《一出好戏》讲述人性,使用Python抓取猫眼近10万条评论并分析,一起揭秘“这出好戏”到底如何?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《一出好戏》讲述人性,使用Python抓取猫眼近10万条评论并分析,一起揭秘“这出好戏”到底如何?相关的知识,希望对你有一定的参考价值。

黄渤首次导演的电影《一出好戏》自8月10日在全国上映,至今已有10天,其主演阵容强大,相信许多观众也都是冲着明星们去的。
目前《一出好戏》在猫眼上已经获得近60万个评价,评分为8.2分,票房已破10亿。

作者本人(汤小洋 )今天也走进了电影院,对这部电影做了亲身的观看,看完后的感觉是有些许失落的,本以为是喜剧片,结果发现笑点一般,从搞笑的角度来看,不如《西虹市首富》,影片更多的是反映人类本性的一部电影,不应当做喜剧片来看,影片中展现的人与人之间的关系倒是值得我们去深思。
今天就跟着 汤老师 一起来揭秘影片《一出好戏》,看看“这出好戏”到底如何?
我们将使用Python抓取猫眼近10万条评论数据,并对获取到的数据进行分析,看看观众对这部电影的评价究竟如何?
整个数据分析的过程分为四步:
- 获取数据
- 处理数据
- 存储数据
- 数据可视化
一、获取数据
1. 简介
? 本次获取的是猫眼APP的评论数据,如图所示:

通过分析发现猫眼APP的评论数据接口为:
http://m.maoyan.com/mmdb/comments/movie/1200486.json?_v_=yes&offset=0&startTime=2018-07-28%2022%3A25%3A03

? 通过对评论数据进行分析,得到如下信息:
-
返回的是json格式数据
-
1200486表示电影的专属id;offset表示偏移量;startTime表示获取评论的起始时间,从该时间向前取数据,即获取最新的评论
-
cmts表示评论,每次获取15条,offset偏移量是指每次获取评论时的起始索引,向后取15条
-
hcmts表示热门评论前10条
- total表示总评论数
2. 代码实现
? 这里先定义一个函数,用来根据指定url获取数据,且只能获取到指定的日期向前获取到15条评论数据
# coding=utf-8
__author__ = ‘汤小洋‘
from urllib import request
import json
import time
from datetime import datetime
from datetime import timedelta
# 获取数据,根据url获取
def get_data(url):
headers = {
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36‘
}
req = request.Request(url, headers=headers)
response = request.urlopen(req)
if response.getcode() == 200:
return response.read()
return None
if __name__ == ‘__main__‘:
html = get_data(‘http://m.maoyan.com/mmdb/comments/movie/1200486.json?_v_=yes&offset=0&startTime=2018-07-28%2022%3A25%3A03‘)
print(html)二、处理数据
对获取的数据进行处理,转换为json
# 处理数据
def parse_data(html):
data = json.loads(html)[‘cmts‘] # 将str转换为json
comments = []
for item in data:
comment = {
‘id‘: item[‘id‘],
‘nickName‘: item[‘nickName‘],
‘cityName‘: item[‘cityName‘] if ‘cityName‘ in item else ‘‘, # 处理cityName不存在的情况
‘content‘: item[‘content‘].replace(‘
‘, ‘ ‘, 10), # 处理评论内容换行的情况
‘score‘: item[‘score‘],
‘startTime‘: item[‘startTime‘]
}
comments.append(comment)
return comments
if __name__ == ‘__main__‘:
html = get_data(‘http://m.maoyan.com/mmdb/comments/movie/1200486.json?_v_=yes&offset=0&startTime=2018-07-28%2022%3A25%3A03‘)
comments = parse_data(html)
print(comments)三、存储数据
? 为了能够获取到所有评论数据,方法是:从当前时间开始,向前获取数据,根据url每次获取15条,然后得到末尾评论的时间,从该时间继续向前获取数据,直到影片上映日期(2018-08-10)为止,获取这之间的所有数据。
# 存储数据,存储到文本文件
def save_to_txt():
start_time = datetime.now().strftime(‘%Y-%m-%d %H:%M:%S‘) # 获取当前时间,从当前时间向前获取
end_time = ‘2018-08-10 00:00:00‘
while start_time > end_time:
url = ‘http://m.maoyan.com/mmdb/comments/movie/1203084.json?_v_=yes&offset=0&startTime=‘ + start_time.replace(‘ ‘, ‘%20‘)
html = None
‘‘‘
问题:当请求过于频繁时,服务器会拒绝连接,实际上是服务器的反爬虫策略
解决:1.在每个请求间增加延时0.1秒,尽量减少请求被拒绝
2.如果被拒绝,则0.5秒后重试
‘‘‘
try:
html = get_data(url)
except Exception as e:
time.sleep(0.5)
html = get_data(url)
else:
time.sleep(0.1)
comments = parse_data(html)
print(comments)
start_time = comments[14][‘startTime‘] # 获得末尾评论的时间
start_time = datetime.strptime(start_time, ‘%Y-%m-%d %H:%M:%S‘) + timedelta(seconds=-1) # 转换为datetime类型,减1秒,避免获取到重复数据
start_time = datetime.strftime(start_time, ‘%Y-%m-%d %H:%M:%S‘) # 转换为str
for item in comments:
with open(‘comments.txt‘, ‘a‘, encoding=‘utf-8‘) as f:
f.write(str(item[‘id‘])+‘,‘+item[‘nickName‘] + ‘,‘ + item[‘cityName‘] + ‘,‘ + item[‘content‘] + ‘,‘ + str(item[‘score‘])+ ‘,‘ + item[‘startTime‘] + ‘
‘)
if __name__ == ‘__main__‘:
# html = get_data(‘http://m.maoyan.com/mmdb/comments/movie/1200486.json?_v_=yes&offset=0&startTime=2018-07-28%2022%3A25%3A03‘)
# comments = parse_data(html)
# print(comments)
save_to_txt()? 有两点需要说明:
- 服务器一般都有反爬虫策略,当请求过于频繁时,服务器会拒绝部分连接,我这里是通过增加每个请求间延时来解决,只是一种简单的解决方案,还望各位看客理解包涵
- 根据数据量的多少,抓取数据所需时间会有所不同,我抓取的是2018-8-19到2018-8-10(上映当天)之间的数据,大概花了2个小时,共抓取约9.2万条评论数据

四、数据可视化
? 这里使用的是pyecharts,pyecharts是一个用于生成Echarts图表的类库,便于在Python中根据数据生成可视化的图表。
? Echarts是百度开源的一个数据可视化JS库,主要用于数据可视化。
# 安装pyecharts
pip install pyecharts ? pyecharts v0.3.2以后,pyecharts 将不再自带地图 js 文件。如用户需要用到地图图表,可自行安装对应的地图文件包。
# 安装地图文件包
pip install echarts-china-provinces-pypkg # 中国省、市、县、区地图
pip install echarts-china-cities-pypkg
pip install echarts-china-counties-pypkg
pip install echarts-china-misc-pypkg
pip install echarts-countries-pypkg # 全球国家地图
pip install echarts-united-kingdom-pypkg1. 粉丝位置分布
? 代码实现
# 导入Style类,用于定义样式风格
from pyecharts import Style
# 导入Geo组件,用于生成地理坐标类图
from pyecharts import Geo
import json
# 导入Geo组件,用于生成柱状图
from pyecharts import Bar
# 导入Counter类,用于统计值出现的次数
from collections import Counter
# 数据可视化
def render():
# 获取评论中所有城市
cities = []
with open(‘comments.txt‘, mode=‘r‘, encoding=‘utf-8‘) as f:
rows = f.readlines()
for row in rows:
city = row.split(‘,‘)[2]
if city != ‘‘: # 去掉城市名为空的值
cities.append(city)
# 对城市数据和坐标文件中的地名进行处理
handle(cities)
# 统计每个城市出现的次数
# data = []
# for city in set(cities):
# data.append((city, cities.count(city)))
data = Counter(cities).most_common() # 使用Counter类统计出现的次数,并转换为元组列表
# print(data)
# 定义样式
style = Style(
title_color=‘#fff‘,
title_pos=‘center‘,
width=1200,
height=600,
background_color=‘#404a59‘
)
# 根据城市数据生成地理坐标图
geo = Geo(‘《一出好戏》粉丝位置分布‘, ‘数据来源:猫眼-汤小洋采集‘, **style.init_style)
attr, value = geo.cast(data)
geo.add(‘‘, attr, value, visual_range=[0, 3500],
visual_text_color=‘#fff‘, symbol_size=15,
is_visualmap=True, is_piecewise=True, visual_split_number=10)
geo.render(‘粉丝位置分布-地理坐标图.html‘)
# 根据城市数据生成柱状图
data_top20 = Counter(cities).most_common(20) # 返回出现次数最多的20条
bar = Bar("《一出好戏》粉丝来源排行TOP20", "数据来源:猫眼-汤小洋采集", title_pos=‘center‘, width=1200, height=60)
attr, value = bar.cast(data_top20)
bar.add("", attr, value, is_visualmap=True, visual_range=[0, 3500], visual_text_color=‘#fff‘, is_more_utils=True,
is_label_show=True)
bar.render("粉丝来源排行-柱状图.html")? 出现的问题:
-
报错:ValueError: No coordinate is specified for xxx(地名)
-
原因:pyecharts的坐标文件中没有该地名,实际上是名称不一致导致的,如数据中地名为‘达州‘,而坐标文件中为‘达州市‘
坐标文件所在路径:
项目/venv/lib/python3.6/site-packages/pyecharts/datasets/city_coordinates.json - 解决:修改坐标文件,在原位置下复制个同样的,然后修改下地名
{
"达州市": [
107.5,
31.22
],
"达州": [
107.5,
31.22
],
} ? 不过由于要修改的地名太多,上面的方法实在是麻烦,所以我定义了一个函数,用来处理地名数据找不到的问题
# 处理地名数据,解决坐标文件中找不到地名的问题
def handle(cities):
# print(len(cities), len(set(cities)))
# 获取坐标文件中所有地名
data = None
with open(
‘/Users/wangbo/PycharmProjects/python-spider/venv/lib/python3.6/site-packages/pyecharts/datasets/city_coordinates.json‘,
mode=‘r‘, encoding=‘utf-8‘) as f:
data = json.loads(f.read()) # 将str转换为json
# 循环判断处理
data_new = data.copy() # 拷贝所有地名数据
for city in set(cities): # 使用set去重
# 处理地名为空的数据
if city == ‘‘:
while city in cities:
cities.remove(city)
count = 0
for k in data.keys():
count += 1
if k == city:
break
if k.startswith(city): # 处理简写的地名,如 达州市 简写为 达州
# print(k, city)
data_new[city] = data[k]
break
if k.startswith(city[0:-1]) and len(city) >= 3: # 处理行政变更的地名,如县改区 或 县改市等
data_new[city] = data[k]
break
# 处理不存在的地名
if count == len(data):
while city in cities:
cities.remove(city)
# print(len(data), len(data_new))
# 写入覆盖坐标文件
with open(
‘/Users/wangbo/PycharmProjects/python-spider/venv/lib/python3.6/site-packages/pyecharts/datasets/city_coordinates.json‘,
mode=‘w‘, encoding=‘utf-8‘) as f:
f.write(json.dumps(data_new, ensure_ascii=False)) # 将json转换为str
可视化结果:
粉丝人群主要集中在沿海一带

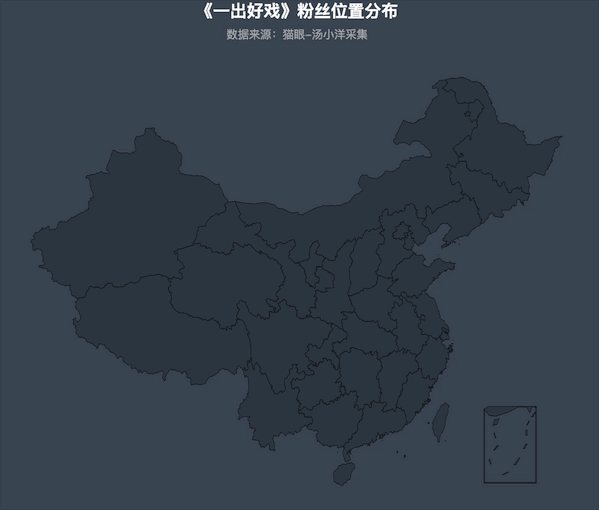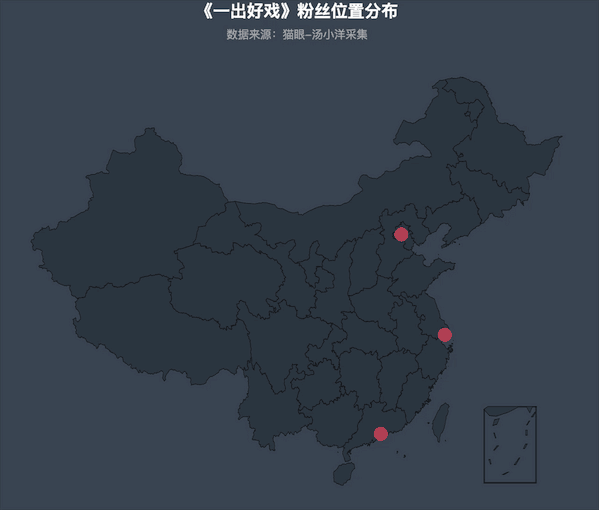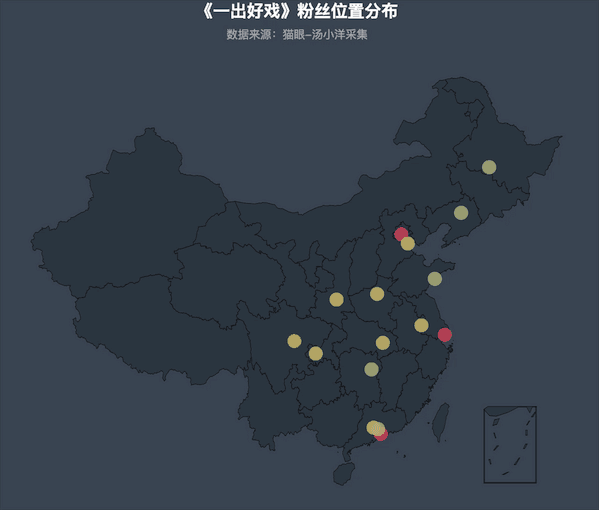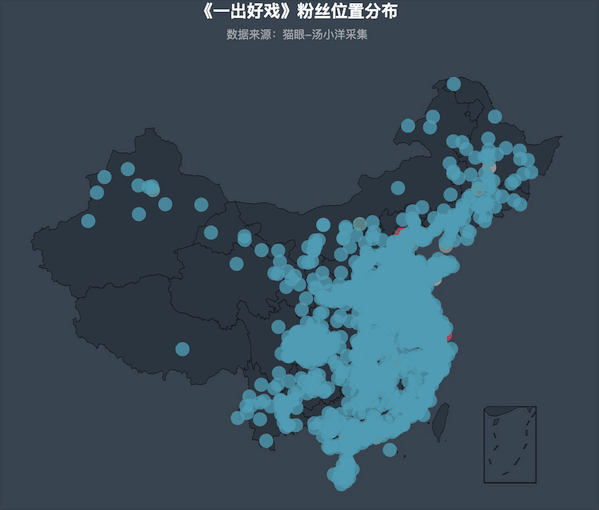
从上图可以看出,《一出好戏》的观影人群主要集中在沿海一带,这些地方经济相对发达,城市人口基数庞大,极多的荧幕数量和座位、极高密度的排片场次,让观众便捷观影,活跃的观众评论也多,自然也就成为票房的主要贡献者。

粉丝来源排名前20的城市依次为:北京、深圳、上海、成都、武汉、广州、西安、郑州、重庆、南京、天津、沈阳、长沙、东莞、哈尔滨、青岛、杭州、合肥、大连、苏州
电影消费是城市消费的一部分,从某种角度来看,可以作为考察一个城市购买力的指标。这些城市在近年的GDP排行中大都居上游,消费水平较高。
2. 词云图
? jieba是一个基于Python的分词库,完美支持中文分词,功能强大
pip install jieba? Matplotlib是一个Python的2D绘图库,能够生成高质量的图形,可以快速生成绘图、直方图、功率谱、柱状图、误差图、散点图等
pip install matplotlib? wordcloud是一个基于Python的词云生成类库,可以生成词云图
pip install wordcloud? 代码实现:
# coding=utf-8
__author__ = "汤小洋"
# 导入jieba模块,用于中文分词
import jieba
# 导入matplotlib,用于生成2D图形
import matplotlib.pyplot as plt
# 导入wordcount,用于制作词云图
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
# 获取所有评论
comments = []
with open(‘comments.txt‘, mode=‘r‘, encoding=‘utf-8‘) as f:
rows = f.readlines()
for row in rows:
comment = row.split(‘,‘)[3]
if comment != ‘‘:
comments.append(comment)
# 设置分词
comment_after_split = jieba.cut(str(comments), cut_all=False) # 非全模式分词,cut_all=false
words = " ".join(comment_after_split) # 以空格进行拼接
# print(words)
# 设置屏蔽词
stopwords = STOPWORDS.copy()
stopwords.add("电影")
stopwords.add("一部")
stopwords.add("一个")
stopwords.add("没有")
stopwords.add("什么")
stopwords.add("有点")
stopwords.add("这部")
stopwords.add("这个")
stopwords.add("不是")
stopwords.add("真的")
stopwords.add("感觉")
stopwords.add("觉得")
stopwords.add("还是")
stopwords.add("但是")
stopwords.add("就是")
# 导入背景图
bg_image = plt.imread(‘bg.jpg‘)
# 设置词云参数,参数分别表示:画布宽高、背景颜色、背景图形状、字体、屏蔽词、最大词的字体大小
wc = WordCloud(width=1024, height=768, background_color=‘white‘, mask=bg_image, font_path=‘STKAITI.TTF‘,
stopwords=stopwords, max_font_size=400, random_state=50)
# 将分词后数据传入云图
wc.generate_from_text(words)
plt.imshow(wc)
plt.axis(‘off‘) # 不显示坐标轴
plt.show()
# 保存结果到本地
wc.to_file(‘词云图.jpg‘)
可视化结果:
总体评价很不错
? 对评论数据进行分词后制作如下词云图:

? 从词云图中可以看到:
- 评论中多次出现“可以”、“好看”、“不错”等热词,说明观众对《一出好戏》的总体评价还是很不错的
- 同时对该影片中“张艺兴”的“演技”也给予了很大的认可,我本人今天在观看后也有同感,让我们看到了不一样的张艺兴,实力演员
- 对于初次“导演”电影的“黄渤”,能拍出这样的影片,粉丝们也是比较肯定的,同时其本身就是票房的保障
- 至于剧情方面,“现实”、“喜剧”、“搞笑”、“故事”等词语,能看出这是一部反映现实的故事片,同时也兼具喜剧搞笑
- 对于评论中出现的“一般”、“失望”等,这些粉丝或许是和我一样,本以为这是一部爆笑喜剧片,笑点应该会很多(毕竟在我们心中,黄渤、王宝强等就是笑星),没想到笑点并不很多,至少与期待的有差距,导致心里有落差的原因吧^_^

3. 评分星级
? 代码实现:
# coding=utf-8
__author__ = "汤小洋"
# 导入Pie组件,用于生成饼图
from pyecharts import Pie
# 获取评论中所有评分
rates = []
with open(‘comments.txt‘, mode=‘r‘, encoding=‘utf-8‘) as f:
rows = f.readlines()
for row in rows:
rates.append(row.split(‘,‘)[4])
# print(rates)
# 定义星级,并统计各星级评分数量
attr = ["五星", "四星", "三星", "二星", "一星"]
value = [
rates.count(‘5‘) + rates.count(‘4.5‘),
rates.count(‘4‘) + rates.count(‘3.5‘),
rates.count(‘3‘) + rates.count(‘2.5‘),
rates.count(‘2‘) + rates.count(‘1.5‘),
rates.count(‘1‘) + rates.count(‘0.5‘)
]
# print(value)
pie = Pie(‘《一出好戏》评分星级比例‘, title_pos=‘center‘, width=900)
pie.add("7-17", attr, value, center=[75, 50], is_random=True,
radius=[30, 75], rosetype=‘area‘,
is_legend_show=False, is_label_show=True)
pie.render(‘评分.html‘)
可视化结果:
四、五星级影评合计高达83%
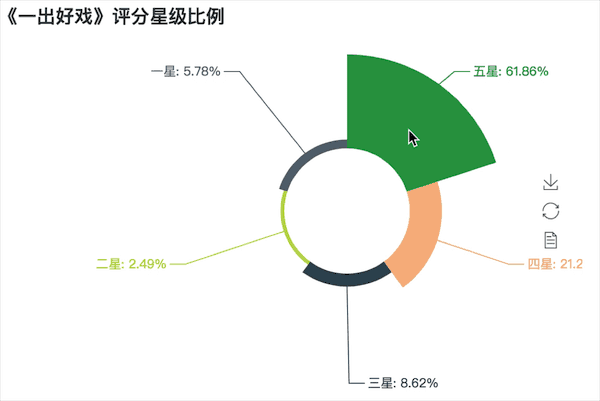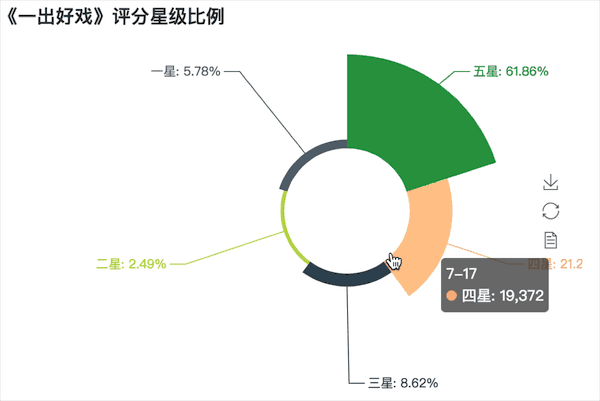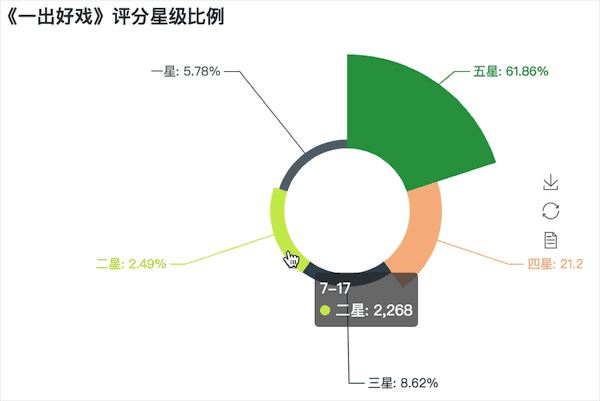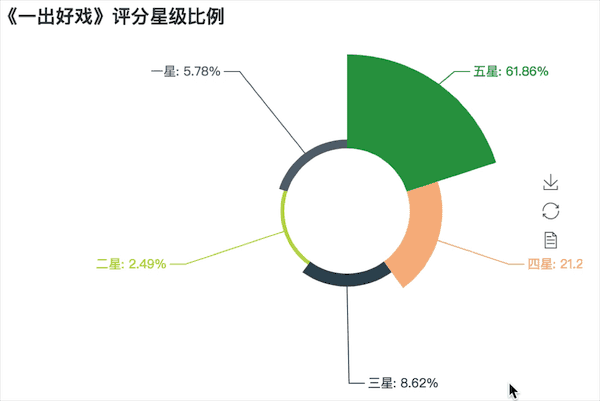
? 从图中可以看出,五星比例接近62%,四星比例为21%,两者合计高达83%,可见口碑还是相当不错的,一星占比不足6%
? 《一出好戏》作为黄渤第一次执导的作品,在拍摄过程中导演渤哥对自己的要求也是很严格的,所以有这样的成绩,也是理所当然。

附:今天看电影的票根 ^_^
以上是关于《一出好戏》讲述人性,使用Python抓取猫眼近10万条评论并分析,一起揭秘“这出好戏”到底如何?的主要内容,如果未能解决你的问题,请参考以下文章
Python爬虫编程思想(37):项目实战:抓取猫眼电影Top100榜单