Python:黑板课爬虫闯关第一关
Posted 丹枫无迹的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python:黑板课爬虫闯关第一关相关的知识,希望对你有一定的参考价值。
近日发现了【黑板课爬虫闯关】这个神奇的网页,练手爬虫非常的合适
地址:http://www.heibanke.com/lesson/crawler_ex00/
第一关非常的简单
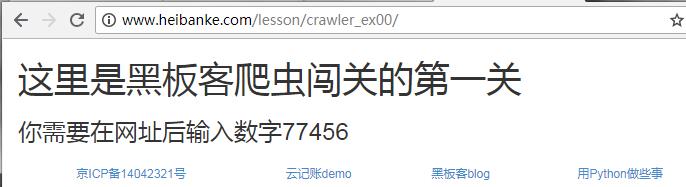
get 请求网址,在响应的 html 中用正则获取需要在网址后面输入的数字,生成新的 url,继续请求,直到通关。
代码如下:
import re
import requests
import time
def main():
url = \'http://www.heibanke.com/lesson/crawler_ex00/\'
get_next(url)
def get_next(url):
print(url)
html = requests.get(url).text
m = re.search(\'(你需要在网址后输入数字|下一个你需要输入的数字是)(\\d+)\', html)
if m:
num = m.group(2)
next_url = \'http://www.heibanke.com/lesson/crawler_ex00/\' + num
time.sleep(1)
get_next(next_url)
else:
m = re.search(\'(?<=\\<h3\\>).*?(?=\\</h3\\>)\', html)
print(m.group())
m = re.search(\'(\\<).*?href="([^"]*?)".*?(\\>下一关\\</a\\>)\', html)
print(f\'下一关 http://www.heibanke.com{m.group(2)}\')
if __name__ == \'__main__\':
main()
以上是关于Python:黑板课爬虫闯关第一关的主要内容,如果未能解决你的问题,请参考以下文章