Python高级应用程序设计任务要求
Posted 牛牛k
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python高级应用程序设计任务要求相关的知识,希望对你有一定的参考价值。
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
网易云歌手信息
2.主题式网络爬虫爬取的内容与数据特征分析
2.主题式网络爬虫爬取的内容与数据特征分析
内容:
网易云的各类歌手信息
数据特征:
歌手名,关注数,动态,粉丝数
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
分析获取所有歌手的方法,从以下的地址请求方式可以看出id跟initail的数字存在规律
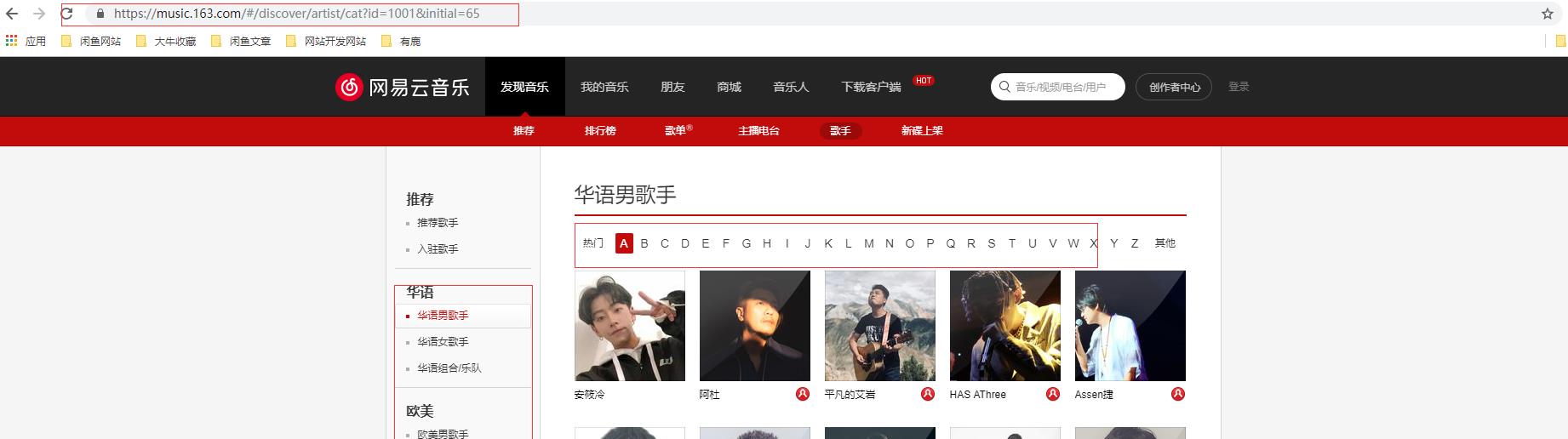
因此定义变量如下

二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
1.主题页面的结构特征
具有不同类型的歌手的页面,需要做动态爬取
2.Htmls页面解析
地址的变化


歌手家路径地址的获取

歌手信息内容
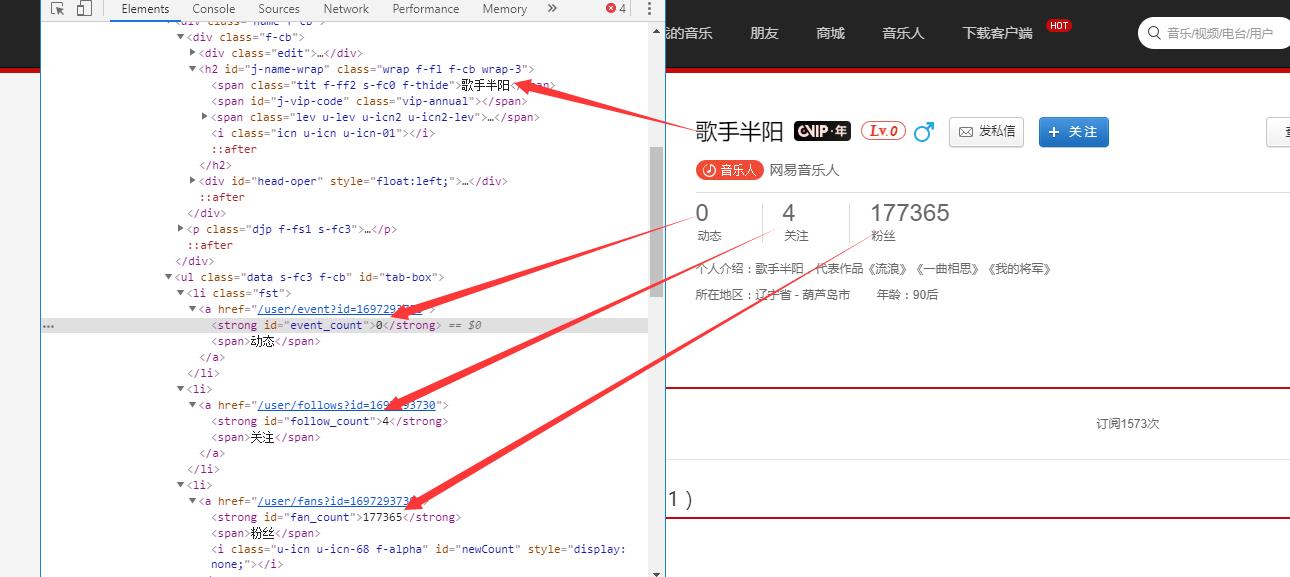
3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
使用类选择器找到对应的标签,然后进行地址拼接
eg:家目录地址:
soup.select(\'a.nm.nm-icn.f-thide.s-fc0~a\')在歌手家目录中找到歌手名称:
soup.select(\'#j-name-wrap > span.tit.f-ff2.s-fc0.f-thide\')[0].string
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
代码:
1 # coding:utf-8 2 import hashlib 3 import requests 4 import chardet 5 from bs4 import BeautifulSoup 6 from selenium import webdriver 7 import re 8 import pymysql as ps 9 import pandas as pd 10 import matplotlib.pyplot as plt 11 import numpy as np 12 13 class FormHotspot(object): 14 def __init__(self): 15 self.new_craw_url = set() 16 self.old_craw_url = set() 17 self.url_size = 0 18 # 无头启动 selenium 19 opt = webdriver.chrome.options.Options() 20 opt.set_headless() 21 self.browser = webdriver.Chrome(chrome_options=opt) 22 self.host = \'localhost\' 23 self.user = \'root\' 24 self.password = \'\' 25 self.database = \'wyy\' 26 self.con = None 27 self.curs = None 28 29 \'\'\' 30 爬取 31 \'\'\' 32 def craw(self): 33 # ------------------------- 歌手地址爬取部分 --------------------- 34 # 歌手分类跟排列下载 35 classification = [1001, 1002, 1003, 2001, 2002, 2003, 6001, 6002, 6003, 7001, 7002, 7003, 4001, 4002, 4003] # id的值 36 arrange = [-1, 0, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88,89, 90] # initial的值 37 #classification = [1001, 1002] # id的值 38 #arrange = [-1, 0] # initial的值 39 self.url_size = int(input("请爬取您想要爬取的歌手的个数:")) 40 print("温馨提示 ! 歌手信息太多情耐心等待! …… ……") 41 #爬取歌手加路径地址 42 for c in classification: 43 for a in arrange: 44 if (self.new_craw_url_size() == self.url_size): 45 break 46 url = \'https://music.163.com/discover/artist/cat?id=\' + str(c) + \'&initial=\' + str(a) 47 downSongList = self.down_song_list(url) 48 # 解析歌手列表 49 songList = self.parser_song_list(downSongList) 50 # 增加新的地址 51 for new_url in songList: 52 self.add_new_craw_url(new_url) 53 # ------------------------ 歌手详情部分 ------------------------- 54 oldSize = self.new_craw_url_size() 55 #爬取歌手信息 56 print("》》》预计有%s个歌手待爬取" % oldSize) 57 success = 0 58 while (self.has_new_craw_url()): 59 try: 60 # -----------下载 61 new_url = self.get_new_craw_url() 62 print("--------------歌手详情地址:"+new_url+":开始爬取") 63 songHtml = self.down_song(new_url) 64 # -----------解析 65 data = self.parser_song(songHtml) 66 # -----------保存 67 success = success + self.keep_song(data) 68 except: 69 print("操作歌手出现错误出错") 70 # 展示 71 print("》》》%s个歌手信息爬取失败!" % (oldSize - success)) 72 print("》》》%s个歌手信息爬取成功!" % success) 73 df = self.get_song() 74 75 # 当前歌手信息对照表 76 print("*************************************************") 77 print("*************当前歌手id-name对照表****************") 78 print(df[[\'id\',\'name\']]) 79 self.show_song(df) 80 81 \'\'\' 82 ----------------------- 歌手详情页 start ----------------------------- 83 \'\'\' 84 \'\'\' 85 歌手信息下载 86 \'\'\' 87 def down_song(self,url): 88 try: 89 if url is None: 90 return None 91 s = requests.session() 92 header = { 93 \'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36\', 94 "Referer": "https://music.163.com/" 95 } 96 self.browser.get(url) 97 self.browser.switch_to.frame(\'g_iframe\') 98 html = self.browser.page_source 99 return html 100 except: 101 print("----------------down song failed--------------") 102 return None 103 104 \'\'\' 105 歌手信息解析 106 \'\'\' 107 def parser_song(self,html): 108 if html is None: 109 return None 110 soup = BeautifulSoup(html,"html.parser") 111 # 歌手名称 112 name = soup.select(\'#j-name-wrap > span.tit.f-ff2.s-fc0.f-thide\')[0].string 113 # 动态 114 dynamic = soup.select(\'#event_count\')[0].string 115 # 关注 116 follow = soup.select(\'#follow_count\')[0].string 117 # 粉丝 118 fans = soup.select(\'#fan_count\')[0].string 119 return {\'name\':name, \'dynamic\':dynamic, \'follow\':follow, \'fans\':fans} 120 121 \'\'\' 122 歌手信息保存 123 \'\'\' 124 def keep_song(self,data): 125 try: 126 self.open_mysql() 127 sql = "insert into singer (name,dynamic,follow,fans) values (%s,%s,%s,%s)" 128 params = (data[\'name\'],data[\'dynamic\'],data[\'follow\'],data[\'fans\']) 129 row = self.curs.execute(sql, params) 130 self.con.commit() 131 self.close_mysql() 132 return row 133 except: 134 print("插入data:%s \\n失败!"%data) 135 self.con.rollback() 136 self.close_mysql() 137 return 0 138 139 \'\'\' 140 歌手信息获取 141 \'\'\' 142 def get_song(self): 143 self.open_mysql() 144 sql = sql = "select * from singer order by id asc" 145 try: 146 df = pd.read_sql(sql=sql,con=self.con) 147 self.close_mysql() 148 return df 149 except: 150 print(\'获取数据失败!\') 151 self.close_mysql() 152 return None 153 154 \'\'\' 155 歌手信息显示 156 \'\'\' 157 def show_song(self,data): 158 id = data[\'id\'] 159 dynamic = data[\'dynamic\'] 160 follow = data[\'follow\'] 161 fans = data[\'fans\'] 162 # x轴刻度最小值 163 xmin = (id[id.idxmin()] - 1) 164 xmax = (id[id.idxmax()] + 1) 165 # 设置坐标轴刻度 166 my_x_ticks = np.arange(xmin, xmax, 1) 167 plt.figure() 168 # 显示中文标签 169 plt.rcParams[\'font.sans-serif\'] = [\'SimHei\'] 170 # -------------------- 子图 ------------------------ 171 axes1 = plt.subplot(2,2,1) #子图 172 plt.scatter(id, dynamic) 173 # 设置坐标轴范围 174 plt.xlim((xmin,xmax)) 175 plt.xticks(my_x_ticks) 176 plt.xlabel("歌手id") 177 plt.ylabel("动态") 178 plt.grid() 179 plt.title("网易云歌手 动态") 180 axes2 = plt.subplot(2, 2, 2) 181 plt.scatter(id, follow) 182 # 设置坐标轴范围 183 plt.xlim((xmin, xmax)) 184 plt.xticks(my_x_ticks) 185 plt.xlabel("歌手id") 186 plt.ylabel("关注") 187 plt.grid() 188 plt.title("网易云歌手 关注") 189 axes3 = plt.subplot(2, 1, 2) 190 plt.scatter(id, fans) 191 # 设置坐标轴范围 192 plt.xlim((xmin, xmax)) 193 plt.xticks(my_x_ticks) 194 plt.xlabel("歌手id") 195 plt.ylabel("粉丝") 196 plt.grid() 197 plt.title("网易云歌手 粉丝") 198 plt.show() 199 200 \'\'\' 201 正则表达式匹配整数 202 \'\'\' 203 def parser_int_and_str(self,str): 204 pattern = re.compile(r\'[\\d]+\') # 查找正数字 205 result = pattern.findall(str) 206 return result 207 208 \'\'\' 209 拼接成日期 210 \'\'\' 211 def to_data(self,data): 212 if data is None: 213 return None 214 result = \'\' 215 # 列表生成式 216 b = [str(i) for i in data] 217 result = "-".join(b) 218 return result 219 220 \'\'\' 221 拼接标签 222 \'\'\' 223 def to_lable(self,data): 224 if data is None: 225 return None 226 result = \'\' 227 # 列表生成式 228 b = [str(i) for i in data] 229 result = "/".join(b) 230 return result 231 232 \'\'\' 233 ----------------------- 歌手详情页 end ----------------------------- 234 ----------------------- 歌手列表 start ----------------------------- 235 \'\'\' 236 237 \'\'\' 238 歌手列表下载 239 \'\'\' 240 def down_song_list(self, url): 241 try: 242 if url is None: 243 return None 244 s = requests.session() 245 headers = { 246 \'accept\':\'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3\', 247 \'accept-encoding\':\'gzip, deflate, br\', 248 \'accept-language\':\'zh-CN,zh;q=0.9\', 249 \'cookie\':r\'_ntes_nnid=6d65167963a7e0c4b0a1136906089c4f,1565780034826; _ntes_nuid=6d65167963a7e0c4b0a1136906089c4f; _iuqxldmzr_=32; WM_TID=2AHnJpF%2Bn2pABQBVAFMpvLV1ePTi2O4q; WM_NI=5BWTbk0awQMfZS94LRLtLiRv%2F8uZfsP2oiDvuxpeBVvhfjZiA4itz5bZiRRJ3xGBkB7BC6hnA7lo2yhQKwyVYIx6A%2BkpcmiKpC9wQ7lPEbYvvG6a6S3LkOY2J0g4YU8NQXo%3D; WM_NIKE=9ca17ae2e6ffcda170e2e6ee93b23a91aba183f17baaef8ba6d54a828e9eaef27b9489ba88c65487ab9c82ca2af0fea7c3b92af79e99b5e161f4bfb9b2d06e9a8df7d5cf5a90ac848ad17eede8bbbbe57994eea18ac77eb7a8c086c15eb6b8aa8bd96383eca795f93fa286a7b3d142f1a889a3ea4af59e8dd7eb6683e9a490b173ac8f8598fc5e9b97b8d7c421a9b0ad8eec41b49df798d43db0908b83dc7eb699fa82b559f194a5b0dc3a8af0a9d5dc5ffc929fb9ee37e2a3; JSESSIONID-WYYY=jwTw1lhoqU9W7H05vPDhC3WQ6vZMwl8KkUsb9Jj4%5CMWKsr2GZulWhYFEskvQyvTIEC4lk%2FAogIWPmzGweqBNKQNYvetHSW8f4K50UXbz2DEigwprCqy%2BCn8IGivydVy67%2BuO9U5eUSJc4CkiCwAu5o8gAPWvjdZtDQEuPRm%2BvZhKU1Ua%3A1575468859151\', 250 \'referer\':\'https://music.163.com/\', 251 \'user-agent\':\'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36\' 252 } 253 self.browser.get(url) 254 self.browser.switch_to.frame(\'g_iframe\') 255 html = self.browser.page_source 256 return html 257 except: 258 print("----------------down 歌手 分类 排序 页面 failed--------------") 259 return None 260 261 262 \'\'\' 263 解析歌手列表 264 \'\'\' 265 def parser_song_list(self, cont): 266 try: 267 if cont is None: 268 return None 269 soup = BeautifulSoup(cont, "html.parser") 270 new_urls = set() 271 # print(soup.prettify()) 272 # print(soup.select(\'a.nm.nm-icn.f-thide.s-fc0~a\')) 273 # 便利具有艺术家家目录的a标签的信息 274 for artist in soup.select(\'a.nm.nm-icn.f-thide.s-fc0~a\'): 275 homeUrl = "https://music.163.com/" + artist[\'href\'] 276 if(not((self.new_craw_url_size()+len(new_urls)) >= self.url_size)): 277 new_urls.add(homeUrl) 278 return new_urls 279 except: 280 print("---------------------parser 歌手家目录地址 failed--------------------") 281 282 \'\'\' 283 ----------------------- 歌手列表 end ----------------------------- 284 \'\'\' 285 286 \'\'\' 287 ----------------------- 地址管理 start --------------------------------- 288 增加一个待爬取的地址 289 \'\'\' 290 def add_new_craw_url(self, url): 291 if url is None: 292 return 293 if url not in self.new_craw_url and url not in self.old_craw_url: 294 self.new_craw_url.add(url) 295 296 297 \'\'\' 298 获取一个待爬取地址 299 \'\'\' 300 def get_new_craw_url(self): 301 if self.has_new_craw_url(): 302 new_craw_url = self.new_craw_url.pop() 303 self.old_craw_url.add(new_craw_url) 304 return new_craw_url 305 else: 306 return None 307 308 309 \'\'\' 310 在新地址集合中是否有待爬取地址 311 \'\'\' 312 def has_new_craw_url(self): 313 return self.new_craw_url_size() != 0 314 315 316 \'\'\' 317 未爬取的地址的数量 318 \'\'\' 319 def new_craw_url_size(self): 320 return len(self.new_craw_url) 321 322 323 \'\'\' 324 被加密数据的长度不管为多少,经过md5加密后得到的16进制的数据,它的长度是固定为32的。 325 \'\'\' 326 def encryption_md5(self, data, password): 327 """ 328 由于hash不处理unicode编码的字符串(python3默认字符串是unicode) 329 所以这里判断是否字符串,如果是则进行转码 330 初始化md5、将url进行加密、然后返回加密字串 331 """ 332 # 创建md5对象 333 m = hashlib.md5() 334 b = data.encode(encoding=\'utf-8\') 335 m.update(b) 336 return m.hexdigest() 337 Python高级应用程序设计任务要求