寒武纪加速推理与训练智能卡分析
Posted 吴建明
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了寒武纪加速推理与训练智能卡分析相关的知识,希望对你有一定的参考价值。
寒武纪加速推理与训练智能卡分析

思元370芯片
基于7nm制程工艺,思元370是寒武纪首款采用chiplet(芯粒)技术的AI芯片,集成了390亿个晶体管,最大算力高达256TOPS(INT8),是寒武纪第二代产品思元270算力的2倍。凭借寒武纪最新智能芯片架构MLUarch03,思元370实测性能表现更为优秀。思元370也是国内第一款公开发布支持LPDDR5内存的云端AI芯片,内存带宽是上一代产品的3倍,访存能效达GDDR6的1.5倍。搭载MLU-Link™多芯互联技术,在分布式训练或推理任务中为多颗思元370芯片提供高效协同能力。全新升级的寒武纪基础软件平台,新增推理加速引擎MagicMind,实现训推一体,大幅提升了开发部署的效率,降低用户的学习成本、开发成本和运营成本。

先进chiplet技术
寒武纪首次采用chiplet技术将2颗AI计算芯粒封装为一颗AI芯片,通过不同芯粒组合规格多样化的产品,为用户提供适用不同场景的高性价比AI芯片。
MLUarch03芯片架构
新一代张量运算单元,内置Supercharger模块大幅提升各类卷积效率;采用全新的多算子硬件融合技术,在软件融合的基础上大幅减少算子执行时间。
MagicMind推理加速引擎
业内首个基于MLIR图编译技术达到商业化部署能力的推理引擎。用户仅需投入极少的开发成本,即可将推理业务部署到寒武纪全系产品上,并获得颇具竞争力的性能。
训推一体软件开发平台
寒武纪基础软件平台整合了训练和推理的全部底层软件栈,包括底层驱动、运行时库、算子库以及工具链等,将MagicMind和人工智能框架Tensorflow,Pytorch深度融合,实现训推一体。
低功耗高带宽LPDDR5内存
思元370芯片在业内率先支持LPDDR5内存,高带宽且低功耗,内存带宽是上一代产品的3倍,访存能效达GDDR6的1.5倍,可在板卡有限的功耗范围内给AI芯片分配更多的能源,输出更强大的算力。
新一代编解码单元
全新视频图像编解码单元,可支持132路1080p视频解码,支持10路8K视频解码。视频编码时,在相同图像质量(全高清视频PSNR)的情况下比上一代产品节省42%带宽,有效降低带宽成本。
MLU-Link多芯互联技术
MLU-Link多芯互联技术,搭载于寒武纪思元370芯片,为每颗芯片提供200GB/s的额外跨芯片直接通讯能力。在思元370应对多卡多芯并行任务时,提供更高效的并行效率。
为AI浮点计算优化
思元370芯片具备完整的张量浮点运算单元,可支持AI加速中繁重的FP32、FP16或BF16计算任务,让计算的选择变得更简单。
思元370系列板卡与业内主流GPU性能对比
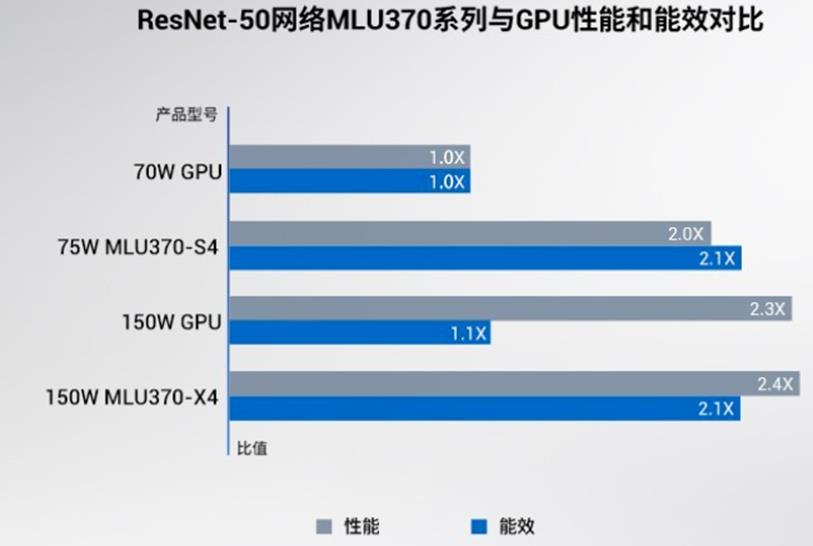
*测试环境:MLU370-S4:NF5468M6/2x Intel Xeon Gold 6330 CPU @ 2.0GHz/MagicMind v0.6
MLU370-X4:NF5468M6/2x Intel Xeon Gold 6330 CPU @ 2.0GHz/MagicMind v0.6
GPU数据:ResNet-50来自于相关产品官网,Transformer、VGG16、YOLOv3均取自实测最大吞吐性能。
了解寒武纪思元370智能加速卡

思元290寒武纪首颗AI训练芯片
寒武纪思元290芯片,采用创新性的MLUv02扩展架构,使用台积电7nm先进制程工艺制造,在一颗芯片上集成了高达460亿的晶体管。芯片具备多项关键性技术创新, MLU-Link™多芯互联技术,提供高带宽多链接的互连解决方案;HBM2内存提供AI训练中所需的高内存带宽;vMLU帮助客户实现云端虚拟化及容器级的资源隔离。多种全新技术帮助AI计算应对性能、效率、扩展性、可靠性等多样化的挑战。

核心优势
寒武纪MLUv02扩展架构
思元290基于MLUv02架构进行了多项扩展,实现峰值算力提升4倍、缓存带宽提高12倍、芯片间通讯带宽提高19倍。新架构采用7nm制程,可提供更高性能功耗比,以及多MLU系统的扩展能力。
寒武纪MLU-Link™多芯互联技术
MLU-Link™多芯互联技术,首发于寒武纪思元290芯片,总带宽高达600GB/s,支持思元芯片间互联和跨系统互联,可实现纵向扩展,满足AI模型训练的需要。
寒武纪vMLU虚拟化解决方案
寒武纪虚拟化技术vMLU,支持在思元290上实现4个相互隔离的AI计算实例,每个实例独占计算、内存和编解码资源,在虚拟化环境下仍可保持不低于90%的极高效率,帮助客户充分利用硬件资源。
寒武纪端云一体软件栈
寒武纪基础软件平台采用端云一体架构,支持寒武纪全系列产品共享同样的软件接口和完备生态,可方便地进行AI应用的开发,迁移和调优,轻松实现云端开发训练模型,终端部署应用。
自适应精度训练
思元290采用寒武纪自适应精度训练方法。自适应精度训练可自适应调整人工智能模型不同层、不同数据类型的量化参数,同时量化参数调整周期也是自适应的,可在保证精度要求的基础上提高能效比。
高带宽内存
思元290承载了32G高带宽内存(HBM2),单芯片内存带宽高达1.23TB/秒,是思元270芯片的 12倍,有效解决传统加速器芯片内存带宽瓶颈问题,为用户提供更高的模型训练速度。
应用领域

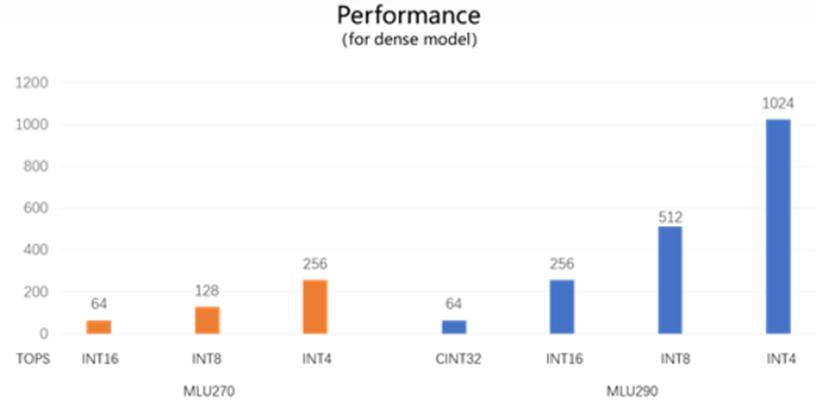
思元270与思元290理论峰值性能对比
了解寒武纪思元290智能加速卡

参考文献链接
https://www.cambricon.com/
模型推理寒武纪 MLU resnet50 量化及离线推理流程
欢迎关注我的公众号 [极智视界],获取我的更多笔记分享
O_o >_< o_O O_o ~_~ o_O
本文介绍了在寒武纪 MLU 中进行 resnet50 量化与离线推理的流程。
本文主要介绍了 Cambricon pytorch 环境搭建、resnet50量化、resnet50 离线推理,resnet 系列是标准模型,其他模型也可参考该流程执行。
1、Cambricon Pytorch 环境配置
这个之前写过一篇文章《【经验分享】寒武纪MLU270 源码编译 pytorch-mlu》,关于 Cambricon Pytorch 的编译与环境搭建可以参考。
按流程搭建好 Cambricon Pytorch 环境后,确认一下环境是否正常,打开 ${PYTORCH_HOME}/build/lib(/opt/cambricon/pytorch/src/pytorch/build/lib),若编译生成了 libtorch_python.so 和 libtorch.so 等文件,则说明 Cambricon PyTorch 编译成功:
2、resnet50 量化推理
2.1 模型量化
cd $HOME/pytorch/tools
./quanti_model.sh
其中 quanti_model.sh 中的内容:
python quantification_tool.py -model_name resnet50 -data_scale 1.0 -mean 0.485 0.456 0.456 -std 0.229 0.224 0.225 -resize 224 -crop 224 -used_images_num 5 -quantize_mode int8 -save_model_path /opt/cambricon/pytorch/models/int8 -save_name resnet50-19c8e357
- 参数说明:
- -model_name:模型名称;
- -data_scale:最大值和最小值缩放比例;
- -mean:量化参数均值;
- -std:量化参数方差;
- -resize:预处理中对图像大小的调整;
- -crop:裁剪图像大小;
- -used_images_num:量化时使用的图片数量;
- -quantize_mode:量化精度;
- -save_model_path:模型量化后的保存路径;
- -save_name:模型量化后的名称;
来看一下终端的输出:

2.2 转离线模型
安装 python3-tk
sudo apt install python3-tk
执行离线模型转换:
cd $HOME/pytorch/tools
python genoff_test_resnet50.py
其中 genoff_test_resnet5.py 中内容:
import sys
import torch
import torch.nn as nn
from torchvision.models.resnet import resnet50
net = resnet50(pretrained=False, progress=True)
net.load_state_dict(torch.load('/opt/cambricon/pytorch/models/int8/resnet50-19c8e357.pth',map_location='cpu'),strict=False)
net.eval().float().mlu()
net.set_core_number(16)
example_mlu = torch.randn(16,3,224,224,dtype=torch.float).mlu()
net = torch.jit.trace(net,example_mlu, check_trace=False)
net(example_mlu)
net.save('/opt/cambricon/pytorch/models/resnet50_int8_offline',True)

2.3 离线推理
执行离线推理:
cd $HOME/pytorch/tools
./inference_resnet50.sh
其中 inference_resnet50.sh 中内容:
/opt/cambricon/pytorch/src/pytorch/test/offline_examples/build/clas_offline_multicore/clas_offline_multicore -offlinemodel /opt/cambricon/pytorch/models/resnet50_int8_offline.cambricon -images file_list_for_release -labels synset_words.txt -simple_compile 2 -input_format 0
- 参数说明:
- -offlinemodel:离线模型的路径;
- -images:图片列表文本文件;
- -labels:标签文件;
- -simple_compile:使能简单编译功能,Cambricon Runtime 根据离线模型 core_number 和 batch_size 参数自动分配最优的软硬件资源;
- -input_format:指定运行网络时输入图片的通道顺序,依据该参数对输入图片进行相应的前处理。支持 RGB、RGBA 和 ARGB 三种输入图片的通道顺序。0 表示 RGB,1 表示 RGBA,2 表示 ARGB;
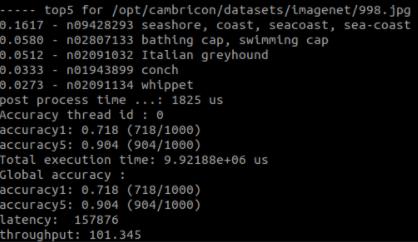
最终的推理结果输出如下:
以上分享了一下 寒武纪 MLU 上前端为 Cambricon Pytorch 时的 resnet50 int8 量化、转离线模型及离线推理的流程,对寒武纪上其他模型的量化推理应该也有借鉴作用。
【公众号传送】
扫描下方二维码即可关注我的微信公众号【极智视界】,获取更多AI经验分享,让我们用极致+极客的心态来迎接AI !

以上是关于寒武纪加速推理与训练智能卡分析的主要内容,如果未能解决你的问题,请参考以下文章
OneFlow和寒武纪达成适配,共同推进新一代超大模型训练解决方案