Python读入CIFAR-10数据库
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python读入CIFAR-10数据库相关的知识,希望对你有一定的参考价值。
CIFAR-10可以去http://www.cs.toronto.edu/~kriz/cifar.html下载(记得下载python格式)
CIFAR-10数据组成:
训练集和测试集分别有50000和10000张图片,RGB3通道,尺寸32×32,如下为data_batch_1的组成(使用pickle.load函数):
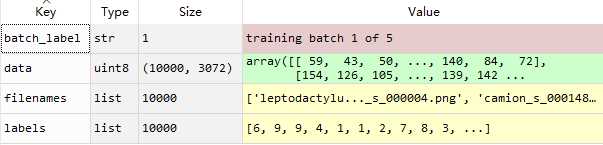
可以看到有四部分,清晰明了
对于CIFAR-10数据的读取,函数有两个,如下所示
1 def load_CIFAR_batch(filename):
2 """ load single batch of cifar """
3 with open(filename, ‘rb‘) as f:
4 datadict = pickle.load(f,encoding=‘latin1‘)
5 X = datadict[‘data‘]
6 Y = datadict[‘labels‘]
7 X = X.reshape(10000, 3, 32,32).transpose(0,2,3,1).astype("float")
8 Y = np.array(Y)
9 return X, Y
——————————————————————————————————————————————
1 def load_CIFAR10(ROOT): 2 """ load all of cifar """ 3 xs = [] 4 ys = [] 5 for b in range(1,6): 6 f = os.path.join(ROOT, ‘data_batch_%d‘ % (b, )) 7 X, Y = load_CIFAR_batch(f) 8 xs.append(X) 9 ys.append(Y) 10 Xtr = np.concatenate(xs)#使变成行向量 11 Ytr = np.concatenate(ys) 12 del X, Y 13 Xte, Yte = load_CIFAR_batch(os.path.join(ROOT, ‘test_batch‘)) 14 return Xtr, Ytr, Xte, Yte
——————————————————————————————————————————————
其中有几个语句要注意一下:
X = X.reshape(10000, 3, 32, 32).transpose(0, 2, 3, 1).astype("float")
起初,X的size为(10000, 3072(3*32*32))。首先reshape很好理解,最后astype的格式转换也很好理解。
可是为什么要调用transpose,转置轴呢?就我认为只需要把一幅图像转成行向量就可以了。是为了方便检索吗?
xs.append(X)将5个batch整合起来;np.concatenate(xs)使得最终Xtr的尺寸为(50000,32,32,3)
当然还需要一步Xtr_rows = Xtr.reshape(Xtr.shape[0], 32 * 32 * 3)使得每一副图像称为一个行向量,最终就有了50000个行向量(Xtr_rows的尺寸为(50000,3072))
——————————————————————————————————————————————
综上,为了方便,难道不应该直接从最开始就不要调用reshape(10000, 3, 32, 32).transpose(0, 2, 3, 1).astype("float"),直接append再concatenate不就能导出Xtr_rows了吗?
知道的博友可以讨论一下!
以上是关于Python读入CIFAR-10数据库的主要内容,如果未能解决你的问题,请参考以下文章
ResNet18迁移学习CIFAR10分类任务(附python代码)