python高级应用程序设计任务
Posted 周倩倩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python高级应用程序设计任务相关的知识,希望对你有一定的参考价值。
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
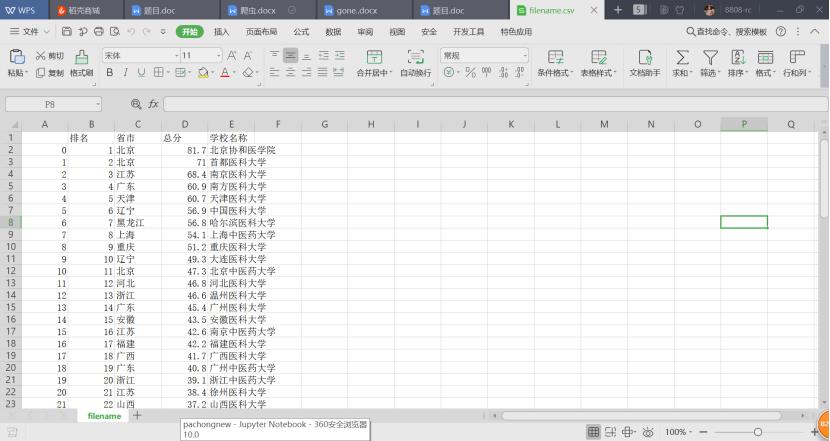
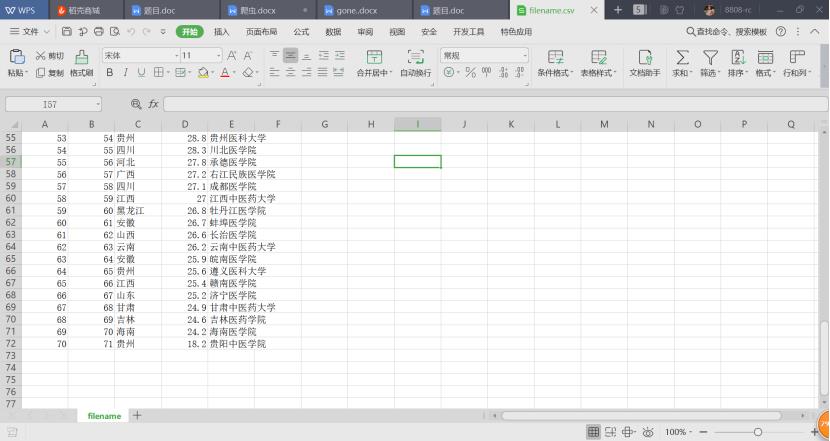
软科中国最好医科大学排名2019,爬取中国最好医科大学排名、学校名称、省市、总分、指标得分(生源质量(新生高考成绩得分))等信息
2.主题式网络爬虫爬取的内容与数据特征分析
爬取内容:爬取中国最好医科大学排名、学校名称、省市、总分、指标得分(生源质量(新生高考成绩得分))等信息
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
本案例使用requests库获取网页数据,使用beautifulSoup库解析页面内容,再使用pandas库把爬取的数据输出
技术难点:数据清洗过程,使用beautifulSoup库对爬取到的页面进行数据提取的过程
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
页面内容如下,本方案要爬取的是表格中的内容。
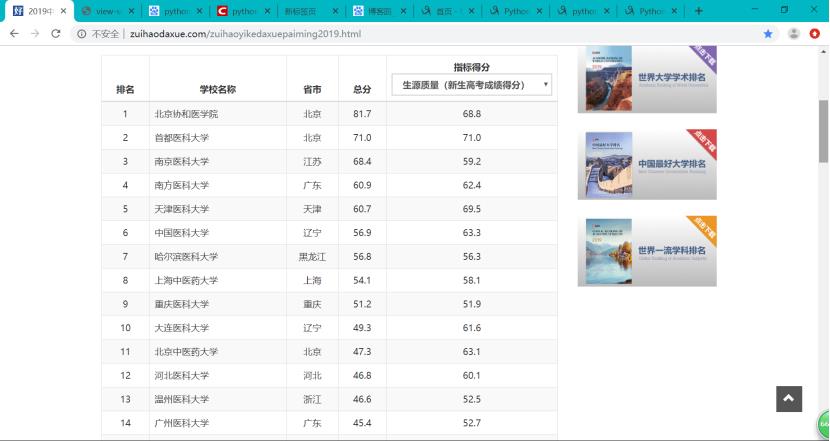
2.Htmls页面解析
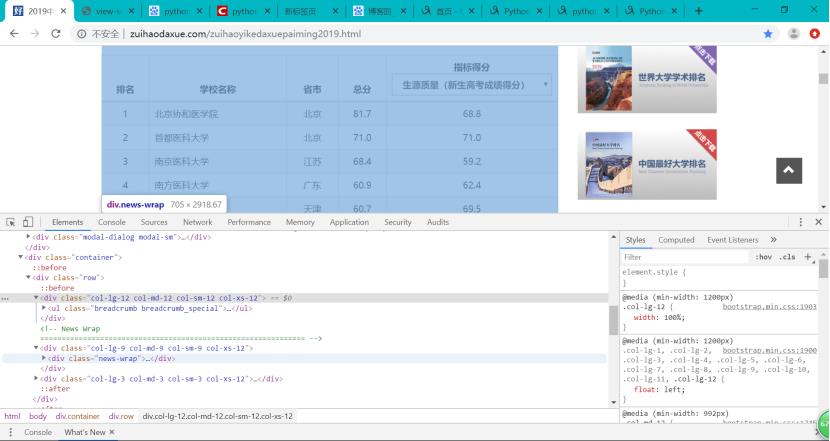
通过F12,对页面进行检查,查看我们所需要爬取内容的相关代码。
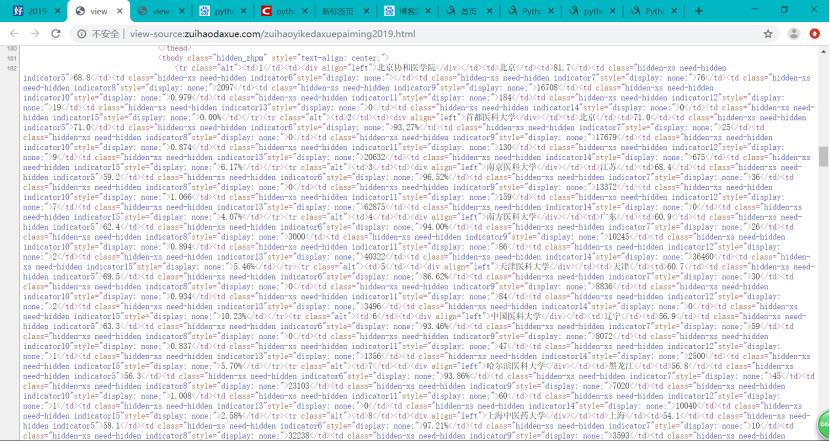
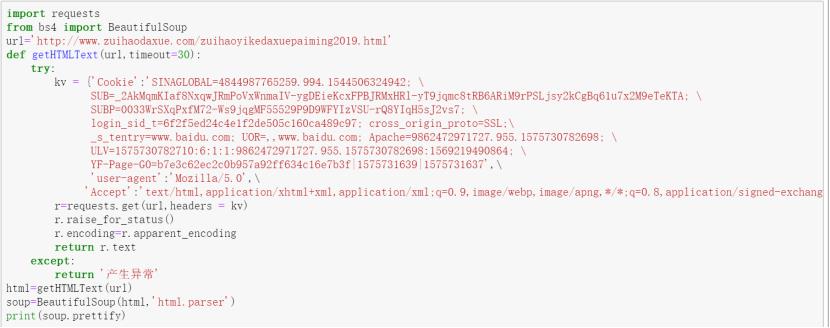
通过requests.get(url)向服务器提交请求,用soup.prettify()方法输出代码:
3.节点(标签)查找方法与遍历方法
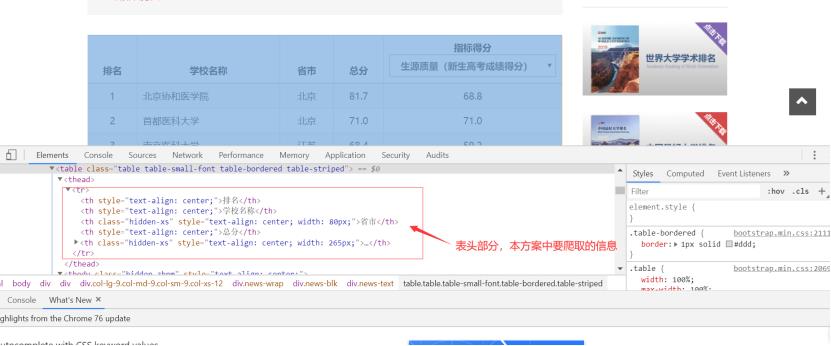
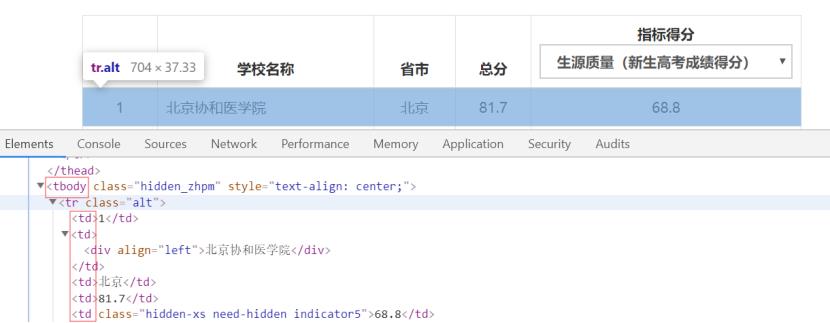
分析html代码,做个简要的分析,如下图:
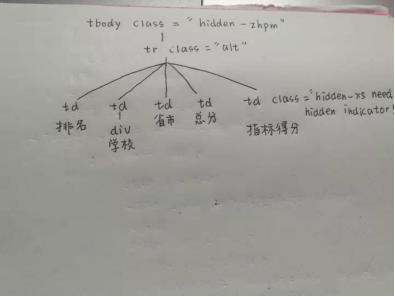
可以看到每一个学校的数据都放在一个tr(行)里,排名放在tr的第一个td(单元格)中,学校名称放在tr的第二个td中,省市放在tr的第三个td中,总分放在tr的第四个td中,指标得分放在tr的第五个td中。
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分:数据抓取及解析、数据提取、保存数据。
(1)数据抓取及解析
用requests抓取网页信息,采用了异常捕捉技术,在程序异常时返回提示信息。
import requests from bs4 import BeautifulSoup url=\'http://www.zuihaodaxue.com/zuihaoyikedaxuepaiming2019.html\' def getHTMLText(url): try: kv = {\'Cookie\':\'SINAGLOBAL=4844987765259.994.1544506324942; \\ SUB=_2AkMqmKIaf8NxqwJRmPoVxWnmaIV-ygDEieKcxFPBJRMxHRl-yT9jqmc8tRB6ARiM9rPSLjsy2kCgBq61u7x2M9eTeKTA; \\ SUBP=0033WrSXqPxfM72-Ws9jqgMF55529P9D9WFYIzVSU-rQ8YIqH5sJ2vs7; \\ login_sid_t=6f2f5ed24c4e1f2de505c160ca489c97; cross_origin_proto=SSL;\\ _s_tentry=www.baidu.com; UOR=,,www.baidu.com; Apache=9862472971727.955.1575730782698; \\ ULV=1575730782710:6:1:1:9862472971727.955.1575730782698:1569219490864; \\ YF-Page-G0=b7e3c62ec2c0b957a92ff634c16e7b3f|1575731639|1575731637\',\\ \'user-agent\':\'Mozilla/5.0\',\\ \'Accept\':\'textml,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3\'} r=requests.get(url,headers = kv) r.raise_for_status() r.encoding=r.apparent_encoding return r.text except: return \'产生异常\'
(2)数据提取
使用beautifulSoup创建soup对象,用于解析页面内容,用find()找到对应标签,再在标签中遍历元素,将其中的内容添加到temp_list中,最后返回final_list。
html=getHTMLText(url) soup=BeautifulSoup(html,\'html.parser\') # print(soup.prettify) final_list=[] def get_uniInfo(html,final_list): soup=BeautifulSoup(html,\'html.parser\') body=soup.body data=body.find(\'tbody\',{\'class\':\'hidden_zhpm\'}) trs=data.find_all(\'tr\') for uniInfo in trs: temp_list=[] info=uniInfo.find_all(\'td\') #寻找所有的td标签 temp_list.append(info[0].string) #找到td标签下的第一个值(排名) temp_list.append(info[2].string) #找到td标签下的第三个值(省市) temp_list.append(info[3].string) #找到td标签下的第四个值(总分) # print(info[0].string,info[2].string,info[3].string) # temp_list.append([info[0].string,info[2].string,info[3].string]) if info[1].find(\'div\'): #找到td标签下的第二个值(学校名称),带有div,这是学校名称的特有标签 university=info[1].find(\'div\').string temp_list.append(university) if info[4].find(\'td\',{\'class\':\'hidden-xs need-hidden indicator5\'}): #找到td标签下的第五个值(指标得分),带有class,这是指标得分的特有属性 score=info[4].find(\'td\',{\'class\':\'hidden-xs need-hidden indicator5\'}).string #score未爬取到,打印不出来 temp_list.append(score) # temp_list.append([university,score]) # print(temp_list) final_list.append(temp_list) print(final_list) get_uniInfo(html,final_list)
(3)保存数据
使用pandas库将获取到的列表转换为DataFrame对象,再使用to_csv()方法生成指定名称的文件
import pandas as pd # df=pd.DataFrame(final_list,columns=[\'排名\',\'学校名称\',\'省市\',\'总分\',\'指标得分\']) df=pd.DataFrame(final_list,columns=[\'排名\',\'省市\',\'总分\',\'学校名称\']) df.to_csv(\'medical-university.csv\',encoding="utf-8") #指定文件名称
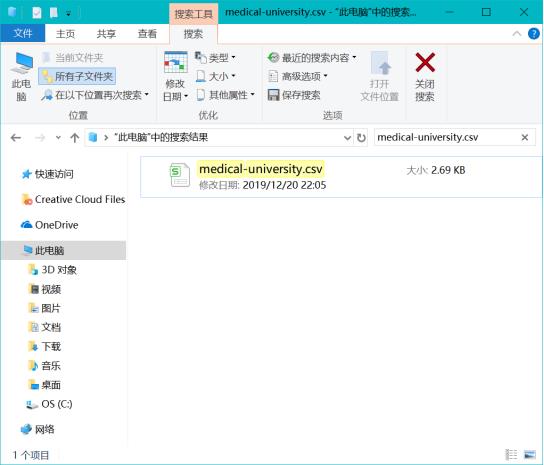
(中间两页内容省略...)
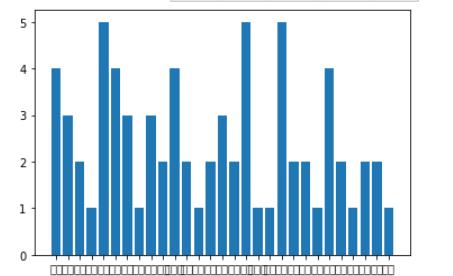
(4)数据可视化(用柱状图反映)
import matplotlib.pyplot as plt import numpy as np plt.figure() plt.bar([\'安徽\',\'北京\',\'福建\',\'甘肃\',\'广东\',\'广西\',\'贵州\',\'海南\',\'河北\',\'河南\',\'黑龙江\',\'湖北\',\'湖南\',\'吉林\',\'江苏\',\'江西\',\'辽宁\',\'内蒙古\',\'宁夏\',\'山东\',\'山西\',\'陕西\',\'上海\',\'四川\',\'天津\',\'新疆\',\'云南\',\'浙江\',\'重庆\'],[4,3,2,1,5,4,3,1,3,2,4,2,1,2,3,2,5,1,1,5,2,2,1,4,2,1,2,2,1]) # 显示图像 plt.show()
完整程序代码:
import requests from bs4 import BeautifulSoup url=\'http://www.zuihaodaxue.com/zuihaoyikedaxuepaiming2019.html\' def getHTMLText(url): try: kv = {\'Cookie\':\'SINAGLOBAL=4844987765259.994.1544506324942; \\ SUB=_2AkMqmKIaf8NxqwJRmPoVxWnmaIV-ygDEieKcxFPBJRMxHRl-yT9jqmc8tRB6ARiM9rPSLjsy2kCgBq61u7x2M9eTeKTA; \\ SUBP=0033WrSXqPxfM72-Ws9jqgMF55529P9D9WFYIzVSU-rQ8YIqH5sJ2vs7; \\ login_sid_t=6f2f5ed24c4e1f2de505c160ca489c97; cross_origin_proto=SSL;\\ _s_tentry=www.baidu.com; UOR=,,www.baidu.com; Apache=9862472971727.955.1575730782698; \\ ULV=1575730782710:6:1:1:9862472971727.955.1575730782698:1569219490864; \\ YF-Page-G0=b7e3c62ec2c0b957a92ff634c16e7b3f|1575731639|1575731637\',\\ \'user-agent\':\'Mozilla/5.0\',\\ \'Accept\':\'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3\'} r=requests.get(url,headers = kv) r.raise_for_status() r.encoding=r.apparent_encoding return r.text except: return \'产生异常\' html=getHTMLText(url) soup=BeautifulSoup(html,\'html.parser\') # print(soup.prettify) final_list=[] def get_uniInfo(html,final_list): soup=BeautifulSoup(html,\'html.parser\') body=soup.body data=body.find(\'tbody\',{\'class\':\'hidden_zhpm\'}) trs=data.find_all(\'tr\') for uniInfo in trs: temp_list=[] info=uniInfo.find_all(\'td\') #寻找所有的td标签 temp_list.append(info[0].string) #找到td标签下的第一个值(排名) temp_list.append(info[2].string) #找到td标签下的第三个值(省市) temp_list.append(info[3].string) #找到td标签下的第四个值(总分) # print(info[0].string,info[2].string,info[3].string) # temp_list.append([info[0].string,info[2].string,info[3].string]) if info[1].find(\'div\'): #找到td标签下的第二个值(学校名称),带有div,这是学校名称的特有标签 university=info[1].find(\'div\').string temp_list.append(university) if info[4].find(\'td\',{\'class\':\'hidden-xs need-hidden indicator5\'}): #找到td标签下的第五个值(指标得分),带有class,这是指标得分的特有属性 score=info[4].find(\'td\',{\'class\':\'hidden-xs need-hidden indicator5\'}).string #score未爬取到,打印不出来 temp_list.append(score) # temp_list.append([university,score]) # print(temp_list) final_list.append(temp_list) print(final_list) get_uniInfo(html,final_list) import pandas as pd # df=pd.DataFrame(final_list,columns=[\'排名\',\'学校名称\',\'省市\',\'总分\',\'指标得分\']) df=pd.DataFrame(final_list,columns=[\'排名\',\'省市\',\'总分\',\'学校名称\']) df.to_csv(\'medical-university.csv\',encoding="utf-8") #指定文件名称
三、结论(10分)
1.经过对主题数据的分析与可视化, 可以得到哪些结论?
经过对数据的分析,可以观察到拥有最多排名最好的医学院的地区是:广东、辽宁、山东,都有5所学校。
2.对本次程序设计任务完成的情况做一个简单的小结。
通过本次程序设计任务,对html知识进行了回顾,也对本学期新学习的爬虫技术进行了学习与巩固。对于我来说,这次作业的核心在于数据清洗这块,需要弄清楚所要爬取的数据具体在哪个标签内,我们需要获取数据就要把数据特有的标签给找到,结合beautifulSoup库,对页面的数据进行提取。在做本次作业的过程中,也遇到很多问题,需要和同学交流解决。通过这次作业,对自己web的学习是一次提升,也对python爬虫技术有了一点了解。存在的问题:有一列内容没有爬取出来,不知道是否与下拉列表有关系,存在好几个class属性值。数据可视化部分,不知道如何将存储好的csv文件数据导入到图像中。
以上是关于python高级应用程序设计任务的主要内容,如果未能解决你的问题,请参考以下文章