高级数据结构 ---- 跳跃表布隆过滤器一致性哈希雪花算法
Posted whc__
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了高级数据结构 ---- 跳跃表布隆过滤器一致性哈希雪花算法相关的知识,希望对你有一定的参考价值。
高级数据结构
1、跳跃表(skiplist)
1.1 什么是跳表?
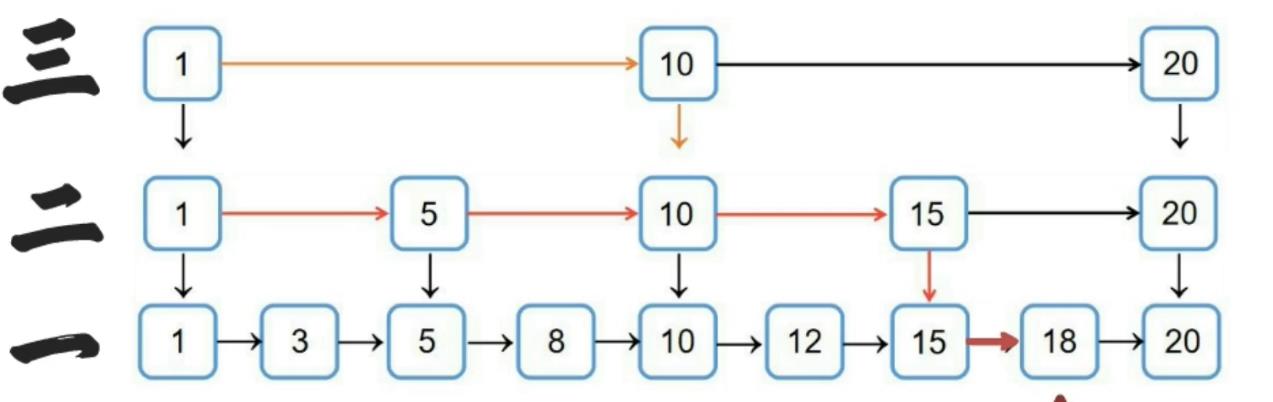
跳表是一个随机化的数据结构,实际就是一种可以进行二分查找的有序链表。
跳表在原有的有序链表上面增加了多级索引,通过索引来实现快速查找。
(不仅提高了搜索性能,也提高了插入和删除操作的性能)
1.2 跳跃表的性质
1.2.1 基本性质
- 跳跃表的每一层都是一条有序的链表
- 跳跃表的查询次数近似于层数,时间复杂度为O(logn)、插入、删除也为O(logn)
- 最底层的链表包含所有元素
- 跳跃表是一种随机化的数据结构(通过抛硬币来决定层数),这样做的目的是为了保证平衡,不会出现两个索引之间存在大量数据
- 跳跃表的空间复杂度为O(n)
1.2.1 索引层的随机提拔
跳表的设计者采用了一种有趣的办法:抛硬币。也就是随机决定新节点是否提拔,每向上提拔一层的几率是50%。因为跳跃表的删除和添加节点是不可预测的,很难用一种有效的算法来保证跳表的索引分布始终均匀。这种方法虽然不能保证索引绝对均匀分布。但是可以让大体趋于平均。
1.3 跳跃表与其它结构相比
-
跳跃表 VS 二叉搜索树
二叉搜索树插入、删除、查找平均时间复杂度也为O(logn),但是在最坏情况下,二叉搜索树退化成链表,时间复杂度变为O(n);
另外,跳跃表更适合作为
范围查找,只需要找到最小值即可,然后顺序遍历若干步就可以了;而平衡树的查找需要通过中序遍历顺序查找并不容易实现。 -
跳跃表 VS 红黑树
红黑树插入、删除、查找平均时间复杂度也为O(logn),但是红黑树的插入、删除结点时,是通过调整结构来保持红黑树的平衡,比起跳跃表直接通过一个随机数来决定跨越几层,在时间复杂度的花销上是要高于跳跃表的
-
跳跃表 VS B+树
B+树实现上更复杂,维持结构平衡的成本高,更适合磁盘的索引。
跳跃表比较适合内存查找。
-
内存占用上
跳跃表比平衡树更灵活一些。平衡树的每个节点包含2个指针,而Redis中跳跃表的每个节点包含的指针数目平均要比平衡树要小
-
对范围查找的支持
-
实现难易程度
1.4 使用场景
-
Redis使用跳跃表作为有序集合键的底层实现之一
条件: 如果一个有序集合包含的元素数量比较多,又或者有序集合中元素的成员是比较长的字符串时,Redis就会使用跳跃表来作为有序集合的底层实现。(由ziplist压缩列表编码转化为skiplist跳跃表编码) 使用skiplist编码的有序集合对象使用zset结构作为底层实现,一个zset结构同时包含一个字典和一个跳跃表
1.5 Redis中的跳跃表
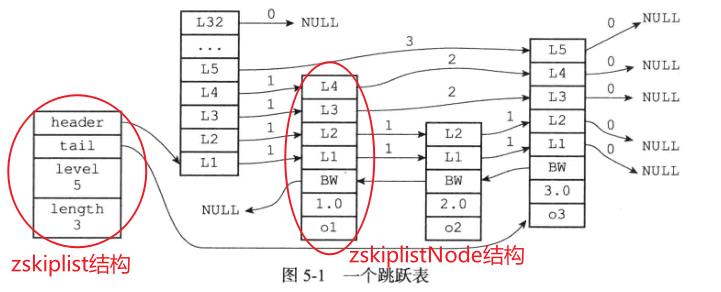
Redis跳跃表实现由 zskiplist 和 zskiplistNode 两个结构组成,其中zskiplist用于保存跳跃表信息(比如表头结点、表尾结点、长度),而zskiplistNode则用于表示跳跃表结点
-
zskiplist结构-
header:指向跳跃表的表头节点
-
tail: 指向跳跃表的表尾节点
-
level: 记录目前跳跃表内,层数最大的那个节点的层数(表头节点不计算在内)
-
length: 记录跳跃表的长度,即跳跃表目前包含节点的数量(表头节点不计算在内)
-
-
zskiplistNode结构-
层(level):节点中用L1、L2、L3等字样标记节点的各个层
-
后退(backward)指针: 节点中用BW字样标记节点的后退指针
-
分值(score): 各个节点中的1.0、2.0和3.0是节点所保存的分值。在跳跃表中,节点按各自所保存的分值从小到大排列
-
成员对象(obj):各个节点中的o1、o2、o3是节点所保存的成员对象
如果分值相同的情况下,节点按照成员对象的从小到大进行排序,大的对象在后面(靠近表尾的方向)。
-
2、布隆过滤器(Bloom Filter)
场景: 经常判断1个元素是否存在,怎么做?
-
使用哈希表(HashMap),将元素作为key去查找
时间复杂度:O(1),但是空间利用率不高,需要占用比较多的内存资源
-
使用布隆过滤器
2.1 什么是布隆过滤器
-
概念
是一个空间效率高的概率型数据结构,可以用来告诉你: 一个元素一定不存在或者可能存在
-
优点
空间效率和查询时间都远远超过一般的算法
-
缺点
有一定的误判率、删除困难
-
本质
实质上是一个很长的二进制向量和一系列随机映射函数(Hash函数)
-
常见应用
网页黑名单系统、垃圾邮件过滤系统、爬虫的网址判重系统、解决缓存穿透问题
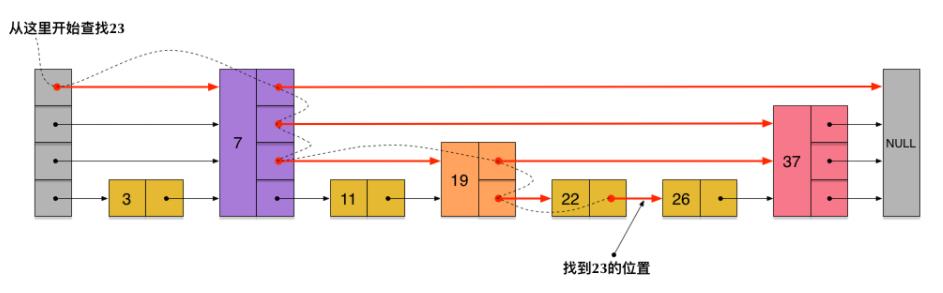
2.2 原理
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FPnLpHbE-1621510762071)(面试-高级数据结构.assets/image-20210520193354932.png)]
-
假设布隆过滤器由20位二进制、3个哈希函数组成,每个元素经过哈希函数处理都能生成一个索引位置
- 添加元素 : 将每一个哈希函数生成的索引位置都设为1
- 查询元素是否存在 (存在的可能存在,不存在的一定不存在)
- 如果有一个哈希函数生成的索引位置值不为1,就代表不存在(100%准确)
- 如果有一个哈希函数生成的索引位置都位1,就代表存在(存在一定的误判率)
-
添加、查询的时间复杂度都是: O(k),k是哈希函数的个数。空间复杂度是: O(m),m是二进制的个数
2.3 场景(Redis缓存穿透)
网页黑名单系统、垃圾邮件过滤系统、爬虫的网址判重系统、解决缓存穿透问题
Redis中的缓存穿透问题的解决方案之一: 布隆过滤器
使用一个足够大的bitmap,用于存储可能访问的key,不存在的key直接被过滤
缓存穿透:访问一个不存在的key,缓存不起作用,请求会穿透到DB,流量大时DB会挂掉。
缓存击穿:一个存在的key,在缓存过期的一刻,同时有大量的请求,这些请求都会击穿到DB,造成瞬时DB请求量大、压力骤增
3、一致性哈希
一致性哈希可以有效解决分布式存储结构下动态增加和删除节点所带来的问题。
3.1 普通哈希
场景描述: 我们有三台缓存服务器,用于缓存图片,我们为这三台缓存服务器编号为0号、1号、2号,现在,有3万张图片需要缓存,我们希望这些图片被均匀的缓存到这3台服务器上,以便它们能够分摊缓存的压力。
使用哈希公式:hash(图片名称)% N
-
新增服务器
假设增加一台缓存服务器,缓存服务器的数量由3台变成了4台,此时,如果仍然使用上述方法对同一张图片进行缓存,那么这张图片所在的服务器编号必定与原来3台服务器时所在的服务器编号不同,因为除数由3变为了4,被除数不变的情况下,余数肯定不同,这种情况带来的结果就是当服务器数量变动时,所有缓存的位置都要发生改变,换句话说,当服务器数量发生改变时,所有缓存在一定时间内是失效的,当应用无法从缓存中获取数据时,则会向后端服务器请求数据
-
删除服务器
假设移除了一台缓存服务器,那么缓存服务器数量从3台变为2台,如果想要访问一张图片,这张图片的缓存位置必定会发生改变,以前缓存的图片也会失去缓存的作用与意义,由于大量缓存在同一时间失效,造成了
缓存的雪崩,此时整个系统很有可能被压垮,所以,为了解决这些问题,一致性哈希算法诞生了。
3.2 一致性哈希算法
3.2.1 基本原理
一致性哈希算法将整个哈希值空间映射成一个虚拟的圆环,整个哈希空间的取值范围为0~2^32-1。整个空间按顺时针方向组织。
一致性哈希算法也是使用取模的方法,只是,刚才描述的取模法是对服务器的数量进行取模,而一致性哈希算法是对2^32取模。
把2^32想象成一个圆
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GRwUlqsZ-1621510762072)(面试-高级数据结构.assets/20210520192653.png)]
假设我们有3台缓存服务器,服务器A、服务器B、服务器C,那么,在生产环境中,这三台服务器有自己的IP地址,我们使用它们各自的IP地址进行哈希计算,使用哈希后的结果对2^32取模。
公式: hash(服务器的IP地址) % 2^32
同样的方法,我们也可以将需要缓存的对象映射到hash环上。
公式: hash(图片名称) % 2^32
从图片的位置开始,沿顺时针方向遇到的第一个服务器就是A服务器,所以,上图中的图片将会被缓存到服务器A上,如下图所示
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CnzRbsVl-1621510762073)(面试-高级数据结构.assets/20210520192651.png)]
依次类推,假设有4张图片
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GocW8j9J-1621510762074)(面试-高级数据结构.assets/20210520192655.png)]
1号、2号图片将会被缓存到服务器A上,3号图片将会被缓存到服务器B上,4号图片将会被缓存到服务器C上。
3.2.2 优点
假设,服务器B出现了故障,我们现在需要将服务器B移除,那么,我们将上图中的服务器B从hash环上移除即可,移除服务器B以后示意图如下。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cJCJid7n-1621510762076)(面试-高级数据结构.assets/20210520192654.png)]
在服务器B未移除时,图片3应该被缓存到服务器B中,可是当服务器B移除以后,按照之前描述的一致性哈希算法的规则,图片3应该被缓存到服务器C中,因为从图片3的位置出发,沿顺时针方向遇到的第一个缓存服务器节点就是服务器C,也就是说,如果服务器B出现故障被移除时,图片3的缓存位置会发生改变。
但是,图片4仍然会被缓存到服务器C中,图片1与图片2仍然会被缓存到服务器A中,这与服务器B移除之前并没有任何区别,这就是一致性哈希算法的优点,如果使用之前的hash算法,服务器数量发生改变时,所有服务器的所有缓存在同一时间失效了,而使用一致性哈希算法时,服务器的数量如果发生改变,并不是所有缓存都会失效,而是只有部分缓存会失效,前端的缓存仍然能分担整个系统的压力,而不至于所有压力都在同一时间集中到后端服务器上。
3.2.3 hash环的偏斜
3.2.3.1 问题所在
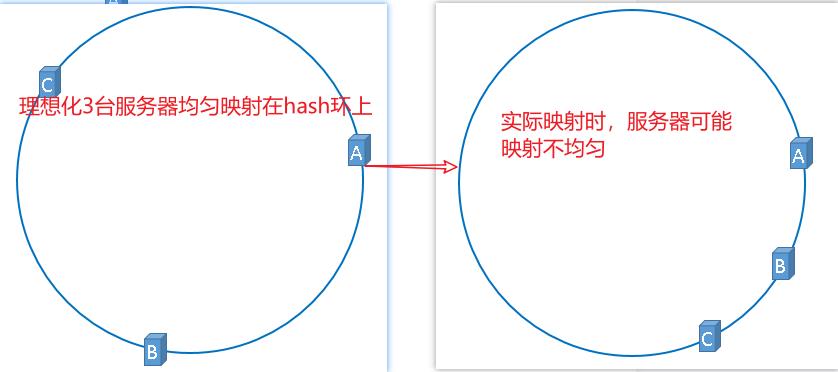
服务器被映射成右图中的模样,那么被缓存的对象很有可能大部分集中缓存在某一台服务器上。
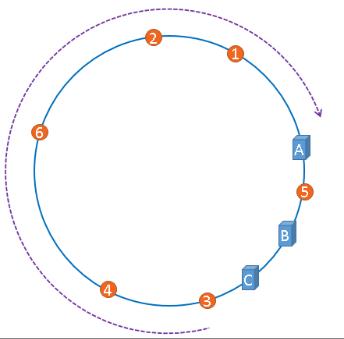
上图中,1号、2号、3号、4号、6号图片均被缓存在了服务器A上,只有5号图片被缓存在了服务器B上,服务器C上甚至没有缓存任何图片,如果出现上图中的情况,A、B、C三台服务器并没有被合理的平均的充分利用,缓存分布的极度不均匀,而且,如果此时服务器A出现故障,那么失效缓存的数量也将达到最大值,在极端情况下,仍然有可能引起系统的崩溃,上图中的情况则被称之为hash环的偏斜,那么,我们应该怎样防止hash环的偏斜呢?一致性hash算法中使用”虚拟节点”解决了这个问题。
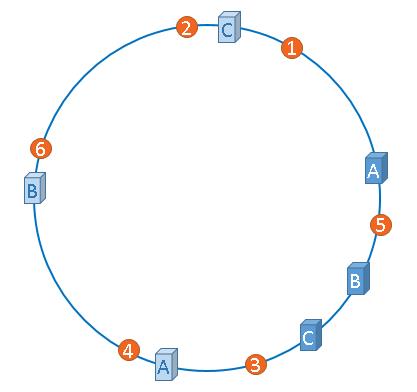
3.2.3.1 虚拟节点
将现有的物理节点通过虚拟的方法复制出来,这些由实际节点虚拟复制而来的节点被称为”虚拟节点”。加入虚拟节点以后的hash环如下,引入虚拟节点的概念后,缓存的分布就均衡多了。
4、雪花算法(Snow Flake)
分布式id生成算法有很多种,Twitter的Snow Flake就是经典的一种
4.1 算法原理
Snow Flake算法生成id的结果是一个64bit大小的整数,结构如下图:
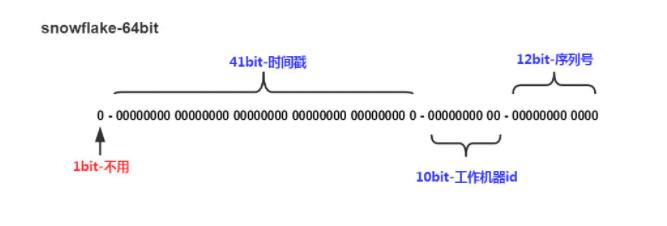
- 1bit:二进制中最高位是符号位,1表示负数,0表示整数。生成id一般都是用整数,所以最高位固定位0
- 41bit-时间戳:用来记录时间戳,毫秒级
- 10bit-工作机器id:用来记录工作机器id
- 12bit-序列号:用来记录同毫秒内产生的不同id
由于在Java中64bit的整数是long类型,所以在Java中SnowFlake算法生成的id就是long来存储的。
以上是关于高级数据结构 ---- 跳跃表布隆过滤器一致性哈希雪花算法的主要内容,如果未能解决你的问题,请参考以下文章