第一步:
(1)登录拉勾网分析源代码 搜索python这个时候你就会发现你想要的信息源代码里面找不到相关的职业,这就说明拉勾网关于职位的信息是异步加载的。
(2)异步信息加载 我借用是chrome浏览器按F12即可打开
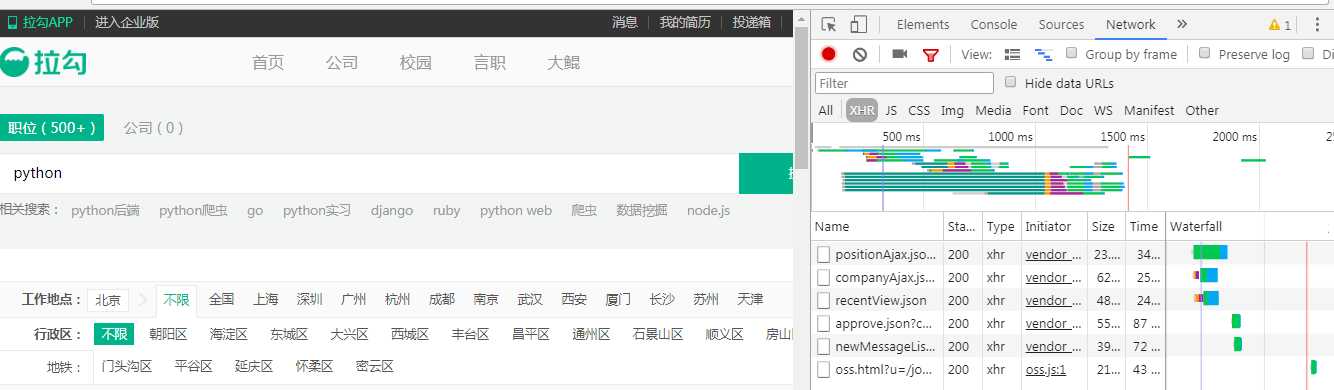
点击Network 进入分析界面 可能什么都没有 刷新一下 然后点击类类型XHR 看下面图片
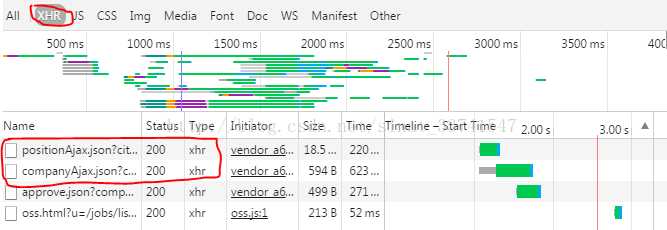
在此遇到的问题:按道理position.....右键点击在另一个页面打开就可以看到相关的职业信息(网上好多都是这么说的)但是我右键在另一个页面打开出现下面这种情况
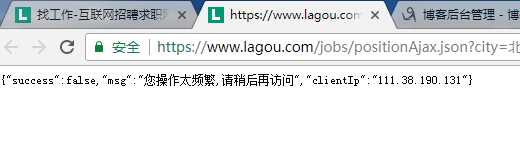
下面用代码说清怎么查看这里面的信息:
#coding: utf-8
import requests
import xlwt
headers={
#第一个电脑和服务器信息,
‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36‘,
# 第二个是你从哪里进入的拉钩网,没有这个以为是机器人访问。
‘Referer‘:‘https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=‘,
#第三个为了辨别身份,有的网站需要,有的不需要
‘Cookie‘:‘user_trace_token=20180324174638-effb0840-3454-44e8-b0db-0f4fe87e941a; _ga=GA1.2.269683739.1521884905; _gid=GA1.2.1286995000.1521884905; LGUID=20180324174640-40822bbf-2f48-11e8-b606-5254005c3644; WEBTJ-ID=20180325123102-1625b6c8afb270-0ecb9a782560ba-4446062d-1049088-1625b6c8afc2c5; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1521884905,1521898433,1521952263; _gat=1; LGSID=20180325122918-150ee81d-2fe5-11e8-9d63-525400f775ce; PRE_UTM=m_cf_cpt_baidu_pc; PRE_HOST=www.baidu.com; PRE_SITE=http%3A%2F%2Fwww.baidu.com%2Fs%3Ftn%3D78000241_2_hao_pg%26ie%3Dutf-8%26word%3D%25E6%258B%2589%25E5%258B%25BE%25E7%25BD%2591; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2Flp%2Fhtml%2Fcommon.html%3Futm_source%3Dm_cf_cpt_baidu_pc; X_HTTP_TOKEN=0581d8aab4c59f36bd4bde164849a65f; _putrc=33125A03144C0336123F89F2B170EADC; JSESSIONID=ABAAABAAAGFABEF50E0907CE27B3CA8713D779A9DF16483; login=true; unick=DarkElf; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; hasDeliver=0; gate_login_token=7405280061b2380ed953d861d5425e1b023d76bdf7ebe1fb42365d3661a371a4; index_location_city=%E5%8C%97%E4%BA%AC; TG-TRACK-CODE=index_search; LGRID=20180325123024-3c7e145e-2fe5-11e8-b62d-5254005c3644; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1521952329; SEARCH_ID=b9d4e982772e4c82ae1fae60a3f0fb4e‘}
#data对应的是分页pn为1就相当于第一页
def getJobList(page):
data={‘first‘:‘false‘,
‘kd‘:‘python‘,
‘pn‘:page}
# 发起一个post请求,指的当前网页的链接
req=requests.post(‘https://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC&needAddtionalResult=false&isSchoolJob=0‘,data=data,headers=headers)
# 将里面的数据以json格式展示类似于(key,value)
result=req.json()
print(result)
#查看第一页的 关于职位的信息
getJobList(1)
运行结果:

把运行结果全部复制到text里面分析这个时候你会发现里面有我们想要的信息
