python爬虫课设-爬取3000条数据并做数据可视化
Posted Henrik-Yao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫课设-爬取3000条数据并做数据可视化相关的知识,希望对你有一定的参考价值。
很久以前接的单子,分享一下(挺水的,将就着看吧)
文章目录
作业要求
《Python与数据分析》期末大作业要求(2020-2021学年第2学期)
一、期末作业要求:
1、在前期作业爬取的数据基础上,用Python编写代码对爬取的数据进行全面数据分析并可视化,鼓励建立计量模型进行分析;
2、写作期末大作业文档:整体思路,对爬取网站的分析,对数据进行哪些方面的数据分析及数据的可视化,结论。
3、必须自己编写爬虫程序,不允许使用爬虫框架(如scrapy) 爬取数据,严禁抄袭。
二、提交:
1、爬虫程序代码(前期作业)文件
(.ipynb),加, 上必要的注释或笔记说明;
2、数据分析、可视化代码文件(.ipynb) ,加上必要的注释或笔记说明;
3、抓取的数据文件及数据分析和可视化产生的中间文件;
4、期末作业文档。
数据爬取
# 用于爬取信息
import requests
# 用于解析网页
from bs4 import BeautifulSoup
# 用于正则匹配找到目标项目
import re
# 对csv文件的操作
import csv
# 打开文件
# a+权限追加写入
# newline=""用于取消自动换行
fp = open("data.csv", "a+", newline="")
# 修饰,处理成支持scv读取的文件
csv_fp = csv.writer(fp)
# 设置csv文件内标题头
head = ['日期', '最高气温', '最低气温']
# 写入标题
csv_fp.writerow(head)
# UA伪装
headers =
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:86.0) Gecko/20100101 Firefox/86.0"
# 存放全部数据
data = []
# 进行url拼接,主要拼接的是年份和月份
# 从2011年到2020年
for i in range(2011, 2021):
# 从1月到12月
for j in range(1, 13):
# 字符串化
i = str(i)
# 小于10则补0
if j < 10:
j = "0" + str(j)
else:
# 字符串化
j = str(j)
# 完成拼接
url = "http://www.tianqihoubao.com/lishi/beijing/month/" + i + j + ".html"
# 获取响应
response = requests.get(url=url, headers=headers)
# 设置编码为gbk
response.encoding = 'gbk'
# 获取响应文本数据
page = response.text
# 用BeautifulSoup解析网页
soup = BeautifulSoup(page, 'lxml')
# 获取所有tr标签
tr_list = soup.find_all('tr')
# 解析每一个tr标签
for tr in tr_list:
# 用于存放一天的数据
one_day = []
# 字符串化便于正则匹配
tr = str(tr)
# 去除所有空格
tr = tr.replace(" ", "")
# 取出日期
date = re.findall(r'title="(.*?)北京天气预报">', tr)
# 如果取到则放入one——day存放
if date:
one_day.append(date[0])
# 取出最高温和最低温
tem = re.findall(r'(.*?)℃', tr)
# 如果取到则放入one——day存放
if tem:
one_day.append(tem[0])
one_day.append(tem[1])
# 如果完整的取到一天的数据则放入data存放
if len(one_day) == 3:
data.append(one_day)
print(one_day)
# 写入csv文件
csv_fp.writerow(one_day)
# 关闭文件指针
fp.close()
爬取结果
数据处理
# 读取csv文件
import csv
# 作图工具
from matplotlib import pyplot as plt
# 存放日期
x = []
# 存放最高气温
h = []
# 存放最低气温
l = []
# 读取之前爬取的数据
with open("data.csv") as f:
reader = csv.reader(f)
j = 1
for i, rows in enumerate(reader):
# 不要标题那一行
if i:
row = rows
print(row)
x.append(rows[0])
h.append(int(rows[1]))
l.append(int(rows[2]))
# 设置画板大小
fig = plt.figure(dpi=128, figsize=(20, 6))
# 显示中文标签
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 画最高气温
plt.plot(x, h, c="red", alpha=0.5)
# 画最低气温
plt.plot(x, l, c="blue", alpha=0.5)
# 区间渲染
plt.fill_between(x, h, l, facecolor="blue", alpha=0.2)
# 标题
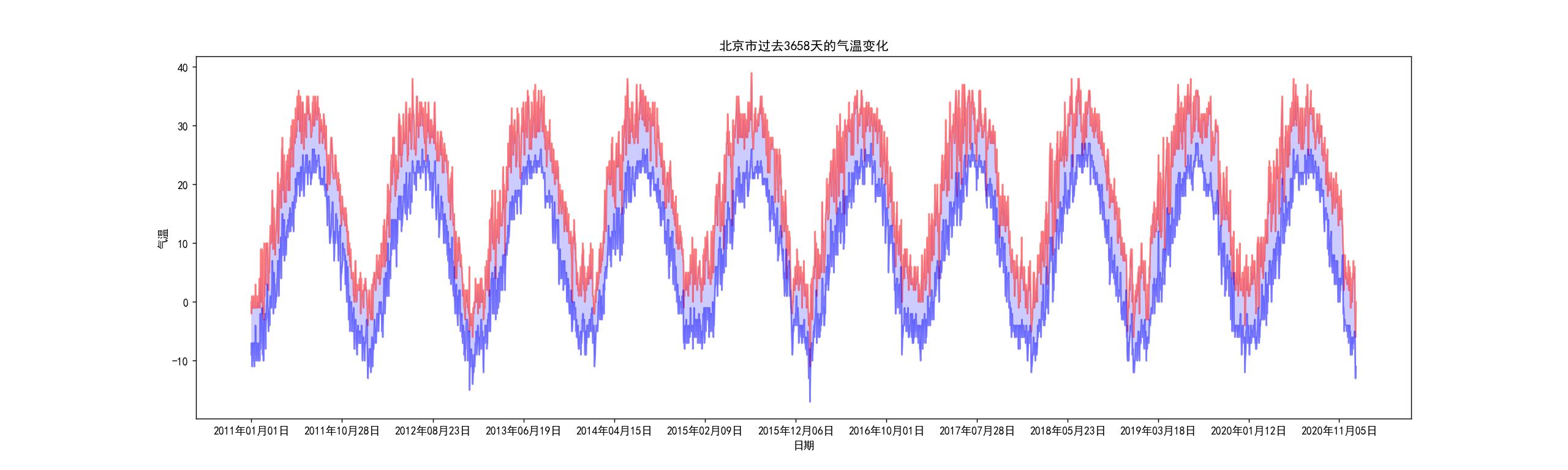
plt.title("北京市过去3658天的气温变化")
# y轴名称
plt.ylabel("气温")
# x轴名称
plt.xlabel("日期")
plt.xticks(x[::300])
plt.show()
数据可视化
大作业文档
整体思路
爬取天气后保网站北京市过去9年(3658天)的最高温度和最低温度,并运用matplotlib绘制折线图进而分析天气变化趋势
网站分析
1.该网站单次只能查询一个月的天气情况,所以通过拼接url的方式依次查询
2.查询数据位于table表单中,tr标签没有属性,所有用正则匹配处理每个tr时需要判断有没有取到数据,日期,最高气温,最低气温都查询到时视为成功并存入总数据的列表
数据分析
1.通过过去3658天的气温变化,可以看出北京市每年的寒暑气温温差基本稳定在50度左右,而2015年寒暑温差超过60度
结论
1.北京市温度变化基本符合规律
以上是关于python爬虫课设-爬取3000条数据并做数据可视化的主要内容,如果未能解决你的问题,请参考以下文章