HTML5里的手势操作是如何实现的呢?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HTML5里的手势操作是如何实现的呢?相关的知识,希望对你有一定的参考价值。
入门新手求指教
参考技术A 举例说明:通过一句addEventListener 就能够知道当前用户的点击是哪种设备,是手指的点击,是鼠标的单击还是触控笔的点击(平板设备都会带有触控笔):
<canvas id="MyCanvas"></canvas>
<script>
MyCanvas.addEventListener("MSPointerDown", MyBack, false);
function MyBack(e)
alert(e.pointerType.toString());
</script>
通过回调的方法中 e.pointerType 还进行判断。
鼠标是4,触控笔是3,手指是2。
至于值为1是何种设备还有待研究。
还有需要注意的就是 想在javascript中添加对输入设备的识别,注册的方法事件也是有点点区别。
addEventListener 添加的事件为 MSPointerDown
而在IE10中对于这样的多种设备识别中优先处理的手指的点击,前提是不影响功能正常单击的情况下,然而IE10不仅仅能识别用户的输入设备还支持非常多的高级手势。 参考技术B 了解一下Touch事件你就知道如何识别手势了本回答被提问者采纳
元宇宙里的手势交互地表最强的手势交互原理剖析(HoloLens 2)下
简介
上篇文章提到,HoloLens手势识别最核心问题的是解决一个模型手拟合的问题,这篇文章会更深入地探讨这个优化问题更多细节和亮点。
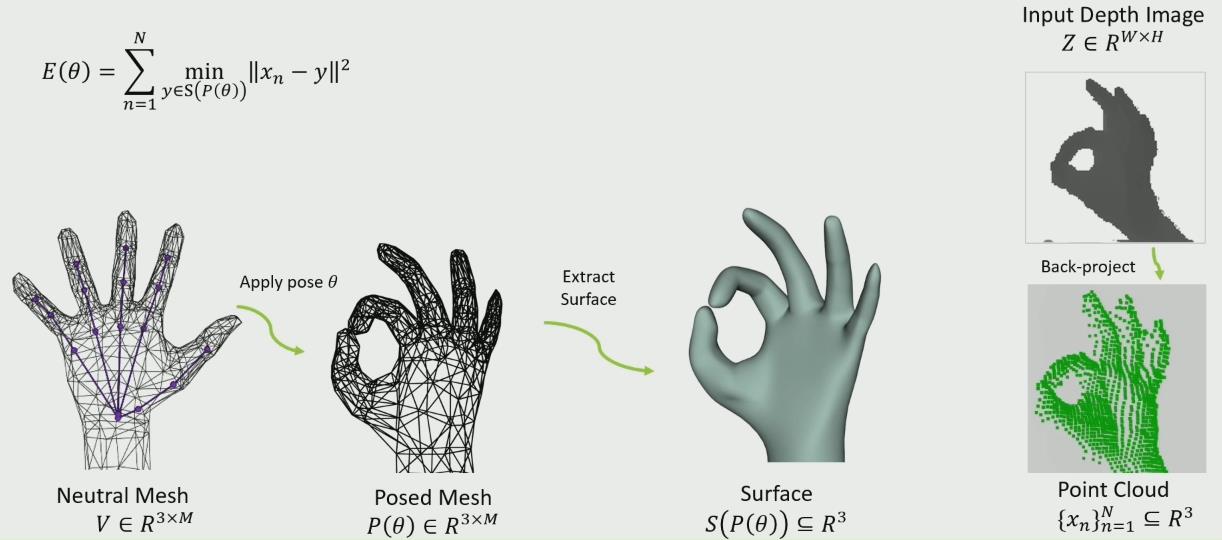
优化问题求解
上篇文正已经详细阐述了Energy函数是如何构建的,可以发现都是一堆平方的和,很适合LM算法迭代求解。注意这里近似海森矩阵的维度很大(N是图像点的数量,一般几百,θ是28维),如果用上法向是2N+θ维。之所以这么高维,每个点在模型上的对应位置会随着迭代而更新(对应点的位置也是优化变量)。LM算法涉及到求逆,很慢,由于矩阵大部分位置为0,可以简化一下计算,节约很多计算量。

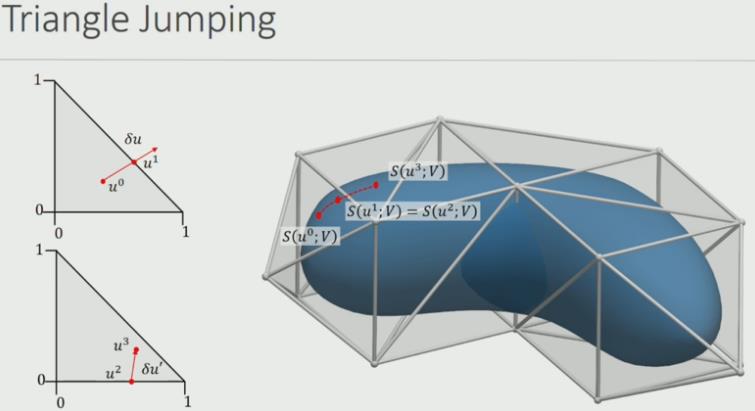
接着就到了最为关键的问题——模型的N个对应点如何在smooth surface model上随着梯度更新而移动?
一个三角面片内的移动很直观;作者另一篇文章也给出了如何跨越三角面片的方法——如果梯度移动超过了三角面片范围,先找到边界点,更新坐标到相邻三角面片,再继续更新梯度(也就是优化时,点的运动需要完成“跨越三角面片”的操作)
如图所示,工程实现时边界上的点u1=u2,在两个面片内的表示方式不一样,每个面片都会记录相邻的面片。(用脚趾想也知道这一套求逆优化的工程量真的挺大……)
优化问题初始姿态
[10]提出了两种pose初始化的方式,至于两种策略如何结合并没有提及。
首先最为直观的是利用上一帧的pose估计(简单线性追踪)
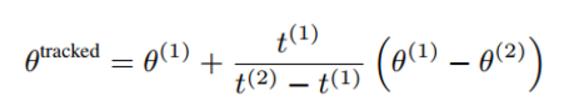
第二种是利用机器学习给出多个近似姿态,并利用检索姿态对应的pose初始化,这一步只需要5ms,这里没有找到对应的文章,但他们同组建图的大佬有一篇用随机森林做重定位的文章,本质上问题一样。
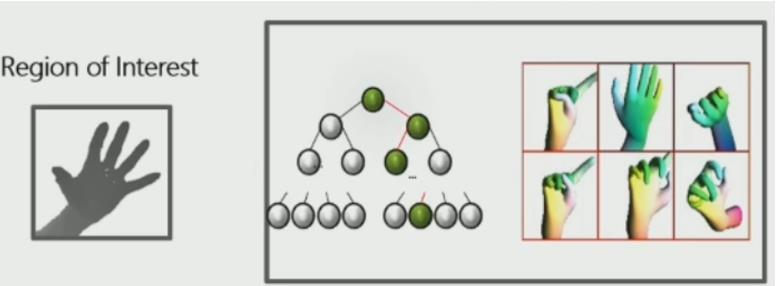
优化过程
每次优化分为稀疏更新和连续更新两步
如图所示,橘色的点是深度摄像头捕获到的手部区域(已转化成点云),蓝色的点是橘色点对应的点
第一轮
稀疏匹配:为每个橘色的点找一个距离最近的蓝色点作为配对点,注意这里的距离不仅是空间距离,还包括法向距离(之前的loss里已经有了介绍)。由于此时蓝色的点较少,存在多个橘点对应同一个蓝色点的情况。
连续匹配:对于每个橘色点对应的蓝色点,按梯度移动形成新的蓝色点,通过这一步可以形成非常多的蓝色的点(图中可以明显看出来)
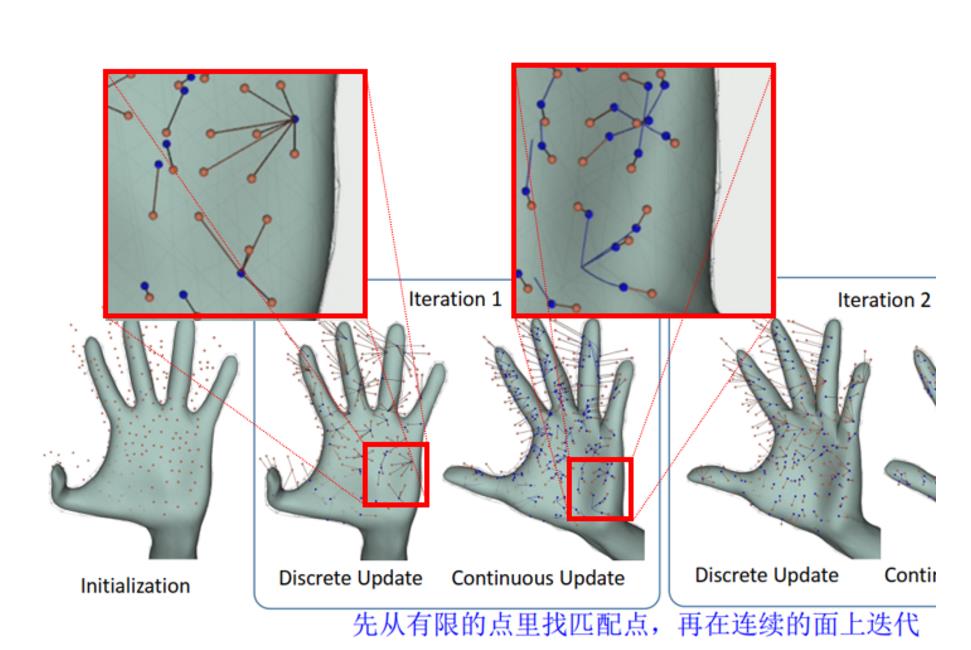
看到这里,难免有一个问题——第一轮蓝色的点怎么获取?
解决办法很简单,在模型手上预设一些点,随着pose改变位置。每帧手势的每个点(点云3D坐标)从这些点里找到距离和法向最近的点作为初始匹配。如果不是第一轮迭代,直接从上一帧结果的所有离散点里找最近的作为匹配点。

第二轮~第N轮
第二轮稀疏匹配有了更多蓝色的点,一些指头上的误匹配也可以拉回来了,之前错分到无名指上的点都拉回小指了(通过连续表面梯度更新的方法无法直接跨越到指头)
第二轮连续匹配继续迭代,到第三轮的时候拟合得已经很好了

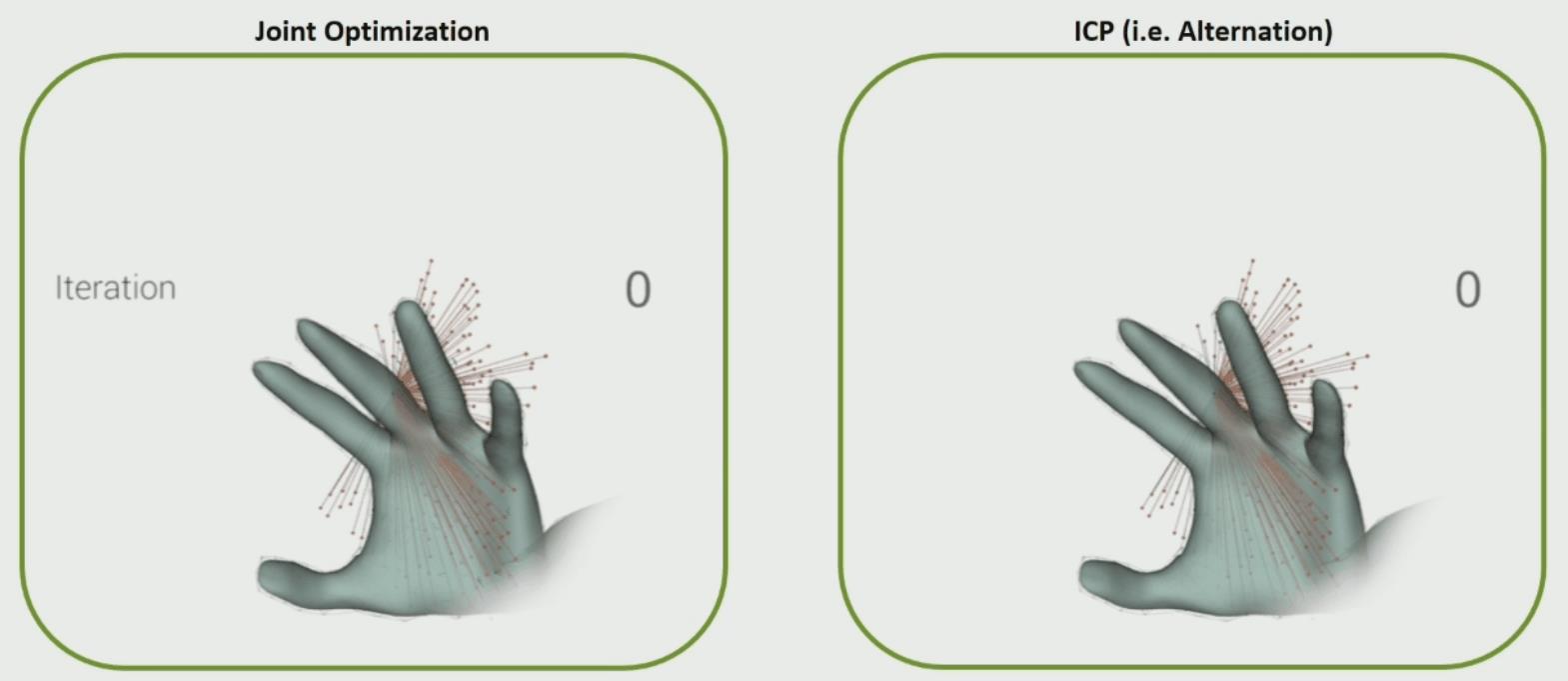
优化结果
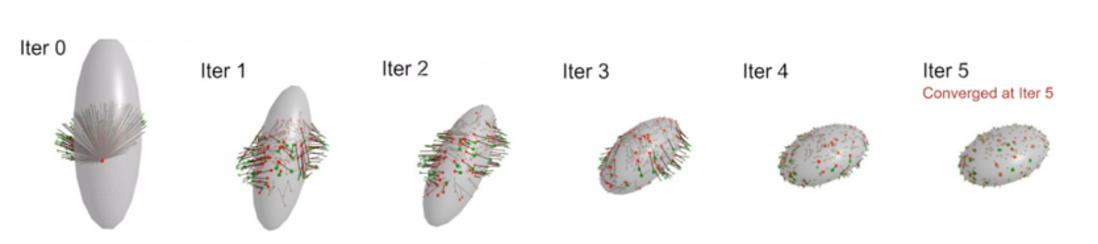
和ICP类的方法相比,迭代所需的轮次要少很多
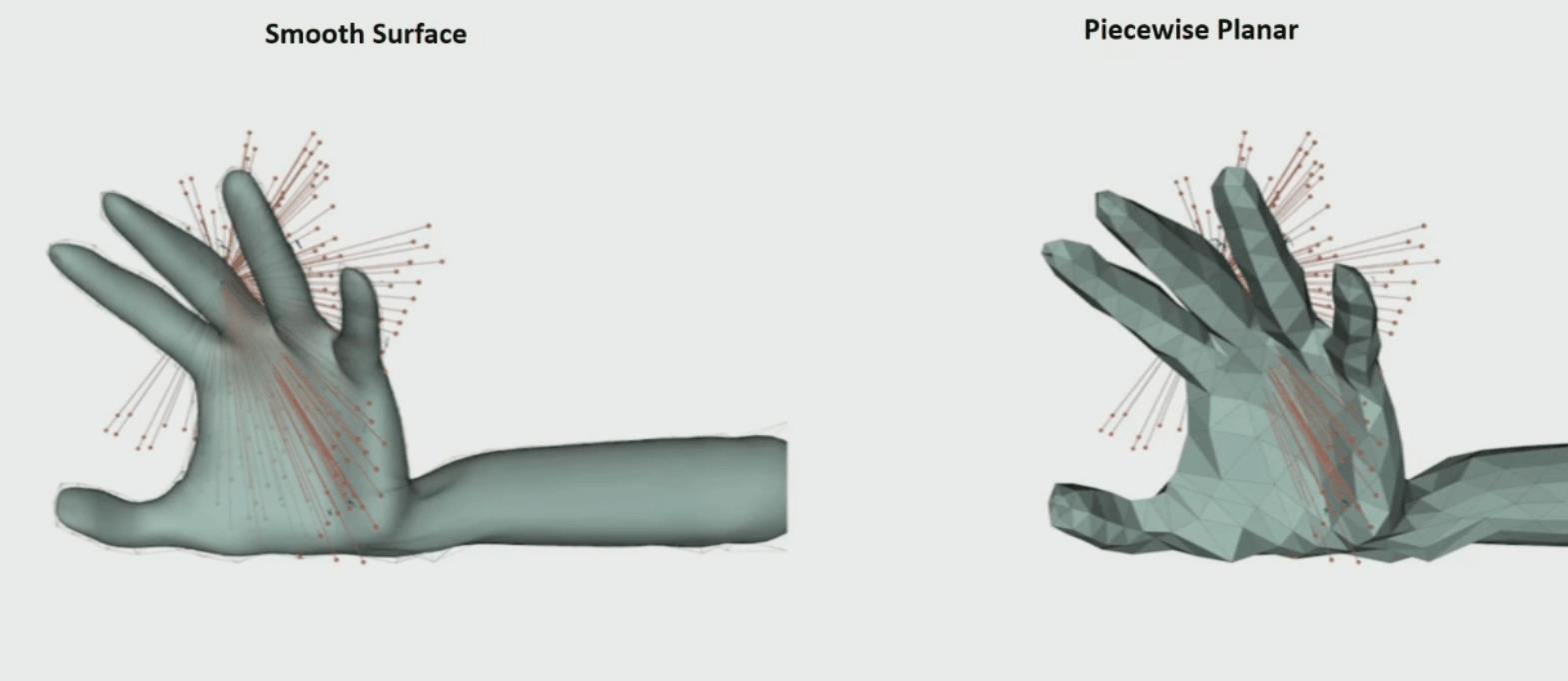
和粗糙三角mesh对比,一开始看着挺正常,最后 mesh的方案会在三角面片之间反复跳变无法收敛到较好的姿态
以上是HoloLens 1里的核心思想,HoloLens 2里也有不少改进点,目前能找到的论文里最关键的的就是ECCV2020[11]这篇。
模型改进——Phong Surface减少模型拟合计算量
上面提及的subdiv还不是非常快,微软团队2020提出了一种新的平滑模型构建方法,让计算量和三角面片模型接近,但是效果能达到和subdiv这种平滑模型接近的效果。目前HoloLens 2上用的就是这种模型,在一个算力只有4GFLOPS的硬件(DSP)上可以稳定双手实时。
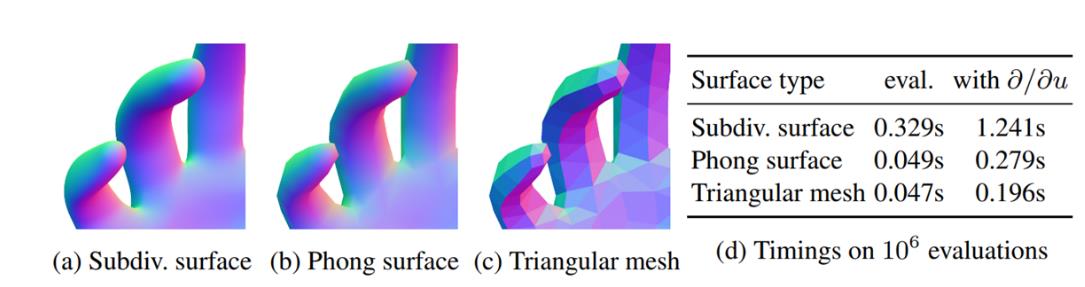
冯氏着色
首先介绍下图形学里的冯氏着色
最基础的,每个三角面片内的法向都一致,最终会使得每个面片的颜色都一样,计算量很少;高洛德着色每个顶点计算颜色,再进行线性插值颜色,计算量也不大;冯氏着色对于面片上的每个点都插值法向,再根据法向计算光照的弹射,最终有比较均匀的光照,计算量在这三种里算是大的(这个理论很老了,1975年就提出了),微软这个改进点很好地运用了冯氏着色的理论。着色器详细的可以看下这篇博客。

新版模型构建
相比于之前subdiv无穷细分的平滑模型,目前这版模型就显得有些糙了,点的位置就是粗糙的mesh手上的点,但是法向是三个点的加权和(法向是平滑的,点是粗糙的)

可以明显感受到这种模型计算量贼小,但是具备了平滑模型的优点,由于法向是平滑的,可以更好地找到匹配点,继而某些mesh手优化不下去的问题也迎刃而解。下面这张图非常明显了,加了平滑梯度的模型手可以和平滑模型找到基本一致的匹配点,而普通的mesh模型还是找到错误的匹配点,让优化问题陷入局部极值。
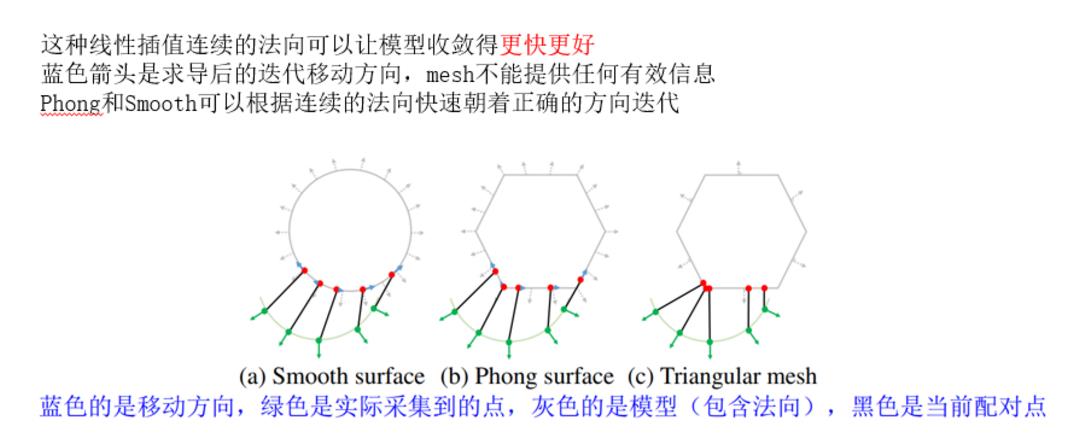
模型优化过程
和上面阐述的类似,优化过程也是要跨面片的,具体的细节可以参考论文[7]。这里的Xi会通过v,w随着模型其他变量一起迭代,v,w不会局限于一个面片,可以跨越相邻的面片。
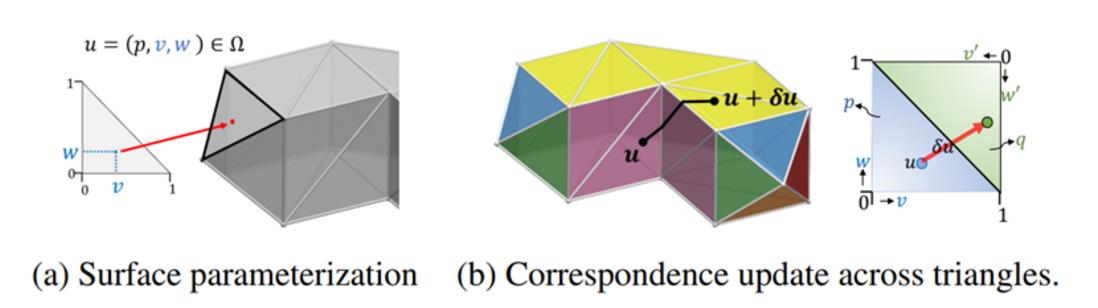
可以直观看下迭代的过程
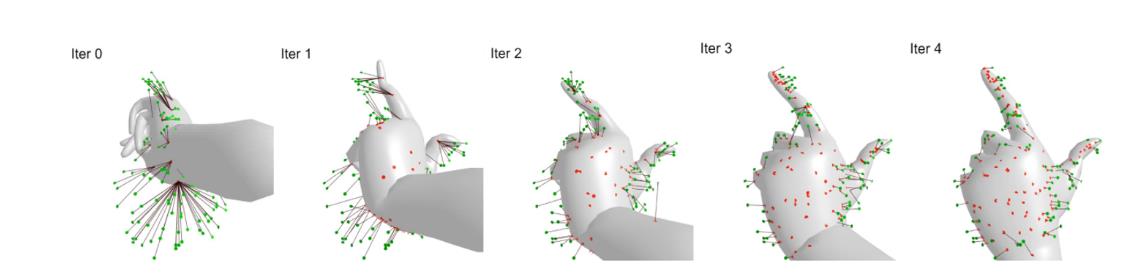
实验结果
文章也有些对比实验,以刚体为例,输入的点是变换后刚体正面的点(模拟深度图只能看到一半),并随机加入了一些噪声,三个轴都旋转固定角度,最终只评估旋转角的误差,定量评估lifted/ICP配合三种建模方式的效果。
结论是主要是一下几点:
- Mesh建模的效果很差
- Lifted优化比ICP快很多
- Phong surface是一种更快更好的建模方式
- 对mesh模型而言,有法向前10轮会下降地更快,但最终收敛效果差很多(因为法向错误反而会陷入局部极小值)
- 连续的法向会让模型收敛得更好,Phong在椭球体刚体迭代实验里精度比Subdiv还高

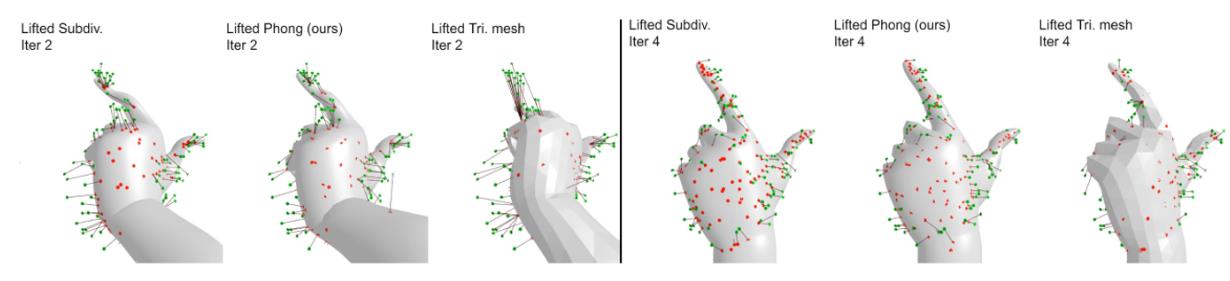
三种方法的实际应用对比如图所示,可以明显看出subdiv和phong的方案很接近,mesh的方案相比之下差很多,收敛得很慢,最终效果也不行
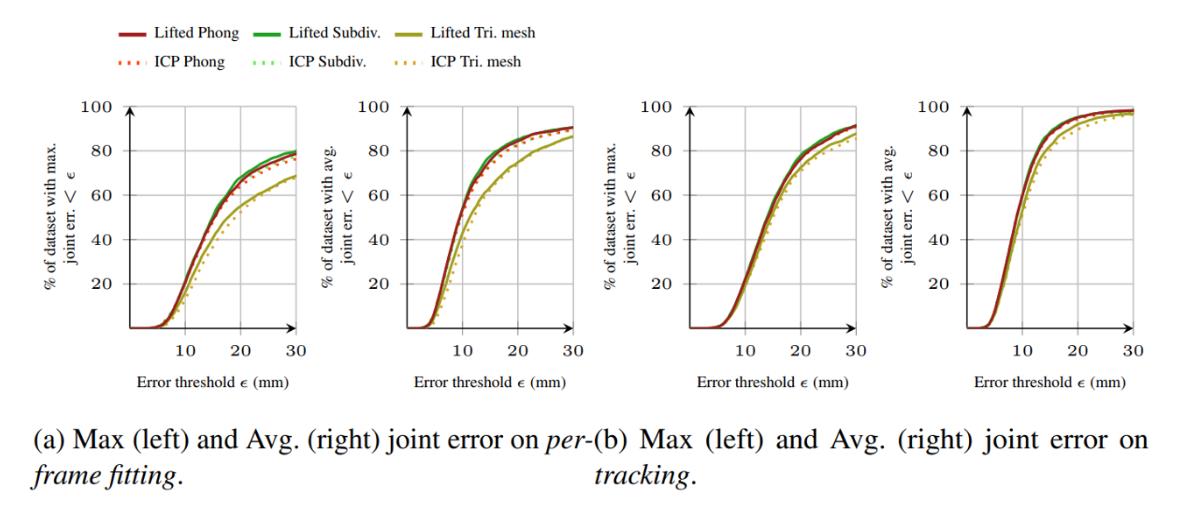
Lifted方法略优于ICP(不像刚体实验里有非常巨大的优势);Subdiv和Phong明显优于mesh;初值很重要,追踪会比每帧重新初始化正确率高很多
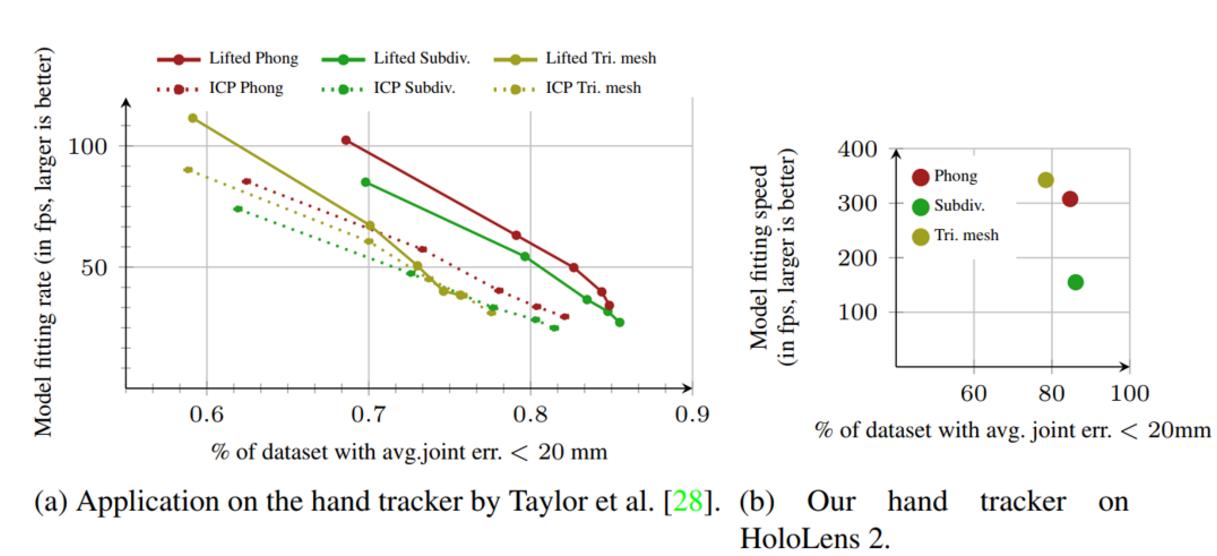
HoloLens 2新模型的速度
- PC的实验可以发现Subdiv可以达到的效果最好,但Phong整体都在右上方(性价比更高)
- HoloLens 2上最终优化后Phong略差于Subdiv,但快了一倍(300FPS)
- 注意一下HoloLens 2的手势跑在DSP上,运算能力只有4GFLOPS(iphone7的百分之一)
- 可以参考一下,高通865(小米10、一加8等)的DSP性能为15360 GOPS,性能至少是HoloLens的千倍以上,只能说一句——微软牛逼。
Reference
- https://en.wikipedia.org/wiki/Time-of-flight_camera
- HoloLens 2 Review: Ahead Of Its Time, For Better And Worse
- https://www.youtube.com/watch?v=S0fEh4UdtT8
- https://www.youtube.com/watch?v=QTz1zQAnMcU
- Azure Kinect DK – Develop AI Models | Microsoft Azure
- Azure Kinect DK Windows comparison | Microsoft Docs
- Taylor J, Stebbing R, Ramakrishna V, et al. User-specific hand modeling from monocular depth sequences[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2014: 644-651.
- Khamis S, Taylor J, Shotton J, et al. Learning an efficient model of hand shape variation from depth images[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 2540-2548.
- Tan D J, Cashman T, Taylor J, et al. Fits like a glove: Rapid and reliable hand shape personalization[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 5610-5619.
- Taylor J, Bordeaux L, Cashman T, et al. Efficient and precise interactive hand tracking through joint, continuous optimization of pose and correspondences[J]. ACM Transactions on Graphics (TOG), 2016, 35(4): 1-12.
- Shen J, Cashman T J, Ye Q, et al. The phong surface: Efficient 3d model fitting using lifted optimization[C]//European Conference on Computer Vision. Springer, Cham, 2020: 687-703.
- Loop C. Smooth subdivision surfaces based on triangles[J]. Master's thesis, University of Utah, Department of Mathematics, 1987.
- Wang R, Yang X, Yuan Y, et al. Automatic shader simplification using surface signal approximation[J]. ACM Transactions on Graphics (TOG), 2014, 33(6): 1-11.
以上是关于HTML5里的手势操作是如何实现的呢?的主要内容,如果未能解决你的问题,请参考以下文章
如何使用HTML5+CSS3+jquery 实现用户拖拽自定义界面