python爬取百度搜索图片
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬取百度搜索图片相关的知识,希望对你有一定的参考价值。
在之前通过爬取贴吧图片有了一点经验,先根据之前经验再次爬取百度搜索界面图片
废话不说,先上代码
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2017/7/22 10:44 # @Author : wqj # @Contact : [email protected] # @Site : # @File : test.py # @Software: PyCharm Community Edition import requests import re import os url = r‘http://image.baidu.com/search/index?tn=baiduimage&ct=201326592&lm=-1&cl=2&ie=gbk&word=%B1%ED%C7%E9%B0%FC&fr=ala&ala=1&alatpl=adress&pos=0&hs=2&xthttps=000000‘ dirpath = r‘D:\\img‘ html = requests.get(url).text urls = re.findall(r‘"objURL":"(.*?)"‘, html) if not os.path.isdir(dirpath): os.mkdir(dirpath) index = 1 for url in urls: print("Downloading:", url) try: res = requests.get(url) if str(res.status_code)[0] == "4": print("未下载成功:", url) continue except Exception as e: print("未下载成功:", url) filename = os.path.join(dirpath, str(index) + ".jpg") with open(filename, ‘wb‘) as f: f.write(res.content) index += 1print("下载结束,一共 %s 张图片" % index)
在爬取得过程中,最先遇到的问题是打开百度图片界面,查看源码,并不能看到img下的src标签,后通过在知乎上查看文章得知百度将图片放在了acjson下,通过XHR来查看
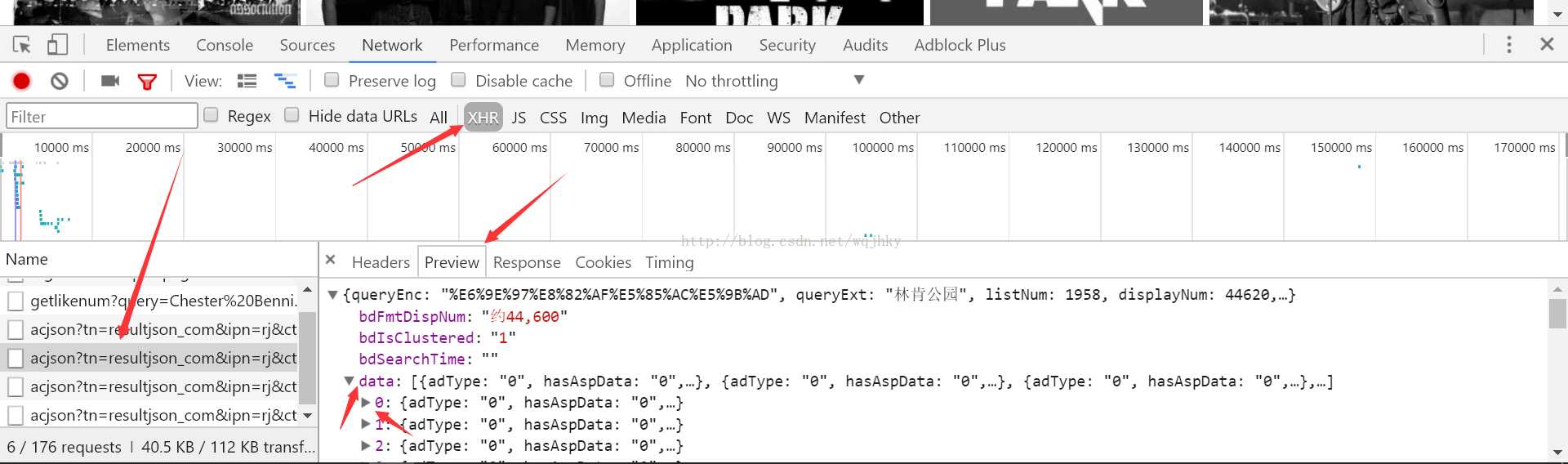
进入之后发现其中有较多图片地址,经过验证后发现objURL才是我们需要的标签
这样我们就可以利用python中的requests库来对页面进行解析匹配
其中
try: res = requests.get(url) if str(res.status_code)[0] == "4": print("未下载成功:", url) continue except Exception as e: print("未下载成功:", url)
需要我们来判断状态码是否正常,如异常需要捕捉。
基本上这个python程序就算结束了。
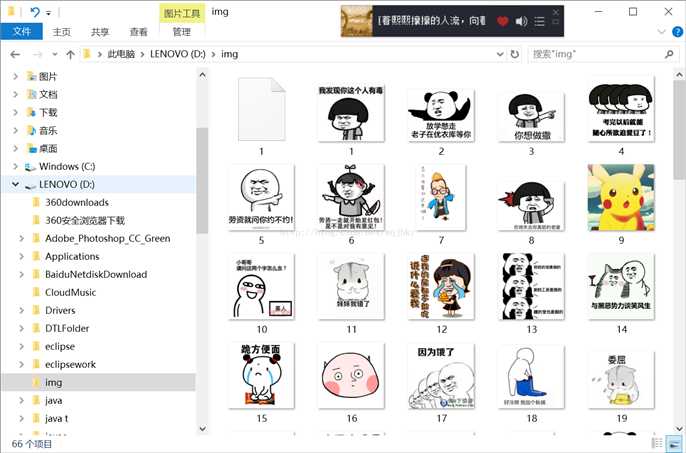
不足的地方有很多,譬如只可以抓取首页的30张图片
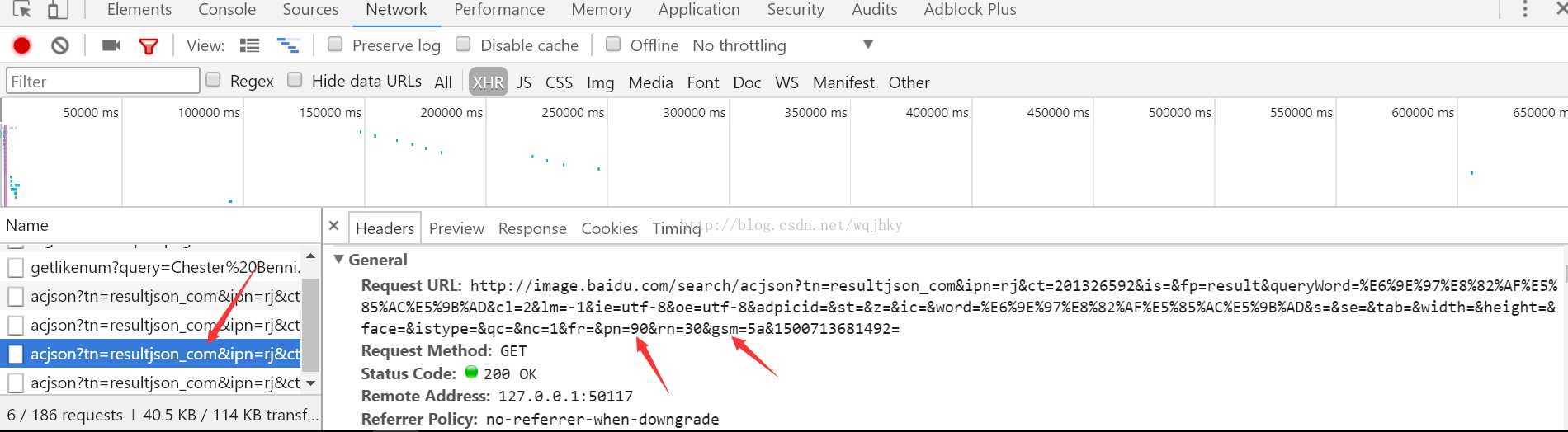
这是相邻的两个请求,每相邻像个请求之间有30张图片,经过分析我们可以看出来其中只有两个参数发生变化,一个是pn,另一个是
gsm。pn是以30递增的规律,而gsm则无法判断。(刚入python的坑)
所以无法连续抓取。。。
以上是关于python爬取百度搜索图片的主要内容,如果未能解决你的问题,请参考以下文章
Python爬虫:运用多线程IP代理模块爬取百度图片上小姐姐的图片