哈希表与布隆过滤器
Posted 江柏英的技术博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了哈希表与布隆过滤器相关的知识,希望对你有一定的参考价值。
一、哈希的整体思想
最简单的哈希表其实就是数组,从数组中取出一个数的时间复杂度是O(1)的。但是数组下标类型是整型的,万一我的下标类型不是整型了该怎么办呢?比如说字符串型,典型的就是我想查找某个单词存不存在。还有些更复杂的数据类型,比如自定义的类型。那么问题就来了,如何满足任意数据类型的索引需求呢?最简单直接的想法,其实就是先对任意数据类型与整型的数组下标做一个映射,往后就又回到数组取数的环节了。这种映射是一种高维空间到低维空间的映射。低维空间是有限的,而高维空间的变化情况要复杂得多。如果采用一个萝卜一个坑的思想,必然会产生重复占位,这就是哈希冲突。当我们在设计哈希表的时候一定要考虑到哈希冲突。为什么说哈希表的设计感极强,其实就在于,解决哈希冲突的方法是多种多样的。还有一个问题,哈希表装满了怎么办?有一个概念叫做装填因子(=存储元素数/哈希表size大小)一般来说,装填因子达到0.75的情况下,意味着哈希表可能要进行扩容了。
布隆过滤器
好了,说回布隆过滤器,传统哈希表有一个缺点,就是存储空间与元素数量有关,在大数据的场景下,经常需要判重操作。如果用一张哈希表存,数据量可能过于庞大。而布隆过滤器,可以实现存储空间与元素数量无关。它是通过几组不同的哈希函数,映射到不同的数组下标,然后在对应位置的数组上标记为1,默认是0,如果这些位置上的数组值一旦只要出现一个0,那么都可以直接判断出,该元素不存在,但是如果全为1,也不能说明它就一定存在哈希表中,只能说明它大概率存在。布隆过滤器经常应用于大数据和信息安全相关的场景中。
二、哈希冲突解决办法
1、开放地址法
思想:如果7的位置发生冲突了,那就试一试8,8也不行,那就试一试9,依次往后“探测”,直到找到空位。(线性探测法)
注意:往后探测位置的计算规则是很灵活的,这里只是举了最简单的线性探测法。
平方探测法也有两种,可以简要看看找找区别,做题的时候格外注意,到底是哪一种:
第一种:7->8->12->21->37 (a[i+1] = a[i] + i^2)
第二种:7->8->11->16->23 (a[i+1] = a[0] + i^2)
值得注意的是,第二种只需要判断 i 从0-Msize-1 即可,因为(key+Msize*Msize)%Msize代表搜索回到了原地,这时可以认为无法搜索到这个数字
2、再哈希法
思想:比方说可以设计三种不同的哈希函数,如果第一种冲突了,就试试第二种,第二种也冲突了就试试第三种,依次类推。
注意:这种方法治标不治本,一般配合其他的哈希冲突解决方法使用。
3、建立公共溢出区
思想:另外建立一个公共溢出区,我想找的元素哈希表中找不到,就去公共溢出区再找找,其实就是用另外一种数据结构来维护,比方说红黑树。
4、链式地址法(拉链法)
思想:把哈希表的每一个坑看成链表的头节点。如果两个元素都想占用这个坑,直接在该坑上往后形成一个链表即可。
三、哈希表代码实现:
#include<iostream>
#include<vector>
using namespace std;
// 开放寻址法
class HashTable
public:
HashTable(int n = 100) : data(n), flag(n), cnt(0)
void insert(string s)
int ind = hash_func(s) % data.size(); // 计算哈希值
recalc_ind(ind, s); // 冲突处理
if (!flag[ind])
data[ind] = s;
flag[ind] = true;
cnt++;
if (cnt * 100 > data.size() * 75)
expand();
bool find(string s)
int ind = hash_func(s) % data.size(); // 计算哈希值
recalc_ind(ind, s); // 冲突处理
return flag[ind];
private:
int cnt; // 记录有多少元素
vector<string> data;
vector<bool> flag; // 记录相应位置是否存数据
void expand()
int n = data.size() * 2;
HashTable h(n);
for (int i = 0; i < data.size(); i++) // 看似很高的时间复杂度,其实分摊到每一个元素,扩容所造成的时间复杂度是O(1)的。
if (flag[i] == false) continue;
h.insert(data[i]);
*this = h;
return ;
int hash_func(string &s)
int seed = 131, hash = 0;
for (int i = 0; s[i]; i++)
hash = hash * seed + s[i];
return hash & 0x7fffffff; // 最高位是0,最后肯定是一个正数
void recalc_ind(int &ind, string s)
int t = 1;
while (flag[ind] && data[ind] != s)
ind += t * t;
t += 1;
ind %= data.size();
return ;
;
// 公共溢出区法:
class HashTable
public:
HashTable(int n = 100) : flag(n), data(n), cnt(0)
void insert(string s)
int ind = hash_func(s) % data.size(); // 计算哈希值
recalc_ind(ind, s); // 冲突处理
if (flag[ind] == false)
data[ind] = s;
flag[ind] = true;
cnt += 1;
if (cnt * 100 > data.size() * 75)
expand();
else if (data[ind] != s)
buff.insert(s);
return ;
bool find(string s)
int ind = hash_func(s) % data.size(); // 计算哈希值
recalc_ind(ind, s); // 冲突处理
if (flag[ind] == false) return false;
if (data[ind] == s) return true;
return buff.find(s) != buff.end();
private:
int cnt;
vector<string> data;
vector<bool> flag;
set<string> buff;
void expand()
int n = data.size() * 2;
HashTable h(n);
for (int i = 0; i < data.size(); i++)
if (flag[i] == false) continue;
h.insert(data[i]);
for (auto x : buff)
h.insert(x);
*this = h;
return ;
int hash_func(string &s)
int seed = 131, hash = 0;
for (int i = 0; s[i]; i++)
hash = hash * seed + s[i];
return hash & 0x7fffffff;
void recalc_ind(int &ind, string &s)
return ;
;
// 拉链法
class Node
public :
Node(string data = "", Node *next = nullptr) : data(), next(nullptr)
string data;
Node *next;
void insert(Node *node)
node->next = this->next;
this->next = node;
return ;
;
class HashTable
public:
HashTable(int n = 100) : data(n), cnt(0)
void insert(string s)
int ind = hash_func(s) % data.size(); // 计算哈希值
recalc_ind(ind, s); // 冲突处理
Node *p = &data[ind];
while (p->next && p->next->data != s) p = p->next;
if (p->next == nullptr)
p->insert(new Node(s));
cnt += 1;
if (cnt > data.size() * 3) expand();
return ;
bool find(string s)
int ind = hash_func(s) % data.size(); // 计算哈希值
recalc_ind(ind, s); // 冲突处理
Node *p = data[ind].next;
while (p && p->data != s) p = p->next;
return p != nullptr;
private:
int cnt;
vector<Node> data;
void expand()
int n = data.size() * 2;
HashTable h(n);
for (int i = 0; i < data.size(); i++)
Node *p = data[i].next;
while (p)
h.insert(p->data);
p = p->next;
*this = h;
return ;
int hash_func(string &s)
int seed = 131, hash = 0;
for (int i = 0; s[i]; i++)
hash = hash * seed + s[i];
return hash & 0x7fffffff;
void recalc_ind(int &ind, string &s)
return ;
;
int main()
int op;
string s;
HashTable h;
while (cin >> op >> s)
switch (op)
case 1: h.insert(s); break;
case 2: cout << "find " << s << " : " << h.find(s) << endl; break;
return 0;
看到这里,不妨来一道PAT的题目练练手吧,PAT题目链接:https://pintia.cn/problem-sets/994805342720868352/exam/problems/994805343236767744
题解代码:
#include<iostream>
#include<vector>
#include<cmath>
using namespace std;
#define MAX_N 20000
int Msize, n, m;
int a[MAX_N + 5], flag[MAX_N + 5];
int cnt;
bool insert(int s)
if (cnt == Msize) return false;
for (int t = 0; t < Msize; t++)
int ind = (s + t * t) % Msize;
if (!flag[ind])
a[ind] = s;
flag[ind] = 1;
cnt++;
return true;
return false;
bool is_prime(int x)
if (x < 2) return false;
for (int i = 2, I = sqrt(x); i <= I; i++)
if (x % i == 0) return false;
return true;
int main()
// 初始化
int x;
scanf("%d%d%d",&Msize, &n, &m);
while (!is_prime(Msize)) Msize++;
// 插入部分
for (int i = 0 ; i < n; i++)
scanf("%d", &x);
bool insert_status = insert(x);
if (!insert_status) printf("%d cannot be inserted.\\n", x);
// 查找部分
int ans = 0;
for (int i = 0; i < m; i++)
scanf("%d", &x);
int t;
for (t = 0; t <= Msize; t++)
ans += 1;
int ind = (x + t * t) % Msize;
if (a[ind] == x || flag[ind] == 0) break;
printf("%.1f\\n", ans * 1.0 / m);
return 0;
高级数据结构 ---- 跳跃表布隆过滤器一致性哈希雪花算法
高级数据结构
1、跳跃表(skiplist)
1.1 什么是跳表?
跳表是一个随机化的数据结构,实际就是一种可以进行二分查找的有序链表。
跳表在原有的有序链表上面增加了多级索引,通过索引来实现快速查找。
(不仅提高了搜索性能,也提高了插入和删除操作的性能)
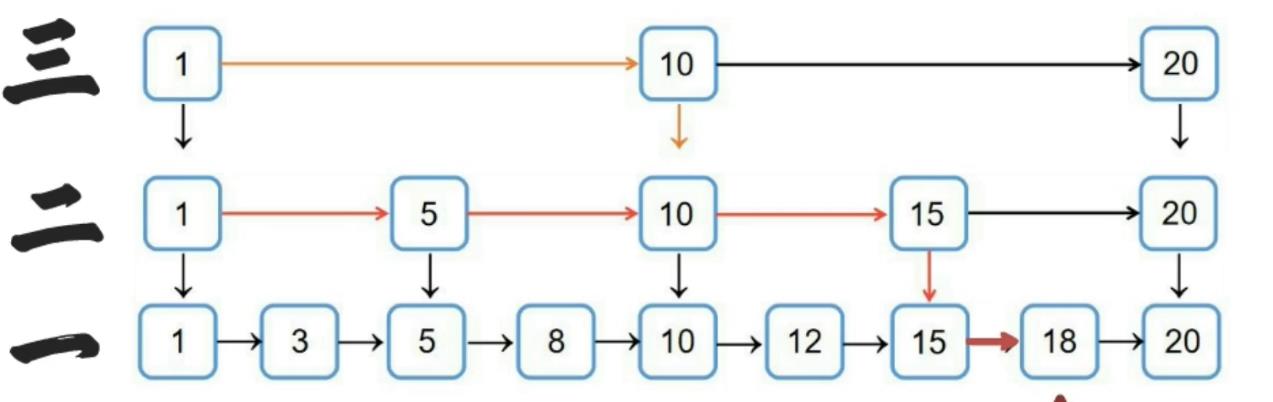
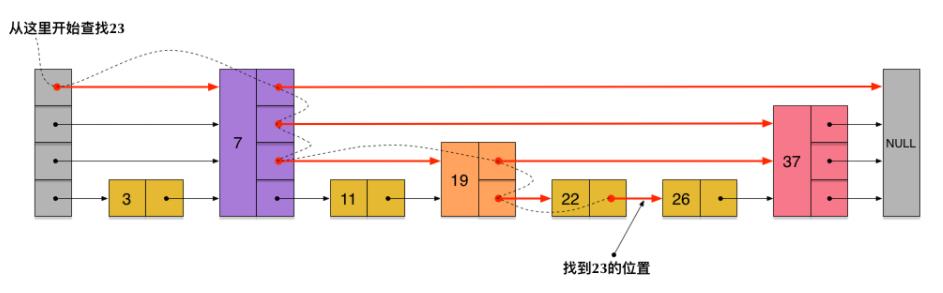
1.2 跳跃表的性质
1.2.1 基本性质
- 跳跃表的每一层都是一条有序的链表
- 跳跃表的查询次数近似于层数,时间复杂度为O(logn)、插入、删除也为O(logn)
- 最底层的链表包含所有元素
- 跳跃表是一种随机化的数据结构(通过抛硬币来决定层数),这样做的目的是为了保证平衡,不会出现两个索引之间存在大量数据
- 跳跃表的空间复杂度为O(n)
1.2.1 索引层的随机提拔
跳表的设计者采用了一种有趣的办法:抛硬币。也就是随机决定新节点是否提拔,每向上提拔一层的几率是50%。因为跳跃表的删除和添加节点是不可预测的,很难用一种有效的算法来保证跳表的索引分布始终均匀。这种方法虽然不能保证索引绝对均匀分布。但是可以让大体趋于平均。
1.3 跳跃表与其它结构相比
-
跳跃表 VS 二叉搜索树
二叉搜索树插入、删除、查找平均时间复杂度也为O(logn),但是在最坏情况下,二叉搜索树退化成链表,时间复杂度变为O(n);
另外,跳跃表更适合作为
范围查找,只需要找到最小值即可,然后顺序遍历若干步就可以了;而平衡树的查找需要通过中序遍历顺序查找并不容易实现。 -
跳跃表 VS 红黑树
红黑树插入、删除、查找平均时间复杂度也为O(logn),但是红黑树的插入、删除结点时,是通过调整结构来保持红黑树的平衡,比起跳跃表直接通过一个随机数来决定跨越几层,在时间复杂度的花销上是要高于跳跃表的
-
跳跃表 VS B+树
B+树实现上更复杂,维持结构平衡的成本高,更适合磁盘的索引。
跳跃表比较适合内存查找。
-
内存占用上
跳跃表比平衡树更灵活一些。平衡树的每个节点包含2个指针,而Redis中跳跃表的每个节点包含的指针数目平均要比平衡树要小
-
对范围查找的支持
-
实现难易程度
1.4 使用场景
-
Redis使用跳跃表作为有序集合键的底层实现之一
条件: 如果一个有序集合包含的元素数量比较多,又或者有序集合中元素的成员是比较长的字符串时,Redis就会使用跳跃表来作为有序集合的底层实现。(由ziplist压缩列表编码转化为skiplist跳跃表编码) 使用skiplist编码的有序集合对象使用zset结构作为底层实现,一个zset结构同时包含一个字典和一个跳跃表
1.5 Redis中的跳跃表
Redis跳跃表实现由 zskiplist 和 zskiplistNode 两个结构组成,其中zskiplist用于保存跳跃表信息(比如表头结点、表尾结点、长度),而zskiplistNode则用于表示跳跃表结点
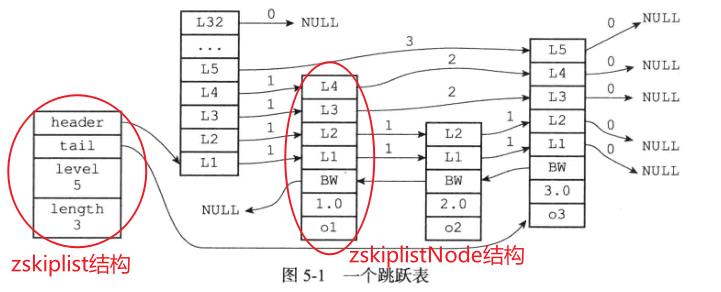
-
zskiplist结构-
header:指向跳跃表的表头节点
-
tail: 指向跳跃表的表尾节点
-
level: 记录目前跳跃表内,层数最大的那个节点的层数(表头节点不计算在内)
-
length: 记录跳跃表的长度,即跳跃表目前包含节点的数量(表头节点不计算在内)
-
-
zskiplistNode结构-
层(level):节点中用L1、L2、L3等字样标记节点的各个层
-
后退(backward)指针: 节点中用BW字样标记节点的后退指针
-
分值(score): 各个节点中的1.0、2.0和3.0是节点所保存的分值。在跳跃表中,节点按各自所保存的分值从小到大排列
-
成员对象(obj):各个节点中的o1、o2、o3是节点所保存的成员对象
如果分值相同的情况下,节点按照成员对象的从小到大进行排序,大的对象在后面(靠近表尾的方向)。
-
2、布隆过滤器(Bloom Filter)
场景: 经常判断1个元素是否存在,怎么做?
-
使用哈希表(HashMap),将元素作为key去查找
时间复杂度:O(1),但是空间利用率不高,需要占用比较多的内存资源
-
使用布隆过滤器
2.1 什么是布隆过滤器
-
概念
是一个空间效率高的概率型数据结构,可以用来告诉你: 一个元素一定不存在或者可能存在
-
优点
空间效率和查询时间都远远超过一般的算法
-
缺点
有一定的误判率、删除困难
-
本质
实质上是一个很长的二进制向量和一系列随机映射函数(Hash函数)
-
常见应用
网页黑名单系统、垃圾邮件过滤系统、爬虫的网址判重系统、解决缓存穿透问题
2.2 原理
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FPnLpHbE-1621510762071)(面试-高级数据结构.assets/image-20210520193354932.png)]
-
假设布隆过滤器由20位二进制、3个哈希函数组成,每个元素经过哈希函数处理都能生成一个索引位置
- 添加元素 : 将每一个哈希函数生成的索引位置都设为1
- 查询元素是否存在 (存在的可能存在,不存在的一定不存在)
- 如果有一个哈希函数生成的索引位置值不为1,就代表不存在(100%准确)
- 如果有一个哈希函数生成的索引位置都位1,就代表存在(存在一定的误判率)
-
添加、查询的时间复杂度都是: O(k),k是哈希函数的个数。空间复杂度是: O(m),m是二进制的个数
2.3 场景(Redis缓存穿透)
网页黑名单系统、垃圾邮件过滤系统、爬虫的网址判重系统、解决缓存穿透问题
Redis中的缓存穿透问题的解决方案之一: 布隆过滤器
使用一个足够大的bitmap,用于存储可能访问的key,不存在的key直接被过滤
缓存穿透:访问一个不存在的key,缓存不起作用,请求会穿透到DB,流量大时DB会挂掉。
缓存击穿:一个存在的key,在缓存过期的一刻,同时有大量的请求,这些请求都会击穿到DB,造成瞬时DB请求量大、压力骤增
3、一致性哈希
一致性哈希可以有效解决分布式存储结构下动态增加和删除节点所带来的问题。
3.1 普通哈希
场景描述: 我们有三台缓存服务器,用于缓存图片,我们为这三台缓存服务器编号为0号、1号、2号,现在,有3万张图片需要缓存,我们希望这些图片被均匀的缓存到这3台服务器上,以便它们能够分摊缓存的压力。
使用哈希公式:hash(图片名称)% N
-
新增服务器
假设增加一台缓存服务器,缓存服务器的数量由3台变成了4台,此时,如果仍然使用上述方法对同一张图片进行缓存,那么这张图片所在的服务器编号必定与原来3台服务器时所在的服务器编号不同,因为除数由3变为了4,被除数不变的情况下,余数肯定不同,这种情况带来的结果就是当服务器数量变动时,所有缓存的位置都要发生改变,换句话说,当服务器数量发生改变时,所有缓存在一定时间内是失效的,当应用无法从缓存中获取数据时,则会向后端服务器请求数据
-
删除服务器
假设移除了一台缓存服务器,那么缓存服务器数量从3台变为2台,如果想要访问一张图片,这张图片的缓存位置必定会发生改变,以前缓存的图片也会失去缓存的作用与意义,由于大量缓存在同一时间失效,造成了
缓存的雪崩,此时整个系统很有可能被压垮,所以,为了解决这些问题,一致性哈希算法诞生了。
3.2 一致性哈希算法
3.2.1 基本原理
一致性哈希算法将整个哈希值空间映射成一个虚拟的圆环,整个哈希空间的取值范围为0~2^32-1。整个空间按顺时针方向组织。
一致性哈希算法也是使用取模的方法,只是,刚才描述的取模法是对服务器的数量进行取模,而一致性哈希算法是对2^32取模。
把2^32想象成一个圆
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GRwUlqsZ-1621510762072)(面试-高级数据结构.assets/20210520192653.png)]
假设我们有3台缓存服务器,服务器A、服务器B、服务器C,那么,在生产环境中,这三台服务器有自己的IP地址,我们使用它们各自的IP地址进行哈希计算,使用哈希后的结果对2^32取模。
公式: hash(服务器的IP地址) % 2^32
同样的方法,我们也可以将需要缓存的对象映射到hash环上。
公式: hash(图片名称) % 2^32
从图片的位置开始,沿顺时针方向遇到的第一个服务器就是A服务器,所以,上图中的图片将会被缓存到服务器A上,如下图所示
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CnzRbsVl-1621510762073)(面试-高级数据结构.assets/20210520192651.png)]
依次类推,假设有4张图片
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GocW8j9J-1621510762074)(面试-高级数据结构.assets/20210520192655.png)]
1号、2号图片将会被缓存到服务器A上,3号图片将会被缓存到服务器B上,4号图片将会被缓存到服务器C上。
3.2.2 优点
假设,服务器B出现了故障,我们现在需要将服务器B移除,那么,我们将上图中的服务器B从hash环上移除即可,移除服务器B以后示意图如下。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cJCJid7n-1621510762076)(面试-高级数据结构.assets/20210520192654.png)]
在服务器B未移除时,图片3应该被缓存到服务器B中,可是当服务器B移除以后,按照之前描述的一致性哈希算法的规则,图片3应该被缓存到服务器C中,因为从图片3的位置出发,沿顺时针方向遇到的第一个缓存服务器节点就是服务器C,也就是说,如果服务器B出现故障被移除时,图片3的缓存位置会发生改变。
但是,图片4仍然会被缓存到服务器C中,图片1与图片2仍然会被缓存到服务器A中,这与服务器B移除之前并没有任何区别,这就是一致性哈希算法的优点,如果使用之前的hash算法,服务器数量发生改变时,所有服务器的所有缓存在同一时间失效了,而使用一致性哈希算法时,服务器的数量如果发生改变,并不是所有缓存都会失效,而是只有部分缓存会失效,前端的缓存仍然能分担整个系统的压力,而不至于所有压力都在同一时间集中到后端服务器上。
3.2.3 hash环的偏斜
3.2.3.1 问题所在
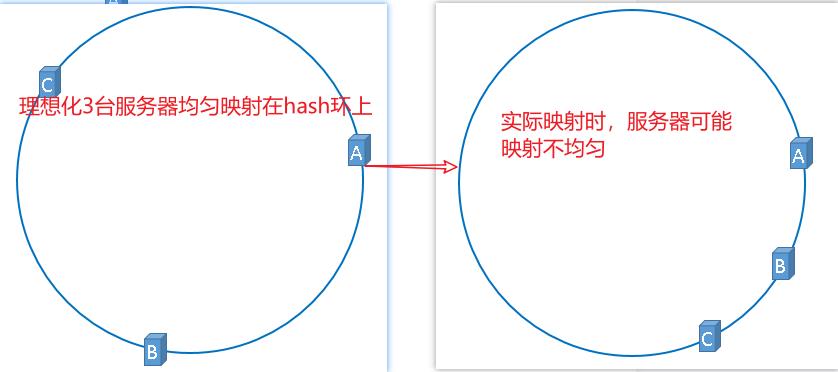
服务器被映射成右图中的模样,那么被缓存的对象很有可能大部分集中缓存在某一台服务器上。
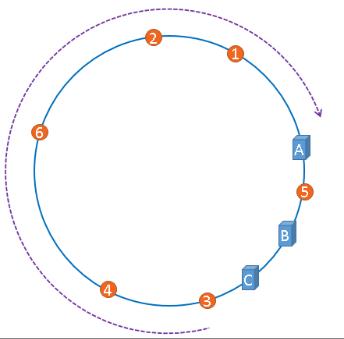
上图中,1号、2号、3号、4号、6号图片均被缓存在了服务器A上,只有5号图片被缓存在了服务器B上,服务器C上甚至没有缓存任何图片,如果出现上图中的情况,A、B、C三台服务器并没有被合理的平均的充分利用,缓存分布的极度不均匀,而且,如果此时服务器A出现故障,那么失效缓存的数量也将达到最大值,在极端情况下,仍然有可能引起系统的崩溃,上图中的情况则被称之为hash环的偏斜,那么,我们应该怎样防止hash环的偏斜呢?一致性hash算法中使用”虚拟节点”解决了这个问题。
3.2.3.1 虚拟节点
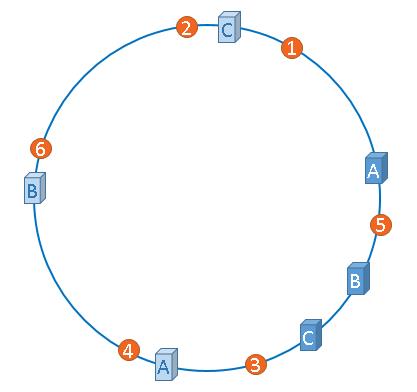
将现有的物理节点通过虚拟的方法复制出来,这些由实际节点虚拟复制而来的节点被称为”虚拟节点”。加入虚拟节点以后的hash环如下,引入虚拟节点的概念后,缓存的分布就均衡多了。
4、雪花算法(Snow Flake)
分布式id生成算法有很多种,Twitter的Snow Flake就是经典的一种
4.1 算法原理
Snow Flake算法生成id的结果是一个64bit大小的整数,结构如下图:
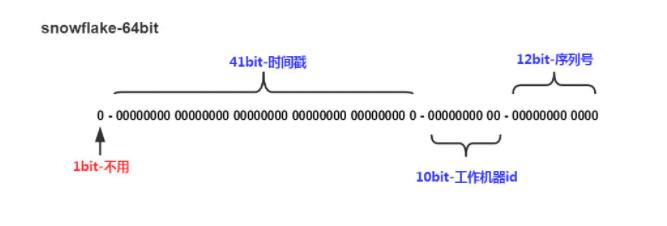
- 1bit:二进制中最高位是符号位,1表示负数,0表示整数。生成id一般都是用整数,所以最高位固定位0
- 41bit-时间戳:用来记录时间戳,毫秒级
- 10bit-工作机器id:用来记录工作机器id
- 12bit-序列号:用来记录同毫秒内产生的不同id
由于在Java中64bit的整数是long类型,所以在Java中SnowFlake算法生成的id就是long来存储的。
以上是关于哈希表与布隆过滤器的主要内容,如果未能解决你的问题,请参考以下文章