论文笔记:Asymmetric Temperature Scaling Makes Larger Networks Teach Well Again
Posted UQI-LIUWJ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文笔记:Asymmetric Temperature Scaling Makes Larger Networks Teach Well Again相关的知识,希望对你有一定的参考价值。
Neurips 2022
研究内容是:为什么大神经网络不一定教地好,有没有什么简单的办法让大神经网络教地好?
1 知识蒸馏
1.1 原理
- 将大(强)模型的能力传递给小(弱)模型
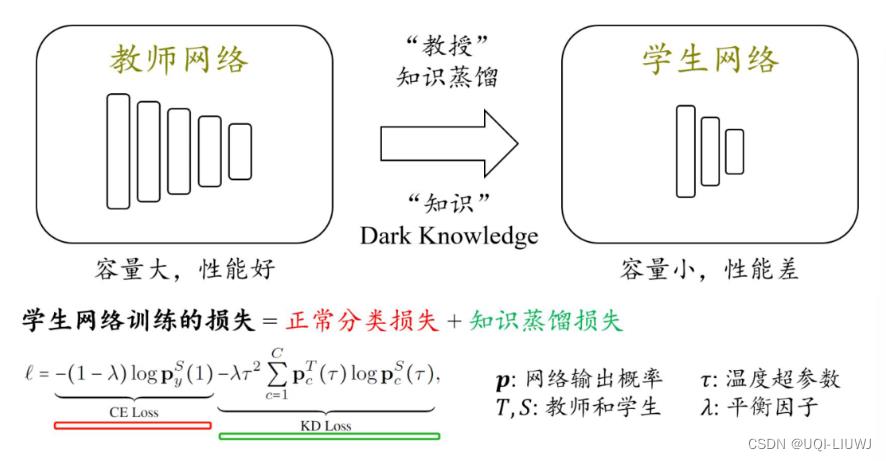
1.2 基本步骤
- 在训练集上训练一个大教师网络,或者拿现有模型的当作教师网络
- 使用1.1所述的损失去指导学生网络进行训练。
- 损失包括两部分:
- 正常分类损失
- hard-label
- 知识蒸馏损失
- soft-label
- 引入的目的是因为学生直接学习 hard-label 太困难了,因此期望学生能够模仿教师的 soft 输出,从而把握类别之间的相似度,从而更好地学习。
- 正常分类损失
- 损失包括两部分:
1.3 知识蒸馏中Temperature的影响
- temperature是KD Loss(知识蒸馏损失)中的τ
- 他影响了教师网络输出中各个label的取值概率
- 如果τ很小,那么教师的输出结果像 hard-label,导致和正常分类损失相比没有什么额外的信息
- 如果τ很大,那么教师的输出结果像 uniform-label,类别之间的差异性就没有了,仅仅起到了一个 label smoothing 的作用。
- 机器学习笔记 temperature+Softmax_softmax temperature_UQI-LIUWJ的博客-CSDN博客

2 大神经网络网络作为知识蒸馏的教师网络,效果不一定好
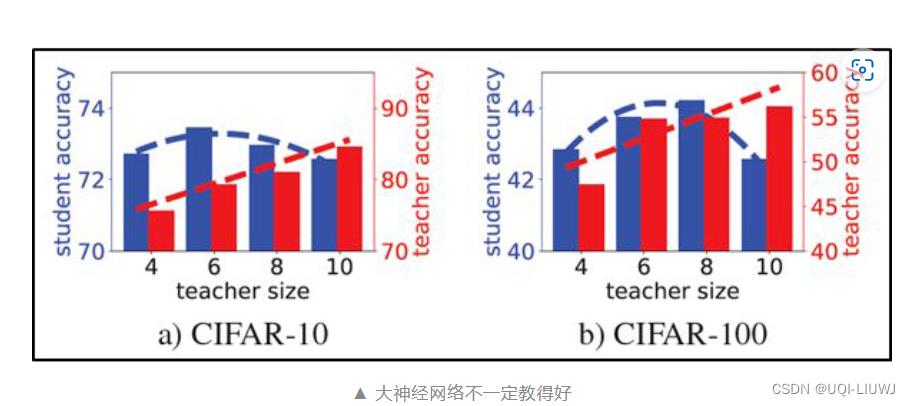
- 随着 teacher size 逐渐变大,教师的准确率越来越高,但是其教的学生的准确率先变高再变低
2.1 大教师神经网络和小教师神经网络的不同
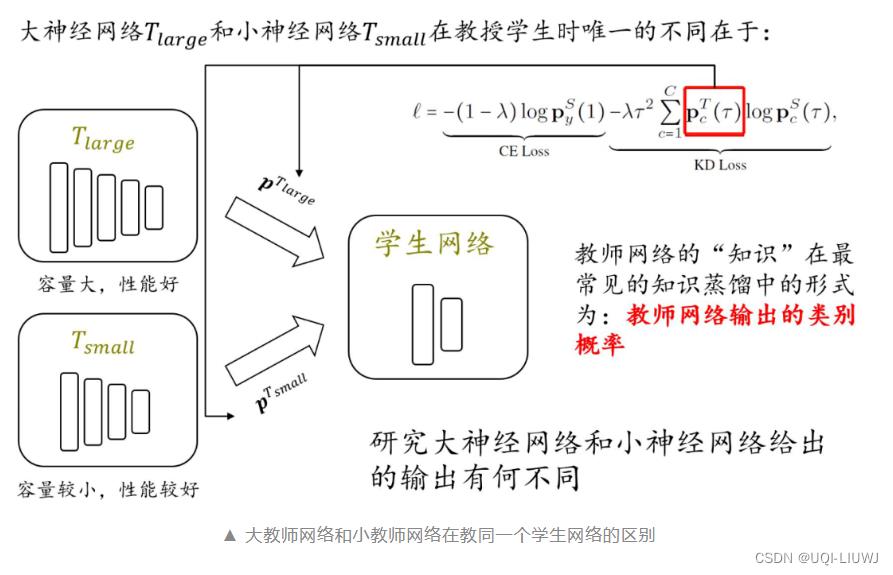
- 在遍历所有可能温度系数的情况下,相比较于大教师网络,小教师网络更容易给出质量更好的指导信息(
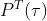 )
)
2.2 大教师神经网络更易给出置信度高的预测
- 大教师神经网络给出置信度更高的预测,包括两个方面
- 正确类别的logit更大
- 错误类别的logits之间差距小
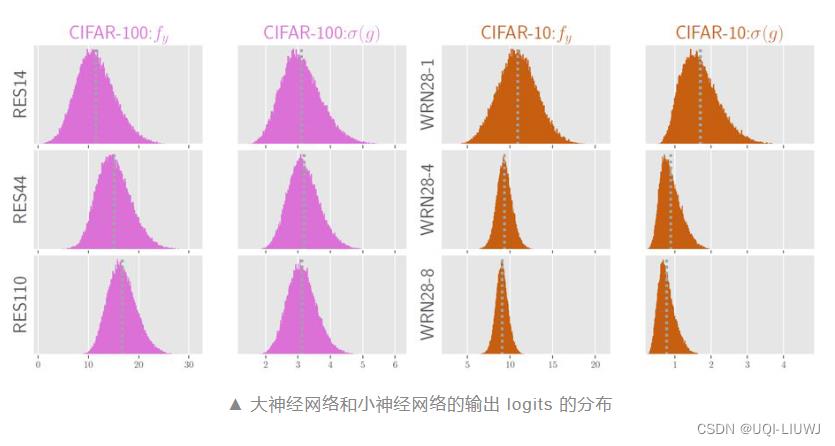
- 论文在 CIFAR-100 和 CIFAR-10 上训练 ResNet14/44/110 和 WRN28-1/4/8
- fy表示正确类别的logit
- σ(g)表示错误类别logits之间的方差
- 在 CIFAR-100 上,ResNet110 很明显给出了更大的fy
- 在 CIFAR-10 上 WideResNet28-8 给出了更小的σ(g)
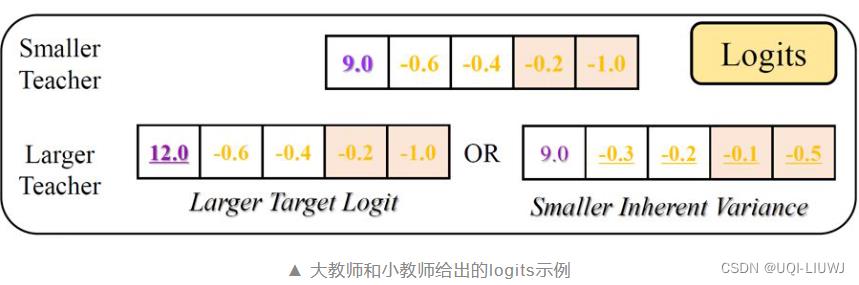
- 大神经网络更为置信
- ——>target logit更大
- 那么无论用什么温度系数τ对教师的输出进行 softmax,最后得到的
 都为 one-hot 形式;
都为 one-hot 形式;
- 那么无论用什么温度系数τ对教师的输出进行 softmax,最后得到的
- ——>(或者)错误的logits之间差距更小
- 假设都一样,那么无论用什么温度系数τ对教师的输出进行 softmax,最后得到的在错误类别之间都无法提供差异化信息。
- 假设都一样,那么无论用什么温度系数τ对教师的输出进行 softmax,最后得到的
- ——>target logit更大
- 大神经网络更为置信
3 知识蒸馏分解
- 通过上一小节可以知道
- 大教师网络的高置信度导致:无论在什么样子的温度系数τ下,其给出的指导信息()都很难具有足够有效的信息
- 大教师网络的高置信度导致:无论在什么样子的温度系数τ下,其给出的指导信息(
3.1 符号说明

SF表示softmax
- 作者理论分析了以下结论
- (1)随着τ的不断增大,得到的 p的熵越来越大,即越来越均匀。
- 也即,随着τ的不断增大,得到的p各元素之间的方差越来越小
- (2)在正确类别的logit是最大的的情况下,随着τ的不断增大,错误类别的平均概率e(q)会逐渐增大
- (3)
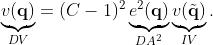
- Inherent Variance:错误类别 logits 经过 softmax 之后得到的类别概率分布的方差
- Derived Average:所有类别 logits 经过 softmax 之后得到的错误类别概率的平均值
- Derived Variance:所有类别 logits 经过 softmax 之后得到的错误类别概率的方差
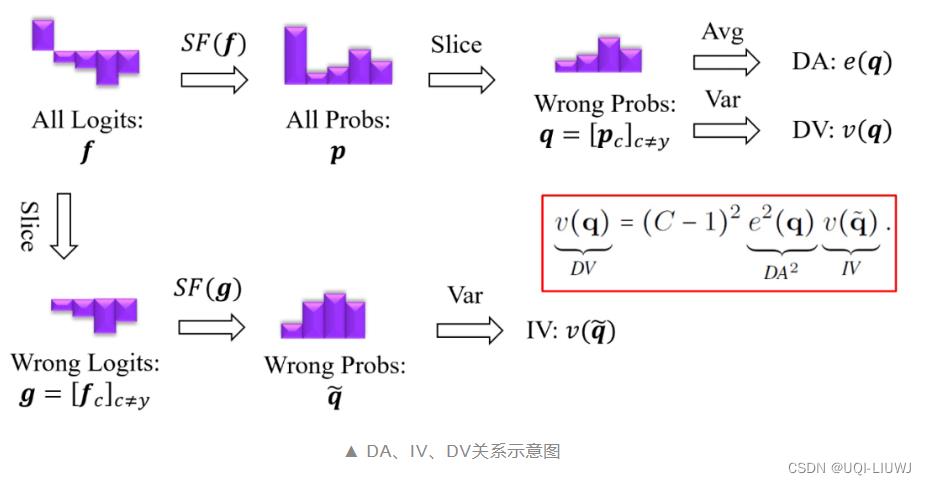
- (1)随着τ的不断增大,得到的 p的熵越来越大,即越来越均匀。
3.2 知识蒸馏分解
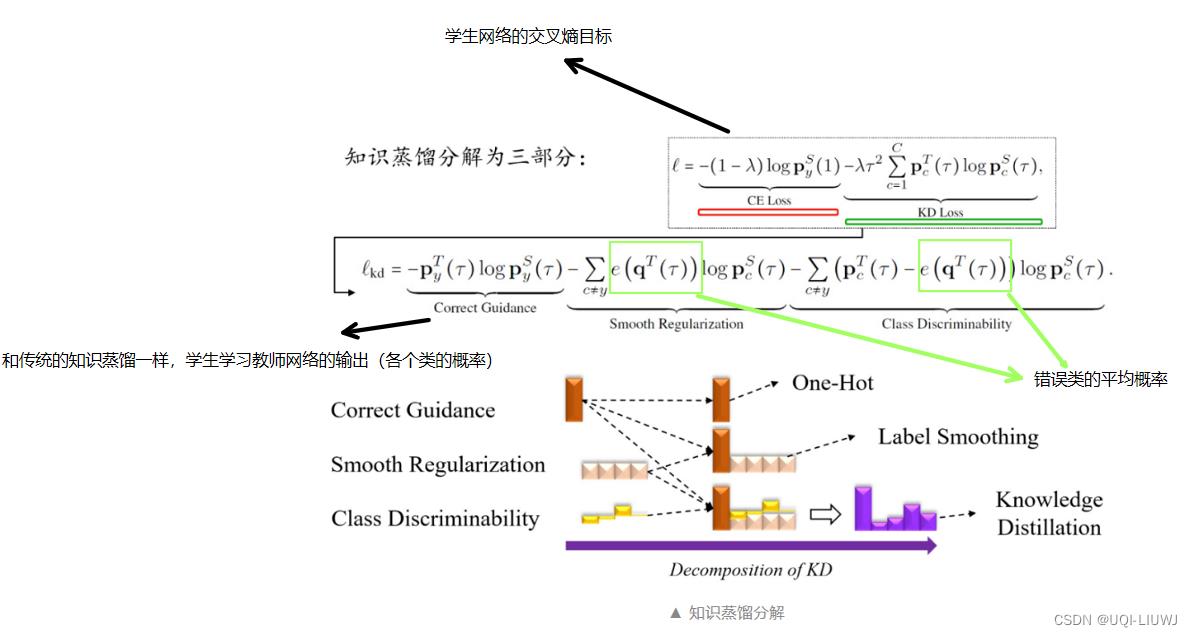
- Correct Guidance,类似于 hard-label 的 one-hot 标签
- Smooth Regularization,错误类别的平均概率值,类似于 label smoothing
- Class Discriminability,错误类别之间的差异,可以用方差来度量,错误类别差异越大,教师提供的指导信息越多!
3.3 不对称的temperature 缩放策略
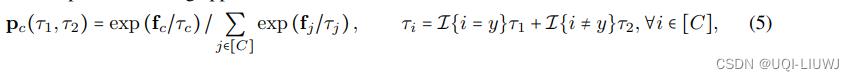
- τ1>τ2>0
- τ1大——>e(q)大(2)——>DA大(3)
- τ2小——>p各元素之间的方差越来越大(1)——>IV大(3)
- ——>DV大(3)
- ——>错误类别的概率“错落有致”
参考内容:NeurIPS 2022 | 知识蒸馏中如何让“大教师网络”也教得好? (qq.com)
以上是关于论文笔记:Asymmetric Temperature Scaling Makes Larger Networks Teach Well Again的主要内容,如果未能解决你的问题,请参考以下文章