BERT模型
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了BERT模型相关的知识,希望对你有一定的参考价值。
https://blog.csdn.net/qq_41898761/article/details/125017287
BERT一层层深究下去的路径是这样的:【BERT】<==【Transformer】<==【self-attention】<==【attention机制】<==【seq2seq】
BERT是一个多层双向的 Transformer encoder 模型。 BERT中的 Transformer 只有 encoder,没有decoder!!!
BERT的改进
1.BERT通过使用**masked language model (MLM)**预训练目标,缓解了单向性约束。masked language model从输入中随机地遮蔽一些标记,目标是仅根据其上下文来预测被遮蔽的单词的原始词汇ID。 与从左到右的语言模型预训练不同,MLM的目标是使表征融合左和右的语境,这使我们能够预训练一个深度的双向Transformer。
2.除了 masked language model,BERT还使用了一个 "next sentence prediction "任务,联合预训练文本对的表示。
https://blog.csdn.net/zag666/article/details/127817715
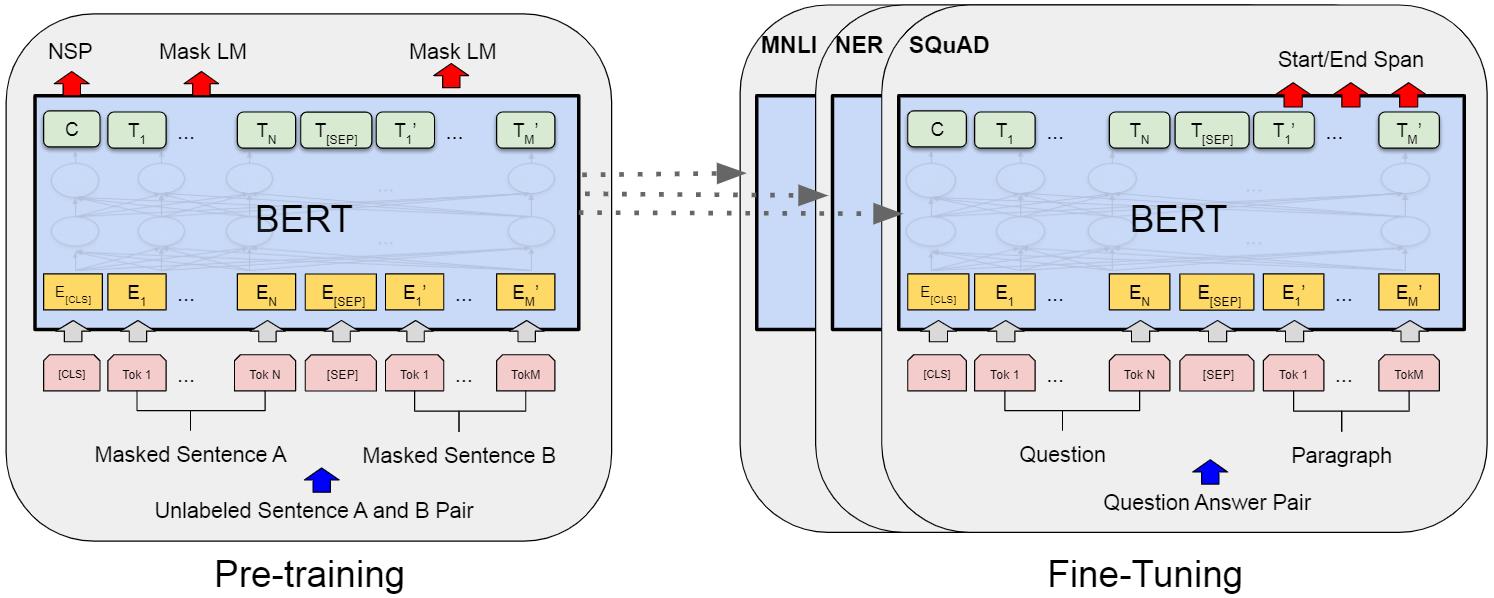
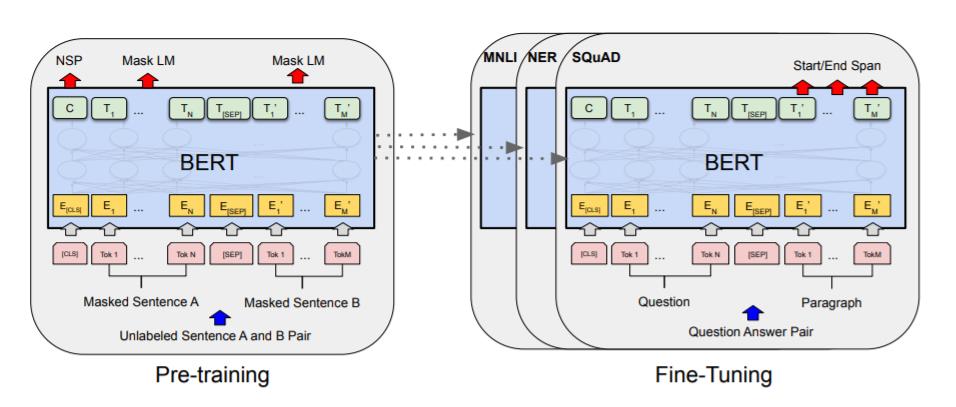
图1:BERT的整体预训练和微调程序。除了输出层之外,在预训练和微调中使用了相同的架构。相同的预训练模型参数被用来初始化不同下游任务的模型。在微调过程中,所有的参数都要进行微调。[CLS]是一个特殊的符号,加在每个输入例子的前面,[SEP]是一个特殊的分隔符。
BERT 的详细实现
在BERT中,有两个步骤:预训练和微调。
(1) 在预训练期间,模型在不同的预训练任务的无标签数据上进行训练。
(2) 对于微调,BERT模型首先用预训练的参数进行初始化,然后用下游任务的有标签数据对所有的参数进行微调。每个下游任务都有单独的微调模型,尽管它们是用相同的预训练参数初始化的。
BERT的一个显著特点是它在不同任务之间的统一架构。预训练的架构和最终的下游架构之间的差异很小。BERT的模型架构是一个多层双向Transformer encoder。
三个参数:
L:transformer块的个数
H:隐藏层的大小
A:在自注意力机制里面那个多头的头的个数
两个模型:
BERTBASE(L=12, H=768, A=12, Total Parameters=110M)
BERTLARGE(L=24, H=1024, A=16, Total Parameters=340M)
https://blog.csdn.net/zag666/article/details/127817715
BERT Transformer 使用的是双向的 self-attention,而GPT Transformer使用的是受限的self-attention,每个token只能关注其左边的上下文。
输入/输出表示
为了使BERT能够处理各种下游任务,我们的输入表示能够在一个标记序列中表示单个句子和一对句子(例如,〈问题,答案〉)。一个 "序列 "指的是输入到BERT的标记序列,它可能是一个单独的句子或两个句子挤在一起。
我们使用WordPiece嵌入,有30,000个标记词汇。 每个序列的第一个令牌总是一个特殊的分类令牌([CLS])。 与该标记相对应的最终隐藏状态被用作分类任务的集合序列表示。 句子对被打包成单一序列。
因为两个句子可能在一起,所以可以用两种方式来区分这些句子。 1.我们用一个特殊的标记([SEP])将它们分开。2.我们给每个标记添加一个学习过的嵌入标记,表明它是属于A句还是B句。
对于一个给定的标记,其输入表示是通过将相应的标记、段和位置嵌入相加而构建的。 图2是这种结构的可视化图。
预训练BERT
BERT整体是一个自编码语言模型(Autoencoder LM),它设计了两个任务来预训练该模型。第一个任务是采用 MaskLM 的方式来训练语言模型,随机屏蔽一定比例的输入标记,然后预测这些被屏蔽的标记。
第二个任务在双向语言模型的基础上额外增加了一个句子级别的连续性预测任务,即预测输入 BERT 的两段文本是否为连续的文本,引入这个任务可以更好地让模型学到连续的文本片段之间的关系。
AR:autoregressive,自回归模型;只考虑单侧的信息,典型的就是GPT。
AE:autoencoding,自编码模型;从损坏的输入数据中预测重建原始数据,可以使用上下文的信息,BERT用的就是AE。
AR模型,auto regressive,自回归模型。 自回归模型可以类比为早期的统计语言模型(Statistical Language Model),也就是根据上文预测下一个单词,或者根据下文预测前面的单词,只能考虑单侧信息,典型的如GPT,而ELMo 是将两个方向(从左至右和从右至左)的自回归模型进行了拼接,实现了双向语言模型,但本质上仍然属于自回归模型
AE模型,auto encoding,自编码模型。 从损坏的输入数据(相当于加入噪声)中预测重建原始数据,可以使用上下文的信息。BERT使用的就是AE。劣势是在下游的微调阶段不会出现掩码词,因此[MASK] 标记会导致预训练和微调阶段不一致的问题。
https://blog.csdn.net/codelady_g/article/details/124678760
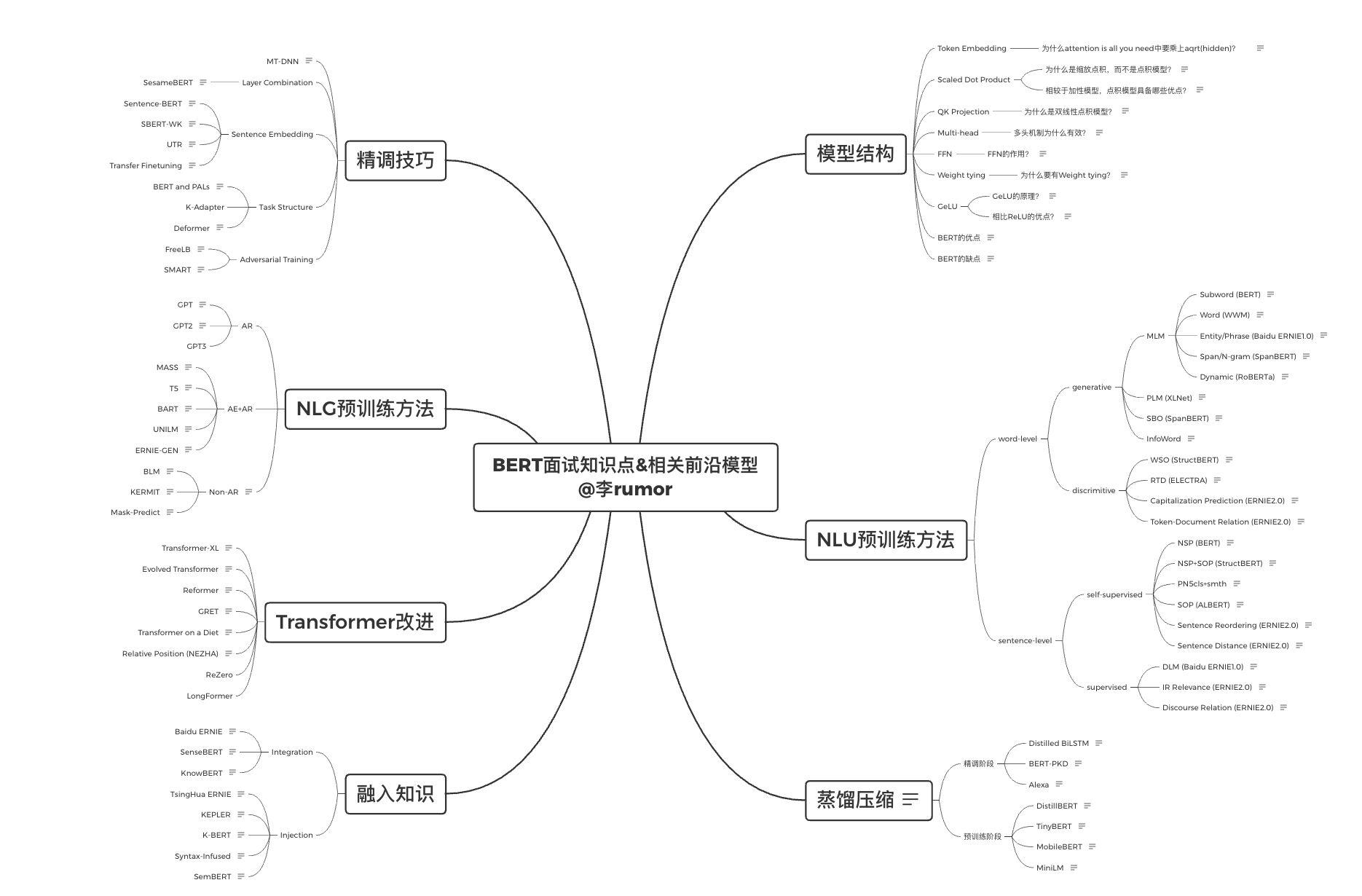
任务1:Masked LM(带掩码的语言模型)
深度双向模型严格来说比从左到右的模型或从左到右的模型和从右到左的模型的浅层串联更强大。不幸的是,标准的条件语言模型只能从左到右或从右到左进行训练,因为双向调节将允许每个词间接地 “看到自己”,并且该模型可以在多层次的背景下简单地预测目标词。
为了训练深度双向表征,我们只需随机屏蔽一定比例的输入标记,然后预测这些被屏蔽的标记。我们把这个过程称为 “masked LM”(MLM),常被称为Cloze任务。
在这种情况下,对应于掩码标记的最终隐藏向量被送入词汇的输出softmax,就像在标准LM中一样。在我们所有的实验中,我们随机屏蔽了每个序列中15%的所有WordPiece标记。我们只预测被屏蔽的词,而不是重建整个输入。
尽管这使我们能够得到一个双向的预训练模型,但缺点是我们在预训练和微调之间产生了不匹配,因为[MASK]标记在微调期间没有出现。
为了缓解这种情况,我们并不总是用实际的[MASK]标记来替换 "被屏蔽 "的单词。训练数据生成器随机选择15%的标记位置进行预测。如果选择了第i个令牌,我们就用(1)80%的概率替换成[MASK]标记(2)10%的概率随机标记(3)10%的概率未改变。然后,Ti将被用来预测具有交叉熵损失的原始标记。
80%的时间是采用[mask],my dog is hairy → my dog is [MASK]
10%的时间是随机取一个词来代替mask的词,my dog is hairy -> my dog is apple
10%的时间保持不变,my dog is hairy -> my dog is hairy
https://blog.csdn.net/zag666/article/details/127817715

为什么使用这个策略?
这是因为transformer要保持对每个输入token分布式的表征,否则Transformer很可能会记住这个[MASK]就是"hairy"(这个地方的理解,强行记住了位置和masked的分布,而没有真正理解上下文),从而导致若训练样本和微调的样本mask不一致的情况下,模型预测出现很大的偏差。
如果仅使用[MASK]或者随机的词,那么模型可能学习到的信息都是错误的单词(认为这个地方的单词就是不正确的);
若仅使用正确的单词,那么模型学到的方法就是直接copy(根据学到的上下文,直接断定),从而学不到完整的上下文信息。
综上三个特点,必须在正确的信息(10%)、未知的信息(80% MASK,使模型具有预测能力)、错误的信息(加入噪声10%,使模型具有纠错能力)都有的情况下,模型才能获取全局全量的信息。
链接:https://blog.csdn.net/codelady_g/article/details/124678760
任务二:下一句预测(NSP)
许多重要的下游任务,如问答(QA)和自然语言推理(NLI)都是基于对两个句子之间关系的理解,而语言建模并不能直接捕捉到这种关系。 为了训练一个能够理解句子关系的模型,我们对一个二进制的下一句预测任务进行了预训练,该任务可以从任何单语语料库中简单地生成。 具体来说,在为每个预训练例子选择句子A和B时,50%的概率B是A后面的实际下一句(标记为IsNext),50%的概率是语料库中的一个随机句子(标记为NotNext)。 针对这一任务的预训练对QA和NLI都非常有益。
https://blog.csdn.net/zag666/article/details/127817715
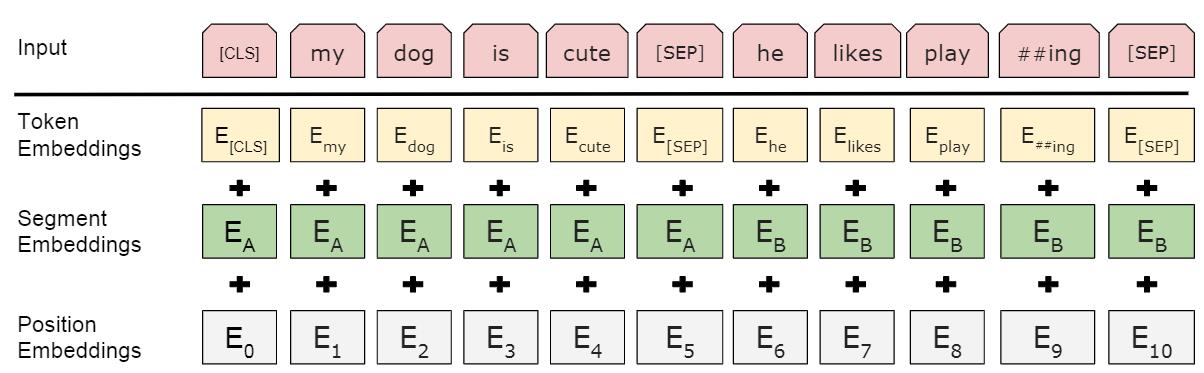
图2:BERT输入表示。输入嵌入是标记嵌入、分段嵌入和位置嵌入的总和。
token embedding :将各个词转换成固定维度的向量。在BERT中,每个词会被转换成768维的向量表示。在实际代码实现中,输入文本在送入token embeddings 层之前要先进行tokenization处理。此外,两个特殊的token会被插入到tokenization的结果的开头 ([CLS])和结尾 ([SEP])
segment embedding: 用于区分一个token属于句子对中的哪个句子。Segment Embeddings 层只有两种向量表示。前一个向量是把0赋给第一个句子中的各个token, 后一个向量是把1赋给第二个句子中的各个token。如果输入仅仅只有一个句子,那么它的segment embedding就是全0 。
position embedding:Transformers无法编码输入的序列的顺序性,所以要在各个位置上学习一个向量表示来将序列顺序的信息编码进来。加入position embeddings会让BERT理解下面下面这种情况,“ I think, therefore I am ”,第一个 “I” 和第二个 “I”应该有着不同的向量表示。
这3种embedding都是768维的,最后要将其按元素相加,得到每一个token最终的768维的向量表示。
链接:https://blog.csdn.net/codelady_g/article/details/124678760
微调BERT
微调是直接的,因为Transformer中的自我注意机制允许BERT通过替换适当的输入和输出来模拟许多下游任务,无论它们涉及单个文本还是文本对。对于涉及文本对的应用,一个常见的模式是在应用双向交叉注意力之前对文本对进行独立编码。
BERT则使用自我注意机制来统一这两个阶段,因为用自我注意对串联的文本对进行编码,有效地包括两个句子之间的双向交叉注意力。
对于每个任务,我们只需将特定任务的输入和输出插入BERT,并对所有参数进行端到端的微调。在输入端,预训练中的句子A和句子B类似于(1)转述中的句子对,(2)必然性中的假设-前提对,(3)问题回答中的问题-段落对,和(4) 文本分类或序列标签中的退化文本-∅对。在输出层,标记表征被送入输出层,用于标记级任务,如序列标签或问题解答,而[CLS]表征被送入输出层,用于分类,如包含关系或情感分析。
与预训练相比,微调的成本很低。从完全相同的预训练模型开始,最多只需1小时就可以在一个独立的云TPU上完成所有的结果,或者在一个GPU上多花几个小时。
链接:https://blog.csdn.net/zag666/article/details/127817715
BERT最终输出的就是句子中每个token的768维的向量,第一个位置是[CLS],它的向量表示蕴含了这个句子整体的信息,用于做文本分类等句子级任务;对于序列标注等token级任务,就需要使用到每一个token的向量表示。只要将768维向量通过一个线性层映射到最终的分类空间中即可。
文链接:https://blog.csdn.net/codelady_g/article/details/124678760
https://blog.csdn.net/zag666/article/details/127817715
https://zhuanlan.zhihu.com/p/46652512
https://baijiahao.baidu.com/s?id=1711778702724114051&wfr=spider&for=pc
BERT视频:
https://www.bilibili.com/video/BV1PL411M7eQ/?spm_id_from=333.337.search-card.all.click&vd_source=6292df769fba3b00eb2ff1859b99d79e BERT 论文逐段精读【论文精读】李沐
https://www.bilibili.com/video/BV1yU4y1E7Ns/?spm_id_from=333.337.search-card.all.click&vd_source=6292df769fba3b00eb2ff1859b99d79e 李沐 69 BERT预训练【动手学深度学习v2】 有代码
https://www.bilibili.com/video/BV15L4y1v7ts/?spm_id_from=333.788.recommend_more_video.0&vd_source=6292df769fba3b00eb2ff1859b99d79e 李沐 70 BERT微调【动手学深度学习v2】有代码
https://www.bilibili.com/video/BV1LA411n73X?p=20&vd_source=6292df769fba3b00eb2ff1859b99d79e 【莫烦Python】机器要说话 NLP 自然语言处理教程 W2V Transformer BERT Seq2Seq GPT
https://www.bilibili.com/video/BV1NJ411o7u3?p=10&vd_source=6292df769fba3b00eb2ff1859b99d79e 【新全】2019 NLP(自然语言处理)之Bert课程 【个别地方有错误】
https://www.bilibili.com/video/BV1Kq4y1H7FL/?spm_id_from=333.788.recommend_more_video.1&vd_source=6292df769fba3b00eb2ff1859b99d79e 68 Transformer【动手学深度学习v2】





[Python人工智能] 三十三.Bert模型 keras-bert库构建Bert模型实现文本分类
从本专栏开始,作者正式研究Python深度学习、神经网络及人工智能相关知识。前一篇文章开启了新的内容——Bert,首先介绍Keras-bert库安装及基础用法,这将为后续文本分类、命名实体识别提供帮助。这篇文章将通过keras-bert库构建Bert模型,并实现文本分类工作。基础性文章,希望对您有所帮助!
这篇文章主要参考“山阴少年”大佬的博客,并结合自己的经验,对其代码进行了详细的复现和理解。希望对您有所帮助,尤其是初学者,也强烈推荐大家关注这位老师的文章。
文章目录
本专栏主要结合作者之前的博客、AI经验和相关视频及论文介绍,后面随着深入会讲解更多的Python人工智能案例及应用。基础性文章,希望对您有所帮助,如果文章中存在错误或不足之处,还请海涵!作者作为人工智能的菜鸟,希望大家能与我在这一笔一划的博客中成长起来。写了这么多年博客,尝试第一个付费专栏,为小宝赚点奶粉钱,但更多博客尤其基础性文章,还是会继续免费分享,该专栏也会用心撰写,望对得起读者。如果有问题随时私聊我,只望您能从这个系列中学到知识,一起加油喔~
- Keras下载地址:https://github.com/eastmountyxz/AI-for-Keras
- TensorFlow下载地址:https://github.com/eastmountyxz/AI-for-TensorFlow
前文赏析:
- [Python人工智能] 一.TensorFlow2.0环境搭建及神经网络入门
- [Python人工智能] 二.TensorFlow基础及一元直线预测案例
- [Python人工智能] 三.TensorFlow基础之Session、变量、传入值和激励函数
- [Python人工智能] 四.TensorFlow创建回归神经网络及Optimizer优化器
- [Python人工智能] 五.Tensorboard可视化基本用法及绘制整个神经网络
- [Python人工智能] 六.TensorFlow实现分类学习及MNIST手写体识别案例
- [Python人工智能] 七.什么是过拟合及dropout解决神经网络中的过拟合问题
- [Python人工智能] 八.卷积神经网络CNN原理详解及TensorFlow编写CNN
- [Python人工智能] 九.gensim词向量Word2Vec安装及《庆余年》中文短文本相似度计算
- [Python人工智能] 十.Tensorflow+Opencv实现CNN自定义图像分类案例及与机器学习KNN图像分类算法对比
- [Python人工智能] 十一.Tensorflow如何保存神经网络参数
- [Python人工智能] 十二.循环神经网络RNN和LSTM原理详解及TensorFlow编写RNN分类案例
- [Python人工智能] 十三.如何评价神经网络、loss曲线图绘制、图像分类案例的F值计算
- [Python人工智能] 十四.循环神经网络LSTM RNN回归案例之sin曲线预测
- [Python人工智能] 十五.无监督学习Autoencoder原理及聚类可视化案例详解
- [Python人工智能] 十六.Keras环境搭建、入门基础及回归神经网络案例
- [Python人工智能] 十七.Keras搭建分类神经网络及MNIST数字图像案例分析
- [Python人工智能] 十八.Keras搭建卷积神经网络及CNN原理详解
[Python人工智能] 十九.Keras搭建循环神经网络分类案例及RNN原理详解 - [Python人工智能] 二十.基于Keras+RNN的文本分类vs基于传统机器学习的文本分类
- [Python人工智能] 二十一.Word2Vec+CNN中文文本分类详解及与机器学习(RF\\DTC\\SVM\\KNN\\NB\\LR)分类对比
- [Python人工智能] 二十二.基于大连理工情感词典的情感分析和情绪计算
- [Python人工智能] 二十三.基于机器学习和TFIDF的情感分类(含详细的NLP数据清洗)
- [Python人工智能] 二十四.易学智能GPU搭建Keras环境实现LSTM恶意URL请求分类
- [Python人工智能] 二十六.基于BiLSTM-CRF的医学命名实体识别研究(上)数据预处理
- [Python人工智能] 二十七.基于BiLSTM-CRF的医学命名实体识别研究(下)模型构建
- [Python人工智能] 二十八.Keras深度学习中文文本分类万字总结(CNN、TextCNN、LSTM、BiLSTM、BiLSTM+Attention)
- [Python人工智能] 二十九.什么是生成对抗网络GAN?基础原理和代码普及(1)
- [Python人工智能] 三十.Keras深度学习构建CNN识别阿拉伯手写文字图像
- [Python人工智能] 三十一.Keras实现BiLSTM微博情感分类和LDA主题挖掘分析
- [Python人工智能] 三十二.Bert模型 (1)Keras-bert基本用法及预训练模型
- [Python人工智能] 三十三.Bert模型 (2)keras-bert库构建Bert模型实现文本分类
一.Bert模型引入
Bert模型的原理知识将在后面的文章介绍,主要结合结合谷歌论文和模型优势讲解。
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- https://arxiv.org/pdf/1810.04805.pdf
- https://github.com/google-research/bert

BERT(Bidirectional Encoder Representation from Transformers)是一个预训练的语言表征模型,是由谷歌AI团队在2018年提出。该模型在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人的成绩,并且在11种不同NLP测试中创出最佳成绩,包括将GLUE基准推至80.4%(绝对改进7.6%),MultiNLI准确度达到86.7% (绝对改进率5.6%)等。可以预见的是,BERT将为NLP带来里程碑式的改变,也是NLP领域近期最重要的进展。
Bert强调了不再像以往一样采用传统的单向语言模型或者把两个单向语言模型进行浅层拼接的方法进行预训练,而是采用新的masked language model(MLM),以致能生成深度的双向语言表征。其模型框架图如下所示,后面的文章再详细介绍,这里仅作引入,推荐读者阅读原文。

二.keras-bert安装感想
首先,我们通过github可以看到开源代码的结构,如下图。
├── chinese_L-12_H-768_A-12(BERT中文预训练模型)
│ ├── bert_config.json
│ ├── bert_model.ckpt.data-00000-of-00001
│ ├── bert_model.ckpt.index
│ ├── bert_model.ckpt.meta
│ └── vocab.txt
├── data(数据集)
│ └── sougou_mini
│ ├── test.csv
│ └── train.csv
├── label.json(类别词典,生成文件)
├── model_evaluate.py(模型评估脚本)
├── model_predict.py(模型预测脚本)
├── model_train.py(模型训练脚本)
└── requirements.txt
然而,在安装过程中我们需要注意各个版本之间的兼容性,尤其是一些冷门的扩展包,否则会提示各种错误。

keras-bert库最适合的版本如下,在requirements.txt文件中可以看到。
- pandas==0.23.4
- Keras==2.3.1
- keras_bert==0.83.0
- numpy==1.16.4
安装过程建议使用:
- pip install keras-bert==0.83.0
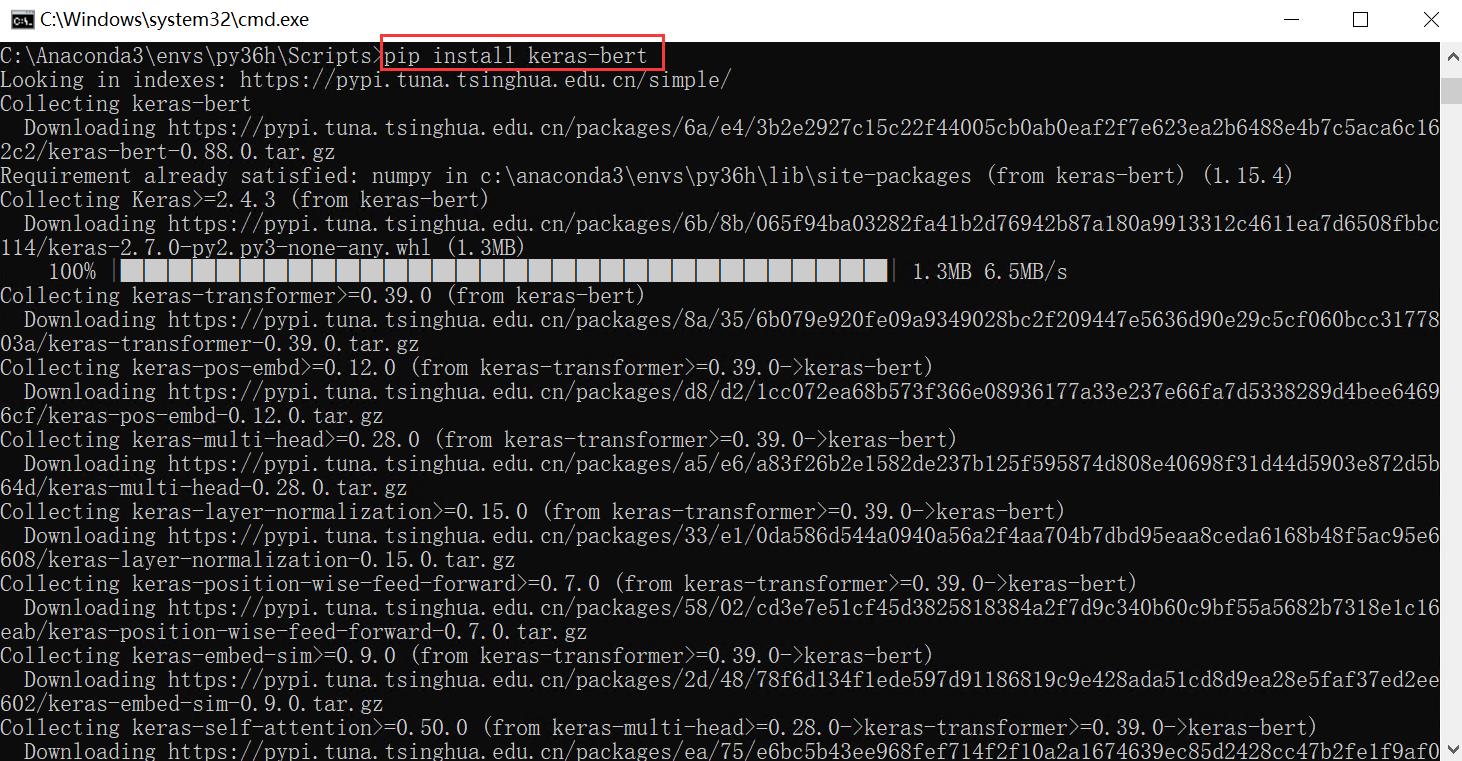
但是,有时候我们配置的扩展包会已经和其他环境适配,比如keras。这里我们需要去PYPI查看Keras-bert可用的版本问题。
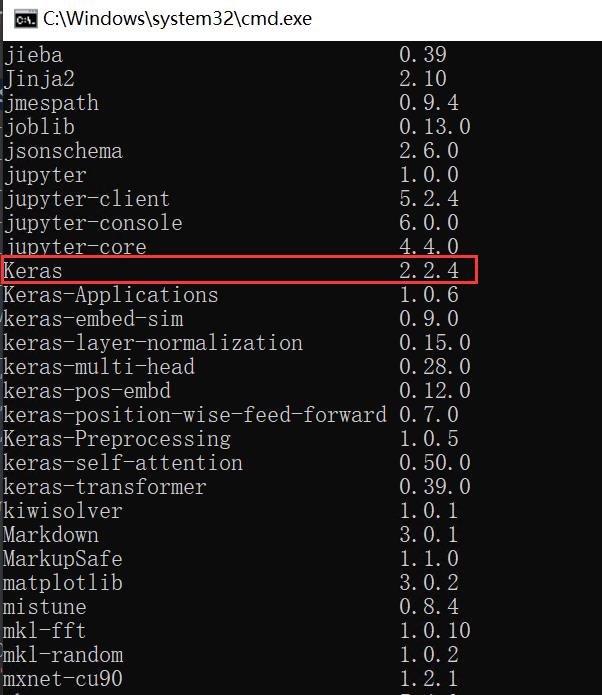
作者的Kears版本为2.2.4,之前安装就会遇到各种问题,最后将keras-bert安装为“0.81.1”才成功运行,这是我们需要注意的。

个人感觉Python环境兼容问题一直困扰大家,也不知道有没有好的解决方法?后面我准备学习下docker来进行环境镜像,也可以通过下面命令快速安装环境。
- pip freeze >requirements.txt

错误修改
如果提示“ImportError: cannot import name ‘Adam’ from ‘keras.optimizers’”,我们可以进行如下修改:
- from keras.optimizers import adam_v2
- opt = adam_v2.Adam(learning_rate=lr, decay=lr/epochs)
其原因是keras库更新后无法按照原方式导入包,打开optimizers.py源码发现两句关键代码更改。但最终修改方法还是版本兼容问题。
- from keras.optimizers import Adam
- opt = Adam(lr=lr, decay=lr/epochs)

三.Bert模型构建分类器
1.数据集
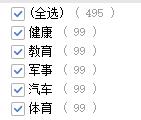
在文本挖掘中有两个比较常用的数据集,分别为:
- sougou小分类数据集
– 5个类别:体育、健康、军事、教育、汽车。
– 训练集和测试集:训练集每个分类800条样本,测试集每个分类100条样本。 - THUCNews数据集
– 10个类别:体育, 财经, 房产, 家居, 教育, 科技, 时尚, 时政, 游戏, 娱乐。
– 训练集和测试集:训练集 5000x10,测试集 1000x10。
本文采用sougou数据集,如下图所示包括label和content。

类别如下:

2.模型构建
(1) 数据预处理
在keras-bert里面,我们使用Tokenizer类来将文本拆分成字并生成相应的id,通过定义字典存放token和id的映射。
- TOKEN_CLS:the token represents classification
- TOKEN_SEP:the token represents separator
- TOKEN_UNK:the token represents unknown token
# -*- coding: utf-8 -*-
"""
Created on Wed Nov 24 00:09:48 2021
@author: xiuzhang
引用:https://github.com/percent4/keras_bert_text_classification
"""
import json
import codecs
import pandas as pd
import numpy as np
from keras_bert import load_trained_model_from_checkpoint, Tokenizer
from keras.layers import *
from keras.models import Model
from keras.optimizers import Adam
#from keras.optimizers import adam_v2
maxlen = 300
BATCH_SIZE = 8
config_path = 'chinese_L-12_H-768_A-12/bert_config.json'
checkpoint_path = 'chinese_L-12_H-768_A-12/bert_model.ckpt'
dict_path = 'chinese_L-12_H-768_A-12/vocab.txt'
#读取vocab词典
token_dict =
with codecs.open(dict_path, 'r', 'utf-8') as reader:
for line in reader:
token = line.strip()
token_dict[token] = len(token_dict)
#------------------------------------------类函数定义--------------------------------------
#词典中添加否则Unknown
class OurTokenizer(Tokenizer):
def _tokenize(self, text):
R = []
for c in text:
if c in self._token_dict:
R.append(c)
else:
R.append('[UNK]') #剩余的字符是[UNK]
return R
tokenizer = OurTokenizer(token_dict)
#数据填充
def seq_padding(X, padding=0):
L = [len(x) for x in X]
ML = max(L)
return np.array([
np.concatenate([x, [padding] * (ML - len(x))]) if len(x) < ML else x for x in X
])
class DataGenerator:
def __init__(self, data, batch_size=BATCH_SIZE):
self.data = data
self.batch_size = batch_size
self.steps = len(self.data) // self.batch_size
if len(self.data) % self.batch_size != 0:
self.steps += 1
def __len__(self):
return self.steps
def __iter__(self):
while True:
idxs = list(range(len(self.data)))
np.random.shuffle(idxs)
X1, X2, Y = [], [], []
for i in idxs:
d = self.data[i]
text = d[0][:maxlen]
x1, x2 = tokenizer.encode(first=text)
y = d[1]
X1.append(x1)
X2.append(x2)
Y.append(y)
if len(X1) == self.batch_size or i == idxs[-1]:
X1 = seq_padding(X1)
X2 = seq_padding(X2)
Y = seq_padding(Y)
yield [X1, X2], Y
[X1, X2, Y] = [], [], []
#构建模型
def create_cls_model(num_labels):
bert_model = load_trained_model_from_checkpoint(config_path, checkpoint_path, seq_len=None)
for layer in bert_model.layers:
layer.trainable = True
x1_in = Input(shape=(None,))
x2_in = Input(shape=(None,))
x = bert_model([x1_in, x2_in])
cls_layer = Lambda(lambda x: x[:, 0])(x) #取出[CLS]对应的向量用来做分类
p = Dense(num_labels, activation='softmax')(cls_layer) #多分类
model = Model([x1_in, x2_in], p)
model.compile(
loss='categorical_crossentropy',
optimizer=Adam(1e-5),
#optimizer=adam_v2.Adam(1e-5),
metrics=['accuracy']
)
model.summary()
return model
#------------------------------------------主函数-----------------------------------------
if __name__ == '__main__':
#数据预处理
train_df = pd.read_csv("data/sougou_mini/train.csv").fillna(value="")
test_df = pd.read_csv("data/sougou_mini/test.csv").fillna(value="")
print("begin data processing...")
labels = train_df["label"].unique()
with open("label.json", "w", encoding="utf-8") as f:
f.write(json.dumps(dict(zip(range(len(labels)), labels)), ensure_ascii=False, indent=2))
train_data = []
test_data = []
for i in range(train_df.shape[0]):
label, content = train_df.iloc[i, :]
label_id = [0] * len(labels)
for j, _ in enumerate(labels):
if _ == label:
label_id[j] = 1
train_data.append((content, label_id))
print(train_data[0])
for i in range(test_df.shape[0]):
label, content = test_df.iloc[i, :]
label_id = [0] * len(labels)
for j, _ in enumerate(labels):
if _ == label:
label_id[j] = 1
test_data.append((content, label_id))
print(len(train_data),len(test_data))
print("finish data processing!")
预处理输出结果如下图所示,[1,0,0,0,0]对应第一类体育。

同时在本地保存类别文件,如下图所示:

(2) 模型训练
模型训练代码如下,这里给出主函数的核心代码:
#------------------------------------------主函数-----------------------------------------
if __name__ == '__main__':
#数据预处理
train_df = pd.read_csv("data/sougou_mini/train.csv").fillna(value="")
test_df = pd.read_csv("data/sougou_mini/test.csv").fillna(value="")
print("begin data processing...")
labels = train_df["label"].unique()
with open("label.json", "w", encoding="utf-8") as f:
f.write(json.dumps(dict(zip(range(len(labels)), labels)), ensure_ascii=False, indent=2))
train_data = []
test_data = []
for i in range(train_df.shape[0]):
label, content = train_df.iloc[i, :]
label_id = [0] * len(labels)
for j, _ in enumerate(labels):
if _ == label:
label_id[j] = 1
train_data.append((content, label_id))
print(train_data[0])
for i in range(test_df.shape[0]):
label, content = test_df.iloc[i, :]
label_id = [0] * len(labels)
for j, _ in enumerate(labels):
if _ == label:
label_id[j] = 1
test_data.append((content, label_id))
print(len(train_data),len(test_data))
print("finish data processing!\\n")
#模型训练
model = create_cls_model(len(labels))
train_D = DataGenerator(train_data)
test_D = DataGenerator(test_data)
print("begin model training...")
model.fit_generator(
train_D.__iter__(),
steps_per_epoch=len(train_D),
epochs=3,
validation_data=test_D.__iter__(),
validation_steps=len(test_D)
)
print("finish model training!")
#模型保存
model.save('cls_cnews.h5')
print("Model saved!")
result = model.evaluate_generator(test_D.__iter__(), steps=len(test_D))
print("模型评估结果:", result)
其中模型结构如下,我们提取 [CLS] 对应的向量,然后构建模型和全连接层,激活函数使用Softmax,最终完成分类任务。核心代码:
- model = create_cls_model(len(labels))
- model.fit_generator()
- result = model.evaluate_generator(test_D.iter(), steps=len(test_D))

训练过程输出结果如下:(花了3小时,还是要使用GPU才行)
Skipping registering GPU devices...
begin model training...
Epoch 1/3
C:\\Users\\PC\\Desktop\\bert-classifier\\blog33-kerasbert-01-classifier.py:144: UserWarning: `Model.fit_generator` is deprecated and will be removed in a future version. Please use `Model.fit`, which supports generators.
model.fit_generator(
500/500 [==============================] - 3386s 7s/step - loss: 0.1906 - accuracy: 0.9370 - val_loss: 0.0768 - val_accuracy: 0.9737
Epoch 2/3
500/500 [==============================] - 3356s 7s/step - loss: 0.0379 - accuracy: 0.9872 - val_loss: 0.0687 - val_accuracy: 0.9758
Epoch 3/3
500/500 [==============================] - 3356s 7s/step - loss: 0.0180 - accuracy: 0.9952 - val_loss: 0.0953 - val_accuracy: 0.9657
finish model training!
Model saved!
模型评估结果: [0.08730510622262955, 0.9696969985961914]
同时将模型存储至本地。
(3) GPU版模型训练
GPU配置的核心代码如下:
[Python人工智能] 三十三.Bert模型 keras-bert库构建Bert模型实现文本分类