Python爬虫:制作一个属于自己的IP代理模块
Posted il_持之以恒_li
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫:制作一个属于自己的IP代理模块相关的知识,希望对你有一定的参考价值。
Python爬虫:制作一个属于自己的IP代理模块
Python爬虫常常会面临自己ip地址被封的情况,也许不懂的读者就只能等ip解封之后再进行接下来的操作了,为什么自己不做一个Python模块专门用于处理这种情况呢?小编首先讲的不会是重点,但是到对于读者开发Python爬虫肯定有一定的帮助,希望读者耐心看下去!

1.使用PyChram的正则
首先,小编讲的不是爬取ip,而是讲了解PyCharm的正则,这里讲的正则不是Python的re模块哈!
而是PyCharm的正则功能,我们在PyChram的界面上按上Ctrl+R,可以发现,这里出现两行输入框,
现在如果小编想把如下数据转换成一个字典存储
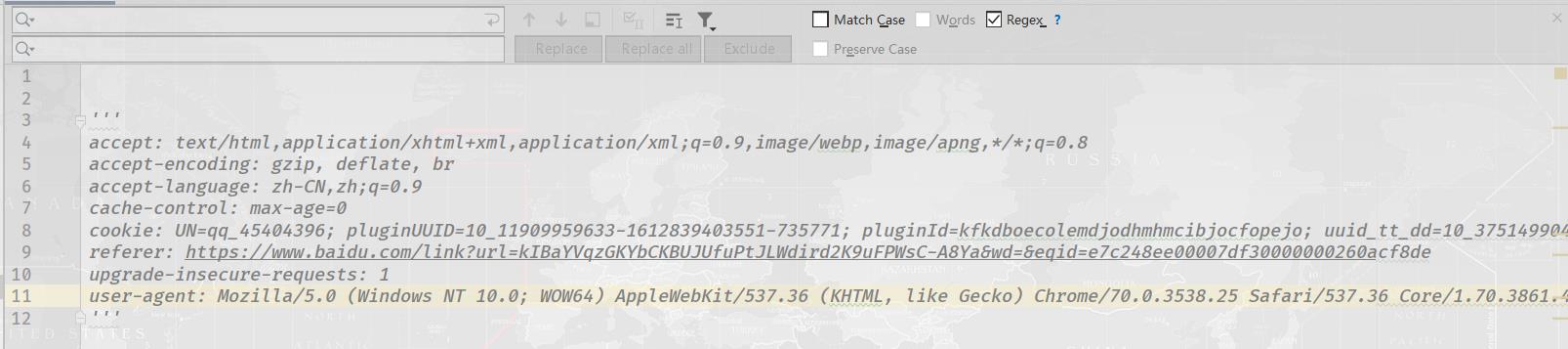
读者也许会一个一去改,但是小编只需在上述的那两个输入框内,输入一串字符串即可。

只需在第一个输入框中,输入(.*) : (.*)
在第二个输入框中,输入"$1":"$2",,看看效果如何
之后再给两端分别一个花括号和取一个字典名称即可。
2.制作一个随机User-Agent模块
反爬措施中,有这样一条,就是服务器会检查请求的user-agent参数值,如果检查的结果为python,那么服务器就知道这是爬虫,为了避免被服务器发现这是爬虫,通常user-agent参数值会设置浏览器的值,但是爬取一个网址时,每次都需要查看网址network下面的内容,显得比较繁琐,为什么不自定义一个随机获取user-agent的值模块呢?这样既可以减少查看network带来的繁琐,同时还可以避免服务器发现这是同一个user-agent发起多次请求。
说了这么多,那么具体怎样实现呢?

只需调用随机模块random的方法choice()即可,这个方法里面的参数类型时列表类型,具体参考代码如下:
import random
class useragent(object):
def getUserAgent(self):
useragents=[
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/90.0.4430.212 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 2.0.50727; SLCC2; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; Tablet PC 2.0; .NET4.0E)',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)',
]
return random.choice(useragents)
这样我们就可以随机得到一个user-agent的值了。
3.最终实践:制作属于自己的ip代理模块
3.1 爬取快代理上的ip
接下来,就是最终实践了,制作属于自己的IP代理模块。
那么,从哪里获取IP呢?小编用的是快代理这个网址,网址链接为:https://www.kuaidaili.com/free/inha/1/。
怎样提取IP呢?小编用的是xpath语法
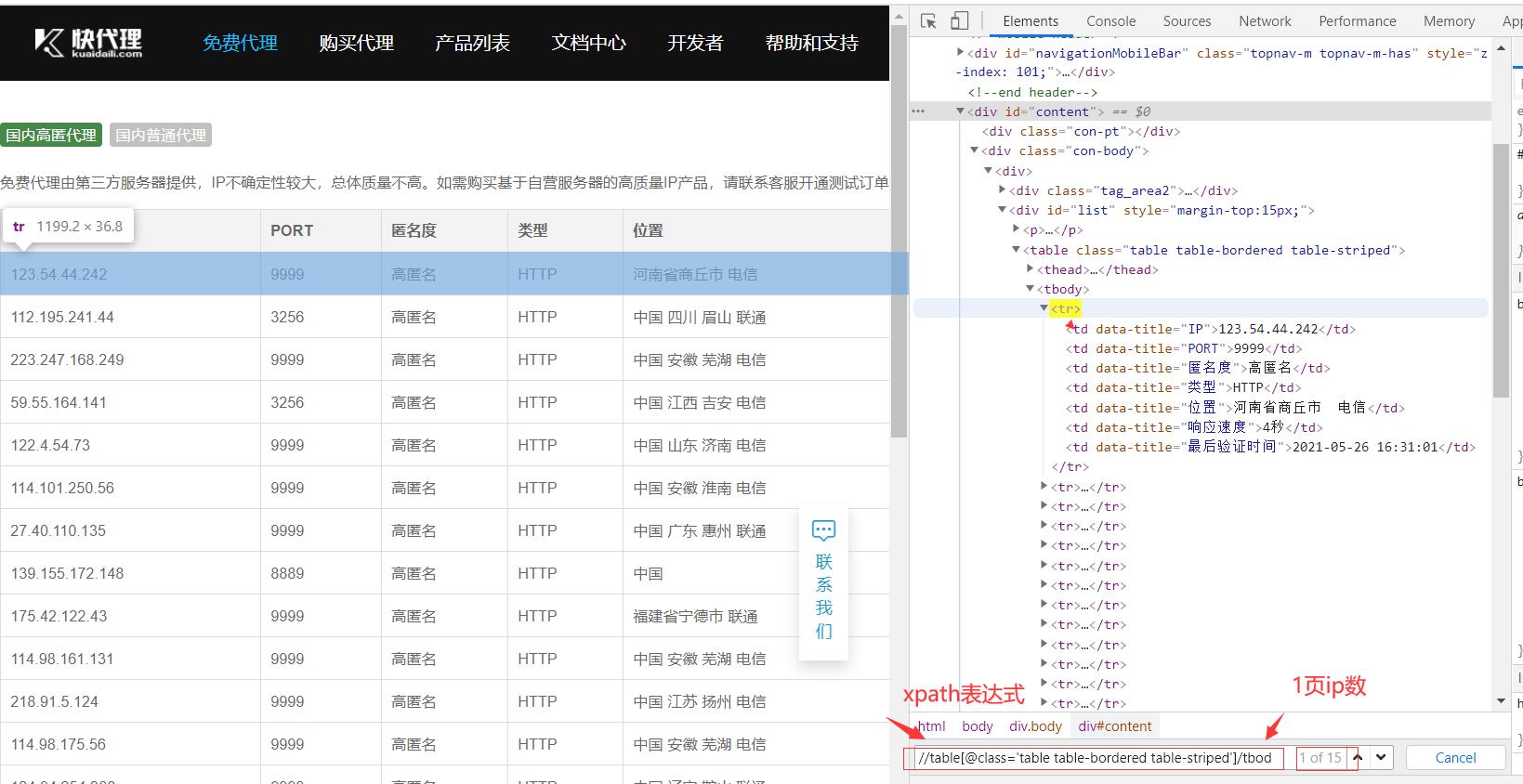
参考代码如下:
import requests
from crawlers.userAgent import useragent # 导入自己自定义的类,主要作用为随机取user-agent的值
from lxml import etree
url='https://www.kuaidaili.com/free/inha/1/'
headers={'user-agent':useragent().getUserAgent()}
rsp=requests.get(url=url,headers=headers)
HTML=etree.HTML(rsp.text)
infos=HTML.xpath("//table[@class='table table-bordered table-striped']/tbody/tr")
for info in infos:
print(info.xpath('./td[1]/text()')) # ip
print(info.xpath('./td[2]/text()')) # ip对应的端口 列表类型
怎样爬取多页呢?分析快代理那个网址,可以发现https://www.kuaidaili.com/free/inha/{页数}/ ,花括号里面就是页数,这个网址总页数为4038,这里小编只爬取5页,并且开始页数取(1,3000)之间的随机数,但是如果for循环这个过程,运行结果如下:
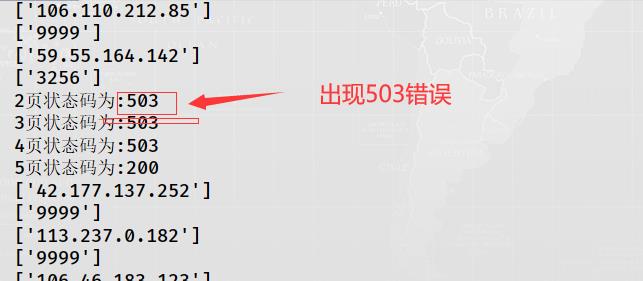
原来是请求过快的原因,只需在爬取1页之后,休眠几秒钟即可解决。
3.2 验证爬取到的ip是否可用
这里直接用百度这个网址作为测试网址,主要代码为:
url='https://www.baidu.com'
headers={'user-agent':useragent().getUserAgent()}
proxies={} # ip ,这里只是讲一下关键代码,没有给出具体IP
rsp=requests.get(url=url,headers=headers,proxies=proxies,time=0.2) # timeout为超时时间
只需判断rsp的状态码为200,如果是,把它添加到一个指定的列表中。
具体参考代码小编已经上传到Gitee上,链接为:ip代理模块
当然读者可用把这个文件保存到python\\Lib文件夹下面,这样就可用随时随地导入了。
3.3 实战:利用爬取到的ip访问CSDN博客网址1000次
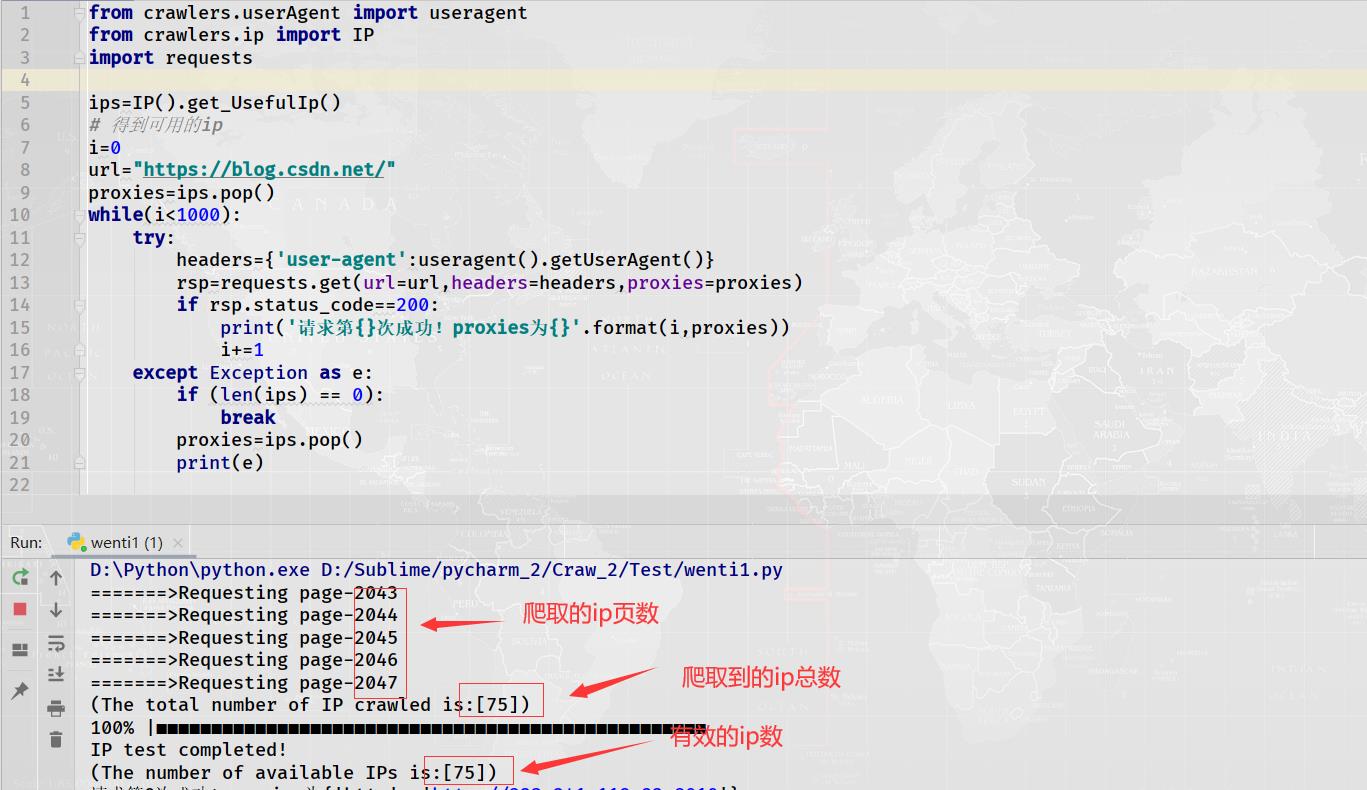


上述出现那个错误,小编上网搜索了一下原因,如下:

我想应该是第1种原因,ip被封,我这里没有设置超时时间,应该不会出现程序请求速度过快。
4. 总结
上述那个ip代理模块还有很多的不足点,比如用它去访问一些网址时,不管运行多少次,输出的结果状态码不会时200,这也正常,毕竟免费的ip并不是每个都能用的。如果要说改进的话,就是多爬取几个不同ip代理网址,去重,这样的结果肯定会比上述的那个ip代理模块要好。小编正在参与CSDN新星计划,如果读者觉得小编的这篇文章还不错的话,记得点赞,同时如果有什么问题和建议,欢迎到评论区留言!
以上是关于Python爬虫:制作一个属于自己的IP代理模块的主要内容,如果未能解决你的问题,请参考以下文章
Python3爬虫Scrapy使用IP代理池和随机User-Agent