Python爬虫-爬取开心网主页(有登录界面-利用cookie)
Posted 夏至稻花如白练,大暑池畔赏红莲
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫-爬取开心网主页(有登录界面-利用cookie)相关的知识,希望对你有一定的参考价值。
爬取开心网主页内容
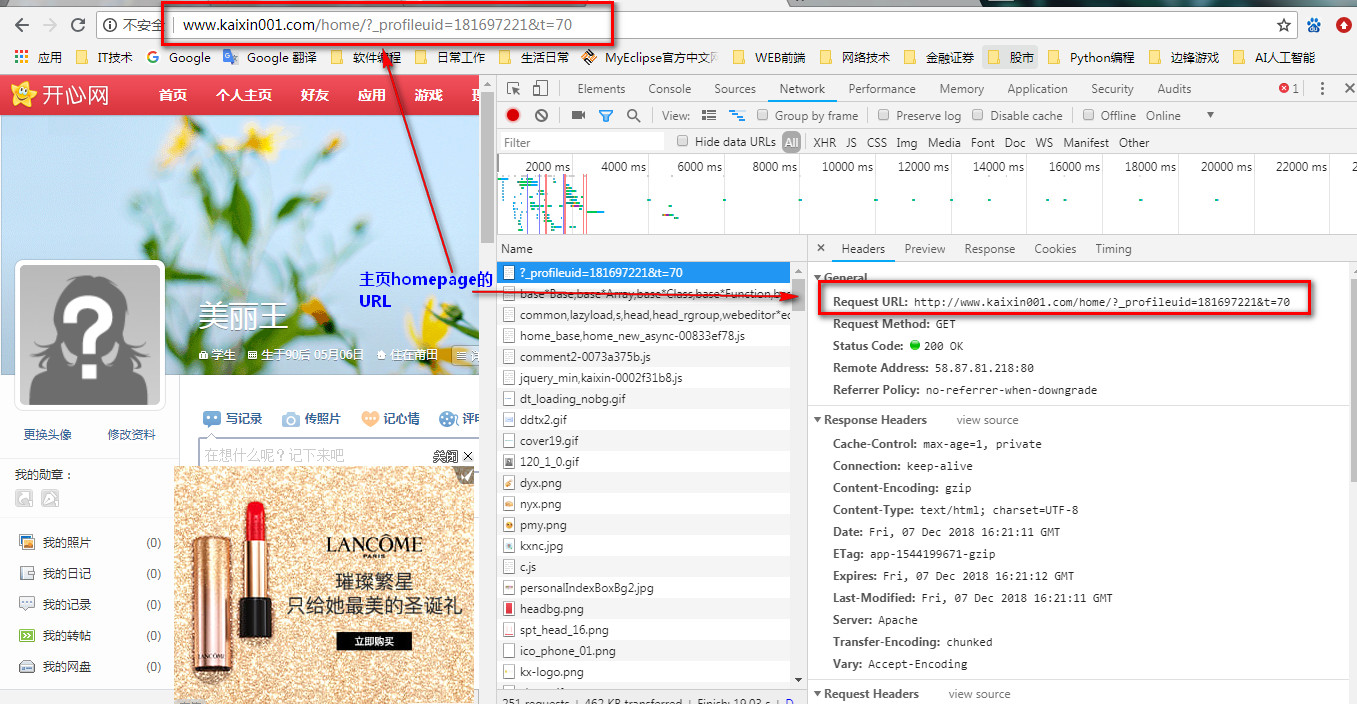
==========================================
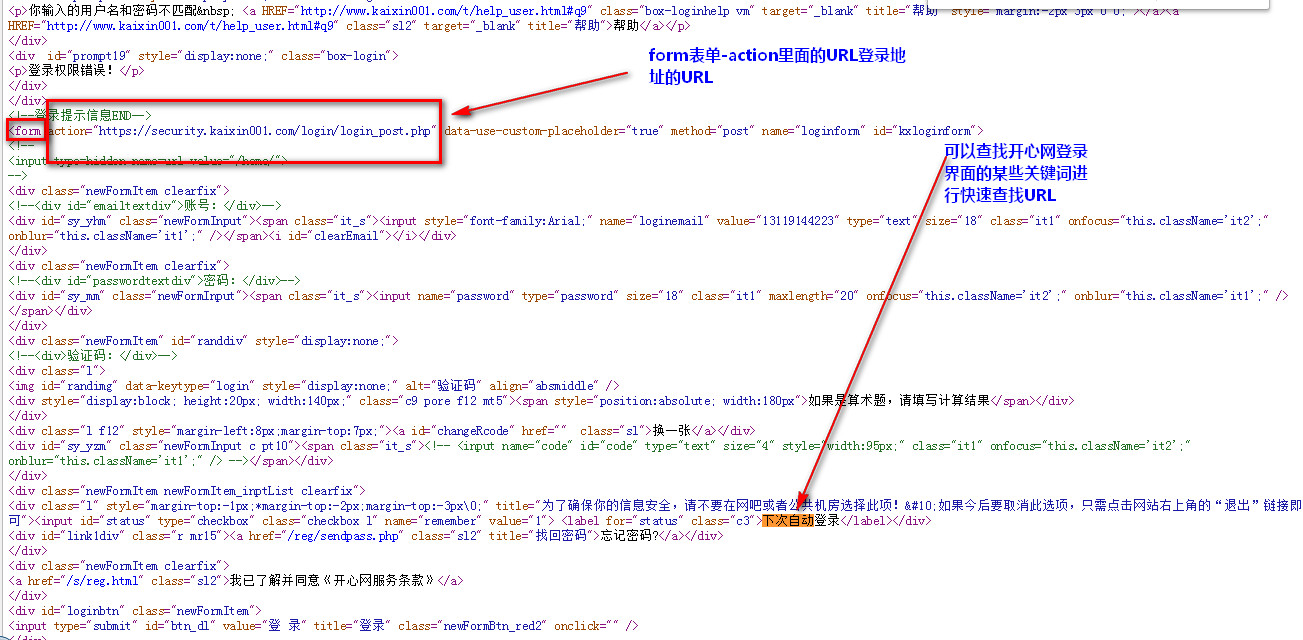
=======================================
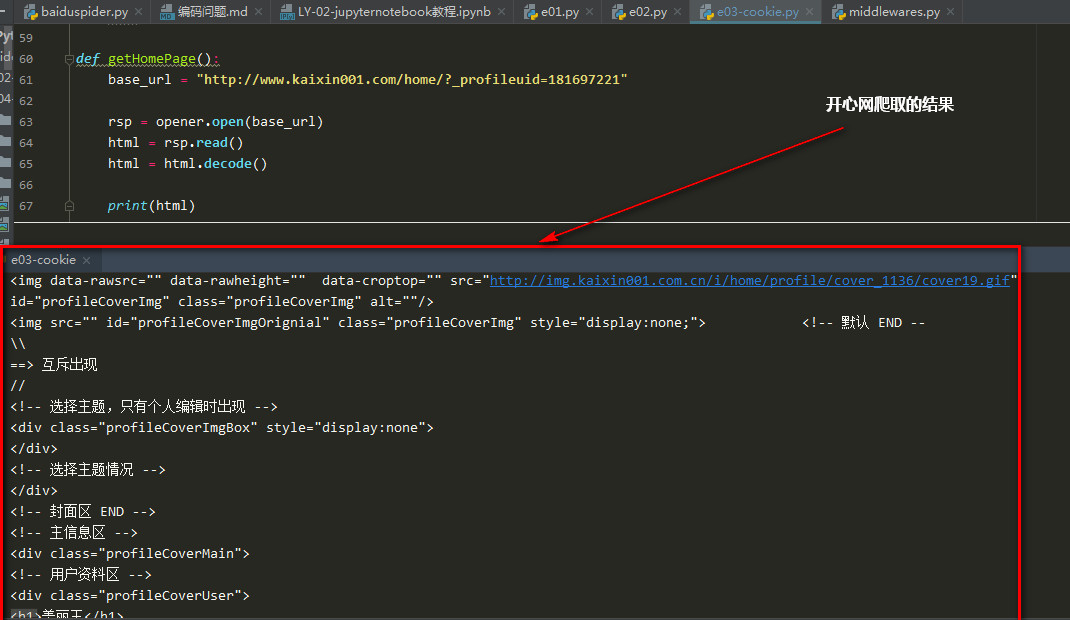
===================================
1 \'\'\' 2 登录开心网 3 利用cookie 4 免除ssl 5 \'\'\' 6 from urllib import request, parse 7 import ssl 8 \'\'\'sd 9 步骤: 10 1, 寻找登录入口, 通过搜查相应文字可以快速定位 11 login_url = "https://security.kaixin001.com/login/login_post.php" 12 相应的用户名和密码对应名称为email, password 13 2. 构造opener 14 3. 构造login函数 15 \'\'\' 16 17 import ssl 18 # 忽略安全问题 19 ssl._create_default_https_context = ssl._create_unverified_context 20 21 from http import cookiejar 22 23 cookie = cookiejar.CookieJar() 24 cookie_handler = request.HTTPCookieProcessor(cookie) 25 http_handler = request.HTTPHandler() 26 https_handler = request.HTTPSHandler() 27 28 opener = request.build_opener(http_handler, https_handler, cookie_handler) 29 30 31 32 def login(): 33 34 login_url = "https://security.kaixin001.com/login/login_post.php" 35 36 data = { 37 "email":"13119144223", 38 "password": "123456" 39 } 40 41 42 # 对post的data内容进行编码 43 data = parse.urlencode(data) 44 45 # http协议的请求头 46 headers = { 47 "Content-Length": len(data), 48 "User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36" 49 } 50 51 # 构造请求Request对象 52 # data要求是一个bytes对象,所以需要进行编码 53 req = request.Request(login_url, data=data.encode(), headers=headers) 54 55 rsp = opener.open(req) 56 57 html = rsp.read() 58 html = html.decode() 59 60 def getHomePage(): 61 base_url = "http://www.kaixin001.com/home/?_profileuid=181697221" 62 63 rsp = opener.open(base_url) 64 html = rsp.read() 65 html = html.decode() 66 67 print(html) 68 69 if __name__ == \'__main__\': 70 login() 71 getHomePage()
以上是关于Python爬虫-爬取开心网主页(有登录界面-利用cookie)的主要内容,如果未能解决你的问题,请参考以下文章