课 python 爬虫 01
Posted 酸辣土豆皮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了课 python 爬虫 01相关的知识,希望对你有一定的参考价值。
1.通讯协议
1.1 端口
我们想要进行数据通讯分几步?
- 1. 找到对方ip
- 2. 数据要发送到对方指定的应用程序上。为了标识这些应用程序,所以给这些网络应用程序都用数字进行了标识。为了方便称呼这个数字,叫做 端口。这里的端口 我们一般都叫做 \'逻辑端口\'
- 3. 定义通讯规则。这个通讯规则我们一般称之为协议
1.2 通讯协议
- 国际组织定义了通用的通信协议 TCP/IP协议:(关键:
TCP(Transmission Control Protocol,传输控制协议)提供的是面向连接,可靠的字节流服务。即客户和服务器交换数据前,必须现在双方之间建立一个TCP连接,之后才能传输数据。并且提供超时重发,丢弃重复数据,检验数据,流量控制等功能,保证数据能从一端传到另一端。
UDP(User Data Protocol,用户数据报协议)是一个简单的面向数据报的运输层协议。它不提供可靠性,只是把应用程序传给IP层的数据报发送出去,但是不能保证它们能到达目的地。由于UDP在传输数据报前不用再客户和服务器之间建立一个连接,且没有超时重发等机制,所以传输速度很快。
TCP三次握手过程
主机A通过向主机B 发送一个含有同步序列号标志位的数据段(SYN)给主机B ,向主机B 请求建立连接,通过这个数据段,主机A告诉主机B 两件事:我想要和你通信;你可以用哪个序列号作为起始数据段来回应我。
主机B 收到主机A的请求后,用一个带有确认应答(ACK)和同步序列号(SYN)标志位的数据段响应主机A,也告诉主机A两件事:我已经收到你的请求了,你可以传输数据了;你要用哪个序列号作为起始数据段来回应我。
主机A收到这个数据段后,再发送一个确认应答,确认已收到主机B 的数据段:“我已收到回复,我现在要开始传输实际数据了”。
这样3次握手就完成了,主机A和主机B 就可以传输数据了。TCP四次挥手过程
当主机A完成数据传输后,将控制位FIN置1,提出停止TCP连接的请求。
主机B收到FIN后对其作出响应,确认这一方向上的TCP连接将关闭,将ACK置1。
由B 端再提出反方向的关闭请求,将FIN置1。
主机A对主机B的请求进行确认,将ACK置1,双方向的关闭结束。TCP异常情况:
进程终止: 进程终止会释放文件描述符, 仍然可以发送FIN. 和正常关闭没有什么区别.
机器重启: 和进程终止的情况相同
机器掉电/网线断开: 接收端认为连接还在, 一旦接收端有写入操作, 接收端发现连接已经不在了, 就会进行 reset. 即使没有写入操作, TCP自己也内置了一个保活定时器, 会定期询问对方方是否还在. 如果对方不在, 也会把连接释放 - 所谓协议就是指计算机通信网络中两台计算机之间进行通信所必须共同遵守的规定或规则
- HTTP又叫做超文本传输协议(是一种通信协议) HTTP 它的端口是 80
2. 网络模型
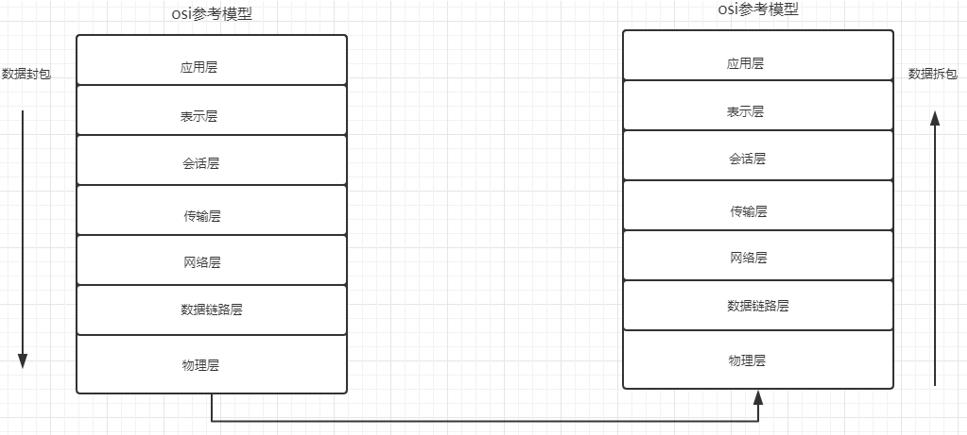
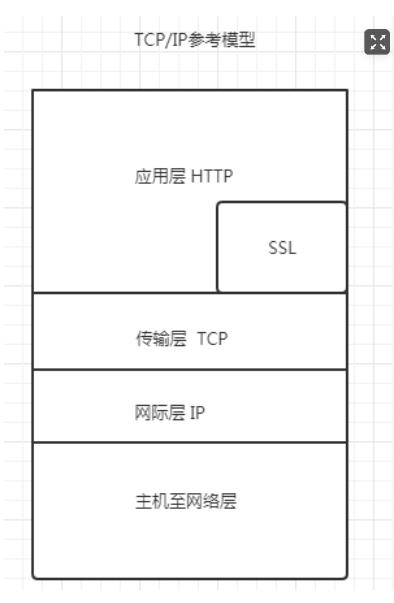
后期更新了新的参考模型 TCP/IP参考模型

2.1 HTTPS是什么呢?
- https=http+ssl,顾名思义,https是在http的基础上加上了SSL保护壳,信息的加密过程就是在SSL中完成的
- https,是以安全为目标的HTTP通道,简单讲是HTTP的安全版。即HTTP下加入SSL层,HTTPS的安全基础是SSL
2.2 SSL怎么理解?
- SSL也是一个协议主要用于web的安全传输协议
2.3 Http请求与响应
HTTP通信由两部分组成: 客户端请求消息 与 服务器响应消息
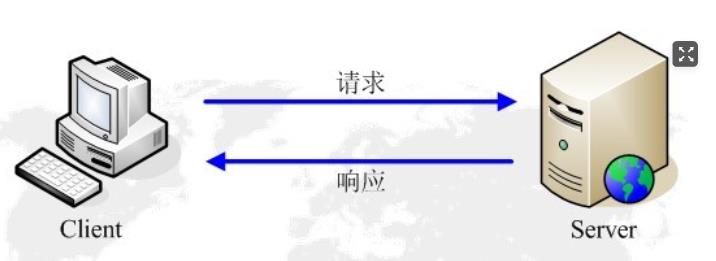
- 当用户在浏览器的地址栏中输入一个URL并按回车键之后,浏览器会向HTTP服务器发送HTTP请求。HTTP请求主要分为“Get”和“Post”两种方法。
- 当我们在浏览器输入URL http://www.baidu.com 的时候,浏览器发送一个Request请求去获取 http://www.baidu.com 的html文件,服务器把Response文件对象发送回给浏览器。
- 浏览器分析Response中的 HTML,发现其中引用了很多其他文件,比如Images文件,CSS文件,JS文件。 浏览器会自动再次发送Request去获取图片,CSS文件,或者JS文件。
- 当所有的文件都下载成功后,网页会根据HTML语法结构,完整的显示出来了。
2.4 客户端的Http请求
URL只是标识资源的位置,而HTTP是用来提交和获取资源。客户端发送一个HTTP请求到服务器的请求消息,包括以下格式:
请求行、请求头部、空行、请求数据
四个部分组成,下图给出了请求报文的一般格式。
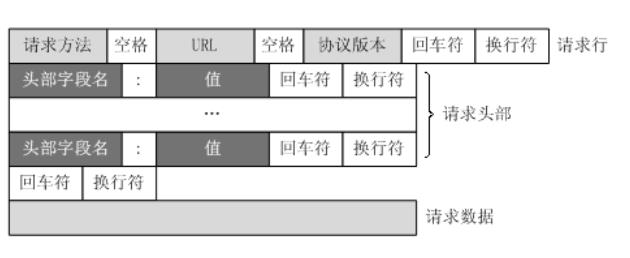
一个典型的HTTP请求示例
1 GET / HTTP/1.1 2 Host: www.baidu.com 3 Connection: keep-alive 4 Cache-Control: max-age=0 5 Upgrade-Insecure-Requests: 1 6 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.75 Safari/537.36 7 Sec-Fetch-Mode: navigate 8 Sec-Fetch-User: ?1 9 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3 10 Sec-Fetch-Site: same-origin 11 Referer: https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=Python%20%20%E6%89%8B%E5%8A%A8%E5%9B%9E%E6%94%B6%E5%9E%83%E5%9C%BE&oq=Python%2520%25E6%2594%25B6%25E5%2588%25B0%25E5%259B%259E%25E6%2594%25B6%25E5%259E%2583%25E5%259C%25BE&rsv_pq=f5baabda0010c033&rsv_t=1323wLC5312ORKIcfWo4JroXu16WSW5HqZ183yRWRnjWHaeeseiUUPIDun4&rqlang=cn&rsv_enter=1&rsv_dl=tb&inputT=2315&rsv_sug3=48&rsv_sug2=0&rsv_sug4=2736 12 Accept-Encoding: gzip, deflate, br 13 Accept-Language: zh-CN,zh;q=0.9 14 Cookie: BIDUPSID=4049831E3DB8DE890DFFCA6103FF02C1;
请求方法
根据HTTP标准,HTTP请求可以使用多种请求方法。
HTTP 0.9:只有基本的文本 GET 功能。
HTTP 1.0:完善的请求/响应模型,并将协议补充完整,定义了三种请求方法: GET, POST 和 HEAD方法。
HTTP 1.1:在 1.0 基础上进行更新,新增了五种请求方法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT 方法。
HTTP 2.0(未普及):请求/响应首部的定义基本没有改变,只是所有首部键必须全部小写,而且请求行要独立为 :method、:scheme、:host、:path这些键值对。
| 序号 | 方法 | 描述 |
| 1 | GET | 请求指定的页面信息,并返回实体主体。 |
| 2 | HEAD | 类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头 |
| 3 | POST | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件),数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。 |
| 4 | PUT | 从客户端向服务器传送的数据取代指定的文档的内容。 |
| 5 | DELETE | 请求服务器删除指定的页面。 |
| 6 | CONNECT | HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。 |
| 7 | OPTIONS | 允许客户端查看服务器的性能。 |
| 8 | TRACE | 回显服务器收到的请求,主要用于测试或诊断。 |
3. 爬虫介绍
3.1 什么是爬虫?
- 简单一句话就是代替人去模拟浏览器进行网页操作
3.2 为什么需要爬虫?
- 为其他程序提供数据源 如搜索引擎(百度、Google等)、数据分析、大数据等等
3.3 企业获取数据的方式?
- 1.公司自有的数据
- 2.第三方平台购买的数据 (百度指数、数据堂)
- 3.爬虫爬取的数据
3.4 Python 做爬虫的优势
- PHP : 对多线程、异步支持不太好
- Java : 代码量大,代码笨重
- C/C++ : 代码量大,难以编写
- Python : 支持模块多、代码简介、开发效率高 (scrapy框架)
3.5 爬虫的分类
- 通用网络爬虫 例如 baidu google yahu
- 聚焦网络爬虫: 根据既定的目标有选择的抓取某一特定主题内容
- 增量式网络爬虫: 指对下载网页采取增量式的更新和只爬行新产生的或者已经发生变化的网页爬虫
- 深层网络爬虫: 指那些大部分内容不能通过静态链接获取的、隐藏在搜索表单后的,只有用户提交一些关键词才能获得的web页面 例如 用户登录注册才能访问的页面
4. 几个概念
4.1 GET和POST
- GET : 查询参数都会在URL上显示出来
- POST : 查询参数和需要提交数据是隐藏在Form表单里的,不会在URL地址上显示出来
4.2 URL组成部分
- URL: 统一资源定位符
- https://new.qq.com/omn/TWF20200/TWF2020032502924000.html
- https: 协议
- new.qq.com: 主机名可以将主机理解为一台名叫 news.qq.com 的机器。这台主机在 qq.com 域名下
- port 端口号: 80 /new.qq.com 在他的后面有个 :80 可以省略
- TWF20200/TWF2020032502924000.html 访问资源的路径
- #anchor: 锚点用前端在做页面定位的
- 注意 : 在浏览器请求一个url,浏览器会对这个url进行一个编码。(除英文字母、数字和部分标识其他的全部使用% 加 十六进制码进行编码)
4.3 User-Agent 用户代理
- 作用:记录用户的浏览器、操作系统等,为了让用户更好的获取HTML页面效果
User-Agent:
Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36
- Mozilla Firefox:(Gecko内核)
4.4 Refer
- 表明当前这个请求是从哪个url过来的。一般情况下可以用来做反爬的技术
4.5 状态码
- 200 : 请求成功
- 301 : 永久重定向
- 302 : 临时重定向
- 403 : 服务器拒绝请求
- 404 : 请求失败(服务器无法根据客户端的请求找到资源(网页))
- 500 : 服务器内部请求
5. 抓包工具
(这里是Chrome)
移动端如Charles
- Elements : 元素 网页源代码,提取数据和分析数据(有些数据是经过特殊处理的所以并不是都是准确的)
- Console : 控制台 (打印信息)
- Sources : 信息来源 (整个网站加载的文件)
- NetWork : 网络工作(信息抓包) 能够看到很多的网页请求
以上是关于课 python 爬虫 01的主要内容,如果未能解决你的问题,请参考以下文章