Python爬虫-爬取伯乐在线美女邮箱
Posted 夏至稻花如白练,大暑池畔赏红莲
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫-爬取伯乐在线美女邮箱相关的知识,希望对你有一定的参考价值。
爬取伯乐在线美女邮箱
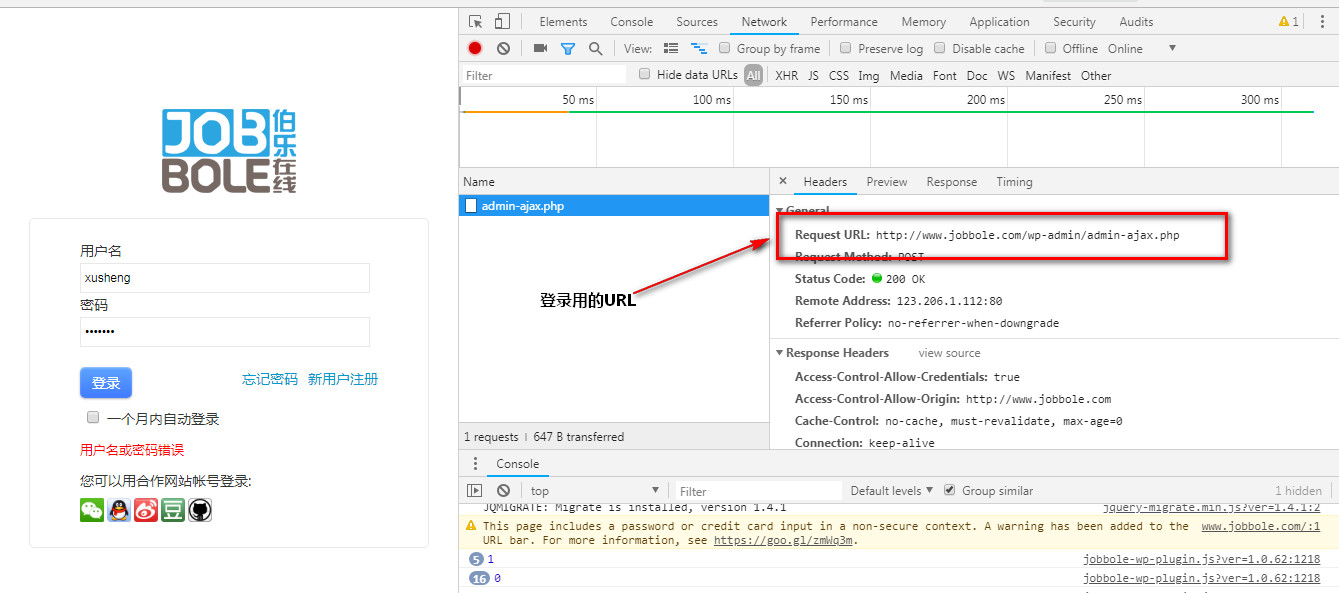
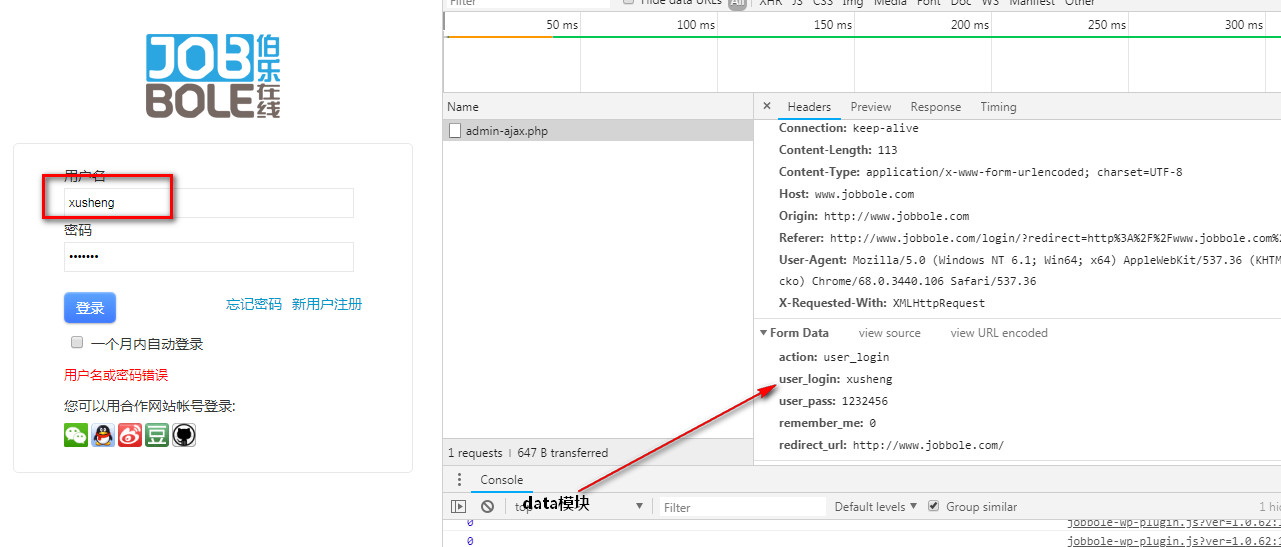
1.登录界面的进入,设置url,cookie,data,headers
2.进入主页,点击邮箱链接,需要重新设置url,cookie(读取重新保存的cookie),data,headers
1 \'\'\' 2 爬取伯乐在线的美女联系方式 3 需要: 4 1. 登录 5 2. 在登录和相应声望值的前提下,提取对方的邮箱 6 \'\'\' 7 8 from urllib import request, error, parse 9 from http import cookiejar 10 import json 11 12 def login(): 13 \'\'\' 14 输入用户名称和密码 15 获取相应的登录cookie 16 cookie 写文件 17 :return: 18 \'\'\' 19 20 # 1. 需要找到登录入口 21 url = "http://date.jobbole.com/wp-login.php" 22 23 # 2. 准备登录数据 24 data = { 25 "log": "augsnano", 26 "pwd": "123456789", 27 # 登陆后重定向地址 28 "redirect_to": "http://date.jobbole.com/4965/", 29 "rememberme": "on" 30 } 31 32 data = parse.urlencode(data).encode() 33 34 35 # 3. 准备存放cookie文件 36 # r表示不转义 37 f = r\'jobbole_cookie.txt\' 38 39 # 4. 准备请求头信息 40 headers = { 41 "User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36", 42 "Connection": "keep-alive" 43 44 } 45 46 # 5. 准备cookie hanlder 47 cookie_handler = cookiejar.MozillaCookieJar(f) 48 49 # 6. 准备http请求handler 50 http_handler = request.HTTPCookieProcessor(cookie_handler) 51 52 53 # 7. 构建opener 54 opener = request.build_opener(http_handler) 55 56 # 8. 构建请求对象 57 req = request.Request(url, data=data, headers=headers) 58 59 # 9. 发送请求 60 try: 61 rsp = opener.open(req) 62 63 cookie_handler.save(f, ignore_discard=True, ignore_expires=True) 64 65 html = rsp.read().decode() 66 print(html) 67 except error.URLError as e: 68 print(e) 69 70 71 def getInfo(): 72 # 1. 确定url 73 url = "http://date.jobbole.com/wp-admin/admin-ajax.php" 74 75 # 2. 读取已经保存的cookie 76 f = r\'jobbole_cookie.txt\' 77 cookie = cookiejar.MozillaCookieJar() 78 cookie.load(f, ignore_expires=True, ignore_discard=True) 79 80 # 3. 构建http_handler 81 http_handler = request.HTTPCookieProcessor(cookie) 82 83 # 4. 构建opener 84 opener = request.build_opener(http_handler) 85 86 # 以下是准备请求对象的过程 87 88 # 5. 构建data 89 data = { 90 "action": "get_date_contact", 91 "postId": "4965" 92 } 93 94 data = parse.urlencode(data).encode() 95 96 # 6. 构建请求头 97 headers = { 98 "User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36", 99 "Connection": "keep-alive" 100 } 101 102 # 7. 构建请求实体 103 req = request.Request(url, data=data, headers=headers) 104 105 # 8. 用opener打开 106 try: 107 rsp = opener.open(req) 108 html = rsp.read().decode() 109 110 html = json.loads(html) 111 print(html) 112 113 f = "rsp.html" 114 with open(f, \'w\') as f: 115 f.write(html) 116 117 except Exception as e: 118 print(e) 119 120 121 122 123 124 125 if __name__ == \'__main__\': 126 getInfo()
以上是关于Python爬虫-爬取伯乐在线美女邮箱的主要内容,如果未能解决你的问题,请参考以下文章