buuctf刷题笔记
Posted z5onk0
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了buuctf刷题笔记相关的知识,希望对你有一定的参考价值。
用了一个月时间,在buuctf上刷了100道题,将做题技巧、脚本和工具记了个笔记,用作查字典
换表的base64解密
import base64
import string
str1 = "x2dtJEOmyjacxDemx2eczT5cVS9fVUGvWTuZWjuexjRqy24rV29q"
string1 = "ZYXABCDEFGHIJKLMNOPQRSTUVWzyxabcdefghijklmnopqrstuvw0123456789+/"
string2 = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
print (base64.b64decode(str1.translate(str.maketrans(string1,string2))))
IDA dump内存
- 脚本
import idc
def main():
begin = 0xCD956000; #需对应修改
size = 0x2FB000 # #需对应修改
list = []
for i in range(size):
byte_tmp = ida_bytes.get_byte(begin + i)
list.append(byte_tmp)
if (i + 1) % 0x1000 == 0:
print("All count:, collect current:, has finish ".format(hex(size), hex(i + 1), float(i + 1) / size))
print(\'collect over\')
file = "/home/t/tmpkqk13.so" #需对应修改
buf = bytearray(list)
with open(file, \'wb\') as fw:
fw.write(buf)
print(\'write over\')
if __name__==\'__main__\':
main()
- shift+e
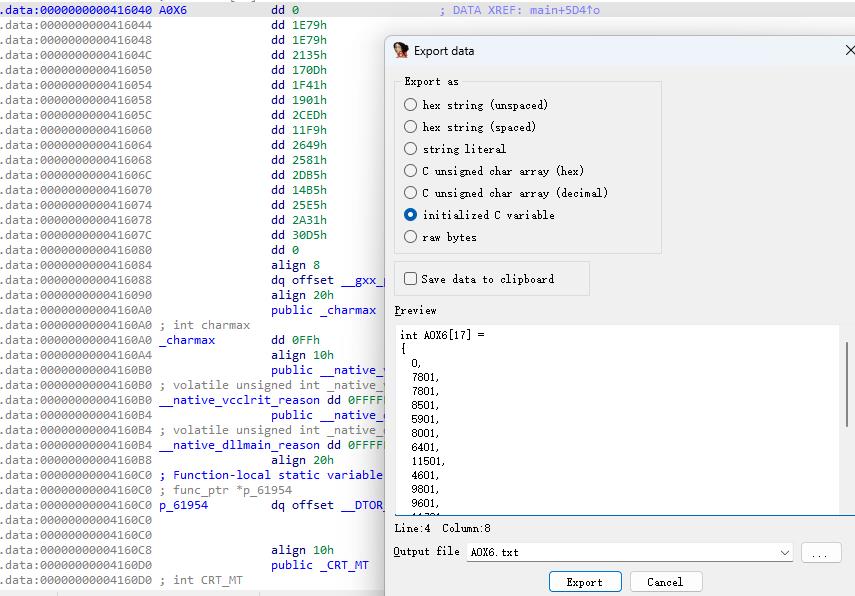
IDA脚本取字节数组
addr = 0x403040
size = 114
array = []
for i in range(size):
array.append(ida_bytes.get_dword(addr+4*i))
print(array)
IDA函数识别失败
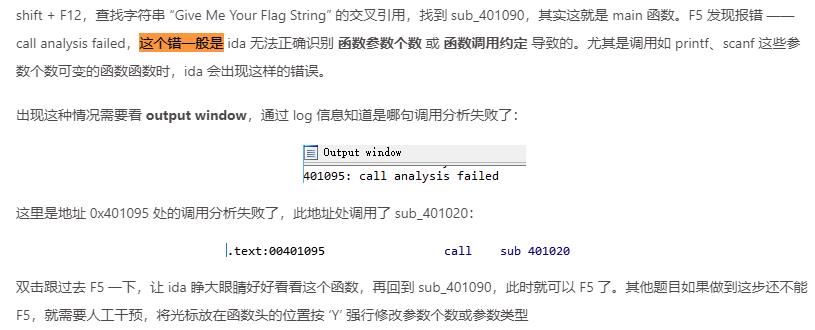
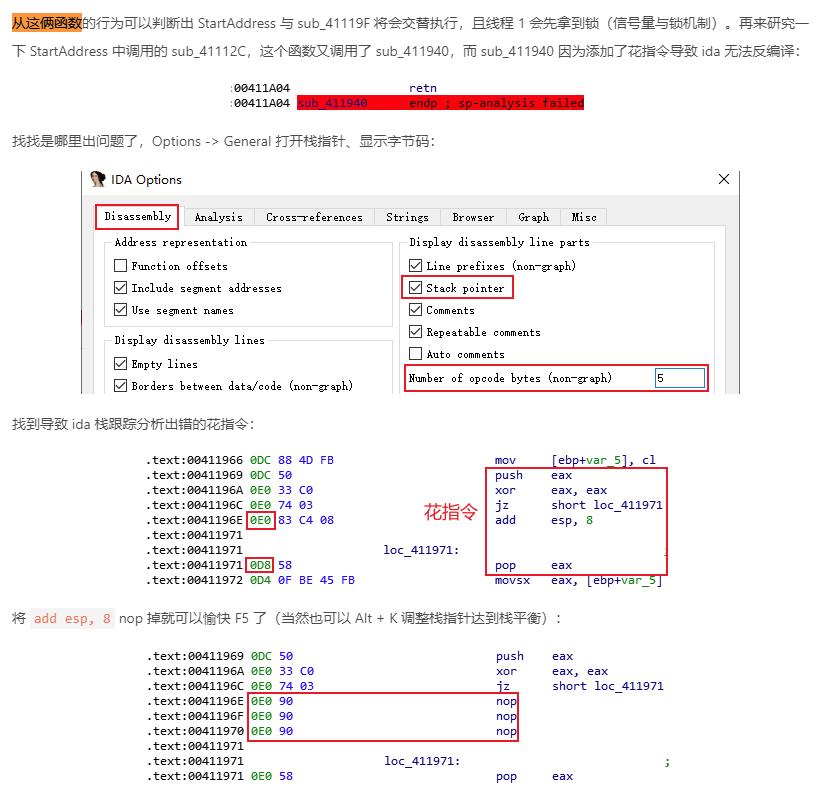
IDA堆栈不平衡导致反编译失败
迷宫转换
maze = "00 00 00 00 23 00 00 00 00 00 00 00 23 23 23 23 00 00 00 23 23 00 00 00 4F 4F 00 00 00 00 00 00 00 00 00 00 00 00 00 00 4F 4F 00 50 50 00 00 00 00 00 00 4C 00 4F 4F 00 4F 4F 00 50 50 00 00 00 00 00 00 4C 00 4F 4F 00 4F 4F 00 50 00 00 00 00 00 00 4C 4C 00 4F 4F 00 00 00 00 50 00 00 00 00 00 00 00 00 00 4F 4F 00 00 00 00 50 00 00 00 00 23 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 23 00 00 00 00 00 00 00 00 00 4D 4D 4D 00 00 00 23 00 00 00 00 00 00 00 00 00 00 4D 4D 4D 00 00 00 00 45 45 00 00 00 30 00 4D 00 4D 00 4D 00 00 00 00 45 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 45 45 54 54 54 49 00 4D 00 4D 00 4D 00 00 00 00 45 00 00 54 00 49 00 4D 00 4D 00 4D 00 00 00 00 45 00 00 54 00 49 00 4D 00 4D 00 4D 21 00 00 00 45 45".split(\' \')
maze = [int(i, 16) for i in maze]
maze = [i if i !=0 else ord(\'*\') for i in maze]
maze = \'\'.join(map(chr, maze))
for i in range(0, len(maze), 16):
print maze[i:i+16]
Unity逆向
- Unity生成游戏时,开发者写的所有 C# 类会被整合编译到 Assembly-CSharp.dll 里,该动态链接库所在的路径是 xxx_Data\\Managed,其中 xxx 为游戏名。这题的 dll 就在 BJD hamburger competition_Data\\Managed 目录下,Reflector 打开该 dll,可以看到类和方法的定义。
- 关注更新UI的方法和语句
求解多元方程组
z3-resolve
from z3 import *
#s = Solver()
v1 = Int(\'v1\')
v2 = Int(\'v2\')
v3 = Int(\'v3\')
v4 = Int(\'v4\')
v5 = Int(\'v5\')
v6 = Int(\'v6\')
v7 = Int(\'v7\')
v8 = Int(\'v8\')
v9 = Int(\'v9\')
v11 = Int(\'v11\')
s.add(-85 * v9 + 58 * v8 + 97 * v6 + v7 + -45 * v5 + 84 * v4 + 95 * v2 - 20 * v1 + 12 * v3 == 12613)
s.add(
30 * v11 + -70 * v9 + -122 * v6 + -81 * v7 + -66 * v5 + -115 * v4 + -41 * v3 + -86 * v1 - 15 * v2 - 30 * v8 == -54400)
s.add(-103 * v11 + 120 * v8 + 108 * v7 + 48 * v4 + -89 * v3 + 78 * v1 - 41 * v2 + 31 * v5 - (
v6 * 64) - 120 * v9 == -10283)
s.add(71 * v6 + (v7 * 128) + 99 * v5 + -111 * v3 + 85 * v1 + 79 * v2 - 30 * v4 - 119 * v8 + 48 * v9 - 16 * v11 == 22855)
s.add(5 * v11 + 23 * v9 + 122 * v8 + -19 * v6 + 99 * v7 + -117 * v5 + -69 * v3 + 22 * v1 - 98 * v2 + 10 * v4 == -2944)
s.add(-54 * v11 + -23 * v8 + -82 * v3 + -85 * v2 + 124 * v1 - 11 * v4 - 8 * v5 - 60 * v7 + 95 * v6 + 100 * v9 == -2222)
s.add(-83 * v11 + -111 * v7 + -57 * v2 + 41 * v1 + 73 * v3 - 18 * v4 + 26 * v5 + 16 * v6 + 77 * v8 - 63 * v9 == -13258)
s.add(81 * v11 + -48 * v9 + 66 * v8 + -104 * v6 + -121 * v7 + 95 * v5 + 85 * v4 + 60 * v3 + -85 * v2 + 80 * v1 == -1559)
s.add(101 * v11 + -85 * v9 + 7 * v6 + 117 * v7 + -83 * v5 + -101 * v4 + 90 * v3 + -28 * v1 + 18 * v2 - v8 == 6308)
s.add(99 * v11 + -28 * v9 + 5 * v8 + 93 * v6 + -18 * v7 + -127 * v5 + 6 * v4 + -9 * v3 + -93 * v1 + 58 * v2 == -1697)
if s.check() == sat:
result = s.model()
print(result)
angr
import angr
base_addr = 0x400000
project = angr.Project("./UniverseFinalAnswer",
main_opts = "base_addr" : base_addr,
auto_load_libs = False)
state = project.factory.entry_state(add_options = angr.options.LAZY_SOLVES)
simManager = project.factory.simgr(state)
simManager.explore(find = base_addr + 0x71A, avoid = base_addr + 0x6EF)
flag = simManager.found[0].posix.dumps(0)
print(flag[:10].decode())
字符串和字节数组互转
enc = "********CENSORED********"
m = [0x410A4335494A0942, 0x0B0EF2F50BE619F0, 0x4F0A3A064A35282B]
import binascii
flag = b\'\'
for i in range(3):
p = enc[i * 8:(i + 1) * 8]
print(p)
a = binascii.b2a_hex(p.encode(\'ascii\')[::-1])
print(a)
b = binascii.a2b_hex(hex(int(a, 16) + m[i])[2:])[::-1]
print(b)
flag += b
print(flag)
字符串、字节流、十六进制数组之间的转换
import binascii
# array = "7635fdf57d47fe95137a26593fff31a1857c63026ebd936a3e4d8dd727732d5ecc62f2dfe5d200"
# medium = b"v5\\xfd\\xf5G\\xfe\\x95\\x13z&Y?\\xff1\\xa1\\x85|c\\x02n\\xbd\\x93j>M\\x8d\\xd7\'s-^\\xccb\\xf2\\xdf\\xe5\\xd2\\x00"
# 字节流转十六进制数组
array = binascii.b2a_hex(bytes).decode(\'utf-8\')
# 十六进制数组转字节流
bytes = binascii.a2b_hex(array).encode(\'utf-8\')
【二叉树】已知中序和后序,求前序遍历
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
char post[] = "20f0Th2tsIS_icArEe7__w"; //后序遍历结果
char mid[] = "2f0t02ThcsiI_SwA__r7Ee"; //中序遍历结果
void f(int root,int start,int end)
if(start > end)
return ;
int i = start;
while(i < end && mid[i] != post[root])
i++; //定位根在中序的位置
printf("%c",mid[i]);
f(root - 1-(end - i),start,i - 1); //递归处理左子树
f(root-1,i + 1,end); //递归处理右子树
int main()
f(24,0,24);
return 0;
脱离程序的逐字节爆破
- 要求:可以提取算法,位与位之间无关联
flag = \'\'
charSet = string.uppercase + string.lowercase
charSet = map(ord, charSet)
for i in range(len(key)):
for char in charSet:
if text[i] == (char - 39 - key[i] + ord(\'a\')) % 26 + ord(\'a\'):
flag += chr(char)
break
print flag
依赖程序的逐字节爆破
- 要求:程序会提示哪一位出错
from pwn import *
import re
flag = "actf"
k = 0
while True:
for i in range(33,127):
p = process(\'./SoulLike\')
_flag = flag + chr(i)
print _flag
p.sendline(_flag)
s = p.recvline()
r = re.findall("on #(.*?)\\n", s)[0]
r = int(r)
if r == k:
print \'no\'
print k
elif r == k + 1:
print s
flag += chr(i)
k += 1
p.close()
p.close()
if k > 11:
break
print (flag)
与位置无关的加密爆破
- 一般加密的过程是out = f(in, n),in是输入的单个字节,n是第几位,out是输出的单个字节
- 一种特殊的加密过程是out = f(in),也就是输入的每一位都进行完全相同的变换
- 这种特殊的加密相当于对字符集做了一个映射关系,那么可以输入所有字符,通过动调捕获输出的字节,即可建立该一对一映射关系,从而按照目标输出恢复原始输入
VM虚拟机逐位爆破
int main()
env_init();
char flag[16];
for (int i = 0; i < 15; i++)
// 创建快照
save_vm_state();
// 所有可见字符
for (int j = 33; j < 128; j++)
flag[i] = j;
if (vm_operate(i, flag))
// flag[i]中途可能会被case 8修改,这里再赋值一次
flag[i] = j;
break;
// 本次猜测不正确,还原现场
recover_vm_state();
flag[15] = 0;
puts(flag);
angr求解目标点的输入
import angr
project = angr.Project("./signal.exe", auto_load_libs = False)
@project.hook(0x40179E)
def MyHook(state):
print(state.posix.dumps(0))
project.terminate_execution()
project.execute()
用angr来输出程序路径信息
import angr
count = 0
project = angr.Project("./attachment.exe")
# 修改目标位置处的寄存器值
@project.hook(addr = 0x401712)
def hook0(state):
# modify variable "inputLen"
state.mem[state.regs.rbp+0x1470].dword = 15
# 到达某地址处打印信息
@project.hook(0x40174C)
def hook1(state):
global count
print("char %d:" % count)
count += 1
# 到达某地址处打印信息
@project.hook(0x4017C6)
def hook2(state):
print("op1")
# 到达某地址处结束执行
@project.hook(0x401B51)
def hook6(state):
project.terminate_execution()
反调试Patch
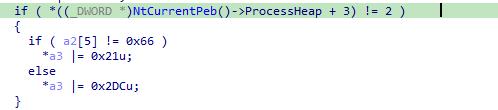
数独游戏
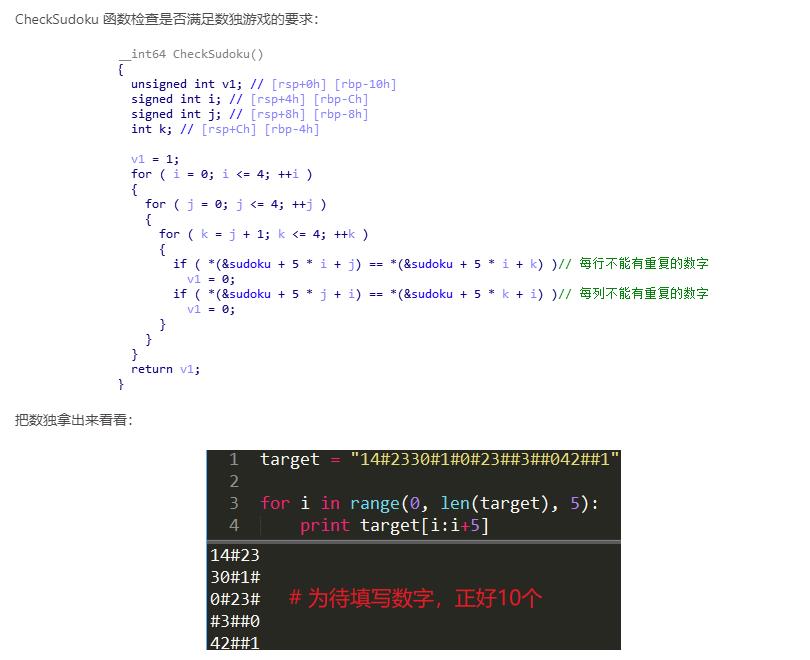
dialogbox弹出窗口

idc脚本还原加密代码段
import idc
addr = 0x401500
for i in range(187):
b = ida_bytes.get_byte(addr + i)
ida_bytes.patch_byte(addr + i, b ^ 0x41)
- 在 ida 中选择 File -> Script File…,选择该脚本运行
- 来到 encypt 函数,先将函数 Undefine,并从上到下,在其解释为 db xx 指令处按 c,强转为汇编代码,保证整个函数内没有 db xx 这样的指令
- 再在 0x401500 处右键创建函数,F5
函数长度过大导致IDA反编译失败
- IDA限制了解析函数的长度,过长会反编译失败
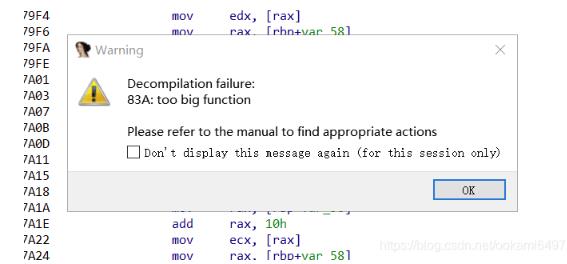
- 修改配置文件
IDA 7.0\\cfg\\hexrays.cfg来解决

逐字节前后异或解密
- 解密方向同加密方向相反,从加密的最后一个字节开始解密
xxtea解密
- https://github.com/xxtea/xxtea-c
- vs中导入头文件编译,可直接使用decode函数
jsfucker解密
-
法一:在线网站
-
法二:js脚本替换
<script> function deEquation(str) for(let i = 0; i <= 1; i++) str = str.replace(/l\\[(\\D*?)](\\+l|-l|==)/g, (m, a, b) => \'l[\' + eval(a) + \']\' + b); str = str.replace(/==(\\D*?)&&/g, (m, a) => \'==\' + eval(a) + \'&&\'); return str; js="jsf**k"//将代码放入其中 res=deEquation(js); document.write(res); </script> -
法三:python库求解js执行结果
import re import execjs from z3 import * #用execjs获取js代码的执行结果 def FrontSub(matched): num = execjs.eval(matched.group(2)) return "l[%s]" % num def EndSub(matched): num = execjs.eval(matched.group(0)) return str(num) # 从js代码中提取等式 html_path = "E:\\\\Project\\\\Reverse\\\\BuuCtf\\\\18\\\\output\\\\equation.html" with open(html_path, "r") as f: content = f.read().split("\\n")[4].strip() _content = re.search(\'if\\((.*)\\)\', content).group(1) eq_list = _content.split("&&") # 构造js代码解密后的等式 z3_eqs = [] for equation in eq_list: [front, end] = equation.split("==") f_tmp = re.sub(\'(l\\[)([\\[\\]!\\+]+)(\\])\', FrontSub, front) # 等号前的js代码执行结果 e_tmp = re.sub(\'.+\', EndSub, end) # 等号后的js代码执行结果 z3_eq = f_tmp + \'==\' + e_tmp # 构造等式 z3_eqs.append(z3_eq) S = Solver() l = IntVector(\'l\', 42) for eq in z3_eqs: eval("S.add(" + eq + ")") if S.check() == sat: result = S.model() for i in range(0x2a): print(chr(int("%s"%(result[l[i]]))),end="")
pyinstaller逆向
- 用PyInstaller Extractor解包,得到pyc和struct文件
- 对比pyc和struct文件,把struct文件前几个字节插入login开头
- 反编译pyc文件,得到源代码
交换字节
两种
循环左移/右移的逆运算
- 正运算
for ( i = 0; i < strlen(input); ++i )
if ( (i & 1) != 0 ) // 奇数循环右移
v1 = (input[i] >> 2) | (input[i] << 6);
else // 偶数循环左移
v1 = (4 * input[i]) | (input[i] >> 6);
input[i] = v1;
- 逆运算
for i in range(0,len(result)):
t = result[i]
if i&1==0: //偶数循环右移
input[i]=(t&0x3)<<6|(t&0xfc)>>2 #低2位左移6位,高6位右移2位 相当于循环右移2位
else: //奇数循环左移
input[i]=(t&0x3f)<<2|(t&0xc0)>>6 #低6位左移2位,高2位右移6位 相当于循环左移2位
静态分析看不到程序主逻辑
-
程序对关键字符串关键call进行了加密,只能通过动态调试的方式来还原程序
-
通过内存访问断点或中断法,来跟踪对输入的加密流程
-
如果遇到调用了另一个程序或者子进程中处理逻辑的情况,可能需要考虑用工具加解密
-
单步调,直到看到输入的字符串
4、8字节数据按小端序转化为字节数组
-
先转化为字节序列
# 可用struct和p32方法 from struct import * raw = [0xFD370FEB59C9B9E, 0xDEAB7F029C4FD1B2, 0xFACD9D40E7636559] target = \'\' for i in range(3): target += pack("Q", raw[i]) -
再将字节序列转化为数组
for i in range(len(target)): array.append(ord(target[i]))
perlAPP压缩程序的还原
- perl程序经过perAPP的压缩
- 在程序运行过程中,会调用script来解压程序(搜索script字符串,找到最近的call)
- 解压后,eax指向perl源码地址,程序调用perl解释器来运行源码
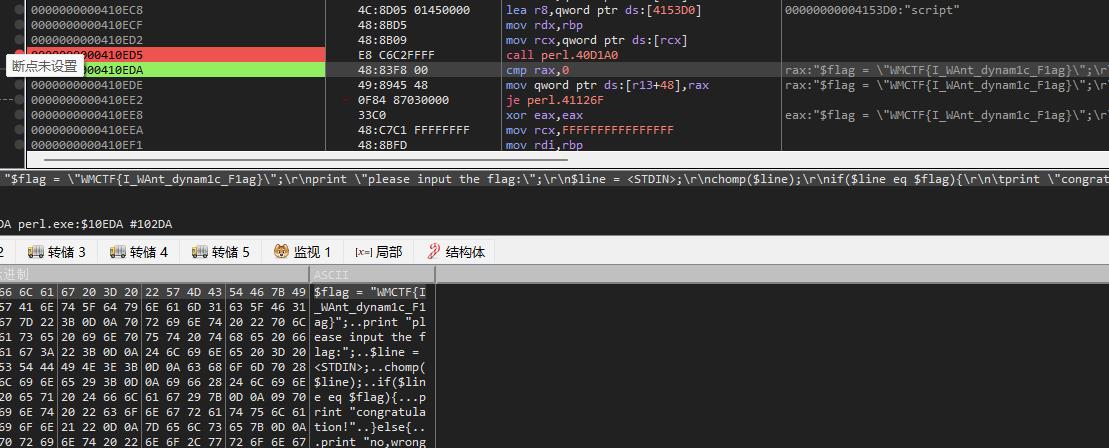
去花指令的原则
- 编译器不会生成无用指令,无用指令一定要patch
- 有用指令一定要保留
rc4
import base64
from Crypto.Cipher import ARC4
func = lambda x : \'=\' if x == \'=\' else table[ord(x) - ord(\'=\')]
table = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/="
target = r"Z`TzzTrD|fQP[_VVL|yneURyUmFklVJgLasJroZpHRxIUlH\\vZE="
target = map(func, target)
encoded = base64.b64decode(\'\'.join(target))
key = "\\x10\\x20\\x30\\x30\\x20\\x20\\x10\\x40"
rc4 = ARC4.new(key)
print rc4.decrypt(encoded)
sm4
CRC32
IDA自动patch目标指令的脚本
st = 0x0000000000401117
end = 0x0000000000402144
def patch_nop(start,end):
for i in range(start,end):
PatchByte(i, 0x90) #修改指定地址处的指令 0x90是最简单的1字节nop
def next_instr(addr):
return addr+ItemSize(addr) #ItemSize获取指令或数据长度,这个函数的作用就是去往下一条指令
addr = st
while(addr<end):
next = next_instr(addr)
if "ds:dword_603054" in GetDisasm(addr): #GetDisasm(addr)得到addr的反汇编语句
while(True):
addr = next
next = next_instr(addr)
if "jnz" in GetDisasm(addr):
dest = GetOperandValue(addr, 0) #得到操作数,就是指令后的数
PatchByte(addr, 0xe9)
PatchByte(addr+5, 0x90)
offset = dest - (addr + 5)
PatchDword(addr + 1, offset)
print("patch bcf: 0x%x"%addr)
addr = next
break
else:
addr = next
负数的除法处理
- 有符号数右移之后,负数会变成正数,所以需要再异或一个 0x8000000000000000
item = item//2
item = item | 0x8000000000000000
SEH反调试
- UnhandledExceptionFilter只有在没有调试器附加时才会被调用,可以将敏感代码(如SMC代码)放到seh handler中,达到反调试的效果
实例分析
- 在函数开头注册了一个407b58的seh struct,这部分代码不会被反编译出来
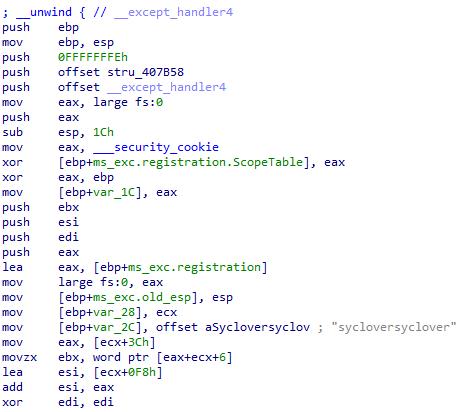
- 查看seh struct,4023dc和4023ef分别是filter和handler
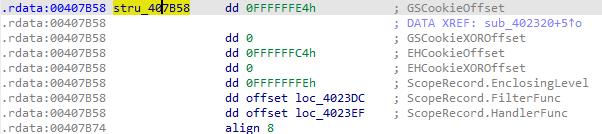
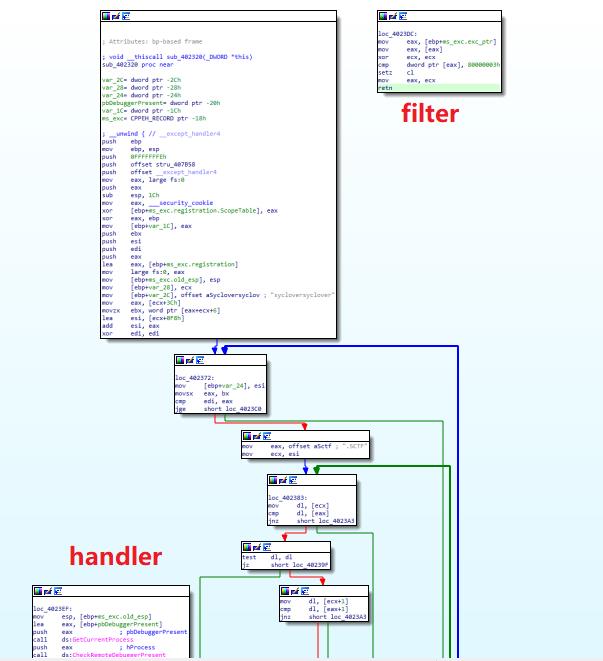
- 由于IDA边界识别的问题,filter和handler函数没有被反编译出来
-
handler中调用了另一个SMC函数,该函数对代码进行了解密
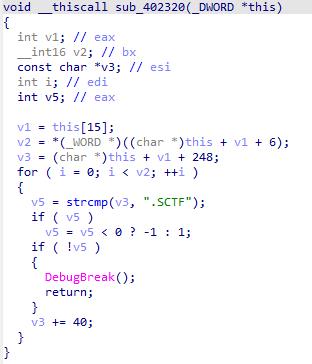
-
主函数中搜索sctf段,调用debugbreak,如果没有调试器附加,触发seh handler->smc的调用链,解密隐藏数据
CE基本用法
-
相比x64dbg,更适用于面向对象语言/框架的逆向,可以直接定位类和实例,获取字段值,给方法下断点
-
内存中暴力搜索字符串
- 首次搜索:字符串要选中utf-16
- 再次搜索:用于定位变化的值
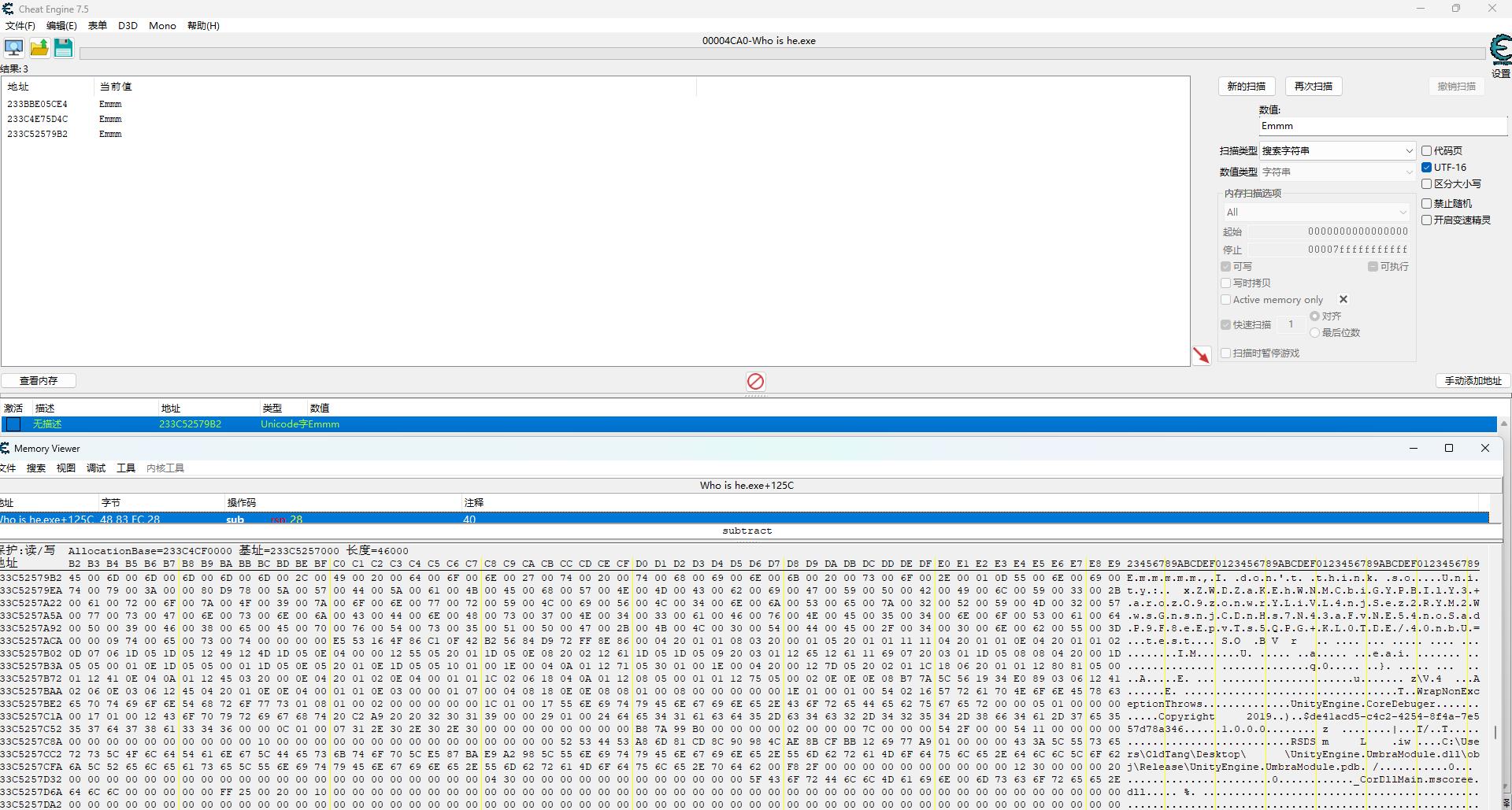
-
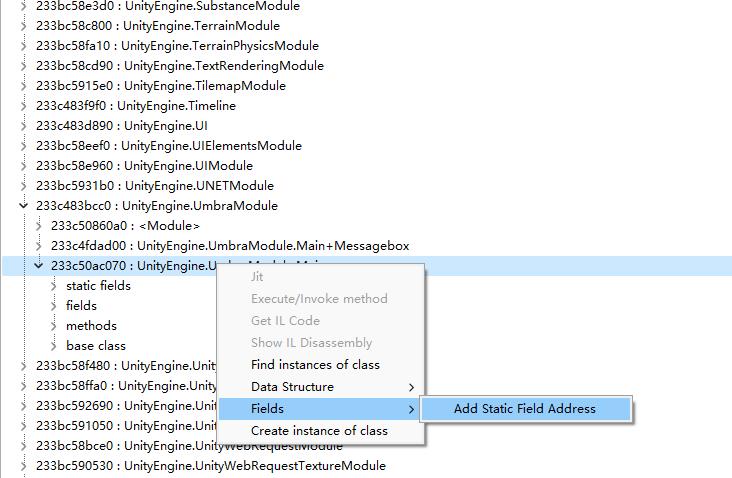
查看实例的字段值
- Mono->分析Mono->右键实例->Add Filed
- 记录器中激活目标字段,右键浏览相关区域内存
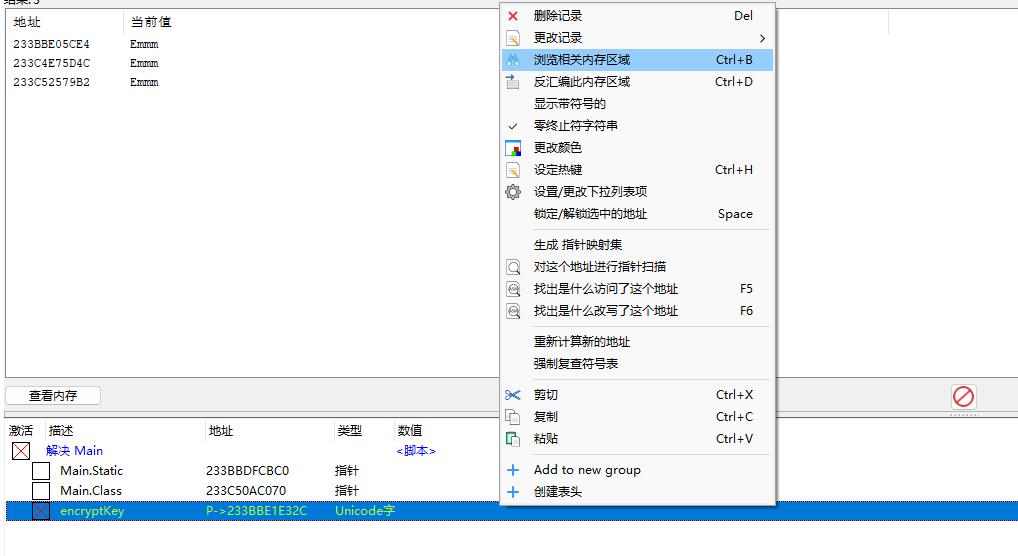
-
方法下断点,观察参数和返回值
- 分析Mono->右键目标方法,选择jit
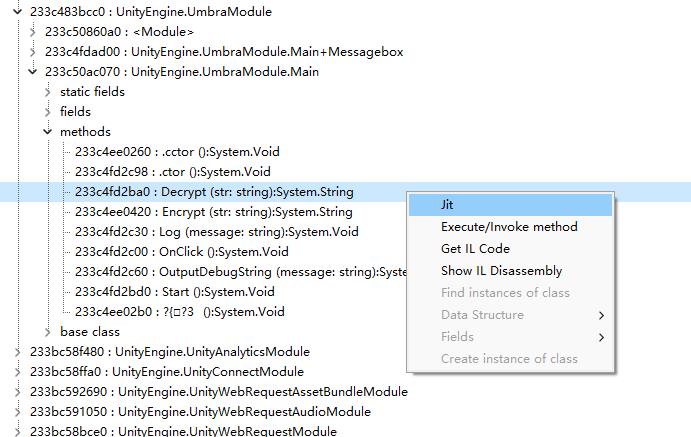
- 函数入口处设置断点
- 断下后,查看寄存器值,以16进制显示
DES算法解密脚本
import base64
from Crypto.Cipher import DES
encryptData = "xZWDZaKEhWNMCbiGYPBIlY3+arozO9zonwrYLiVL4njSez2RYM2WwsGnsnjCDnHs7N43aFvNE54noSadP9F8eEpvTs5QPG+KL0TDE/40nbU="
e = base64.b64decode(encryptData)
# 在C#中,字符串默认是Unicode字符串,所以转成字节数组,在每个字符字节后都要加一个"\\x00"
keyiv = b"t\\x00e\\x00s\\x00t\\x00"
d = DES.new(keyiv, DES.MODE_CBC, keyiv)
print(d.decrypt(e).decode("utf-16"))
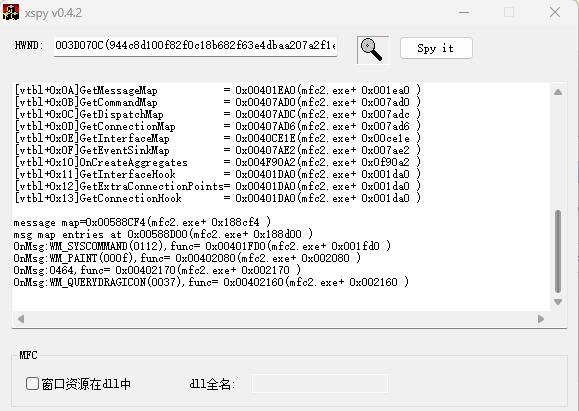
xspy分析mfc窗口
python发送win32消息
import win32gui
hwnd = win32gui.FindWindow(None, "Flag就在控件里")
win32gui.SendMessage(hwnd, 0x464, None, None)
以上是关于buuctf刷题笔记的主要内容,如果未能解决你的问题,请参考以下文章