python爬虫笔记之re.compile.findall()
Posted 逆向小白
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫笔记之re.compile.findall()相关的知识,希望对你有一定的参考价值。
re.compile.findall原理是理解了,但输出不大理解(主要是加了正则表达式的括号分组)
一开始不懂括号的分组及捕捉,看了网上这个例子(如下),然而好像还是说不清楚这个括号的规律(还是说我没找到或是我理解能力太差),还是看不出括号的规律,于是更多的尝试(第二张大图),并最后总结规律。
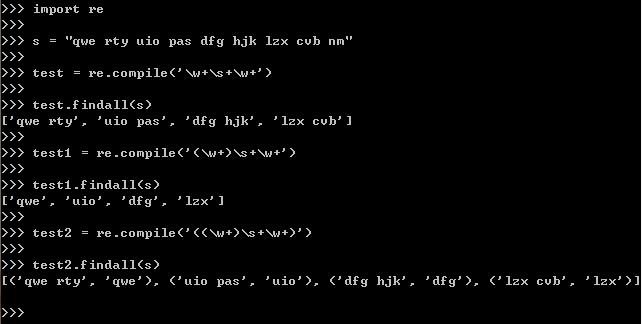



下图是为了尝试出括号分组的规律,下面是总结

就从最后一次匹配说起吧
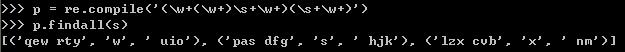
分析:首先是匹配的顺序,分析某个括号时,暂时去掉其它括号,易读
第一步,先对整个‘ ’内的规则作出匹配,整体匹配,先去括号(易读),即先从s中匹配出第一个【\\w+\\w+\\s+\\w+\\s+\\w+】(去括号的样子),但由于没有括号将这个整体扩上,所以没有捕捉(即不用输出),第一个匹配到的大字符串是“qew rty uio”
【可以这样一个个对应】
\\w+ \\w+ \\s+ \\w+ \\s+ \\w+
| | | | | |
qe w rty uio
对应图
第二步,匹配到的字符串再进行匹配捕捉,即输出,现在从左往右,一个个左括号捕捉起,第一个左括号【(\\w+\\w+\\s+\\w+)】(暂时去掉了嵌套在中间的左括号,易读),则匹配到上面字符串中(“qew rty uio”)的"qew rty"(可对照上面的对应图),由于是括号内,所以捕捉(即输出)
第三步,第二个括号,\\w+(\\w+)\\s+\\w+(暂时去掉其它括号) 匹配上一括号中的字符串(“qew rty”),即是匹配到‘w’(可对照上面的对应图),由于是括号内,所以捕捉(即输出)
第四步,第三个括号,\\w+\\w+\\s+\\w+(\\s+\\w+)(暂时去掉其他括号)匹配并输出第一步中的字符串,即是“uio”
总结:
1、首先全部去括号的匹配,画出对应图,这样很清晰,然后看括号内的即捕捉输出,然后在匹配的文本(s)再寻找下一个匹配的大字符串,一直找下去……
2、去括号是为了清晰的分析,主要注意从第一个左括号开始分析起
3、如果是嵌套括号,如(((a)b)(c)d),若要捕捉a括号的字符,则先需要匹配最外面的括号,然后在慢慢往里面匹配,即是先匹配出d括号的内容,再在d括号里面匹配出b括号的内容,再在b括号中匹配出a括号的内容,然后所有括号里的,输出,按左边第一个括号所匹配的字符串排列:(d,b,a,c)
如有错误,麻烦及时指正,谢谢!
以上是关于python爬虫笔记之re.compile.findall()的主要内容,如果未能解决你的问题,请参考以下文章