解决Python中下载cifar-10数据集缓慢问题
Posted 明志
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了解决Python中下载cifar-10数据集缓慢问题相关的知识,希望对你有一定的参考价值。
解决Python中下载cifar-10数据集缓慢问题
??最近需要使用cifar-10数据集进行开发,但是使用Python在下载的时候发现速度非常慢。下面介绍一下我的解决方法。
1、下载cifax-10数据集,如果使用Python进行下载的话速度比较慢,这里建议你直接到官网进行下载,官网: 直接点击下载即可。示例:
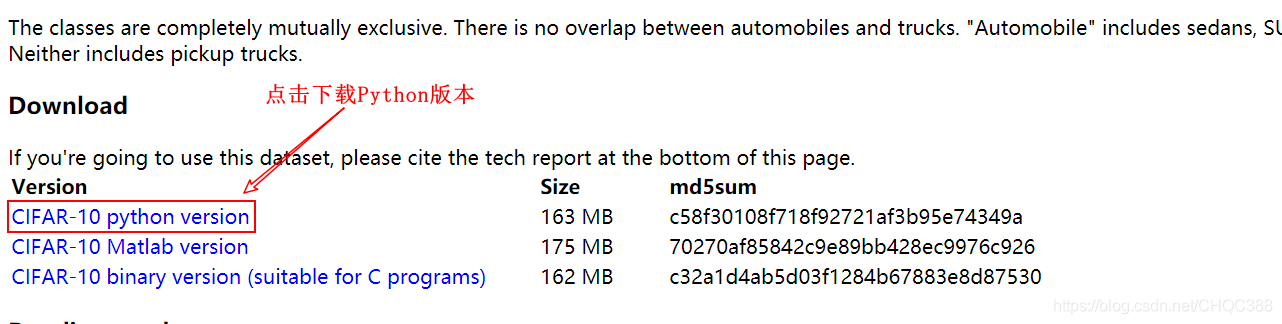
然后选择合适的位置保存即可,示例:
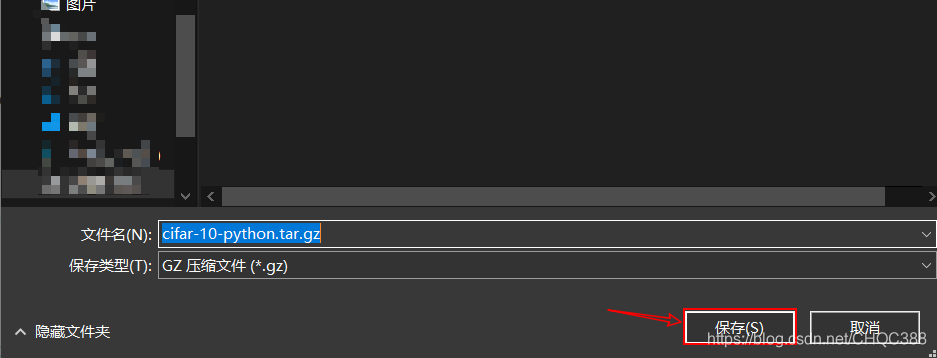
2、对下载好的文件进行解压。示例:
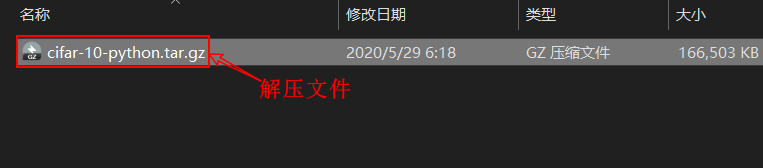
文件的目录如下所示:
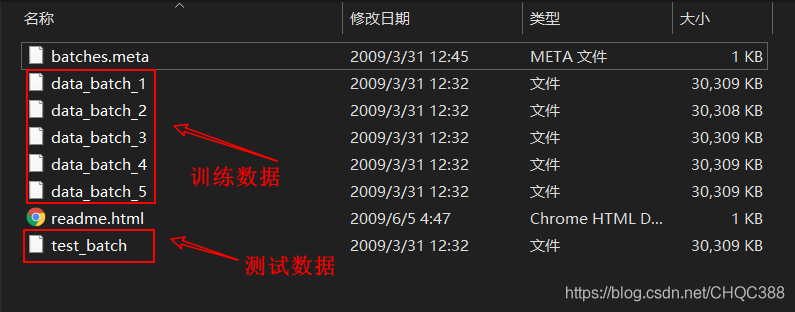
3、使用Python3读取cifar-10中的数据。示例代码:
def load_file(filename):
# filename表示需要读取文件的路径
with open(filename,‘rb‘) as fo:
data = pickle.load(fo,encoding=‘latin1‘) # bytes 官方的例程 latin1 读取数据
return data
提示:上面的方法需要自己编写程序进行读取。需要时刻注意文件的路径。
4、上面的方法需要自己编写程序进行数据的读取,编写过程比较麻烦,而且容易出错。下面介绍使用Keras库中的cifar10.load_data()函数进行数据读取,直接可以读取出训练集和测试集。这里需要你首先安装tensorflow库和Keras库。
(1)将刚才下载的压缩文件直接复制,放到Keras库的数据集文件夹下,一般情况下在"C:Users用户名.kerasdatasets" 下,如果有特殊情况读者可以自行寻找,然后将压缩文件粘贴到datasets文件夹下即可。
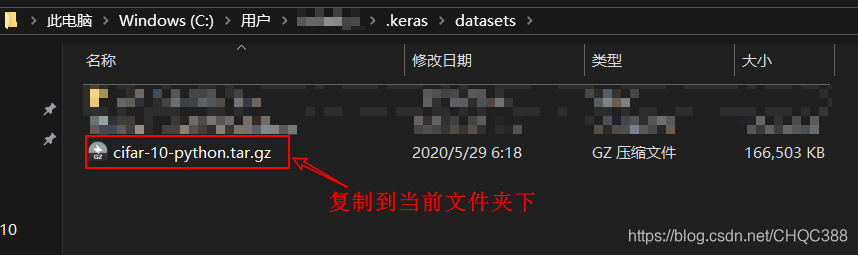
(2)修改文件名。将文件名由:cifar-10-python.tar.gz 改为:cifar-10-batches-py.tar.gz点击保存即可。示例:
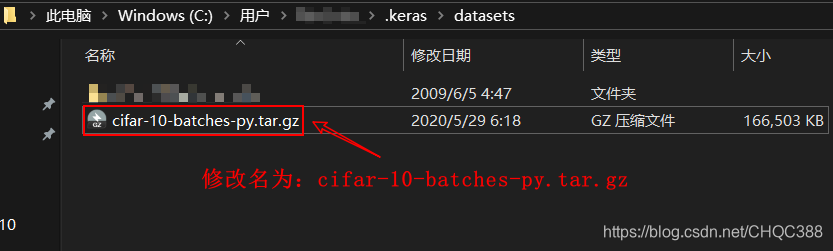
(3)修改好文件名之后,直接退出,使用Python代码直接读取数据。示例:
from keras.datasets import cifar10 # 读取数据集
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
提示:当上面程序运行时,会自动将压缩包进行解压操作,无需自己手动进行解压。
至此,当数据解压完成之后,就可以使用Keras库内置的函数进行读取数据了。
以上是关于解决Python中下载cifar-10数据集缓慢问题的主要内容,如果未能解决你的问题,请参考以下文章