Python爬虫:运用多线程IP代理模块爬取百度图片上小姐姐的图片
Posted il_持之以恒_li
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫:运用多线程IP代理模块爬取百度图片上小姐姐的图片相关的知识,希望对你有一定的参考价值。
Python爬虫:运用多线程、IP代理模块爬取百度图片上小姐姐的图片
1.爬取输入类型的图片数量(用于给用户提示)
使用过百度图片的读者会发现,在搜索栏上输入关键词之后,会显示出搜索的结果,小编想大多数读者应该关注的是搜索内容(这里指的是图片),也许没有注意这些搜索图片的数量吧!
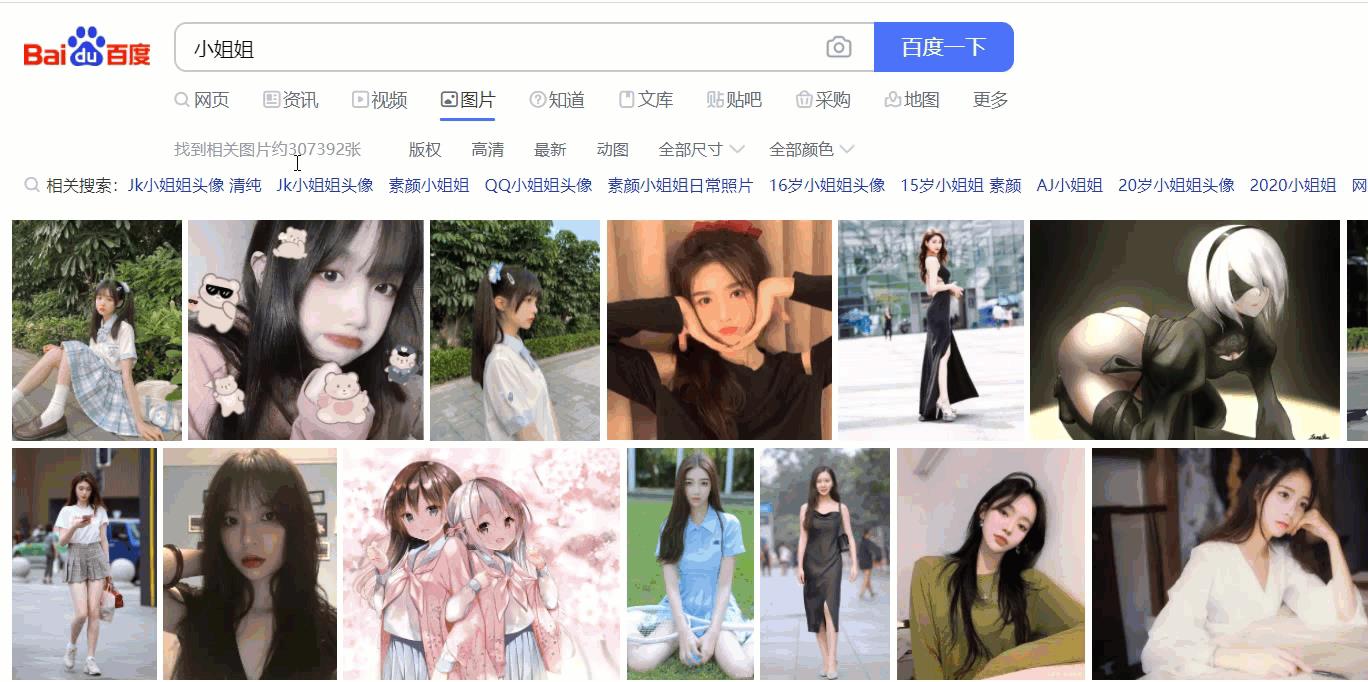
虽然搜索图片是动态加载的,但是搜索图片的数量是静态的,读者来到开发者工具就知道了。

细心的读者会发现两边的搜索图片数量不相同,不过,这个对于我们最终结果没有任何影响,这个数据的差异最多也就1000,这个1000对于搜索图片总数量根本不值一提,另外,最后这1000张的图片质量也不会咋地(与关键词内容无关)。
对于这个网址进行分析:
https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=%d_R&pv=&ic=0&nc=1&z=&hd=&latest=©right=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&sid=&word=%s
其中%d是一个时间戳,只不过用python实现为:
import time
int(time.time()*1000)
%s就是搜索关键词了,这里需要编码一下,如下:
from urllib.parse import quote
keyword=input('输入图片类型:')
# 对输入的keyword进行编码
encodeKeyword=quote(keyword)
小编使用xpath和re模块,用来得到搜索图片数量

小编在这里提示一下,就是请求除了添加user-agent值之外,还需添加Accept,否则请求不到所需要的数据。
2.得到图片的下载链接
由于这个网址是一个动态网址,所以直接解析原网址肯定得不到图片下载链接的哈!

点击浏览器的开发者这个工具,来到Network->XHR,细心的读者可以发现 无论怎样刷新网址,XHR下面总是只有两个网址数据,这两个网址下面没有我们需要的。但是如果将左方图片下滑,就会出现一系列网址数据了,我们需要的图片下载链接就在这些网址下面。
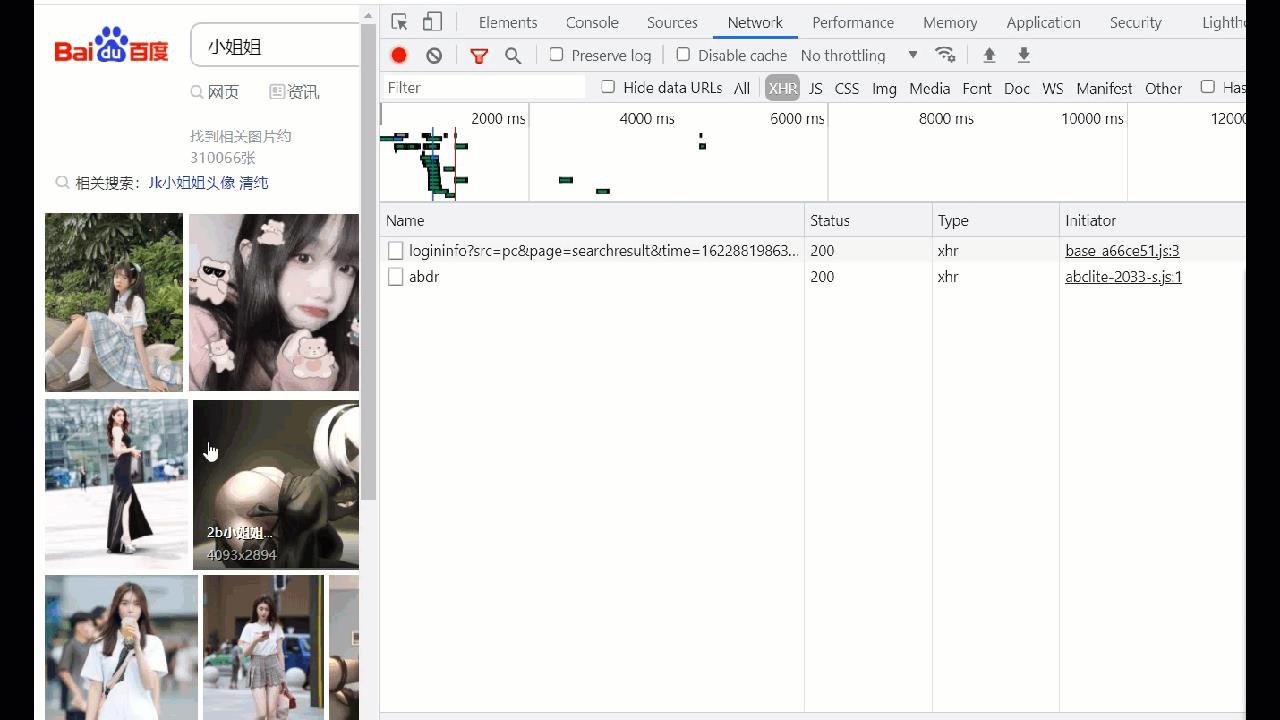
具体网址为:
https://image.baidu.com/search/acjson?tn=resultjson_com&logid=9748117420796842251&ipn=rj&ct=201326592&is=&fp=result&queryWord={0}&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=&hd=&latest=©right=&word={0}&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&nojc=&pn={1}&rn=30&gsm=1e&{2}=
其中{0}和{2}和上述讲的一样,分别是搜索词编码和时间戳,{1}小编猜测应该是页数,只不过这个页数是30的倍数,后面rn是每页的数量。pn从0开始,读者下滑得到的第一个网址的这个参数应该会是30,但是把30改成0依旧能访问,并且此时的网址里面的数据是我们开始搜索得到的结果,也许这个网址直接被隐藏,防止被爬取吧!

下面还有一个参数为:thumbURL,就是图片下载链接了。

3.最终实战:使用多线程、IP代理模块爬取小姐姐的图片
Python默认是没有IP代理模块的,小编这里讲IP代理模块是自定义的,自己写的一个模块,感兴趣的读者可以看看小编的博客,博客链接:Python爬虫:制作一个属于自己的IP代理模块2、Python爬虫:制作一个属于自己的IP代理模块
具体参考代码如下:
import requests
import json
from crawlers.userAgent import useragent # 从自定义模块中导入随机获取user-agent值的模块
from urllib.parse import quote
from lxml import etree
from crawlers.ip2 import IPs # 从自定义模块中导入IP代理模块
import re
import sys
import time
import threading # 导入线程模块
import os
# 初始化两个自定义模块
userAgent=useragent()
keyword=input('输入图片类型:')
# 对输入的keyword进行编码
encodeKeyword=quote(keyword)
# 时间
time1=int(time.time()*1000)
# url1用来得到图片总数
url1='https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=%d_R&pv=&ic=0&nc=1&z=&hd=&latest=©right=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&sid=&word=%s'%(time1,encodeKeyword)
# https://image.baidu.com/search/index?ct=201326592&z=3&tn=baiduimage&ipn=r&word=%E9%A3%8E%E6%99%AF&pn=0&istype=2&ie=utf-8&oe=utf-8&cl=2&lm=-1&st=-1&fr=&fmq=1622874884985_R&ic=0&se=&sme=&width=0&height=0&face=0
# print(url1)
headers={'User-Agent':userAgent.getUserAgent(),
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
}
try:
rsp=requests.get(url=url1,headers=headers)
html=etree.HTML(rsp.text)
nums=html.xpath("//div[@id='resultInfo']/text()")[0] # 图片总数
nums=re.findall('找到相关图片约(.*)张',nums)[0]
except Exception as e:
print(e)
sys.exit()
print('------该类图片页数为->%d'%(int(nums.replace(',',''))//30))
pn=int(input('用户输入下载页数:'))
names=[]
urls=[]
for i in range(pn):
time2=int(time.time()*1000)
url2='https://image.baidu.com/search/acjson?tn=resultjson_com&logid=9748117420796842251&ipn=rj&ct=201326592&is=&fp=result&queryWord={0}&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=&hd=&latest=©right=&word={0}&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&nojc=&pn={1}&rn=30&gsm=1e&{2}='.format(encodeKeyword,i*30,time2)
# https://image.baidu.com/search/acjson?tn=resultjson_com&logid=9668459090674682963&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E9%A3%8E%E6%99%AF&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=3&ic=0&hd=&latest=©right=&word=%E9%A3%8E%E6%99%AF&s=&se=&tab=&width=0&height=0&face=0&istype=2&qc=&nc=&fr=&expermode=&nojc=&pn=30&rn=30&gsm=1e&1622876252843=
# print(url2)
response=requests.get(url=url2,headers=headers)
imgList=json.loads(response.text)['data']
for i in range(len(imgList)-1):
try:
imgUrl=imgList[i]['replaceUrl'][0]['ObjURL']
except:
imgUrl=imgList[i]['thumbURL']
imgName=imgList[i]['fromPageTitleEnc']
names.append(imgName)
urls.append(imgUrl)
time.sleep(0.1)
nameList=['/','\\\\',':','*','"', '<', '>','|' ,'.','?'] # 对爬取的图片名称进行处理,使图片文件命名规范
for i in range(len(names)):
for name in nameList:
names[i]=names[i].replace(name,'')
urlAndName=[[urls[i],names[i]] for i in range(len(urls))]
for list_1 in urlAndName:
print(list_1)
print(len(urlAndName))
ips=IPs()
proxies=ips.getUserIps()
# 得到ip代理
proxy=proxies.pop()
savePath='./%s'%(keyword)
try:
os.mkdir(savePath)
except:
pass
def download(urlAndName):
global proxy
while True:
if len(proxies)==0:
print('ip代理已经使用完毕!')
break
if len(urlAndName) == 0:
break
headers={'user-agent':userAgent.getUserAgent()}
try:
img=urlAndName.pop()
rsp=requests.get(url=img[0],headers=headers,proxies=proxy)
if rsp.status_code==200:
with open(file='{}/{}.jpg'.format(savePath,img[1]),mode='wb') as f:
f.write(rsp.content)
print('==>ip数量:{}====>网址数量:{}'.format(len(proxies),len(urlAndName)))
except Exception as e:
print(e)
print('-------->', len(urlAndName))
proxy = proxies.pop()
threads=[]
for i in range(10):
thread=threading.Thread(target=download,args=(urlAndName,))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
上述代码中导入两个自定义模块不懂的读者可以看看小编提到的两篇博客喔!




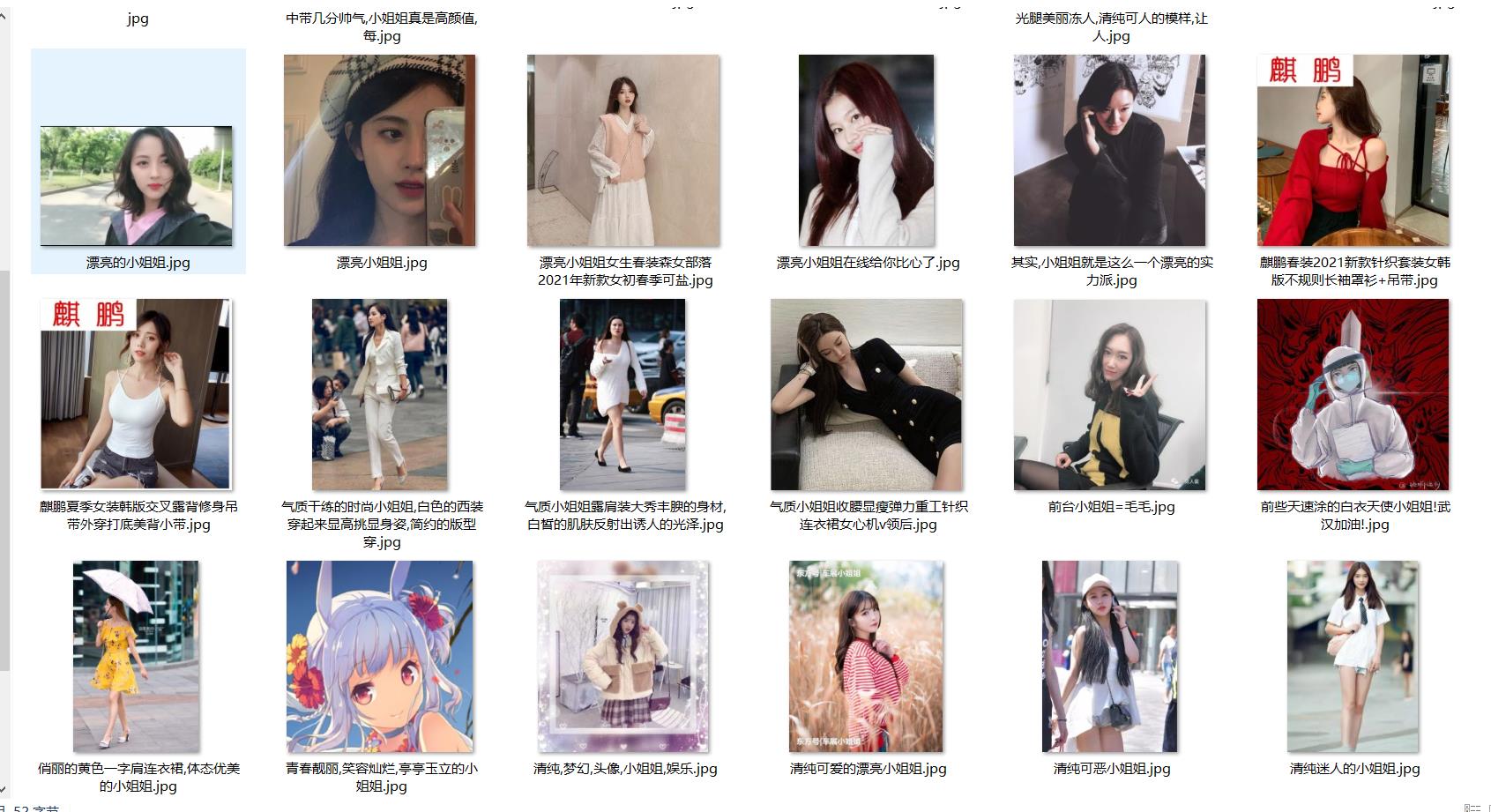
4.总结
小编的参考代码中使用多线程还有一定问题,读者从运行结果就可以看出,另外,还有一个问题就是快运行结束的时候,会出现多个线程运行一个网址,虽然这对最终结果没有什么影响,但这是一个问题。因为这个百度图片网站虽然搜索小姐姐这个关键词,但是还是出现了许多其他乱七八糟的图片 ,希望读者自己运行的时候理解。小编正在参加新星计划,读者觉得小编的这篇文章还可以的话,记得点赞,当然,对于程序代码有什么问题和建议,欢迎在评论区评论!
以上是关于Python爬虫:运用多线程IP代理模块爬取百度图片上小姐姐的图片的主要内容,如果未能解决你的问题,请参考以下文章