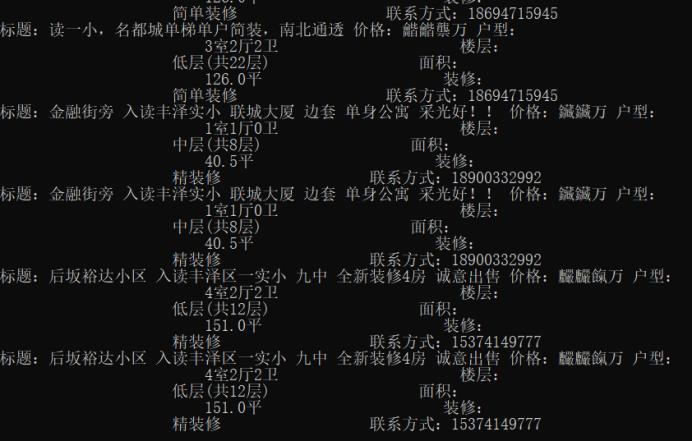
5.数据持久化


6.附完整程序代码
import requests
from bs4 import BeautifulSoup
import records
def getHtml(url):
\'\'\'
获取目标网页数据
\'\'\'
try:
# 伪装UA
ua = {\'user-agent\': \'Mozilla/5.0 Chrome/79.0.3945.88 Safari/537.36\'}
# 读取网页
r = requests.get(url, headers=ua)
# 获取状态
r.raise_for_status()
# 打印数据 print(r.text)
# 返回数据
return r.text
except:
return "Fail"
def parseHtml(html):
\'\'\'
房屋数据收集
\'\'\'
# 数据数组
data = []
# 结构解析
soup = BeautifulSoup(html, "html.parser")
# 获取具体房屋的链接
titles = soup.select(\'.title a\')
print(titles)
# for循环解析链接
for i in titles:
# 解析href链接属性
a = i.get(\'href\')
# 打印数据 print(a)
# 加入数组
data.append(a)
# 返回数组
return data
def parseInfo(html):
\'\'\'
房屋数据清洗
\'\'\'
# 创建字典
j = {}
# 结构解析
soup = BeautifulSoup(html, "html.parser")
# 获取房屋标题
titles = soup.select(\'.f20\')[0].get_text()
# 获取房屋价格
price = soup.select(\'.house-basic-info .price\')[0].get_text()
# 获取房屋户型
huxing = soup.select(\'.house-basic-info .room .main\')[0].get_text()
# 获取房屋楼层
louceng = soup.select(\'.house-basic-info .room .sub\')[0].get_text()
# 获取房屋面积
mianji = soup.select(\'.house-basic-info .area .main\')[0].get_text()
# 获取房屋装修
maopi = soup.select(\'.house-basic-info .area .sub\')[0].get_text()
# 获取联系电话
phone = soup.select(\'.phone-num\')[0].get_text()
# 组合数据
sj = \'标题:%s 价格:%s 户型:%s 楼层:%s 面积:%s 装修:%s 联系方式:%s \'%(titles,price,huxing,louceng,mianji,maopi,phone)
# 打印数据
print(sj)
# 字典
j[\'标题\'] = titles
j[\'价格\'] = price
j[\'户型\'] = huxing
j[\'楼层\'] = louceng
j[\'面积\'] = mianji
j[\'装修\'] = maopi
j[\'联系\'] = phone
# 返回字典
return j
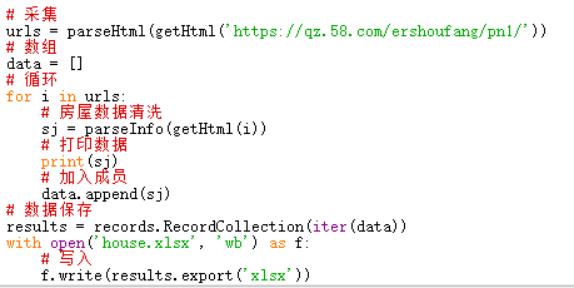
# 采集
urls = parseHtml(getHtml(\'https://qz.58.com/ershoufang/pn1/\'))
# 数组
data = []
# 循环
for i in urls:
# 房屋数据清洗
sj = parseInfo(getHtml(i))
# 打印数据 print(sj)
# 加入成员
data.append(sj)
# 数据保存
results = records.RecordCollection(iter(data))
with open(\'house.xlsx\', \'wb\') as f:
# 写入
f.write(results.export(\'xlsx\'))
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
1.经过对主题数据的分析与可视化,可以得到哪些结论?
可以很直观的找到心仪的租房户型,位置,价格,面积。
2.对本次程序设计任务完成的情况做一个简单的小结。
2.对本次程序设计任务完成的情况做一个简单的小结。
首先思路要清晰,不然很容易卡着,做完这步,不懂下步怎么做;其次,通过使用requests爬取数据,BeautifulSoup解析页面......让我对爬虫的认识又深刻了,对它更加“熟悉”了。同时,又巩固了之前所学的知识;最后,我觉得,学习爬虫真的很值,可以很直观,很快速的,帮你把你想要的数据提取出来。节省了我们大量的时间。
以上是关于Python高级应用程序设计任务的主要内容,如果未能解决你的问题,请参考以下文章