[Python人工智能] 三十三.Bert模型 keras-bert库构建Bert模型实现文本分类
Posted Eastmount
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[Python人工智能] 三十三.Bert模型 keras-bert库构建Bert模型实现文本分类相关的知识,希望对你有一定的参考价值。
从本专栏开始,作者正式研究Python深度学习、神经网络及人工智能相关知识。前一篇文章开启了新的内容——Bert,首先介绍Keras-bert库安装及基础用法,这将为后续文本分类、命名实体识别提供帮助。这篇文章将通过keras-bert库构建Bert模型,并实现文本分类工作。基础性文章,希望对您有所帮助!
这篇文章主要参考“山阴少年”大佬的博客,并结合自己的经验,对其代码进行了详细的复现和理解。希望对您有所帮助,尤其是初学者,也强烈推荐大家关注这位老师的文章。
文章目录
本专栏主要结合作者之前的博客、AI经验和相关视频及论文介绍,后面随着深入会讲解更多的Python人工智能案例及应用。基础性文章,希望对您有所帮助,如果文章中存在错误或不足之处,还请海涵!作者作为人工智能的菜鸟,希望大家能与我在这一笔一划的博客中成长起来。写了这么多年博客,尝试第一个付费专栏,为小宝赚点奶粉钱,但更多博客尤其基础性文章,还是会继续免费分享,该专栏也会用心撰写,望对得起读者。如果有问题随时私聊我,只望您能从这个系列中学到知识,一起加油喔~
- Keras下载地址:https://github.com/eastmountyxz/AI-for-Keras
- TensorFlow下载地址:https://github.com/eastmountyxz/AI-for-TensorFlow
前文赏析:
- [Python人工智能] 一.TensorFlow2.0环境搭建及神经网络入门
- [Python人工智能] 二.TensorFlow基础及一元直线预测案例
- [Python人工智能] 三.TensorFlow基础之Session、变量、传入值和激励函数
- [Python人工智能] 四.TensorFlow创建回归神经网络及Optimizer优化器
- [Python人工智能] 五.Tensorboard可视化基本用法及绘制整个神经网络
- [Python人工智能] 六.TensorFlow实现分类学习及MNIST手写体识别案例
- [Python人工智能] 七.什么是过拟合及dropout解决神经网络中的过拟合问题
- [Python人工智能] 八.卷积神经网络CNN原理详解及TensorFlow编写CNN
- [Python人工智能] 九.gensim词向量Word2Vec安装及《庆余年》中文短文本相似度计算
- [Python人工智能] 十.Tensorflow+Opencv实现CNN自定义图像分类案例及与机器学习KNN图像分类算法对比
- [Python人工智能] 十一.Tensorflow如何保存神经网络参数
- [Python人工智能] 十二.循环神经网络RNN和LSTM原理详解及TensorFlow编写RNN分类案例
- [Python人工智能] 十三.如何评价神经网络、loss曲线图绘制、图像分类案例的F值计算
- [Python人工智能] 十四.循环神经网络LSTM RNN回归案例之sin曲线预测
- [Python人工智能] 十五.无监督学习Autoencoder原理及聚类可视化案例详解
- [Python人工智能] 十六.Keras环境搭建、入门基础及回归神经网络案例
- [Python人工智能] 十七.Keras搭建分类神经网络及MNIST数字图像案例分析
- [Python人工智能] 十八.Keras搭建卷积神经网络及CNN原理详解
[Python人工智能] 十九.Keras搭建循环神经网络分类案例及RNN原理详解 - [Python人工智能] 二十.基于Keras+RNN的文本分类vs基于传统机器学习的文本分类
- [Python人工智能] 二十一.Word2Vec+CNN中文文本分类详解及与机器学习(RF\\DTC\\SVM\\KNN\\NB\\LR)分类对比
- [Python人工智能] 二十二.基于大连理工情感词典的情感分析和情绪计算
- [Python人工智能] 二十三.基于机器学习和TFIDF的情感分类(含详细的NLP数据清洗)
- [Python人工智能] 二十四.易学智能GPU搭建Keras环境实现LSTM恶意URL请求分类
- [Python人工智能] 二十六.基于BiLSTM-CRF的医学命名实体识别研究(上)数据预处理
- [Python人工智能] 二十七.基于BiLSTM-CRF的医学命名实体识别研究(下)模型构建
- [Python人工智能] 二十八.Keras深度学习中文文本分类万字总结(CNN、TextCNN、LSTM、BiLSTM、BiLSTM+Attention)
- [Python人工智能] 二十九.什么是生成对抗网络GAN?基础原理和代码普及(1)
- [Python人工智能] 三十.Keras深度学习构建CNN识别阿拉伯手写文字图像
- [Python人工智能] 三十一.Keras实现BiLSTM微博情感分类和LDA主题挖掘分析
- [Python人工智能] 三十二.Bert模型 (1)Keras-bert基本用法及预训练模型
- [Python人工智能] 三十三.Bert模型 (2)keras-bert库构建Bert模型实现文本分类
一.Bert模型引入
Bert模型的原理知识将在后面的文章介绍,主要结合结合谷歌论文和模型优势讲解。
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- https://arxiv.org/pdf/1810.04805.pdf
- https://github.com/google-research/bert

BERT(Bidirectional Encoder Representation from Transformers)是一个预训练的语言表征模型,是由谷歌AI团队在2018年提出。该模型在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人的成绩,并且在11种不同NLP测试中创出最佳成绩,包括将GLUE基准推至80.4%(绝对改进7.6%),MultiNLI准确度达到86.7% (绝对改进率5.6%)等。可以预见的是,BERT将为NLP带来里程碑式的改变,也是NLP领域近期最重要的进展。
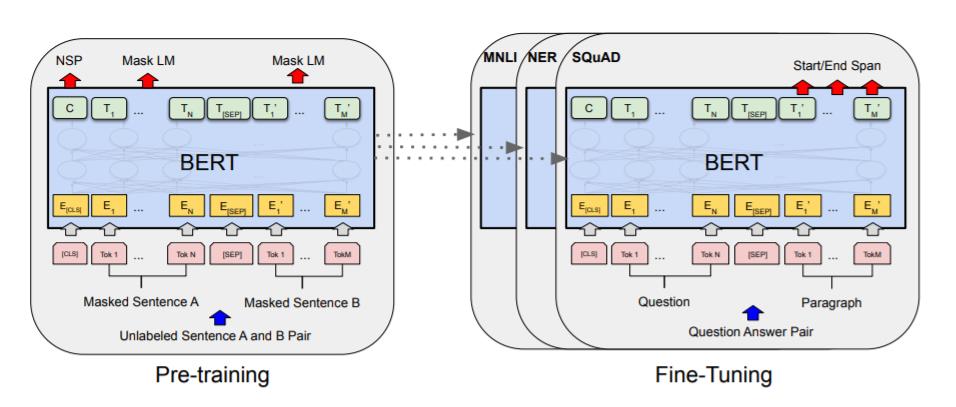
Bert强调了不再像以往一样采用传统的单向语言模型或者把两个单向语言模型进行浅层拼接的方法进行预训练,而是采用新的masked language model(MLM),以致能生成深度的双向语言表征。其模型框架图如下所示,后面的文章再详细介绍,这里仅作引入,推荐读者阅读原文。

二.keras-bert安装感想
首先,我们通过github可以看到开源代码的结构,如下图。
├── chinese_L-12_H-768_A-12(BERT中文预训练模型)
│ ├── bert_config.json
│ ├── bert_model.ckpt.data-00000-of-00001
│ ├── bert_model.ckpt.index
│ ├── bert_model.ckpt.meta
│ └── vocab.txt
├── data(数据集)
│ └── sougou_mini
│ ├── test.csv
│ └── train.csv
├── label.json(类别词典,生成文件)
├── model_evaluate.py(模型评估脚本)
├── model_predict.py(模型预测脚本)
├── model_train.py(模型训练脚本)
└── requirements.txt
然而,在安装过程中我们需要注意各个版本之间的兼容性,尤其是一些冷门的扩展包,否则会提示各种错误。

keras-bert库最适合的版本如下,在requirements.txt文件中可以看到。
- pandas==0.23.4
- Keras==2.3.1
- keras_bert==0.83.0
- numpy==1.16.4
安装过程建议使用:
- pip install keras-bert==0.83.0
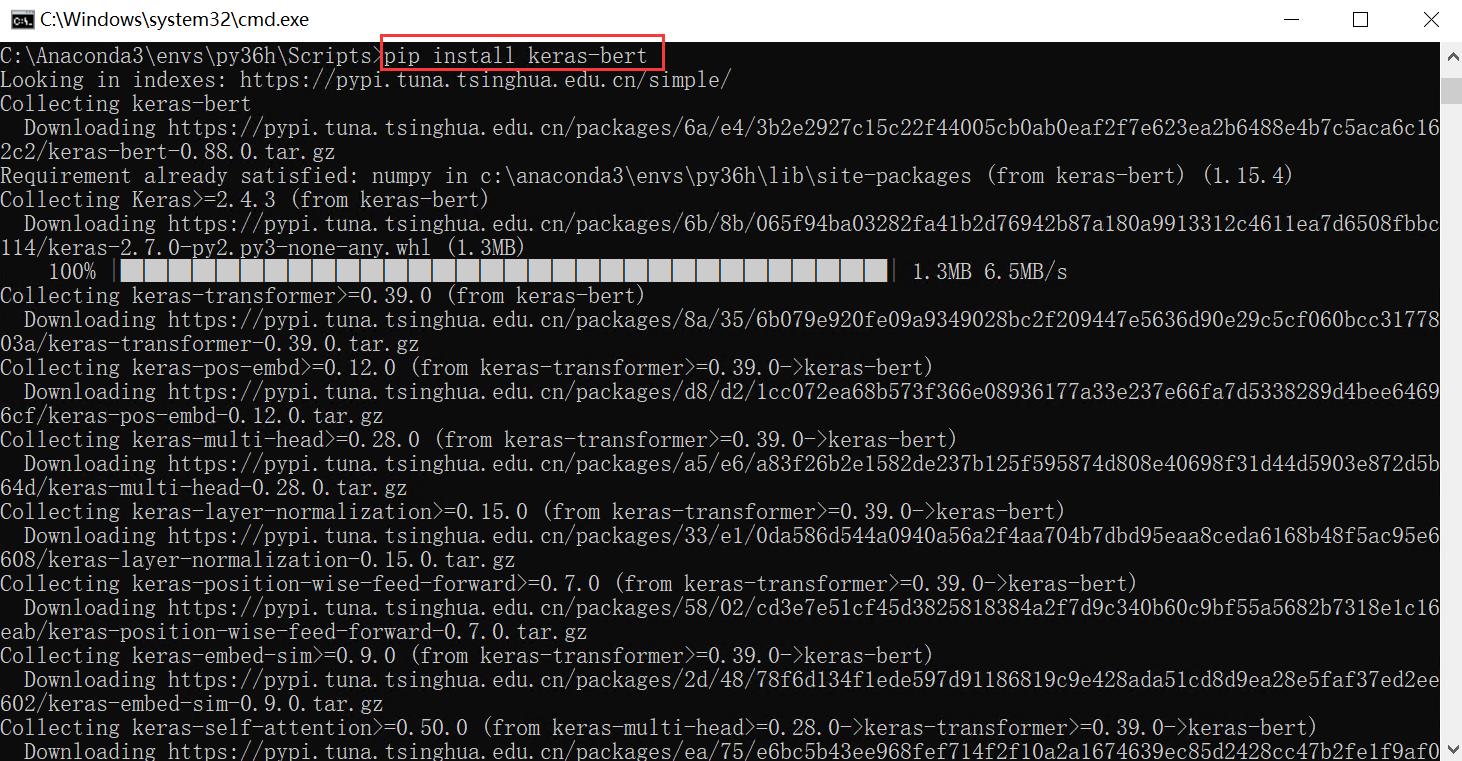
但是,有时候我们配置的扩展包会已经和其他环境适配,比如keras。这里我们需要去PYPI查看Keras-bert可用的版本问题。
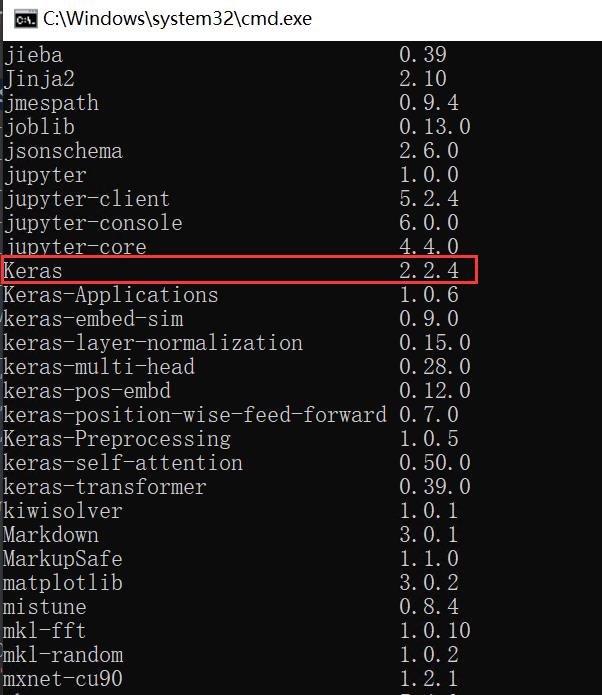
作者的Kears版本为2.2.4,之前安装就会遇到各种问题,最后将keras-bert安装为“0.81.1”才成功运行,这是我们需要注意的。

个人感觉Python环境兼容问题一直困扰大家,也不知道有没有好的解决方法?后面我准备学习下docker来进行环境镜像,也可以通过下面命令快速安装环境。
- pip freeze >requirements.txt

错误修改
如果提示“ImportError: cannot import name ‘Adam’ from ‘keras.optimizers’”,我们可以进行如下修改:
- from keras.optimizers import adam_v2
- opt = adam_v2.Adam(learning_rate=lr, decay=lr/epochs)
其原因是keras库更新后无法按照原方式导入包,打开optimizers.py源码发现两句关键代码更改。但最终修改方法还是版本兼容问题。
- from keras.optimizers import Adam
- opt = Adam(lr=lr, decay=lr/epochs)

三.Bert模型构建分类器
1.数据集
在文本挖掘中有两个比较常用的数据集,分别为:
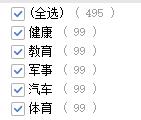
- sougou小分类数据集
– 5个类别:体育、健康、军事、教育、汽车。
– 训练集和测试集:训练集每个分类800条样本,测试集每个分类100条样本。 - THUCNews数据集
– 10个类别:体育, 财经, 房产, 家居, 教育, 科技, 时尚, 时政, 游戏, 娱乐。
– 训练集和测试集:训练集 5000x10,测试集 1000x10。
本文采用sougou数据集,如下图所示包括label和content。

类别如下:

2.模型构建
(1) 数据预处理
在keras-bert里面,我们使用Tokenizer类来将文本拆分成字并生成相应的id,通过定义字典存放token和id的映射。
- TOKEN_CLS:the token represents classification
- TOKEN_SEP:the token represents separator
- TOKEN_UNK:the token represents unknown token
# -*- coding: utf-8 -*-
"""
Created on Wed Nov 24 00:09:48 2021
@author: xiuzhang
引用:https://github.com/percent4/keras_bert_text_classification
"""
import json
import codecs
import pandas as pd
import numpy as np
from keras_bert import load_trained_model_from_checkpoint, Tokenizer
from keras.layers import *
from keras.models import Model
from keras.optimizers import Adam
#from keras.optimizers import adam_v2
maxlen = 300
BATCH_SIZE = 8
config_path = 'chinese_L-12_H-768_A-12/bert_config.json'
checkpoint_path = 'chinese_L-12_H-768_A-12/bert_model.ckpt'
dict_path = 'chinese_L-12_H-768_A-12/vocab.txt'
#读取vocab词典
token_dict =
with codecs.open(dict_path, 'r', 'utf-8') as reader:
for line in reader:
token = line.strip()
token_dict[token] = len(token_dict)
#------------------------------------------类函数定义--------------------------------------
#词典中添加否则Unknown
class OurTokenizer(Tokenizer):
def _tokenize(self, text):
R = []
for c in text:
if c in self._token_dict:
R.append(c)
else:
R.append('[UNK]') #剩余的字符是[UNK]
return R
tokenizer = OurTokenizer(token_dict)
#数据填充
def seq_padding(X, padding=0):
L = [len(x) for x in X]
ML = max(L)
return np.array([
np.concatenate([x, [padding] * (ML - len(x))]) if len(x) < ML else x for x in X
])
class DataGenerator:
def __init__(self, data, batch_size=BATCH_SIZE):
self.data = data
self.batch_size = batch_size
self.steps = len(self.data) // self.batch_size
if len(self.data) % self.batch_size != 0:
self.steps += 1
def __len__(self):
return self.steps
def __iter__(self):
while True:
idxs = list(range(len(self.data)))
np.random.shuffle(idxs)
X1, X2, Y = [], [], []
for i in idxs:
d = self.data[i]
text = d[0][:maxlen]
x1, x2 = tokenizer.encode(first=text)
y = d[1]
X1.append(x1)
X2.append(x2)
Y.append(y)
if len(X1) == self.batch_size or i == idxs[-1]:
X1 = seq_padding(X1)
X2 = seq_padding(X2)
Y = seq_padding(Y)
yield [X1, X2], Y
[X1, X2, Y] = [], [], []
#构建模型
def create_cls_model(num_labels):
bert_model = load_trained_model_from_checkpoint(config_path, checkpoint_path, seq_len=None)
for layer in bert_model.layers:
layer.trainable = True
x1_in = Input(shape=(None,))
x2_in = Input(shape=(None,))
x = bert_model([x1_in, x2_in])
cls_layer = Lambda(lambda x: x[:, 0])(x) #取出[CLS]对应的向量用来做分类
p = Dense(num_labels, activation='softmax')(cls_layer) #多分类
model = Model([x1_in, x2_in], p)
model.compile(
loss='categorical_crossentropy',
optimizer=Adam(1e-5),
#optimizer=adam_v2.Adam(1e-5),
metrics=['accuracy']
)
model.summary()
return model
#------------------------------------------主函数-----------------------------------------
if __name__ == '__main__':
#数据预处理
train_df = pd.read_csv("data/sougou_mini/train.csv").fillna(value="")
test_df = pd.read_csv("data/sougou_mini/test.csv").fillna(value="")
print("begin data processing...")
labels = train_df["label"].unique()
with open("label.json", "w", encoding="utf-8") as f:
f.write(json.dumps(dict(zip(range(len(labels)), labels)), ensure_ascii=False, indent=2))
train_data = []
test_data = []
for i in range(train_df.shape[0]):
label, content = train_df.iloc[i, :]
label_id = [0] * len(labels)
for j, _ in enumerate(labels):
if _ == label:
label_id[j] = 1
train_data.append((content, label_id))
print(train_data[0])
for i in range(test_df.shape[0]):
label, content = test_df.iloc[i, :]
label_id = [0] * len(labels)
for j, _ in enumerate(labels):
if _ == label:
label_id[j] = 1
test_data.append((content, label_id))
print(len(train_data),len(test_data))
print("finish data processing!")
预处理输出结果如下图所示,[1,0,0,0,0]对应第一类体育。

同时在本地保存类别文件,如下图所示:

(2) 模型训练
模型训练代码如下,这里给出主函数的核心代码:
#------------------------------------------主函数-----------------------------------------
if __name__ == '__main__':
#数据预处理
train_df = pd.read_csv("data/sougou_mini/train.csv").fillna(value="")
test_df = pd.read_csv("data/sougou_mini/test.csv").fillna(value="")
print("begin data processing...")
labels = train_df["label"].unique()
with open("label.json", "w", encoding="utf-8") as f:
f.write(json.dumps(dict(zip(range(len(labels)), labels)), ensure_ascii=False, indent=2))
train_data = []
test_data = []
for i in range(train_df.shape[0]):
label, content = train_df.iloc[i, :]
label_id = [0] * len(labels)
for j, _ in enumerate(labels):
if _ == label:
label_id[j] = 1
train_data.append((content, label_id))
print(train_data[0])
for i in range(test_df.shape[0]):
label, content = test_df.iloc[i, :]
label_id = [0] * len(labels)
for j, _ in enumerate(labels):
if _ == label:
label_id[j] = 1
test_data.append((content, label_id))
print(len(train_data),len(test_data))
print("finish data processing!\\n")
#模型训练
model = create_cls_model(len(labels))
train_D = DataGenerator(train_data)
test_D = DataGenerator(test_data)
print("begin model training...")
model.fit_generator(
train_D.__iter__(),
steps_per_epoch=len(train_D),
epochs=3,
validation_data=test_D.__iter__(),
validation_steps=len(test_D)
)
print("finish model training!")
#模型保存
model.save('cls_cnews.h5')
print("Model saved!")
result = model.evaluate_generator(test_D.__iter__(), steps=len(test_D))
print("模型评估结果:", result)
其中模型结构如下,我们提取 [CLS] 对应的向量,然后构建模型和全连接层,激活函数使用Softmax,最终完成分类任务。核心代码:
- model = create_cls_model(len(labels))
- model.fit_generator()
- result = model.evaluate_generator(test_D.iter(), steps=len(test_D))

训练过程输出结果如下:(花了3小时,还是要使用GPU才行)
Skipping registering GPU devices...
begin model training...
Epoch 1/3
C:\\Users\\PC\\Desktop\\bert-classifier\\blog33-kerasbert-01-classifier.py:144: UserWarning: `Model.fit_generator` is deprecated and will be removed in a future version. Please use `Model.fit`, which supports generators.
model.fit_generator(
500/500 [==============================] - 3386s 7s/step - loss: 0.1906 - accuracy: 0.9370 - val_loss: 0.0768 - val_accuracy: 0.9737
Epoch 2/3
500/500 [==============================] - 3356s 7s/step - loss: 0.0379 - accuracy: 0.9872 - val_loss: 0.0687 - val_accuracy: 0.9758
Epoch 3/3
500/500 [==============================] - 3356s 7s/step - loss: 0.0180 - accuracy: 0.9952 - val_loss: 0.0953 - val_accuracy: 0.9657
finish model training!
Model saved!
模型评估结果: [0.08730510622262955, 0.9696969985961914]
同时将模型存储至本地。
(3) GPU版模型训练
GPU配置的核心代码如下:
[Python人工智能] 三十二.Bert模型 Keras-bert基本用法及预训练模型
[Python人工智能] 三十五.基于Transformer的商品评论情感分析 机器学习和深度学习的Baseline模型实现
[Python人工智能] 三十六.基于Transformer的商品评论情感分析 keras构建多头自注意力(Transformer)模型