迁移学习《Asymmetric Tri-training for Unsupervised Domain Adaptation》
Posted Blair
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了迁移学习《Asymmetric Tri-training for Unsupervised Domain Adaptation》相关的知识,希望对你有一定的参考价值。
论文信息
论文标题:Asymmetric Tri-training for Unsupervised Domain Adaptation
论文作者:Kuniaki Saito, Y. Ushiku, T. Harada
论文来源:27 February 2017——ICML
论文地址:download
论文代码:download
视屏讲解:click
1 介绍
简单的域分布对齐可能无法提供有效的判别表示,为学习目标域的判别表示,本文假设人工标记目标样本可以产生良好的表示。
在本文中,提出了一种用于无监督域适应的非对称三重训练方法,将伪标签分配给未标记的样本,并像训练真实标签一样训练神经网络。 本文工作,不对称地使用三个网络。 不对称是指两个网络用于标记未标记的目标样本,一个网络由样本训练以获得目标判别表示。
2 相关工作
[1] 研究了伪标签在神经网络中的作用。他们认为,使用伪标签训练分类器的效果等同于熵正则化,从而导致类之间的低密度分离。
3 方法

算法伪代码:

为使 $F_1$, $F_2$ 从不同视角分类样本,将分类器权重 $\\left|W_1^T W_2\\right|$ 考虑到损失函数:
$E\\left(\\theta_F, \\theta_F_1, \\theta_F_2\\right)=\\frac1n \\sum_i=1^n\\left[L_y\\left(F_1 \\circ F\\left(x_i\\right), y_i\\right)+L_y\\left(F_2 \\circ F\\left(x_i\\right), y_i\\right)\\right]+\\lambda\\left|W_1^T W_2\\right| \\quad\\quad\\quad(1)$
伪代码主要分为两部分:
-
- 第一部分:使用训练集训练整个网络,$F_1$, $F_2$ 使用 $\\textEq.1$ 优化,$F_t$ 使用标准的分类损失训练;
- 第二部分:为目标域样本提供伪标签,要求1:$F_1$, $F_2$ 的预测类别相同;要求2:$F_1$, $F_2$ 预测的概率大于 $0.9$ 或 $0.95$;
为防止过拟合得到伪标签,重采样参与的伪标签样本。设置 $N_\\text init =5000$ ,然后逐步增 加参与的数量 $N_t=k / 20 * n$ , $n$ 为所有目标域样本数量。设置参与训练的价标签样本最大数量为 $40000$。
通过构建仅在目标域样本上训练的特定于目标域的网络,将学习判别性表示。但是仅使用有噪声的伪标签样本训练,网络可能无法学习有用的表示。然后我们使用源域和伪标签样本训练三个分类器以保证准确率。同随着训练, $F$ 将学习目标域判别性表示,使分类器 $F_1$, $F_2$ 的正确率提升。这个周期逐渐增强目标域上的准确率。
[1] Lee, Dong-Hyun. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. In ICML workshop on Challenges in Representation Learning, 2013.
因上求缘,果上努力~~~~ 作者:加微信X466550探讨,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/17291334.html
深度学习面试题27:非对称卷积(Asymmetric Convolutions)
目录
产生背景
举例
参考资料
|
产生背景 |
之前在深度学习面试题16:小卷积核级联卷积VS大卷积核卷积中介绍过小卷积核的三个优势:
①整合了三个非线性激活层,代替单一非线性激活层,增加了判别能力。
②减少了网络参数。
③减少了计算量
在《Rethinking the Inception Architecture for Computer Vision》中作者还想把小卷积核继续拆解,从而进一步增强前面的优势
|
举例 |
一个3*3的卷积可以拆解为:一个3*1的卷积再串联一个1*3的卷积,实验证明这样做在精度上损失不大,这两者的感受野是相同的,如下图所示:
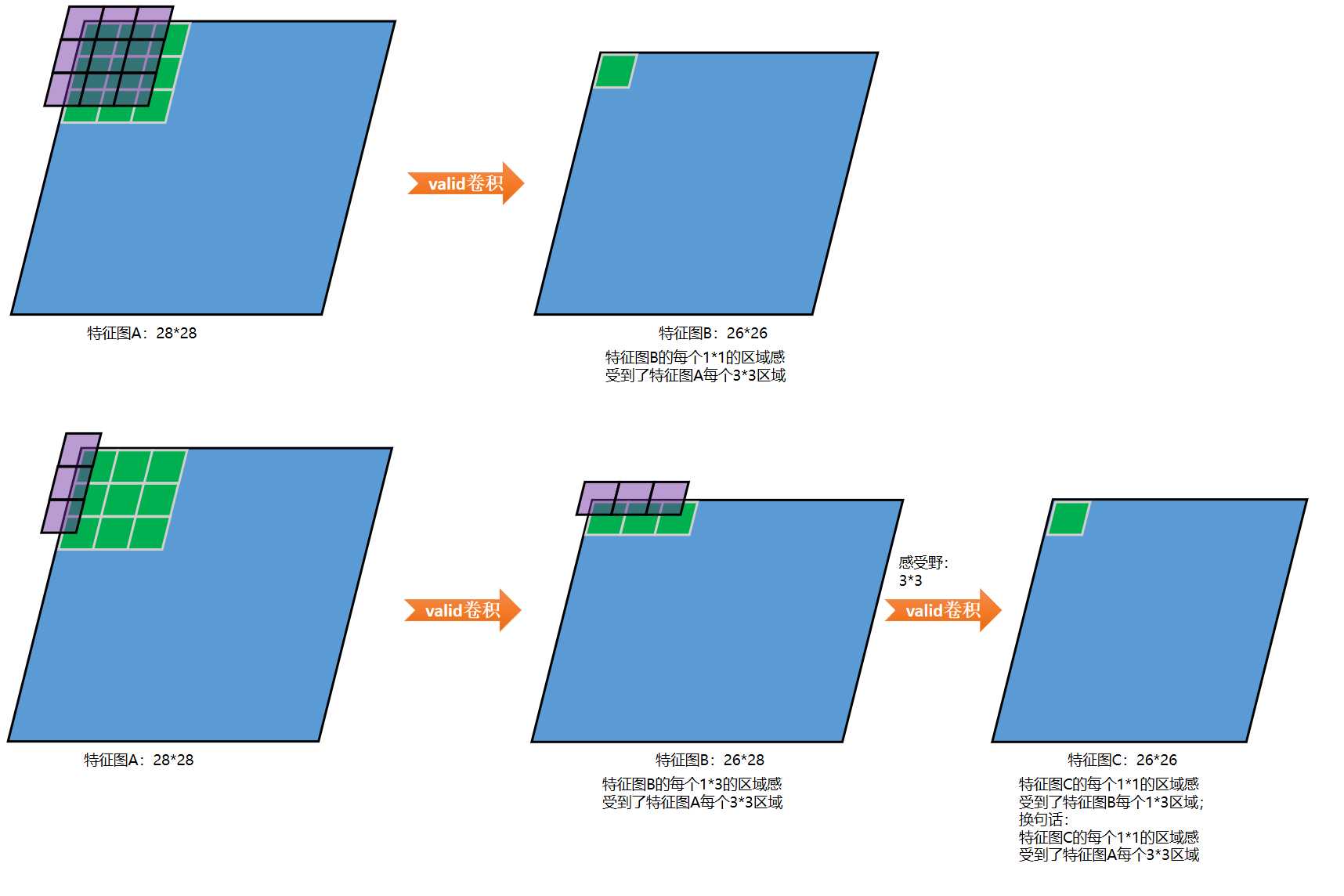
同理,
5*5的卷积可以拆解为:一个5*1的卷积再串联一个1*5的卷积
7*7的卷积可以拆解为:一个7*1的卷积再串联一个1*7的卷积
作者在论文《Rethinking the Inception Architecture for Computer Vision》中说明,这样的非对称卷积不要用在靠近输入的层,会影响精度,要用在较高的层
|
参考资料 |
《图解深度学习与神经网络:从张量到TensorFlow实现》_张平
Rethinking the Inception Architecture for Computer Vision
以上是关于迁移学习《Asymmetric Tri-training for Unsupervised Domain Adaptation》的主要内容,如果未能解决你的问题,请参考以下文章
第18期:对称加密和非对称加密 | Symmetric and Asymmetric Encryption
论文笔记:Asymmetric Temperature Scaling Makes Larger Networks Teach Well Again