Python爬取百度图片
Posted 、工藤新一
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬取百度图片相关的知识,希望对你有一定的参考价值。
Python爬取百度图片
目录
实例:爬取乔布斯的图片
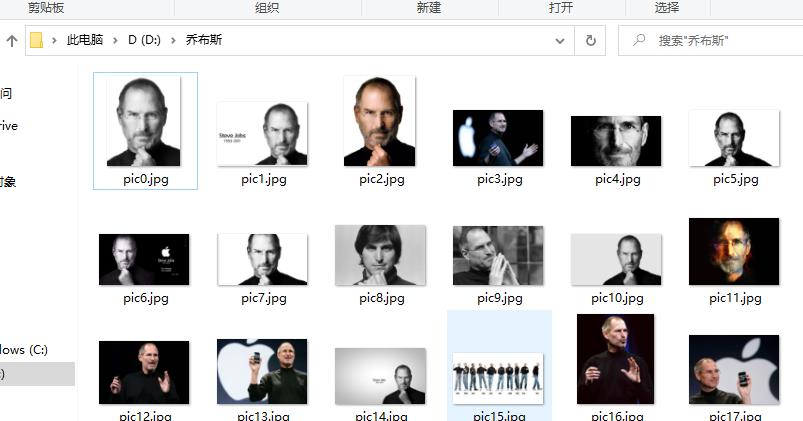
解析
import urllib.request
import urllib.parse
import re
import os
#添加header,referer是必须的User-Agent用来伪装浏览器
header=\\
{
'User-Agert':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/73.0.3683.103 Safari/537.36',
"referer":"http://image.baidu.com"
}
#keword=input(“请输入搜索关键字”)
url="https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=index&fr=&hs=0&xthttps=111111&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&word=%E4%B9%94%E5%B8%83%E6%96%AF&oq=%E4%B9%94%E5%B8%83%E6%96%AF&rsp=-1"##.format(word=keword) [http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word={word}](http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=%7bword%7d)
#转码
\\#keword=urllib.parse.quote(keword,"utf-8")
n=0
j=0
while n<3000:
error=0
n+=30
#获取请求
rep=urllib.request.Request(url,headers=header)
#打开网页
rep=urllib.request.urlopen(rep)
#获取网页内容
try:
html=rep.read().decode("utf-8")
#print(html)
except:
print("出错了")
error=1
#正则匹配
p=re.compile(r"thumbURL.*?\\.jpg")
#获取正则匹配到的结果,返回list
s=p.findall(html)
if os.path.isdir("D://text_pic") !=True:
os.makedirs("D://text_pic")
with open("testpic.txt","a") as f:
#获取图片
for i in s:
i=i.replace('thumbURL":"',"")
print(i)
f.write(i)
f.write("\\n")
#保存图片
urllib.request.urlretrieve(i,"D://text_pic/pic{num}.jpg".format(num=j))
j+=1
f.close()
print("总共爬取的图片数为:"+str(j))
代码
`import urllib.request`
`import urllib.parse`
`import re`
`import os`
\\#添加header,referer是必须的User-Agent用来伪装浏览器
`header=\\`
`{`
`'User-Agert':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36',`
`"referer":"http://image.baidu.com"`
`}`
\\#keword=input("请输入搜索关键字")
`url="https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=index&fr=&hs=0&xthttps=111111&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&word=%E4%B9%94%E5%B8%83%E6%96%AF&oq=%E4%B9%94%E5%B8%83%E6%96%AF&rsp=-1"##.format(word=keword) [http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word={word}](http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=%7bword%7d)`
\\#转码
`\\#keword=urllib.parse.quote(keword,"utf-8")`
`n=0`
`j=0`
`while n<3000:`
`error=0`
`n+=30`
#获取请求
`rep=urllib.request.Request(url,headers=header)`
#打开网页
`rep=urllib.request.urlopen(rep)`
#获取网页内容
`try:`
`html=rep.read().decode("utf-8")`
`#print(html)`
`except:`
`print("出错了")`
`error=1`
#正则匹配
`p=re.compile(r"thumbURL.*?\\.jpg")`
#获取正则匹配到的结果,返回list
`s=p.findall(html)`
`if os.path.isdir("D://text_pic") !=True:`
`os.makedirs("D://text_pic")`
`with open("testpic.txt","a") as f:`
#获取图片
`for i in s:`
`i=i.replace('thumbURL":"',"")`
`print(i)`
`f.write(i)`
`f.write("\\n")`
#保存图片 `urllib.request.urlretrieve(i,"D://text_pic/pic{num}.jpg".format(num=j)`
`j+=1`
`f.close()`
`print("总共爬取的图片数为:"+str(j))`
----------------------------------------------
附:Python制作二维码简易步骤
附:Python爬取整本小说
附:Python爬天气预报
附:Python爬取百度图片
附:python图片转字符画
以上是关于Python爬取百度图片的主要内容,如果未能解决你的问题,请参考以下文章