模型训练与推理中为什么需要使用GPU?基本概念梳理
Posted Morven.Huang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了模型训练与推理中为什么需要使用GPU?基本概念梳理相关的知识,希望对你有一定的参考价值。

随着AI尤其是ChatGPT的大火,像英伟达、国内的寒武纪等GPU芯片/AI芯片厂商股价也随之大幅攀升。
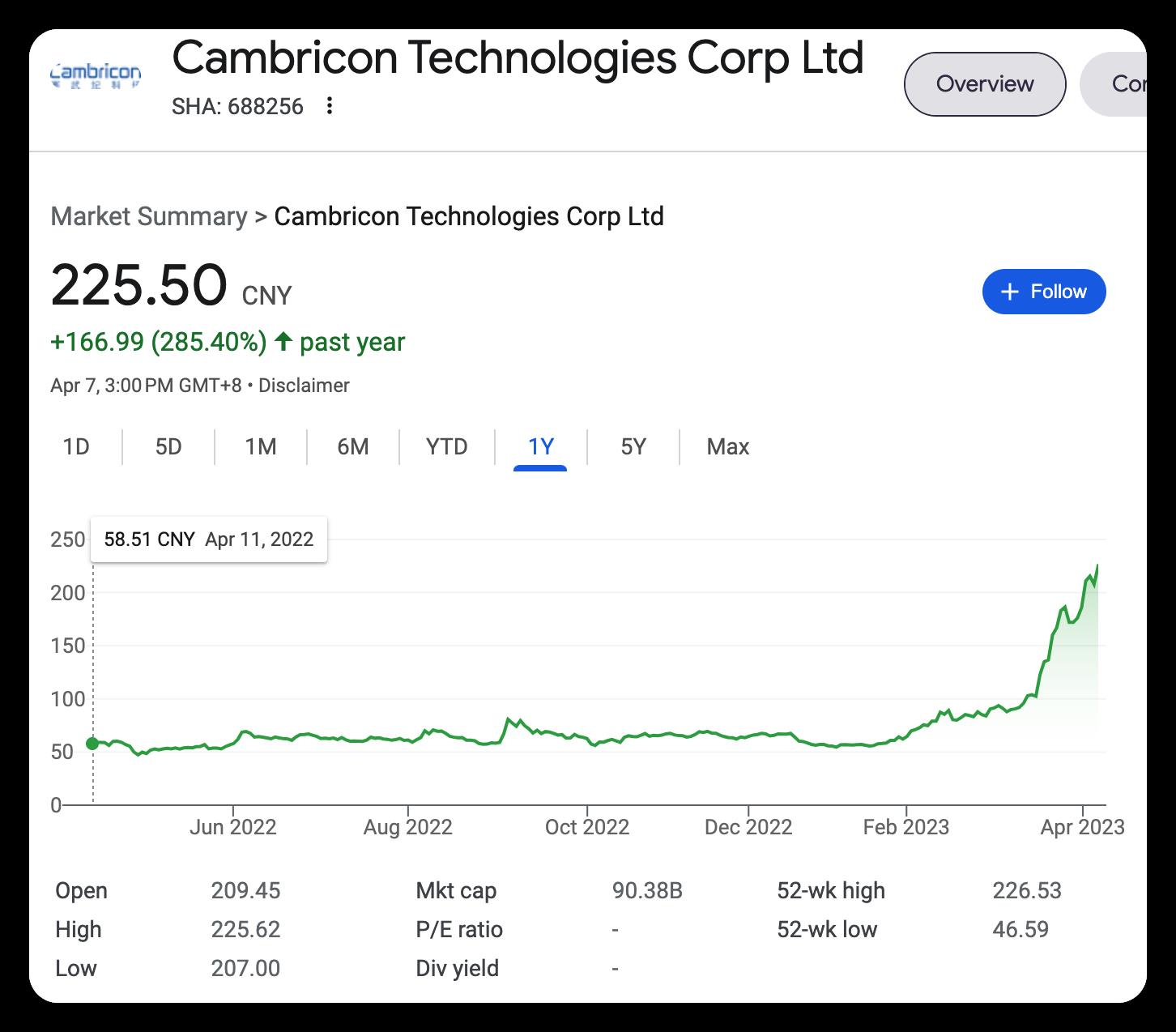
(寒武纪股价)
GPU就是我们日常所说的“显卡”,那么为什么显卡和AI有关系呢?而美国政府又为什么要出台关于GPU的芯片禁令呢?
实际上,我们这里所说的GPU,与日常用于图形渲染的显卡,还是有一些差别,它更多的是一种AI专用的ASIC芯片(ASIC,Application Specific Integrated Circuit),只不过技术上有类似或者说相通之处,我们大多数时候还称它为GPU。
如GPT、BERT等LLM都需要在大量的数据上进行训练,而GPU具有高度的并行计算能力,可以加速深度学习模型的训练和推理,可以说,GPU是人工智能的算力基础,没有它,就玩不转人工智能。所以,美国的禁令直接针对的是中国的人工智能行业。
下面,我画了一张思维导图,梳理了GPU与CPU的区别,GPU在机器学习领域的优势,以及国内外主要的一些GPU/AI芯片厂商,希望大家能有所收获。目前,国内GPU/AI芯片领域仍然面临专利和制程两大困境,希望将来越来越好吧,加油。
(对了,如果有小伙伴还没试用过ChatGPT,我搭了一个小跳板,免费的,关注下面公众号“后厂村思维导图馆”,私信留言索要,资源有限,先到先得哦)
如何在 Tensorflow 2.0 + Keras 中进行并行 GPU 推理?
【中文标题】如何在 Tensorflow 2.0 + Keras 中进行并行 GPU 推理?【英文标题】:How to do parallel GPU inferencing in Tensorflow 2.0 + Keras? 【发布时间】:2020-03-15 23:49:56 【问题描述】:让我们从我刚开始接触 TensorFlow 和一般深度学习的前提开始。
我有使用 tf.Model.train()、两个可用 GPU 训练的 TF 2.0 Keras 样式模型,我希望缩减推理时间。
我使用非常方便的 tf.distribute.MirroredStrategy().scope() 上下文管理器训练了跨 GPU 分布的模型
mirrored_strategy = tf.distribute.MirroredStrategy()
with mirrored_strategy.scope():
model.compile(...)
model.train(...)
两个 GPU 都得到了有效利用(即使我对结果的准确性不太满意)。
我似乎找不到类似的策略来使用 tf.Model.predict() 方法在 GPU 之间分配推理:当我运行 model.predict() 时,我(显然)只从两个 GPU 中的一个获得使用。
是否有可能在两个 GPU 上建立相同的模型,并为它们并行提供不同的数据块?
有些帖子建议如何在 TF 1.x 中执行此操作,但我似乎无法在 TF2.0 中复制结果
https://medium.com/@sbp3624/tensorflow-multi-gpu-for-inferencing-test-time-58e952a2ed95
Tensorflow: simultaneous prediction on GPU and CPU
我对这个问题的心理斗争主要是
TF 1.x 基于tf.Session(),而会话隐含在 TF2.0 中,如果我理解正确,我阅读的解决方案为每个 GPU 使用单独的会话,我真的不知道如何在 TF2 中复制它.0
我不知道如何在特定会话中使用model.predict() 方法。
我知道这个问题可能没有很好地表述,但我将其总结为:
有人知道如何在 TF2.0 中的多个 GPU 上运行 Keras 风格的 model.predict()(以并行方式推断每个 GPU 上的不同批次数据)吗?
提前感谢您的帮助。
【问题讨论】:
tensorflow.org/tutorials/distribute/save_and_load 这可能会有所帮助。我遇到了同样的问题,我的问题似乎源于我将模型保存为 hdf5 格式,在将模型加载回分布式启动时不支持这种格式 【参考方案1】:尝试在tf.distribute.MirroredStrategy 中加载模型并使用更大的batch_size
mirrored_strategy = tf.distribute.MirroredStrategy()
with mirrored_strategy.scope():
model = tf.keras.models.load_model(saved_model_path)
result = model.predict(batch_size=greater_batch_size)
【讨论】:
这不适用于 model.predict_on_batch(greater_batch_size) 对吧?以上是关于模型训练与推理中为什么需要使用GPU?基本概念梳理的主要内容,如果未能解决你的问题,请参考以下文章