Python网络爬虫四多线程爬取多张百度图片的图片
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python网络爬虫四多线程爬取多张百度图片的图片相关的知识,希望对你有一定的参考价值。
最近看了女神的新剧《逃避虽然可耻但有用》
被大只萝莉萌的一脸一脸的,我们来爬一爬女神的皂片。
百度搜索结果:新恒结衣
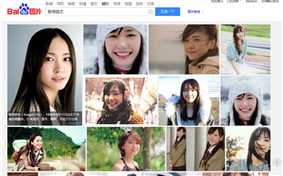
1.下载简单页面
通过查看网页的html源码,分析得出,同一张图片共有4种链接:
{"thumbURL":"http://img5.imgtn.bdimg.com/it/u=2243348409,3607039200&fm=23&gp=0.jpg",
"middleURL":"http://img5.imgtn.bdimg.com/it/u=2243348409,3607039200&fm=21&gp=0.jpg",
"hoverURL":"http://img5.imgtn.bdimg.com/it/u=2243348409,3607039200&fm=23&gp=0.jpg",
"objURL":"http://attachments.gfan.com/attachments2/day_110111/1101112033d77a4a8eb2b00eb1.jpg"}
主要区别是分辨率不同,objURL是图片的源也是最清楚的一张。经测试,前三种都有反爬虫措施,用浏览器可以打开,但是刷新一次就403 Forbidden。用爬虫获取不到图片
第四种objURL是指图片的源网址,获取该网址会出现三种情况:
- 正常。继续下载
- 403 Forbidden。用continue跳过。
- 出现异常。用try except处理。
1 #coding: utf-8 2 import os 3 import re 4 import urllib 5 import urllib2 6 7 def getHtml(url): 8 page=urllib.urlopen(url) 9 html=page.read() 10 return html 11 12 def getImg(html): 13 reg=r‘"objURL":"(.*?)"‘ #正则 14 # 括号表示分组,将括号的内容捕获到分组当中 15 # 这个括号也就可以匹配网页中图片的url了 16 imgre=re.compile(reg) 17 print imgre 18 imglist=re.findall(imgre,html) 19 l=len(imglist) 20 print l 21 return imglist 22 23 def downLoad(urls,path): 24 index = 1 25 for url in urls: 26 print("Downloading:", url) 27 try: 28 res = urllib2.Request(url) 29 if str(res.status_code)[0] == "4": 30 print("未下载成功:", url) 31 continue 32 except Exception as e: 33 print("未下载成功:", url) 34 filename = os.path.join(path, str(index) + ".jpg") 35 urllib.urlretrieve(url,filename) #直接将远程数据下载到本地。 36 index += 1 37 html =getHtml("http://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&s" 38 "f=1&fmq=1484296421424_R&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&" 39 "word=新垣结衣&f=3&oq=xinyuanj&rsp=0") 40 Savepath="D:\\TestDownload" 41 downLoad(getImg(html),Savepath)
其中urlretrieve方法
直接将远程数据下载到本地。
urllib.urlretrieve(url[, filename[, reporthook[, data]]])
参数说明:
url:外部或者本地url
filename:指定了保存到本地的路径(如果未指定该参数,urllib会生成一个临时文件来保存数据);
reporthook:是一个回调函数,当连接上服务器、以及相应的数据块传输完毕的时候会触发该回调。我们可以利用这个回调函数来显示当前的下载进度。
data:指post到服务器的数据。该方法返回一个包含两个元素的元组(filename, headers),filename表示保存到本地的路径,header表示服务器的响应头。
女神的照片就这么被爬下来了
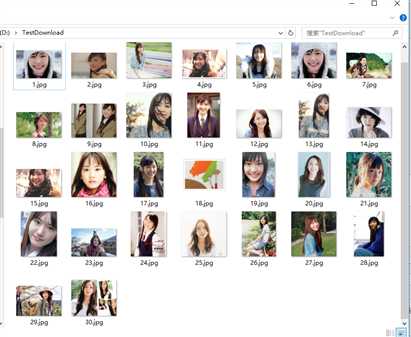
2.爬取更多图片
等等,这个方法不过瘾呀,百度图片的页面是动态加载的,需要你往下滑才能继续加载后面的照片,我们这才完成了第一步,只爬到了30张图。
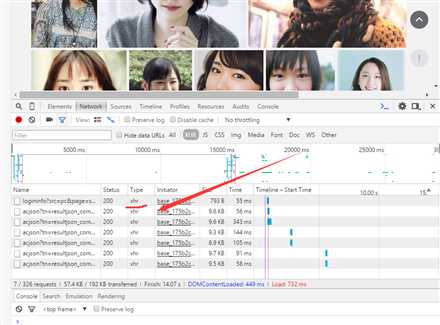
打开浏览器,按F12,切换到Network标签,然后将网页向下拉。这时浏览器地址栏的网址并没有改变,而网页中的图片却一张张增加,说明网页在后台与服务器交互数据。好的发现了就是这个家伙
XHR英文全名XmlHttpRequest,中文可以解释为可扩展超文本传输请求。Xml可扩展标记语言,Http超文本传输协议,Request请求。XMLHttpRequest对象可以在不向服务器提交整个页面的情况下,实现局部更新网页。当页面全部加载完毕后,客户端通过该对象向服务器请求数据,服务器端接受数据并处理后,向客户端反馈数据。
点开对比Request的URL,可以发现,基本上是一样的,除了末尾一点点。
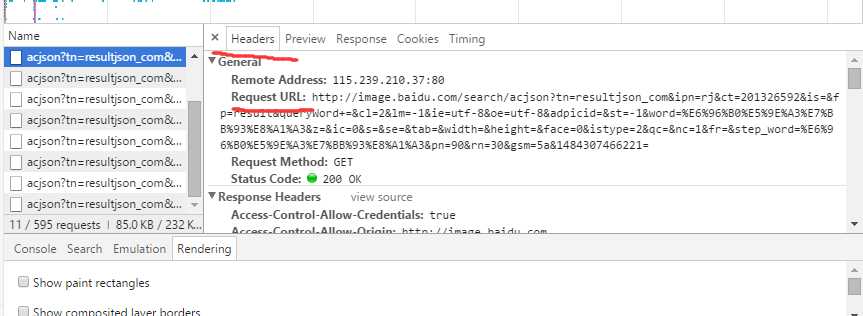
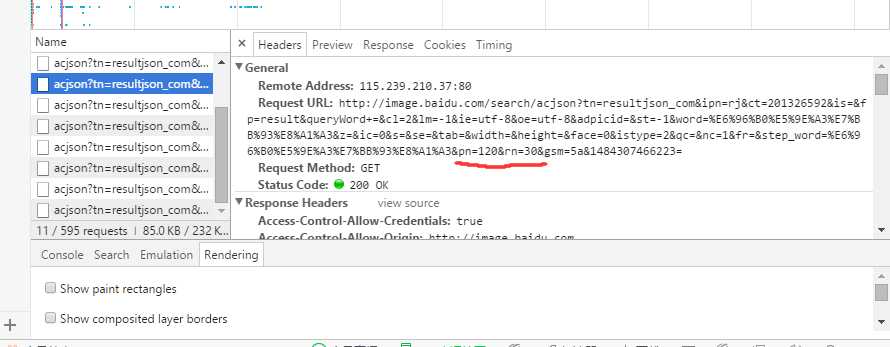
只是pn的值不一样,测试发现,pn应该是表示当前请求的图片序号,rn表示更新显示图片的数量。
pn=90&rn=30&gsm=5a&1484307466221=
pn=120&rn=30&gsm=5a&1484307466223=
pn=150&rn=30&gsm=78&1484307469213=
pn=180&rn=30&gsm=78&1484307469214=
pn=210&rn=30&gsm=b4&1484307553244=
现在知道了,其实我们只要不断访问这个Request URL,改变他的pn值理论上就可以实现下载多张图片了。
1 def getMoreURL(word): 2 word = urllib.quote(word) 3 url = r"http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&fp=result&queryWord={word}" 4 r"&cl=2&lm=-1&ie=utf-8&oe=utf-8&st=-1&ic=0&word={word}&face=0&istype=2nc=1&pn={pn}&rn=60" 5 urls = (url.format(word=word, pn=x) for x in itertools.count(start=0, step=30)) 6 #itertools.count 0开始,步长30,迭代 7 return urls
其中,urllib.quote的作用是,对url就行处理。
所以 URL 中使用其他字符就需要进行 URL 编码。
URL 中传参数的部分(query String),格式是:
name1=value1&name2=value2&name3=value3
URL编码的方式是把需要编码的字符转化为 %xx 的形式。通常 URL 编码是基于 UTF-8 的(当然这和浏览器平台有关)。
例子:
比如『我』,unicode 为 0x6211, UTF-8 编码为 0xE6 0x88 0x91,URL 编码就是
%E6%88%91itertools.count(start,step)的作用是一个迭代器,2个参数是开始和步长,这样就得到一个等差数列,这个数列填入url中,就得到了我们的urls。
试了下,转到解析得到的数据,objURL居然不是一个http的图片,查资料,显示下一步要做的就是解码。
"objURL":"ippr_z2C$qAzdH3FAzdH3Fta_z&e3Bi1fsk_z&e3Bv54AzdH3FkufAzdH3Fw6vitejAzdH3F99lwbdublldlnvjaavmc8c01ba8a8m1mu0vjwama_z&e3B3r2"
3.页面解码
参考百度图片页面解码,发现其实就是一个table,key和value对应就可以解码了,简直就是明文密码0.0.。。。
所以在我们的程序里加个字典,多个解码的过程。
期间解码过程一度出错,经过仔细排查,是url.translate(char_table)出了问题,
str 的translate方法需要用单个字符的十进制unicode编码作为key
value 中的数字会被当成十进制unicode编码转换成字符
也可以直接用字符串作为value
所以需要加上一行
char_table = {ord(key): ord(value) for key, value in char_table.items()}
以上是关于Python网络爬虫四多线程爬取多张百度图片的图片的主要内容,如果未能解决你的问题,请参考以下文章