Python爬虫:制作一个属于自己的IP代理模块2
Posted il_持之以恒_li
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫:制作一个属于自己的IP代理模块2相关的知识,希望对你有一定的参考价值。
Python爬虫:制作一个属于自己的IP代理模块2
小编前些日子写了一篇关于IP代理模块的博客(Python爬虫:制作一个属于自己的IP代理模块
),但是那个还需要改进,今天小编改进了一下那个模块,爬取多个网址的ip数据,然后去重,最后判断爬取的ip是否可用。让我们来看看前面的那个模块和改进的模块它们两者之间的区别吧!

1.爬取3个免费提供ip代理的网址
这三个ip代理网址分别为:快代理、泥马ip代理、89免费代理
1.1 爬取快代理网址的IP数据
首先,让我们来爬取快快代理的IP数据吧!
快代理的网址样式为:https://www.kuaidaili.com/free/inha/{页码}/
花括号代表页码,这个网址的页码很多,有4000多页。
让我们来看看怎样得到这个网站的ip数据吧!这里使用xpath语法
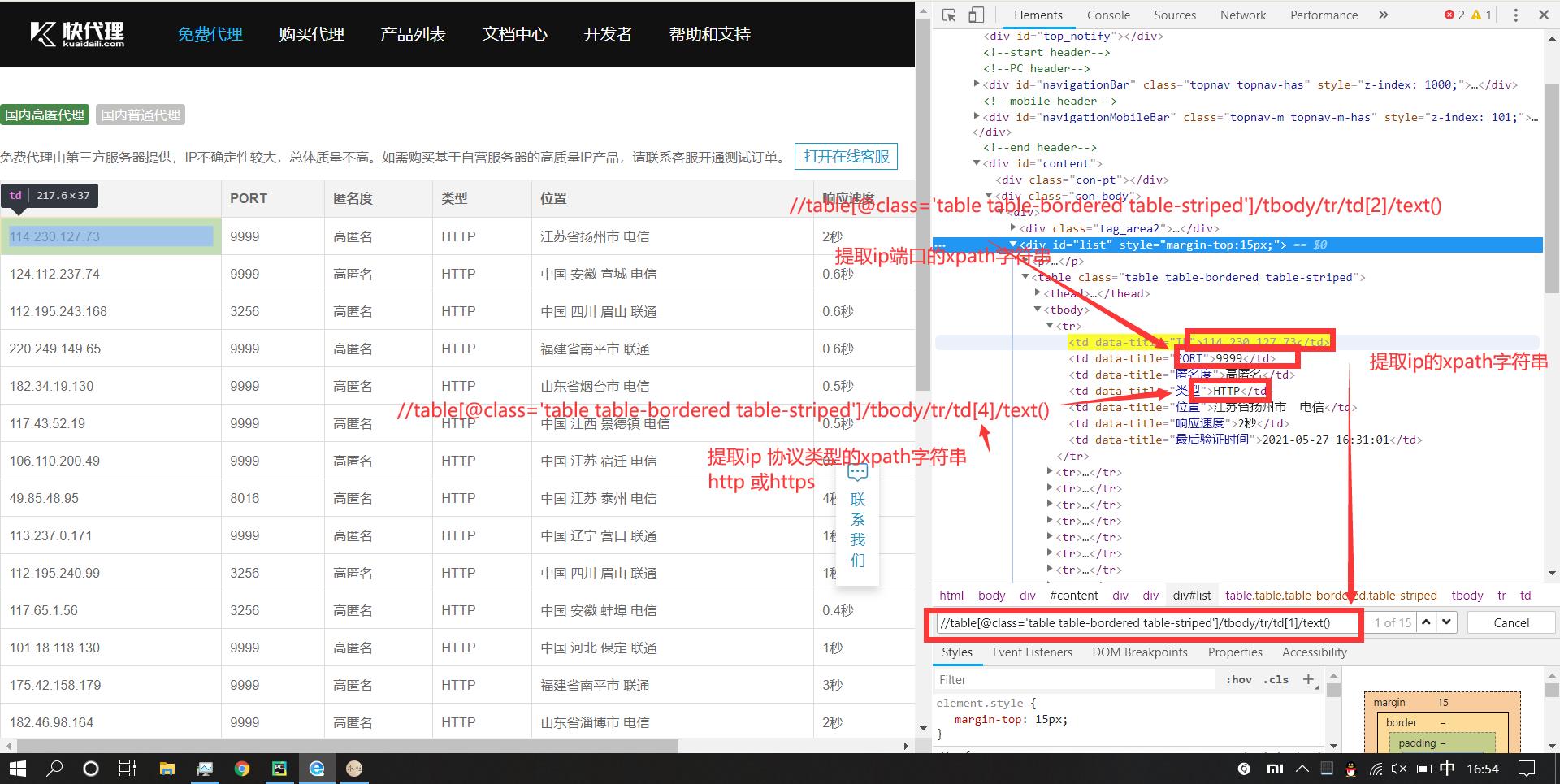
因为这个协议类型是大写字母,小编页不知道这个会不会对最终结果造成影响,于是干脆把它转成小写字母了。
代码为:

应为爬取的是多页ip数据,使用小编在爬取1页之后那里休眠了2秒。
1.2 爬取泥马ip代理网址的IP数据
这个网址的样式和快代理一样:http://www.nimadaili.com/gaoni/{页码}/
花括号里面的内容是页码,虽然这个网址下面标的是有2000页

但是真正有ip数据的页数只有300多页。
现在让我们来看看怎样得到这个网址的ip数据吧!
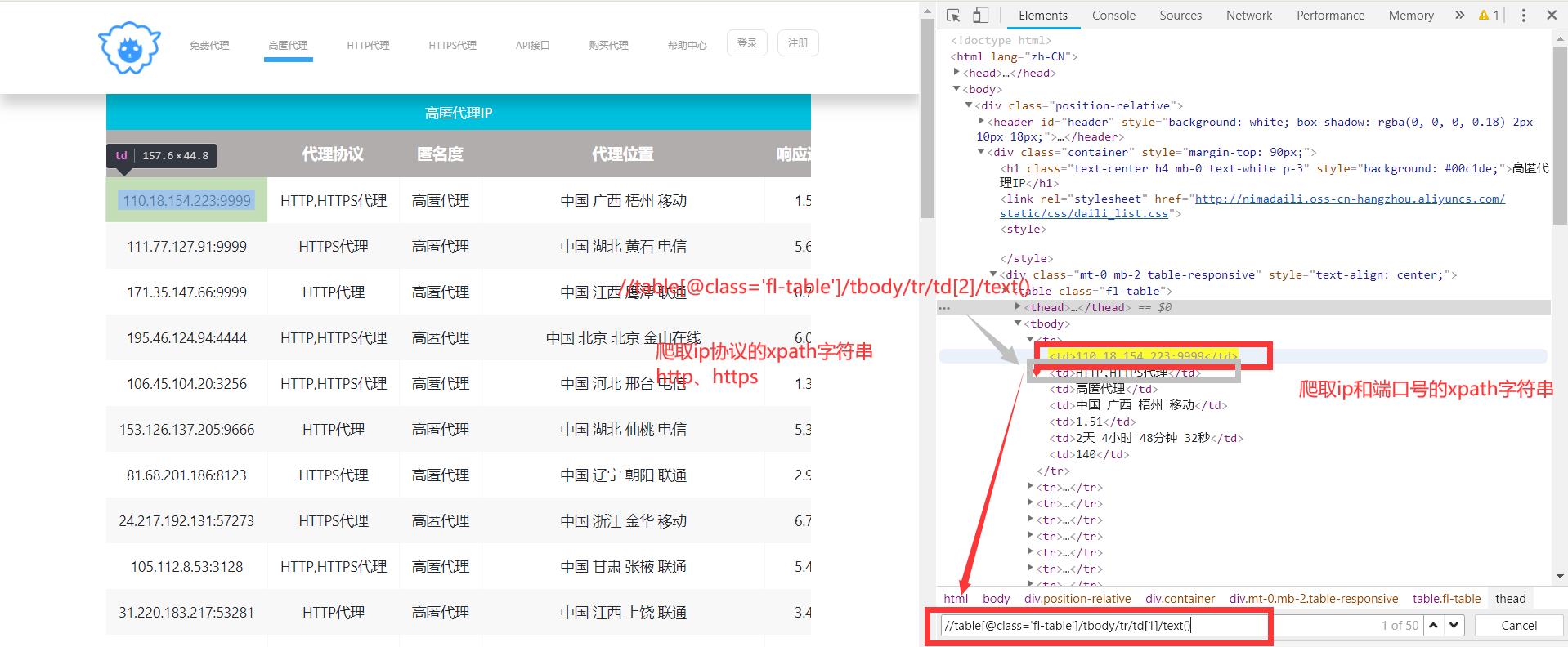
有的ip只有一个协议可以使用(大多数ip都是这种情况),有的ip两个协议都可以使用,这里为了简单,小编直接选取1个ip协议(两个协议都可用的,选第1个)。同样这里也要转换字符串大小写情况。

1.2 爬取89免费代理网址的IP数据

这个网址样式为:https://www.89ip.cn/index_{页码}.html
花括号代表页码,总共有效的页数为100多页,具体爬取这个ip数据参考如下:
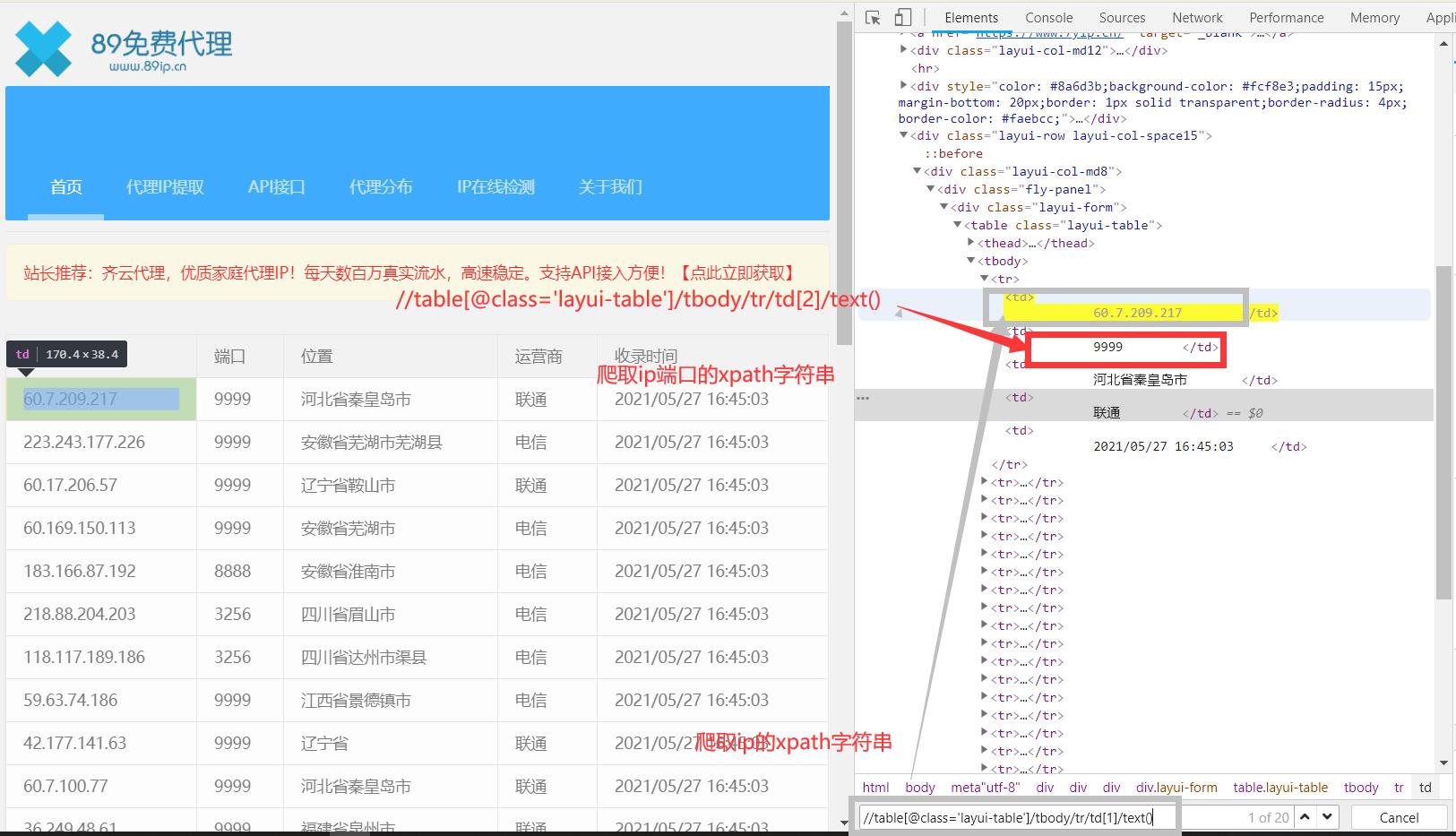
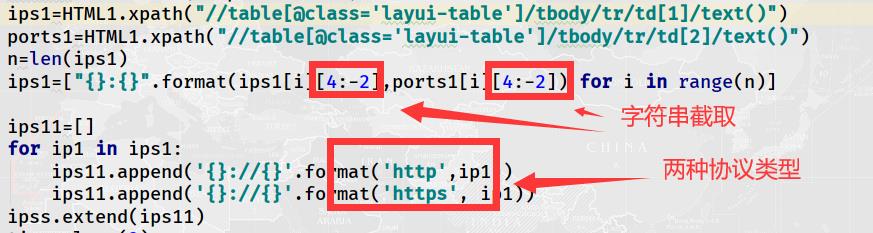
因为网址没有提到ip协议类型,这里直接将两种(http,https)都拼接,爬取的信息前面和后面有换行和空格,所以在最终拼接时,还要进行字符串的截取,
2.验证爬取的ip是否可用
这里依旧使用百度这个网址用来检验爬取的ip是否可用,为了提高检验效率,使用多线程。
参考代码如下:
def checkIps(self,ips):
while True:
if len(ips)==0:
break
proxies=ips.pop()
headers = {'user-agent': self.userAgent.getUserAgent()}
try:
rsp=requests.get(url=self.url,headers=headers,proxies=proxies,timeout=0.5) # 设置超时时间
if(rsp.status_code==200):
self.userfulProxies.append(proxies)
print('========IP{}可用'.format(proxies)) # 测试需要的话可以不注释掉
time.sleep(1) # 休眠1秒钟
except Exception as e:
print(e)
print('========IP{}不可用'.format(proxies)) # 用于测试,可用注销掉的
def getUserIps(self): # 得到可用的ip数据
self.spiderIps()
ips=self.proxies[:]
# 爬取的ip总数上百,使用10个线程
threads=[]
for i in range(10):
thread=threading.Thread(target=self.checkIps,args=(ips,))
thread.start()
threads.append(thread)
for th in threads:
th.join()
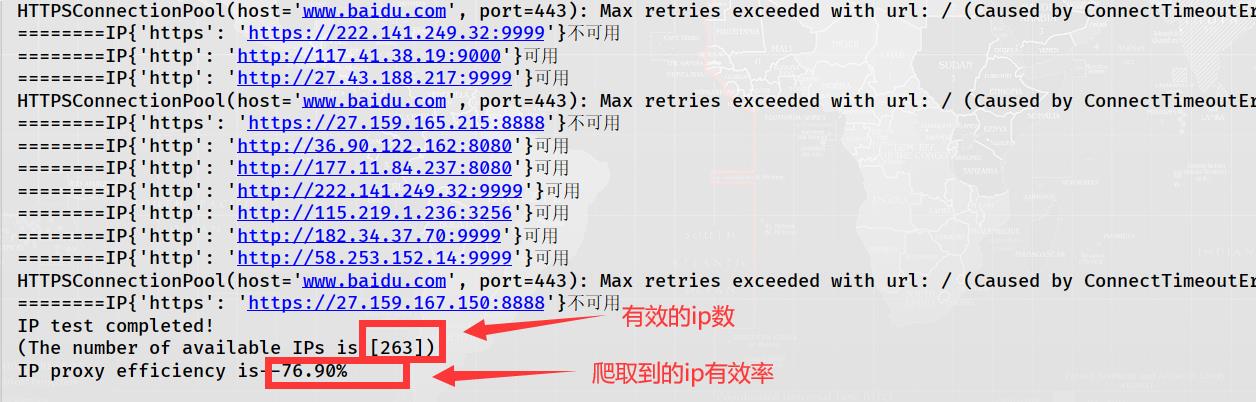
print('IP test completed!') # ip测试完毕!
print('(The number of available IPs is:[%d])' % len(self.userfulProxies)) # 总共有效的ip数目为
print('IP proxy efficiency is--{:.2f}%'.format((len(self.userfulProxies)/len(self.proxies))*100)) # 爬取的ip有效率
return self.userfulProxies # 把可用的ip数据返回
运行结果:
3.最终实战:利用ip代理爬取集图网上500页小姐姐的图片
上一次使用开始的那个ip代理模块,爬取这个网址直接全部不能使用,现在小编想肯定可用。毕竟

而

开始爬取(这里只演算这个ip代理模块的可用性,只爬取图片链接,并不下载图片,不过,如果要下载图片,不也是1行代码的事吗?哈哈)
参考代码如下:
import requests
from crawlers.userAgent import useragent # 导入自己自定义的类,主要作用为随机取user-agent的值
from lxml import etree
from Craw_2.Test.wenti1 import IPs # 导入ip代理模块
ip=IPs()
proxiess=ip.getUserIps()
userAgent=useragent()
url='http://www.jituwang.com/sucai/meinv-7559813-%d.html'
i=1
proxies=proxiess.pop()
print('开始爬取')
while i<501:
try:
headers = {'user-agent': userAgent.getUserAgent()}
rsp=requests.get(url=url%(i),headers=headers,proxies=proxies,timeout=1)
if rsp.status_code==200:
print(proxies,i)
html=etree.HTML(rsp.text)
hrefs=html.xpath("//div[@class='boxMain']//li/a//img/@src")
print(hrefs)
i+=1
except Exception as e:
if len(proxiess)==0:
break
proxies = proxiess.pop()
print(e)
运行结果:
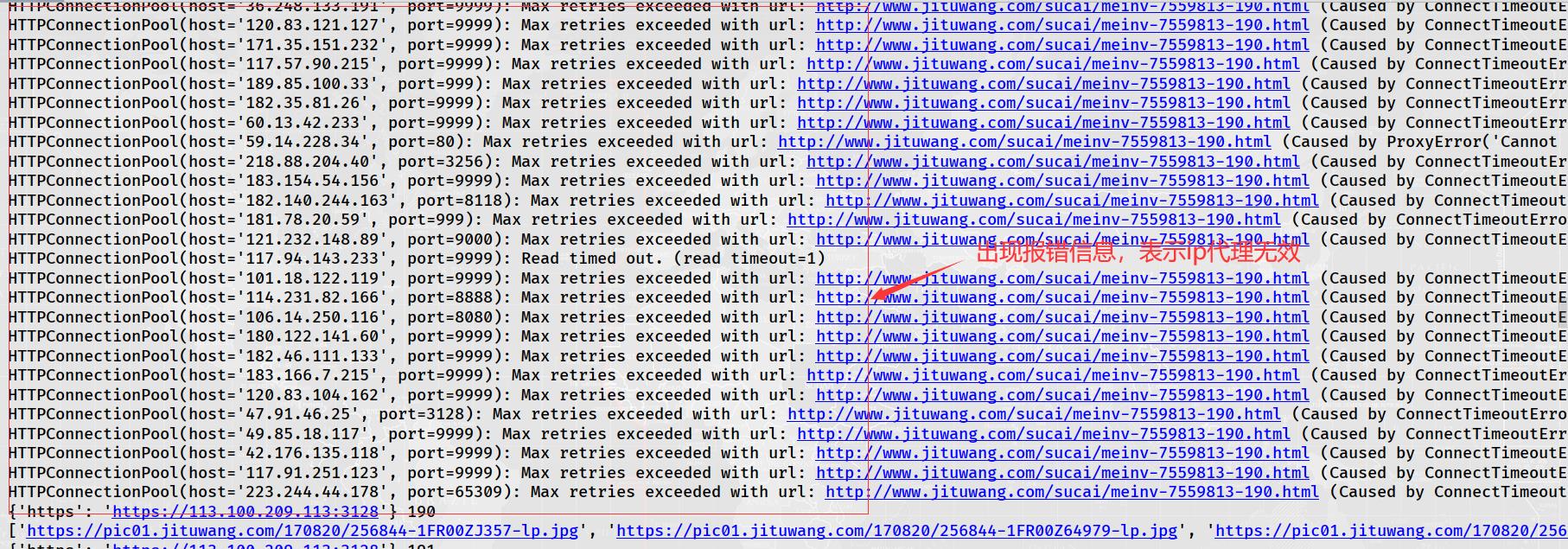
因为免费的ip具有时效性,所以爬取的ip到使用时并不一定可用。
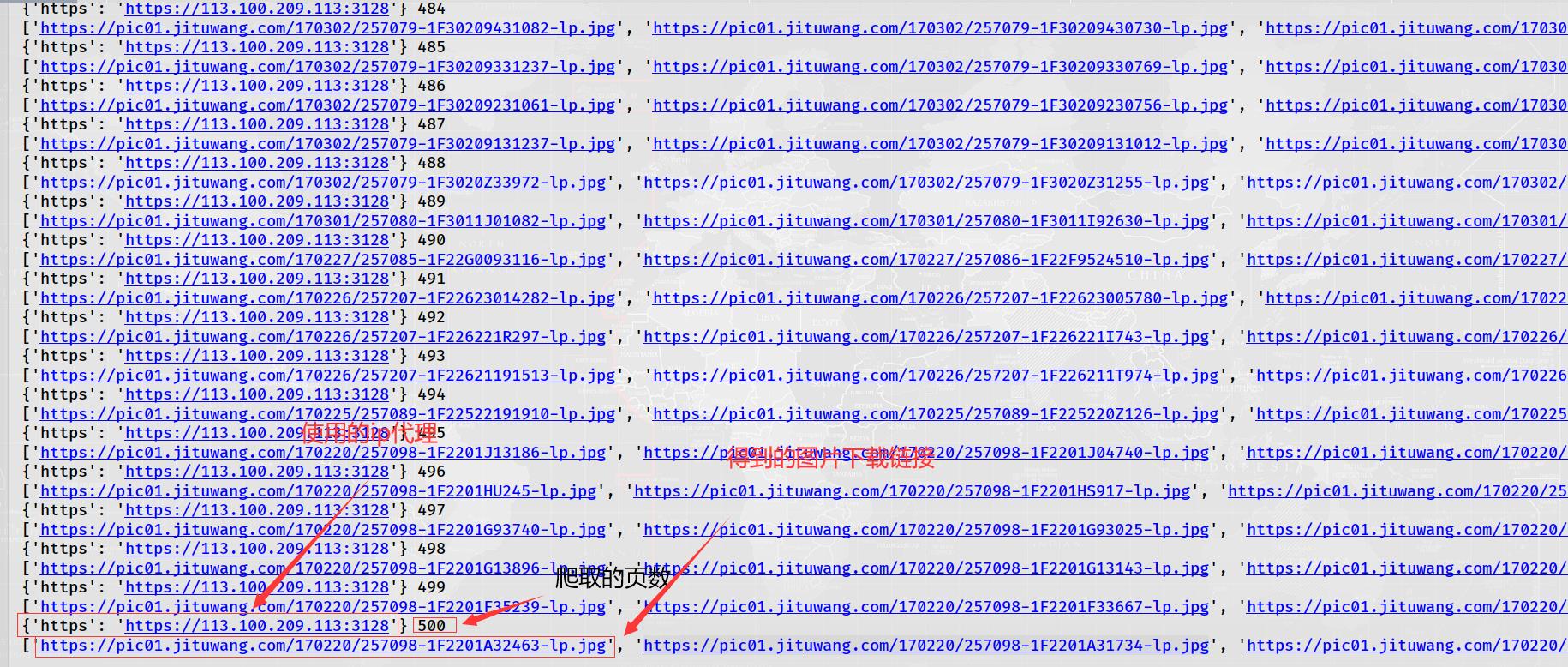
我们点击其中的一张图片链接进入:
链接为:https://pic01.jituwang.com/201028/144489-20102Q35I377-lp.jpg
发现图片的尺寸太小了,我们点击原网址上的这张图片,在那上面找到这张图片的链接点击进入,发现图片尺寸变大了,
网址链接为:https://img01.jituwang.com/201028/144489-20102Q35I377.jpg

将上述的那两个链接进行比较,发现除了链接头部和尾部有一点不同之外,其他部分都相同,我们可使用字符串的拼接和字符串的截取就可以得到尺寸大的图片了。
小编这里没有使用多线程,因此爬取这些图片的下载连接速度很慢,有兴趣的读者可以尝试使用多线程再加这个ip代理爬取链接喔!这样速度肯定会块很多。
从上述使用ip代理可以知道,如果不使用ip代理,或许没有爬到500页的时候,自己的IP就已经被封掉了,因此,可以看到使用ip代理的重要性。
ip代理模块的源码小编已经上传到gitee上,链接为:ips2.py,想要源码的读者可以自行下载!
4.总结
小编的这个ip代理模块相比之前的那个已经得到很大的提升,要说改进的话,就是再多增加几个ip代理网址,提高爬取的ip质量。小编正在参加新星计划,读者觉得小编的这篇文章还可以的话,记得点赞!
以上是关于Python爬虫:制作一个属于自己的IP代理模块2的主要内容,如果未能解决你的问题,请参考以下文章
Python3爬虫Scrapy使用IP代理池和随机User-Agent