Python高级应用程序设计任务要求
Posted chanw
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python高级应用程序设计任务要求相关的知识,希望对你有一定的参考价值。
用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
爬取虎牙直播英雄联盟播放信息
2.主题式网络爬虫爬取的内容与数据特征分析
此次爬虫主要尝试爬取虎牙直播英雄联盟播放页的视频标题、主播名以及视频播放量
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
此次设计方案应用request库对虎牙网站进行页面爬取采集,然后beautifulsoup库提取目标信息,最后利用pandas将数据存储打印。技术难点主要有对数据的清洗以及对打印结果的排版。
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
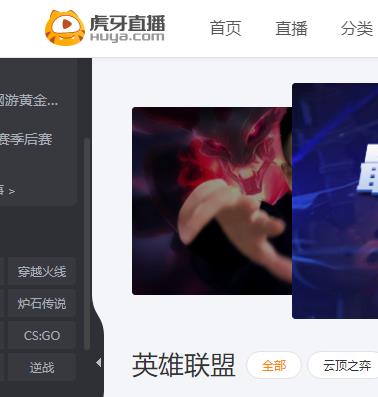
2.Htmls页面解析
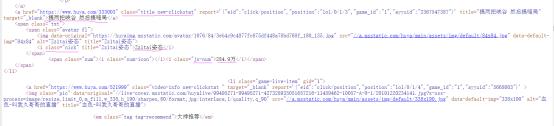
标题信息在class="title new-clickstat"的<a>标签中;主播名在class="nick"的<i>标签中;播放量在class="js-num"的<i>标签中。
3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
本爬虫使用find_all()方法进行遍历查找。
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。

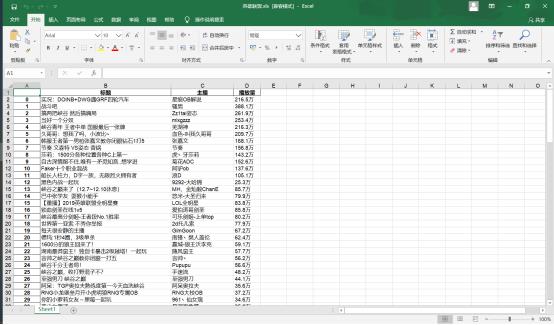
1.数据爬取与采集
def getHTMLText(url): try: #获取目标页面 r = requests.get(url) #判断页面是否链接成功 r.raise_for_status() #使用HTML页面内容中分析出的响应内容编码方式 r.encoding = r.apparent_encoding #返回页面内容 return r.text except: #如果爬取失败,返回“爬取失败” return "爬取失败" #获取目标信息 def getData(titleList,nameList,numList,html): #创建BeautifulSoup对象 soup = BeautifulSoup(html,"html.parser") #获取标题信息 for a in soup.find_all("a",{"class":"title new-clickstat"}): #将标题信息存在列表中 titleList.append(a.string) #获取主播名字信息 for i in soup.find_all("i",{"class":"nick"}): #将主播名字存在列表中 nameList.append(i.string) #获取播放量 for i in soup.find_all("i",{"class":"js-num"}): #将播放量存在列表中 numList.append(i.string)
2.对数据进行清洗和处理
def getHTMLText(url): try: #获取目标页面 r = requests.get(url) #判断页面是否链接成功 r.raise_for_status() #使用HTML页面内容中分析出的响应内容编码方式 r.encoding = r.apparent_encoding #返回页面内容 return r.text except: #如果爬取失败,返回“爬取失败” return "爬取失败"
#用来存放标题的列表 titleList = [] #用来存放主播名字的列表 nameList = [] #用来存放播放量的列表 numList = [] #英雄联盟页面链接 url = "https://www.huya.com/g/lol" #获取页面html代码 html = getHTMLText(url) #将目标信息存在目标列表中 getData(titleList,nameList,numList,html) #创建文件夹 makeMkdir() #数据存储并打印数据 pdSaveRead(titleList,nameList,numList)
3.文本分析(可选):jieba分词、wordcloud可视化
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
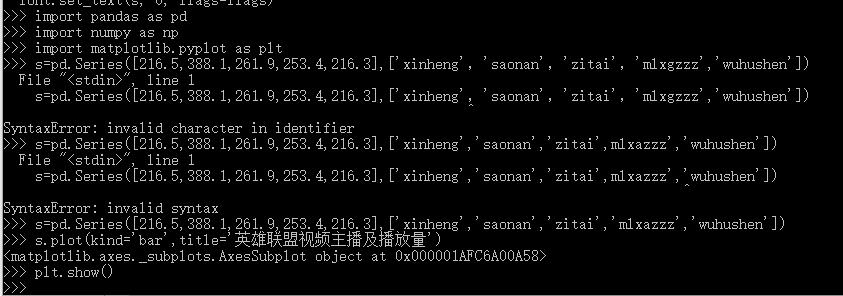
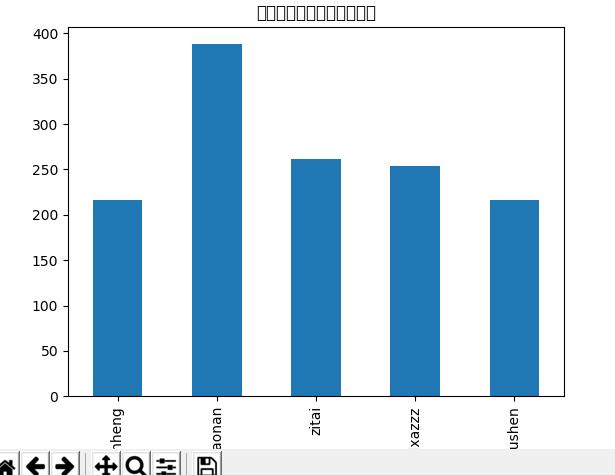
5.数据持久化
#使用pandas进行数据存储、读取 def pdSaveRead(titleList,nameList,numList): #创建numpy数组 r = np.array([titleList,nameList,numList]) #columns(列)名 columns_title = [\'标题\',\'主播\',\'播放量\'] #创建DataFrame数据帧 df = pd.DataFrame(r.T,columns = columns_title) #将数据存在Excel表中 df.to_excel(r\'C:\\虎牙直播\\英雄联盟.xls\',columns = columns_title) #读取表中岗位信息 dfr = pd.read_excel(r\'C:\\虎牙直播\\英雄联盟.xls\') print(dfr.head()) #用来存放标题的列表 titleList = [] #用来存放主播名字的列表 nameList = [] #用来存放播放量的列表 numList = [] #英雄联盟页面链接 url = "https://www.huya.com/g/lol"
6.附完整代码
import requests from bs4 import BeautifulSoup import pandas as pd import numpy as np import os #爬取前程无忧目标的HTML页面 def getHTMLText(url): try: #获取目标页面 r = requests.get(url) #判断页面是否链接成功 r.raise_for_status() #使用HTML页面内容中分析出的响应内容编码方式 r.encoding = r.apparent_encoding #返回页面内容 return r.text except: #如果爬取失败,返回“爬取失败” return "爬取失败" #获取目标信息 def getData(titleList,nameList,numList,html): #创建BeautifulSoup对象 soup = BeautifulSoup(html,"html.parser") #获取标题信息 for a in soup.find_all("a",{"class":"title new-clickstat"}): #将标题信息存在列表中 titleList.append(a.string) #获取主播名字信息 for i in soup.find_all("i",{"class":"nick"}): #将主播名字存在列表中 nameList.append(i.string) #获取播放量 for i in soup.find_all("i",{"class":"js-num"}): #将播放量存在列表中 numList.append(i.string) #创建文件夹 def makeMkdir(): try: #创建文件夹 os.mkdir("C:\\虎牙直播") except: #如果文件夹存在则什么也不做 "" #使用pandas进行数据存储、读取 def pdSaveRead(titleList,nameList,numList): #创建numpy数组 r = np.array([titleList,nameList,numList]) #columns(列)名 columns_title = [\'标题\',\'主播\',\'播放量\'] #创建DataFrame数据帧 df = pd.DataFrame(r.T,columns = columns_title) #将数据存在Excel表中 df.to_excel(r\'C:\\虎牙直播\\英雄联盟.xls\',columns = columns_title) #读取表中岗位信息 dfr = pd.read_excel(r\'C:\\虎牙直播\\英雄联盟.xls\') print(dfr.head()) #用来存放标题的列表 titleList = [] #用来存放主播名字的列表 nameList = [] #用来存放播放量的列表 numList = [] #英雄联盟页面链接 url = "https://www.huya.com/g/lol" #获取页面html代码 html = getHTMLText(url) #将目标信息存在目标列表中 getData(titleList,nameList,numList,html) #创建文件夹 makeMkdir() #数据存储并打印数据 pdSaveRead(titleList,nameList,numList)
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
1.经过对主题数据的分析与可视化,可以得到哪些结论?
通过爬取数据,能更直观的看出哪个主播的播放量更高,更受欢迎。
2.对本次程序设计任务完成的情况做一个简单的小结。
2.对本次程序设计任务完成的情况做一个简单的小结。
这次爬虫让我知道,做事情要一步一步来,不理解的方面要先解决了熟悉了再继续往下,前期的准备工作是必不可少的,这样在之后的各个步骤中才能明确自己要做什么,什么先做什么后做,对完成任务才能更加得心应手。此次爬虫过程中遇到不少困惑和不解,最终和伙伴一起学习讨论才能解决,让我深刻感受到PYTHON的魅力之处,希望这些对自己以后的学习有所帮助。
以上是关于Python高级应用程序设计任务要求的主要内容,如果未能解决你的问题,请参考以下文章