网络爬虫学习——抓取猫眼电影排行
Posted nqqqy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了网络爬虫学习——抓取猫眼电影排行相关的知识,希望对你有一定的参考价值。
大二学生,python小白,边学爬虫边学习python基础
使用教材:《python3网络爬虫开发实战》——崔庆才
首先贴出代码:
import requests from requests.exceptions import RequestException import re import json import time def get_one_page(url): headers={ ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/79.0.3945.117 Safari/537.36‘ } response=requests.get(url,headers=headers) if response.status_code==200: return response.text return None def parse_one_page(html): pattern=re.compile( ‘<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>.*?star.*?>(.*?)</p>.*?releasetime.*?>(.*?)</p>.*?integer.*?>(.*?)</i>.*?fraction.*?>(.*?)</i>.*?</dd>‘,re.S ) items=re.findall(pattern,html) for item in items: yield{ # yield为一个生成器 ‘index‘:item[0], ‘image‘:item[1], ‘title‘:item[2].strip(), ‘actor‘:item[3].strip()[3:], ‘time‘:item[4].strip()[5:], ‘score‘:item[5].strip()+item[6].strip() } def write_to_file(content): with open(‘result1.txt‘,‘a‘,encoding=‘utf-8‘) as f: print(type(json.dumps(content))) f.write(json.dumps(content,ensure_ascii=False)+‘ ‘) f.close() def main(offset): url=‘http://maoyan.com/board/4?offset=‘+ str(offset) # str():将对象转换为字符串 html=get_one_page(url) for item in parse_one_page(html): print(item) write_to_file(item) if __name__==‘__main__‘: for i in range(10): # range()可生成一个自然数列 main(offset=i*10) time.sleep(1) #延迟
运行结果:

关于爬虫:
1.网站地址为:https://maoyan.com/board/4
2.右击鼠标选择“检查”或者在键盘上按下f12,进入开发者工具
3.选择network监听工具,若此时页面为空,则刷新一下就好,可在最下面获得headers,如下图所示:
4.网页源代码如图所示:
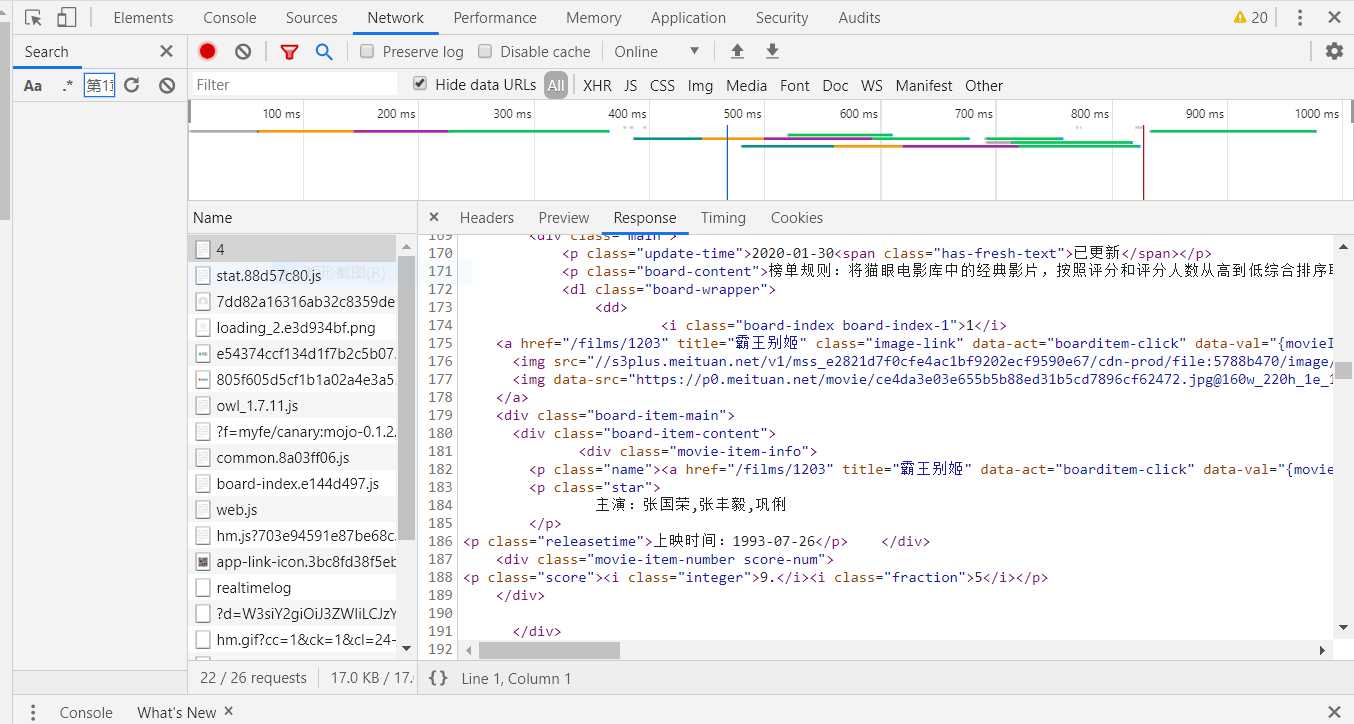
通过正则表达式提取需要的数据:
compile()方法可以将正则字符串编译成正则表达式对象,以便在后面的匹配中复用。
findall()方法会搜索整个字符串,然后返回匹配正则表达式的所有内容,如果有返回结果的话,就是列表类型,需要遍历来依次获取每组内容,第一个参数为正则表达式,第二个参数为需要搜索的字符串。
5.仔细观察各页面的url,不难发现offset代表偏移量,通过改变offset,我们可以得到不同页面的url
6.写入文件:
open()方法:打开文件,并保存文件操作对象,使用方式:文件句柄=open(‘文件路径‘,‘访问模式‘,‘编码格式‘)
read()方法:将文件读取到内存,使用read(num)可以从文件中读取数据,num表示要从文件中读取的数据的长度(字符个数),如果没有传入num或者为负,那么就表示读取文件中所有的数据,read()将读取的数据以字符串的形式返回。
注意:如果open是打开一个文件,那么可以不用写打开的模式,即只写 open(‘aaa.txt‘)
如果使用read读了多次,那么后面继续使用read读取的数据是从上次读完后的位置开始的
read ()方法默认会把文件的所有内容 一次性读取到内存,当然可以指定读取的字符数。如果文件太大,对内存的占用会非常严重
write()方法:将指定内容写入文件,使用方式:write(‘content‘),content为指定内容,注意:如果文件不存在那么创建,如果存在那么就先清空文件(覆盖),然后写入数据到文件里。
close()方法:关闭文件
read/write/close方法都需要文件对象来调用
文件路径:一种是相对路径,另一种是绝对路径,如:D:/python_study/result.txt
json全称为javascript Object Notation,JavaScript标记对象,通过对象和数组的组合来表示数据,是一种轻量级的数据交换格式。常用的数据处理方式有两种:Json的loads方法将JSON文本字符串转位JSON对象,dumps方法将JSON对象转位文本字符串,这里使用的是后者。
关于python:
我之前只接触过c,c++,java这类c like语言,初次学习python感觉是非常不适应,边学边说它是另类2333
‘‘‘ 多行注释 ‘‘‘ """ 多行注释 """ print(666) # 单行注释 a=1 # 参数不需要声明 b=2 # 不需要分号 print("%d%d"%(a,b)) # 异类!尽然不用逗号 def demo(): # def关键字定义函数,定义以冒号结尾 print(‘这是一个函数‘) # 函数体 #没有花括号,所以换行缩进显得尤为重要
python是一种解释型脚本语言,和C/C++语言不同,C/C++程序从main函数开始执行,python程序从开始到结尾顺序执行。总结下python中的main函数的作用:让模块(函数)可以自己单独执行(调试),相当于构造了调用其它函数的入口,这就类似于C/C++里面的mian函数了。
我一开始是直接写main():就开始调试了,运行成功,后来看到一位大佬的博文才明白写if __name__==‘__main__‘:的原因,主要在于有没有被import,博文地址:
https://blog.csdn.net/weixin_35684521/article/details/81396434
以上是关于网络爬虫学习——抓取猫眼电影排行的主要内容,如果未能解决你的问题,请参考以下文章
用pyquery 初步改写崔庆才的 抓取猫眼电影排行(正在更新)特意置顶,提醒自己更新