13-爬取百度贴吧中的图片(python+xpath)
Posted ystraw
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了13-爬取百度贴吧中的图片(python+xpath)相关的知识,希望对你有一定的参考价值。
通过xpath分析页面,爬取页面中的图片:
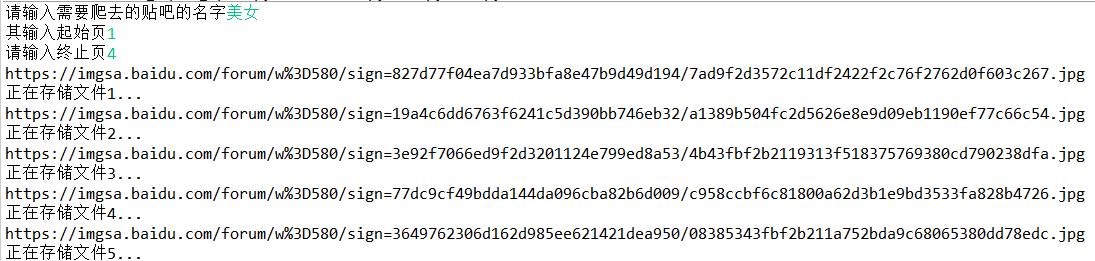
#_*_ coding: utf-8 _*_
\'\'\'
Created on 2018年7月15日
@author: sss
function: 使用xpath还处理爬取的数据
\'\'\'
from lxml import etree
import urllib
from pip._vendor.distlib.compat import raw_input
from asyncio.tasks import sleep
class Spider:
def __init__(self):
self.tiebaName = raw_input(\'请输入需要爬去的贴吧的名字\')
self.beginPage = int(raw_input(\'其输入起始页\'))
self.endPage = int(raw_input(\'请输入终止页\'))
self.url = \'http://tieba.baidu.com/f\'
self.ua_header = {\'User-Agent\': \'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1 Trident/5.0;\'}
#图片编号
self.userName = 1
#计算爬取页
def tiebaSpider(self):
for page in range(self.beginPage, self.endPage + 1):
pn = (page - 1) * 50 #url中的page number
word = {\'pn\': pn, \'kw\': self.tiebaName}
word = urllib.parse.urlencode(word ) #转化为url编码格式
myUrl = self.url + \'?\' + word
#调用页面处理函数load_Page
#并获取页面的所有帖子链接
links = self.loadPage(myUrl)
#开始抓取每个首页所有楼主发帖的标贴连接
def loadPage(self, url ):
req = urllib.request.Request(url, headers=self.ua_header)
html = urllib.request.urlopen(req).read()
#解析html为html文档
selector = etree.HTML(html)
#抓取当前页面的所有帖子的url的后部分,也就是帖子的编号
# http://tieba.baidu.com/p/4884069807里的 “p/4884069807”
links = selector.xpath(\'//div[@class="threadlist_lz clearfix"]/div/a/@href\')
#links类型为etreeElementString列表
#遍历列表,并且合并成一个帖子地址,调用图片处理函数LoadImage
for link in links:
link = \'http://tieba.baidu.com\' + link
self.loadImages(link )
#抓取每个首页中对应的每个楼主的发布详细页面
def loadImages(self, link ):
req = urllib.request.Request(link, headers= self.ua_header)
html = urllib.request.urlopen(req).read()
selector = etree.HTML(html)
#获取这个帖子里的所有图片的src路径
imagesLinks = selector.xpath(\'//img[@class="BDE_Image"]/@src\')
#获取图片路径,下载保存
for imagesLink in imagesLinks:
self.writeImages(imagesLink)
print(\'完成所有下载!\')
#保存页面中的图片
def writeImages(self, imagesLink):
"""
将Images里的二进制内容存入到userNname文件中
"""
print(imagesLink)
#通过图片连接获取图片内容:
images = urllib.request.urlopen(imagesLink).read()
print(\'正在存储文件%d...\' % self.userName)
#写入文件:
with open(\'./images/\' + str(self.userName) + \'.png\', \'wb\') as f: #存入也该项目同级的images文件夹中
f.write(images)
#计数器加一
self.userName += 1
if __name__ == \'__main__\':
mySpider = Spider()
mySpider.tiebaSpider()
以上是关于13-爬取百度贴吧中的图片(python+xpath)的主要内容,如果未能解决你的问题,请参考以下文章