爬取拉勾网
Posted truedragon
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬取拉勾网相关的知识,希望对你有一定的参考价值。
爬取的url:https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=
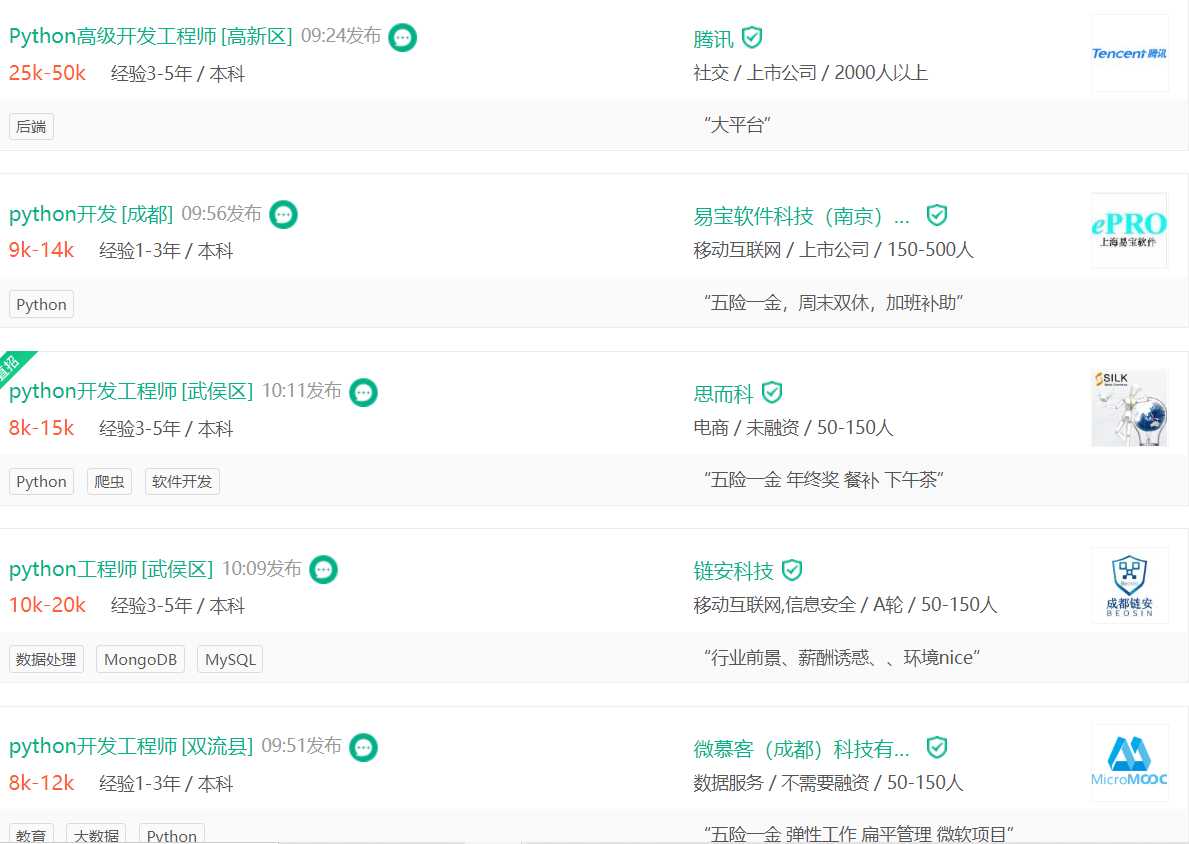
爬取职位名称,薪水,公司,待遇这些
抓包,找到信息加载为一个post请求返回

查看他携带的数据,里面是关键字(python)和页数(pn),这个sid每次都会改变,经测试,该post请求主要检查的是cookies,这个sid不需要(一次一次试出来的)
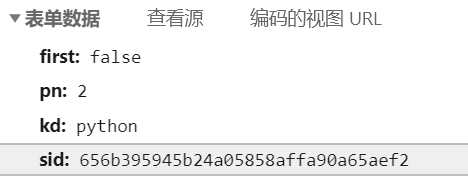
既然需要携带cookie,那我们首先建立一个session连接,获得cookie
1 s.get(url, headers=headers, timeout=3) 2 cookie = s.cookies
之后我们再用这个cookie构造post请求
1 response = s.post(url2, data=data, headers=headers, cookies=cookie) 2 html = response.text
成功返回json数据,之后解析json取出我们需要的数据就可以了
1 json_data = json.loads(html) 2 resulet = json_data[‘content‘][‘positionResult‘][‘result‘] 3 for datas in resulet: 4 positionName = datas[‘positionName‘] 5 companyShortName = datas[‘companyShortName‘] 6 companySize = datas[‘companySize‘] 7 salary = datas[‘salary‘] 8 workYear = datas[‘workYear‘] 9 positionAdvantage = datas[‘positionAdvantage‘] 10 city = datas[‘city‘] 11 firstType = datas[‘firstType‘] 12 secondType = datas[‘secondType‘]
最后将数据写入excel
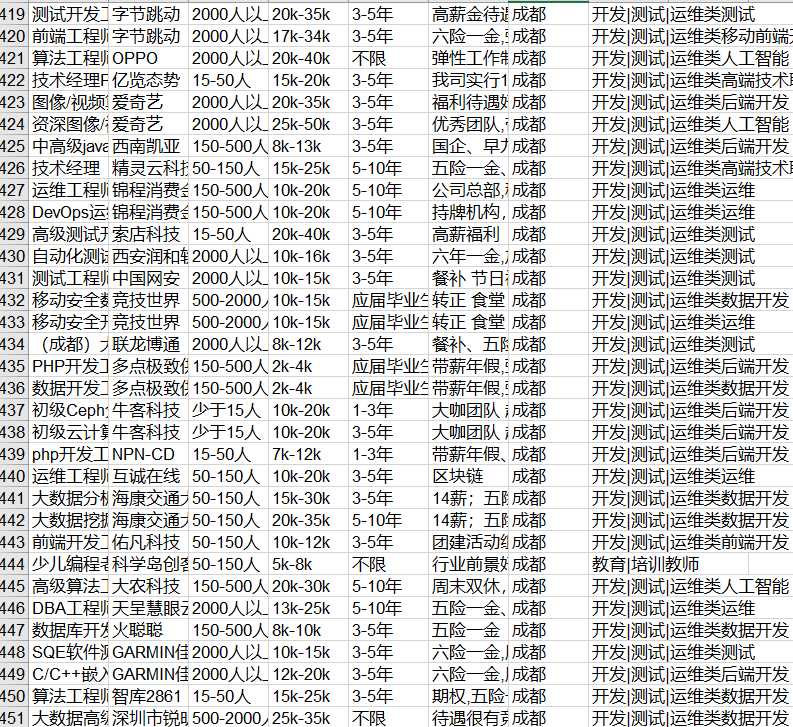
取出薪水和公司名称做一个简单的可视化
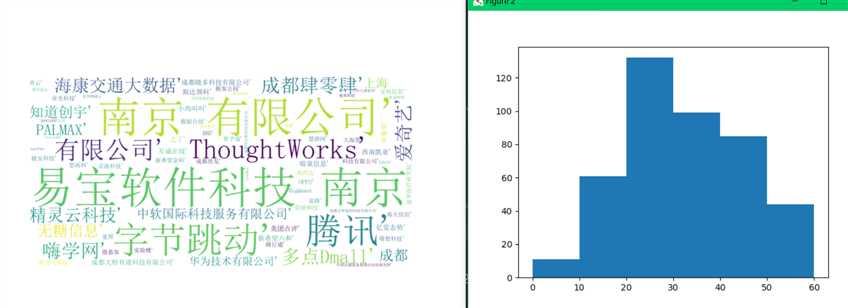
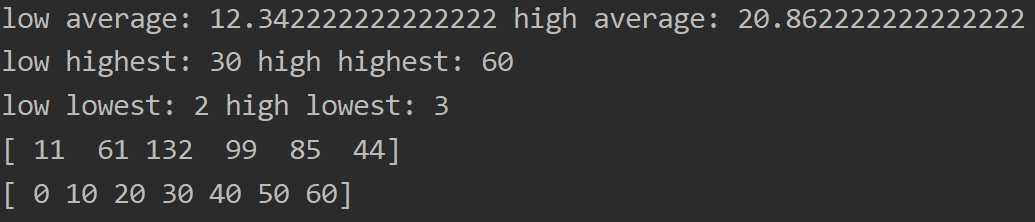
可以看到成都的python岗位平均薪资12 - 20k
最低工资2k,最高工资60k
在20 - 30k工资的人数占比最高为30%,0-10k的人数占比还是挺低的,当然都有学历和工作经验的要求(我就懒得分析了)
以上是关于爬取拉勾网的主要内容,如果未能解决你的问题,请参考以下文章