Python 高级应用程序设计任务
Posted acolasia9865
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 高级应用程序设计任务相关的知识,希望对你有一定的参考价值。
一.主题式网络爬虫设计方案
1.主题式网络爬虫的名称
爬拥有超级计算机500强的公司和数量
2·主题式网络爬虫的内容与数据特征分析
爬虫的内容:超级计算机500强
数据特征分析:对前500强超级计算机的品牌公司进行分析
3,主题式网络爬虫设计方案概述(包括实现思路和技术难点)
设计方案:创建一个get的类,通过get_page爬取网页,在通过parse_page_detail()获取每个详情页所需要爬取的具体信息数据,最后通过save_to_csv()保存到csv文件中。
技术难点:网址的抓包和正文的提取
二,主题页面的结构特征分析
1,主题页面的特征结构
每页数据有100条数据,共5页,数据总量为500条,通过F12检查页面,发现所需要爬取的数据都是静态的。
2.Htmls页面解析
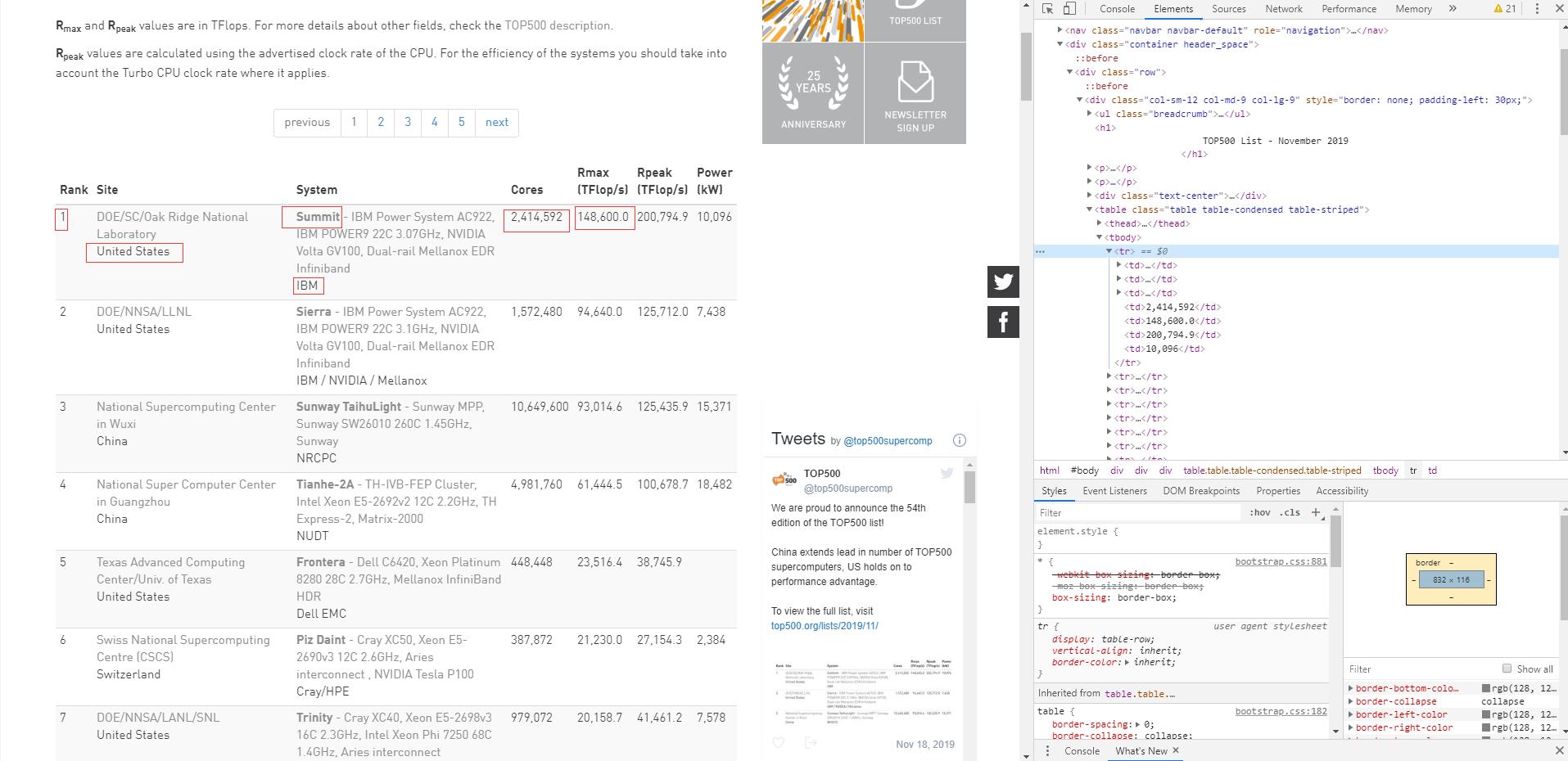
3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
2.对数据进行清洗和处理
1 import requests 2 import json 3 from lxml import etree 4 import seaborn as sns 5 import pandas as pd 6 7 base_url = \'http://www.mtime.com/top/movie/top100/\' 8 config_headers = { 9 \'Accept\': \'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9\', 10 \'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36\' 11 } 12 13 #数据爬取 14 def get_page(page_count): 15 res = requests.get("https://www.top500.org/list/2019/11/?page={0}".format(page_count), headers = config_headers) 16 return res.content.decode(\'utf-8\') 17 18 def parse(data): 19 html = etree.HTML(data) 20 with open(\'a\', \'w\', encoding=\'utf-8\') as f: 21 f.write(data) 22 computer_list = html.xpath("//table/tr") 23 return [parse_item(item) for item in computer_list] 24 25 #数据清洗 26 def parse_item(item): 27 d = {} 28 d[\'rank\'] = item.xpath(\'string(./td[1])\') 29 d[\'country\'] = item.xpath(\'./td[2]/text()\') 30 d[\'company\'] = item.xpath(\'./td[3]/text()\') 31 d[\'name\'] = item.xpath(\'string(./td[3]/a/b)\') 32 d[\'cores\'] = item.xpath(\'./td[4]/text()\') 33 d[\'rmax\'] = item.xpath(\'./td[5]/text()\') 34 for key, v in d.items(): 35 if isinstance(v, list) and len(v) > 0: 36 d[key] = v[0] 37 return d 38 39 40 parse_data = [] 41 for i in range(1, 6): 42 data = get_page(i) 43 clear_data = parse(data) 44 parse_data.extend(clear_data) 45 46 pd.DataFrame(parse_data).to_csv(\'data.csv\') 47 48 def get_column(dc, column_name): 49 return \',\'.join([item[column_name] for item in dc])
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
1 import pandas as pd 2 import matplotlib.pyplot as plt 3 import seaborn as sns 4 5 f = open(\'data.csv\',encoding=\'UTF-8\') 6 data = pd.read_csv(f,sep=\',\',header=None,encoding=\'UTF-8\',names=[\'rank\',\'country\',\'company\',\'name\',\'ores\',\'rmax\']) 7 8 #各国家拥有超级电脑数量 9 country = data[\'country\'].value_counts() 10 sns.set_style("darkgrid") 11 bar_plot = sns.barplot(x=(country.index),y=country.values, palette="muted") 12 plt.xticks(rotation=90) 13 plt.show()
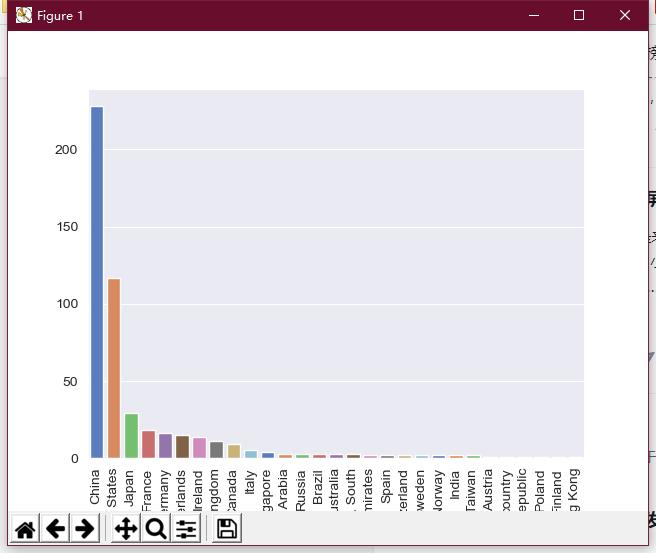
每个国家拥有超级计算机的数量
1 import matplotlib.pyplot as plt 2 from wordcloud import WordCloud 3 import pandas as pd 4 5 f = open(\'data.csv\',encoding=\'UTF-8\') 6 data = pd.read_csv(f,sep=\',\',header=None,encoding=\'UTF-8\',names=[\'rank\',\'country\',\'company\',\'name\',\'ores\',\'rmax\']) 7 8 def draw_country_wordcloud(): 9 country_str = ",".join(data[\'country\']) 10 #生成国家词云 11 country_wordcloud = WordCloud(background_color="white",width=1000, height=860, margin=2).generate(country_str) 12 #生成公司词云 13 plt.imshow(country_wordcloud) 14 plt.axis("off") 15 plt.show() 16 country_wordcloud.to_file(\'country_wordcloud.png\') 17 18 def draw_company_wordcloud(): 19 company_str = ",".join(data[\'company\']) 20 company_wordcloud = WordCloud(background_color="white",width=1000, height=860, margin=2).generate(company_str) 21 plt.imshow(company_wordcloud) 22 plt.axis("off") 23 plt.show() 24 company_wordcloud.to_file(\'country_wordcloud.png\') 25 26 27 draw_country_wordcloud()

国家的词云
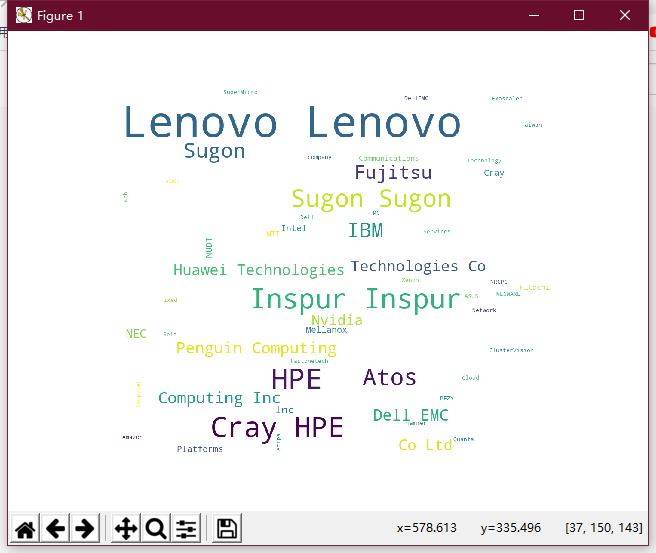
品牌词云
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
①在世界上拥有超级电脑的国家中,中国远超美国成为拥有最多超级电脑的国家。
②中国华为拥有超级电脑的能力。
③在超级电脑的领域,欧洲国家的公司占了很大一部分
2.对本次程序设计任务完成的情况做一个简单的小结。
在这次Python爬虫的过程中我学到了很多在实践中才会遇到的问题,在这次的爬虫中我用到了Xpath。这让我在学习过后的到了很好的复习和巩固,利用好python我们可以爬到很多有用的点,比如说这次我可以爬到超级电脑的国家,品牌和每个国家的数量。并利用可视化很清晰的展示出差别。
以上是关于Python 高级应用程序设计任务的主要内容,如果未能解决你的问题,请参考以下文章