反爬虫2-python3.6 正则表达式抓取猫眼电影TOP100
Posted 志同道合海纳百川
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了反爬虫2-python3.6 正则表达式抓取猫眼电影TOP100相关的知识,希望对你有一定的参考价值。
首先总结一下大数据采集的思路,思维导图供参考:
本篇主要内容是对比多线程抓取的速度
主要内容:
1.查看网页源代码
2.抓取单页内容
3.正则表达式提取信息
4.猫眼TOP100所有信息写入文件
5.多线程抓取
详细讲解:
1.查看网页源代码
按ctrl+shift+i,发现每一个电影的信息都在“<dd></dd>”标签之中。
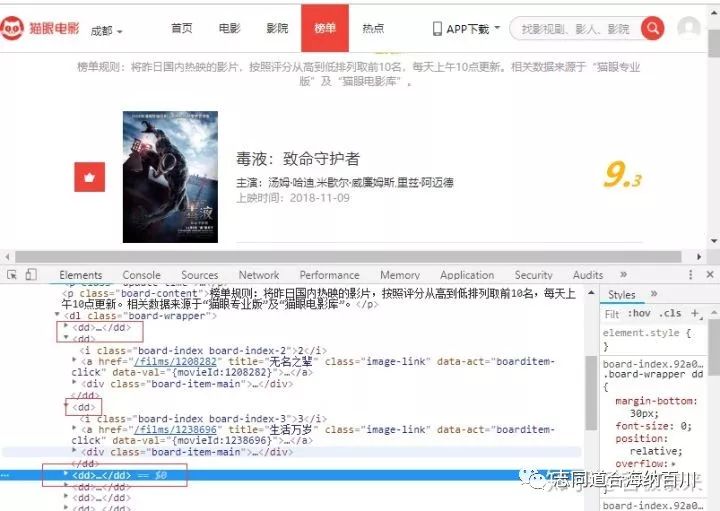
点开之后,信息如下:
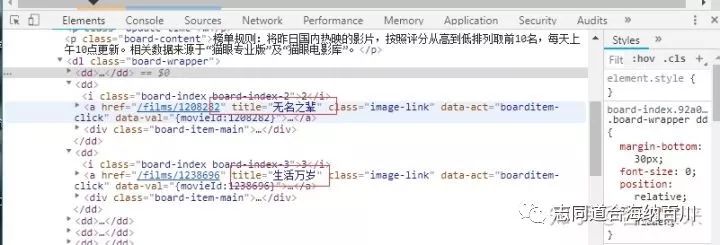
2.抓取单页内容
在 浏览器中打开猫眼电影网站,点击“榜单”,再点击“TOP100榜”如下图:
接下来通过以下代码获取网页源代码:
import requests#猫眼电影网站有反爬虫措施,设置headers后可以爬取headers = {'Content-Type': 'text/plain; charset=UTF-8',
'Origin': 'https://maoyan.com',
'Referer': 'https://maoyan.com/board/4',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/67.0.3396.99 Safari/537.36'}#爬取网页源代码def get_one_page(url,headers):
try:
response=requests.get(url,headers=headers)
if response.status_code==200:
return response.text
return None
except:
return Nonedef main():
url = 'https://maoyan.com/board/4'
html=get_one_page(url,headers)
print(html)if __name__ == '__main__':
main()结果如下图:
3.正则表达式提取信息
首先看一下正则表达式re.compile()的使用:参考连接:正则表达式re.compile()的使用 - Darkman_EX的博客 - CSDN博客
compile()的定义:
compile(pattern, flags=0)
Compile a regular expression pattern, returning a pattern object.从compile()函数的定义中,可以看出返回的是一个匹配对象,它单独使用就没有任何意义,需要和findall(), search(), match()搭配使用。
compile()与findall()一起使用,返回一个列表。
import re
def main():
content = 'hi,everyone!this is my first time to learn re,i\'m very glad to …'
regex = re.compile('\w*o\w*')
x = regex.findall(content)
print(x)
if __name__ == '__main__':
main()
#输出:['everyone', 'to', 'to']compile()与match()一起使用,可返回一个class、str、tuple。但是一定需要注意match(),从位置0开始匹配,匹配不到会返回None,返回None的时候就没有span/group属性了,并且与group使用,返回一个单词‘Hello’后匹配就会结束。
import re
def main():
content = 'hi,everyone!this is my first time to learn re,i\'m very glad to …'
regex = re.compile('\w*o\w*')
y = regex.match(content)
print(y)
print(type(y))
print(y.group())
print(y.span())
if __name__ == '__main__':
main()
#输出:AttributeError: 'NoneType' object has no attribute 'group','span'
#改变conten='hello,everyone!this is my first time to learn re,i\'m very glad to …'
#输出改为:
"""
<_sre.SRE_Match object; span=(0, 5), match='hello'>
<class '_sre.SRE_Match'>
hello
(0, 5)
"""yeild的用法:
如果一个函数定义中包含yield关键字,那么这个函数就不再是一个普通函数,
而是一个generator.最难理解的就是generator和函数的执行流程不一样。函数是顺序执行,
遇到return语句或者最后一行函数语句就返回。而变成generator的函数,在每次调用next()的时候执行,
遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行。利用正则表达式提取信息:
在这里获取内容的函数返回一个生成器(生成字典),所以在main函数里面用for循环迭代获得字典。
#正则表达式提取信息
def parse_one_page(html):
# re.S模式保证能匹配到换行符,()里是我们要配的内容
pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?src="/img?url=(.*?)".*?name"><a'
+ '.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>',
re.S)
items = re.findall(pattern, html)
for item in items:
# 相当于return一个字典
yield {
'index': item[0],
'image': item[1],
'title': item[2],
'actor': item[3].strip()[3:],
'time': item[4].strip()[5:],
'score': item[5] + item[6]
}
def main():
url = "https://maoyan.com/board/4"
html = get_one_page(url, headers)
for item in parse_one_page(html):
print(item)输出:
{'index': '1', 'image': 'https://p1.meituan.net/movie/20803f59291c47e1e116c11963ce019e68711.jpg@160w_220h_1e_1c', 'title': '霸王别姬', 'actor': '张国荣,张丰毅,巩俐', 'time': '1993-01-01', 'score': '9.6'}
{'index': '2', 'image': 'https://p0.meituan.net/movie/283292171619cdfd5b240c8fd093f1eb255670.jpg@160w_220h_1e_1c', 'title': '肖申克的救赎', 'actor': '蒂姆·罗宾斯,摩根·弗里曼,鲍勃·冈顿', 'time': '1994-10-14(美国)', 'score': '9.5'}
{'index': '3', 'image': 'https://p0.meituan.net/movie/54617769d96807e4d81804284ffe2a27239007.jpg@160w_220h_1e_1c', 'title': '罗马假日', 'actor': '格利高里·派克,奥黛丽·赫本,埃迪·艾伯特', 'time': '1953-09-02(美国)', 'score': '9.1'}
{'index': '4', 'image': 'https://p0.meituan.net/movie/e55ec5d18ccc83ba7db68caae54f165f95924.jpg@160w_220h_1e_1c', 'title': '这个杀手不太冷', 'actor': '让·雷诺,加里·奥德曼,娜塔莉·波特曼', 'time': '1994-09-14(法国)', 'score': '9.5'}
{'index': '5', 'image': 'https://p1.meituan.net/movie/f5a924f362f050881f2b8f82e852747c118515.jpg@160w_220h_1e_1c', 'title': '教父', 'actor': '马龙·白兰度,阿尔·帕西诺,詹姆斯·肯恩', 'time': '1972-03-24(美国)', 'score': '9.3'}
{'index': '6', 'image': 'https://p1.meituan.net/movie/0699ac97c82cf01638aa5023562d6134351277.jpg@160w_220h_1e_1c', 'title': '泰坦尼克号', 'actor': '莱昂纳多·迪卡普里奥,凯特·温丝莱特,比利·赞恩', 'time': '1998-04-03', 'score': '9.5'}
{'index': '7', 'image': 'https://p0.meituan.net/movie/da64660f82b98cdc1b8a3804e69609e041108.jpg@160w_220h_1e_1c', 'title': '唐伯虎点秋香', 'actor': '周星驰,巩俐,郑佩佩', 'time': '1993-07-01(中国香港)', 'score': '9.2'}
{'index': '8', 'image': 'https://p0.meituan.net/movie/b076ce63e9860ecf1ee9839badee5228329384.jpg@160w_220h_1e_1c', 'title': '千与千寻', 'actor': '柊瑠美,入野自由,夏木真理', 'time': '2001-07-20(日本)', 'score': '9.3'}
{'index': '9', 'image': 'https://p0.meituan.net/movie/46c29a8b8d8424bdda7715e6fd779c66235684.jpg@160w_220h_1e_1c', 'title': '魂断蓝桥', 'actor': '费雯·丽,罗伯特·泰勒,露塞尔·沃特森', 'time': '1940-05-17(美国)', 'score': '9.2'}
{'index': '10', 'image': 'https://p0.meituan.net/movie/230e71d398e0c54730d58dc4bb6e4cca51662.jpg@160w_220h_1e_1c', 'title': '乱世佳人', 'actor': '费雯·丽,克拉克·盖博,奥利维娅·德哈维兰', 'time': '1939-12-15(美国)', 'score': '9.1'}4.猫眼TOP100所有信息写入文件
上边代码实现单页的信息抓取,要想爬取100个电影的信息,先观察每一页url的变化,点开每一页我们会发现url进行变化,原url后面多了‘?offset=0’,且offset的值变化从0,10,20,变化如下:
https://maoyan.com/board/4?offset=0
maoyan.com/board/4?
https://maoyan.com/board/4?offset=20
#猫眼TOP100所有信息写入文件
def write_to_file(content):
#encoding ='utf-8',ensure_ascii =False,使写入文件的代码显示为中文
with open('C:\\Users\\nanafighting\\Desktop\\maoyantop100.txt','a',encoding ='utf-8') as f:
# 数据转换成json格式的字符串
f.write(json.dumps(content,ensure_ascii =False)+'\n')
f.close()
# 下载电影封面
def save_image_file(url, path):
jd = requests.get(url)
if jd.status_code == 200:
with open(path, 'wb') as f:
f.write(jd.content)
f.close()
def main(offset):
url = "https://maoyan.com/board/4?offset=" + str(offset)
html = get_one_page(url, headers)
if not os.path.exists('covers'):
os.mkdir('covers')
for item in parse_one_page(html):
print(item)
write_to_file(item)
save_image_file(item['image'], 'covers/' + item['title'] + '.jpg')
if __name__ == '__main__':
# 对每一页信息进行爬取
for i in range(10):
main(i * 10)部分结果如下:
{'index': '1', 'image': 'https://p1.meituan.net/movie/20803f59291c47e1e116c11963ce019e68711.jpg@160w_220h_1e_1c', 'title': '霸王别姬', 'actor': '张国荣,张丰毅,巩俐', 'time': '1993-01-01', 'score': '9.6'}
{'index': '2', 'image': 'https://p0.meituan.net/movie/283292171619cdfd5b240c8fd093f1eb255670.jpg@160w_220h_1e_1c', 'title': '肖申克的救赎', 'actor': '蒂姆·罗宾斯,摩根·弗里曼,鲍勃·冈顿', 'time': '1994-10-14(美国)', 'score': '9.5'}
{'index': '3', 'image': 'https://p0.meituan.net/movie/54617769d96807e4d81804284ffe2a27239007.jpg@160w_220h_1e_1c', 'title': '罗马假日', 'actor': '格利高里·派克,奥黛丽·赫本,埃迪·艾伯特', 'time': '1953-09-02(美国)', 'score': '9.1'}
{'index': '4', 'image': 'https://p0.meituan.net/movie/e55ec5d18ccc83ba7db68caae54f165f95924.jpg@160w_220h_1e_1c', 'title': '这个杀手不太冷', 'actor': '让·雷诺,加里·奥德曼,娜塔莉·波特曼', 'time': '1994-09-14(法国)', 'score': '9.5'}
{'index': '5', 'image': 'https://p1.meituan.net/movie/f5a924f362f050881f2b8f82e852747c118515.jpg@160w_220h_1e_1c', 'title': '教父', 'actor': '马龙·白兰度,阿尔·帕西诺,詹姆斯·肯恩', 'time': '1972-03-24(美国)', 'score': '9.3'}
{'index': '6', 'image': 'https://p1.meituan.net/movie/0699ac97c82cf01638aa5023562d6134351277.jpg@160w_220h_1e_1c', 'title': '泰坦尼克号', 'actor': '莱昂纳多·迪卡普里奥,凯特·温丝莱特,比利·赞恩', 'time': '1998-04-03', 'score': '9.5'}
{'index': '7', 'image': 'https://p0.meituan.net/movie/da64660f82b98cdc1b8a3804e69609e041108.jpg@160w_220h_1e_1c', 'title': '唐伯虎点秋香', 'actor': '周星驰,巩俐,郑佩佩', 'time': '1993-07-01(中国香港)', 'score': '9.2'}
{'index': '8', 'image': 'https://p0.meituan.net/movie/b076ce63e9860ecf1ee9839badee5228329384.jpg@160w_220h_1e_1c', 'title': '千与千寻', 'actor': '柊瑠美,入野自由,夏木真理', 'time': '2001-07-20(日本)', 'score': '9.3'}
{'index': '9', 'image': 'https://p0.meituan.net/movie/46c29a8b8d8424bdda7715e6fd779c66235684.jpg@160w_220h_1e_1c', 'title': '魂断蓝桥', 'actor': '费雯·丽,罗伯特·泰勒,露塞尔·沃特森', 'time': '1940-05-17(美国)', 'score': '9.2'}
{'index': '10', 'image': 'https://p0.meituan.net/movie/230e71d398e0c54730d58dc4bb6e4cca51662.jpg@160w_220h_1e_1c', 'title': '乱世佳人', 'actor': '费雯·丽,克拉克·盖博,奥利维娅·德哈维兰', 'time': '1939-12-15(美国)', 'score': '9.1'}5.多线程抓取
from multiprocessing.pool import Pool
if __name__ == '__main__':
#对每一页信息进行爬取
pool = Pool()
pool.map(main,[i*10 for i in range(10)])
pool.close()部分输出结果:
{'index': '1', 'image': 'https://p1.meituan.net/movie/20803f59291c47e1e116c11963ce019e68711.jpg@160w_220h_1e_1c', 'title': '霸王别姬', 'actor': '张国荣,张丰毅,巩俐', 'time': '1993-01-01', 'score': '9.6'}
{'index': '21', 'image': 'https://p1.meituan.net/movie/b449893ebc63d5c54eb4a5b60341f334383831.jpg@160w_220h_1e_1c', 'title': '加勒比海盗', 'actor': '约翰尼·德普,凯拉·奈特莉,奥兰多·布鲁姆', 'time': '2003-11-21', 'score': '8.9'}
{'index': '31', 'image': 'https://p1.meituan.net/movie/618e57ddb3173de6bbf2e278946b11f279679.jpg@160w_220h_1e_1c', 'title': '天堂电影院', 'actor': '菲利浦·诺瓦雷,赛尔乔·卡斯特利托,蒂兹亚娜·罗达托', 'time': '1988-11-17(意大利)', 'score': '9.2'}
{'index': '11', 'image': 'https://p1.meituan.net/movie/ba1ed511668402605ed369350ab779d6319397.jpg@160w_220h_1e_1c', 'title': '天空之城', 'actor': '寺田农,鹫尾真知子,龟山助清', 'time': '1992', 'score': '9.1'}
{'index': '22', 'image': 'https://p0.meituan.net/movie/932bdfbef5be3543e6b136246aeb99b8123736.jpg@160w_220h_1e_1c', 'title': '指环王3:王者无敌', 'actor': '伊莱贾·伍德,伊恩·麦克莱恩,丽芙·泰勒', 'time': '2004-03-15', 'score': '9.2'}
{'index': '32', 'image': 'https://p0.meituan.net/movie/4c41068ef7608c1d4fbfbe6016e589f7204391.jpg@160w_220h_1e_1c', 'title': '活着', 'actor': '葛优,巩俐,牛犇', 'time': '1994-05-18(法国)', 'score': '9.0'}
{'index': '12', 'image': 'https://p1.meituan.net/movie/18e3191039d5e71562477659301f04aa61905.jpg@160w_220h_1e_1c', 'title': '喜剧之王', 'actor': '周星驰,莫文蔚,张柏芝', 'time': '1999-02-13(中国香港)', 'score': '9.2'}
{'index': '2', 'image': 'https://p0.meituan.net/movie/283292171619cdfd5b240c8fd093f1eb255670.jpg@160w_220h_1e_1c', 'title': '肖申克的救赎', 'actor': '蒂姆·罗宾斯,摩根·弗里曼,鲍勃·冈顿', 'time': '1994-10-14(美国)', 'score': '9.5'}
{'index': '3', 'image': 'https://p0.meituan.net/movie/54617769d96807e4d81804284ffe2a27239007.jpg@160w_220h_1e_1c', 'title': '罗马假日', 'actor': '格利高里·派克,奥黛丽·赫本,埃迪·艾伯特', 'time': '1953-09-02(美国)', 'score': '9.1'}
{'index': '33', 'image': 'https://p1.meituan.net/movie/779bcc212a50a2526343362778f6b63c334618.jpg@160w_220h_1e_1c', 'title': '拯救大兵瑞恩', 'actor': '汤姆·汉克斯,马特·达蒙,汤姆·塞兹摩尔', 'time': '1998-07-24(美国)', 'score': '8.9'}完整代码:
import requests
import re
import json
import os
#猫眼电影网站有反爬虫措施,设置headers后可以爬取
headers = {'Content-Type': 'text/plain; charset=UTF-8',
'Origin': 'https://maoyan.com',
'Referer': 'https://maoyan.com/board/4',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'}
#爬取网页源代码
def get_one_page(url,headers):
try:
response=requests.get(url,headers=headers)
if response.status_code==200:
return response.text
return None
except:
return None
def main():
url = 'https://maoyan.com/board/4'
html=get_one_page(url,headers)
#正则表达式提取信息
def parse_one_page(html):
# re.S模式保证能匹配到换行符,()里是我们要配的内容
pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?src="/img?url=(.*?)".*?name"><a'
+ '.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>',
re.S)
items = re.findall(pattern, html)
for item in items:
# 相当于return一个字典
yield {
'index': item[0],
'image': item[1],
'title': item[2],
'actor': item[3].strip()[3:],
'time': item[4].strip()[5:],
'score': item[5] + item[6]
}
def main():
url = "https://maoyan.com/board/4"
html = get_one_page(url, headers)
for item in parse_one_page(html):
print(item)
#猫眼TOP100所有信息写入文件
def write_to_file(content):
#encoding ='utf-8',ensure_ascii =False,使写入文件的代码显示为中文
with open('C:\\Users\\nanafighting\\Desktop\\maoyantop100.txt','a',encoding ='utf-8') as f:
# 数据转换成json格式的字符串
f.write(json.dumps(content,ensure_ascii =False)+'\n')
f.close()
# 下载电影封面
def save_image_file(url, path):
jd = requests.get(url)
if jd.status_code == 200:
with open(path, 'wb') as f:
f.write(jd.content)
f.close()
def main(offset):
url = "https://maoyan.com/board/4?offset=" + str(offset)
html = get_one_page(url, headers)
if not os.path.exists('covers'):
os.mkdir('covers')
for item in parse_one_page(html):
print(item)
write_to_file(item)
save_image_file(item['image'], 'covers/' + item['title'] + '.jpg')
"""
if __name__ == '__main__':
# 对每一页信息进行爬取
for i in range(10):
main(i * 10)
"""
"""
if __name__ == '__main__':
main()
"""
##多线程抓取
from multiprocessing.pool import Pool
if __name__ == '__main__':
#对每一页信息进行爬取
pool = Pool()
pool.map(main,[i*10 for i in range(10)])
pool.close()参考链接:Python爬虫之抓取猫眼电影TOP100 - real向往的博客 - CSDN博客
大家如果对数据分析比较感兴趣可以关注我的知乎专栏:数据分析之路
https://zhuanlan.zhihu.com/c_1027961928915701760
知乎上面看代码更加方便,里面会不定期更新知识,希望与大家一起学习进步。
以上是关于反爬虫2-python3.6 正则表达式抓取猫眼电影TOP100的主要内容,如果未能解决你的问题,请参考以下文章