K8S学习圣经6:资源控制+SpringCloud动态扩容原理和实操
Posted 疯狂创客圈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了K8S学习圣经6:资源控制+SpringCloud动态扩容原理和实操相关的知识,希望对你有一定的参考价值。
文章很长,持续更新,建议收藏起来,慢慢读!疯狂创客圈总目录 博客园版 为您奉上珍贵的学习资源 :
免费赠送 :《尼恩Java面试宝典》 持续更新+ 史上最全 + 面试必备 2000页+ 面试必备 + 大厂必备 +涨薪必备
免费赠送 :《尼恩技术圣经+高并发系列PDF》 ,帮你 实现技术自由,完成职业升级, 薪酬猛涨!加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷1)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷2)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷3)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 资源宝库: Java 必备 百度网盘资源大合集 价值>10000元 加尼恩领取
Kubernets学习圣经: 底层原理和实操
说在前面:
现在拿到offer超级难,甚至连面试电话,一个都搞不到。
尼恩的技术社群中(50+),很多小伙伴凭借 “左手云原生+右手大数据”的绝活,拿到了offer,并且是非常优质的offer,据说年终奖都足足18个月。
而云原生的核心组件是 K8S,但是 K8S 又很难。从Java高薪岗位和就业岗位来看,K8S 现在对于 高级工程师, 架构师,越来越重要,下面是一个高薪Java岗位的K8S技能要求:

市面上很多的pdf和视频,都是从技术角度来说的,讲的晦涩难懂。
在这里,尼恩从架构师视角出发,基于自己的尼恩Java 架构师知识体系和知识宇宙,对K8S的核心原理做一个宏观的介绍, 一共十二部分, 组成一本《K8S学习圣经》
《K8S学习圣经》 带大家穿透K8S,实现K8S自由,让大家不迷路。

《K8S学习圣经》的组成
- 第一部分:云原生(Cloud Native)的原理与演进
- 第二部分:穿透K8S的8大宏观架构
- 第三部分:最小化K8s环境实操
- 第四部分:Kubernetes 基本概念
- 第五部分:Kubernetes 工作负载
- 第六部分:Kubernetes 的资源控制
- 第七部分: SVC负载均衡底层原理
- 第八部分: Ingress底层原理和实操
- 第九部分: 蓝绿发布、金丝雀发布、滚动发布、A/B测试 实操
- 第十部分: 服务网格Service Mesh 宏观架构模式和实操
- 第十一部分: 使用K8S+Harber 手动部署 Springboot 应用
- 第十二部分: CICD核心实操 :jenkins流水线部署springboot应用到k8s集群
- 第十三部分: k8s springboot 生产实践(高可用部署、基于qps动态扩缩容、prometheus监控)
- 第十四部分:k8s生产环境容器内部JVM参数配置解析及优化
米饭要一口一口的吃,不能急。
结合《K8S学习圣经》,尼恩从架构师视角出发,左手云原生+右手大数据 +SpringCloud Alibaba 微服务 核心原理做一个宏观的介绍。由于内容确实太多, 所以写多个pdf 电子书:
(1) 《 Docker 学习圣经 》PDF (V1已经完成)
(2) 《 SpringCloud Alibaba 微服务 学习圣经 》PDF (V1已经完成)
(3) 《 K8S 学习圣经 》PDF (coding…)
(4) 《 flink + hbase 学习圣经 》PDF (planning …)
以上学习圣经,并且后续会持续升级,从V1版本一直迭代发布。 就像咱们的《 尼恩 Java 面试宝典 》一样, 已经迭代到V60啦。
40岁老架构师尼恩的掏心窝: 通过一系列的学习圣经,带大家穿透“左手云原生+右手大数据 +SpringCloud Alibaba 微服务“ ,实现技术 自由 ,走向颠覆人生,让大家不迷路。
本PDF 《K8S 学习圣经》完整版PDF的 V1版本,后面会持续迭代和升级。供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
以上学习圣经的 基础知识是 尼恩的 《高并发三部曲》,建议在看 学习圣经之前,一定把尼恩的《 Java高并发三部曲 》过一遍,切记,切记。
本部分目录(第六部分)
第六部分:Kubernetes 的资源控制
动态的扩容缩容的重要性
在微服务应用中,在高并发场景下, 需要对 springboot、SpringCloud 、nginx 应用进行动态的扩容缩容
- 当微服务的性能不足以支撑庞大的访问量,可以动态扩容
- 而当访问量减少时,过多的微服务实例会白白占用服务器资源,造成资源浪费时,可以动态缩容。
所以动态的扩容缩容 ,是高并发应用的标配。
但是,社群中很多的小伙伴,不懂动态的扩容缩容 底层原理。
没有做过 动态的扩容缩容实操。因此,很容易错过很多 高质量的 offer。
目前业界主流的方案,是基于K8S实现 动态的扩容缩容。
这一个部分, 尼恩带着大家,从Deployment 资源对象 入手,一步一步,带大家最终,完成基于K8S实现 动态的扩容缩容实操。
1:Deployment 资源对象
为了更好地解决Pod编排的问题,k8s在V1.2版本开始,引入了deployment资源对象,
注意:
deployment资源并不直接管理pod,而是通过管理replicaset来间接管理pod,
简单的说:deployment管理replicaset,而 replicaset管理pod。
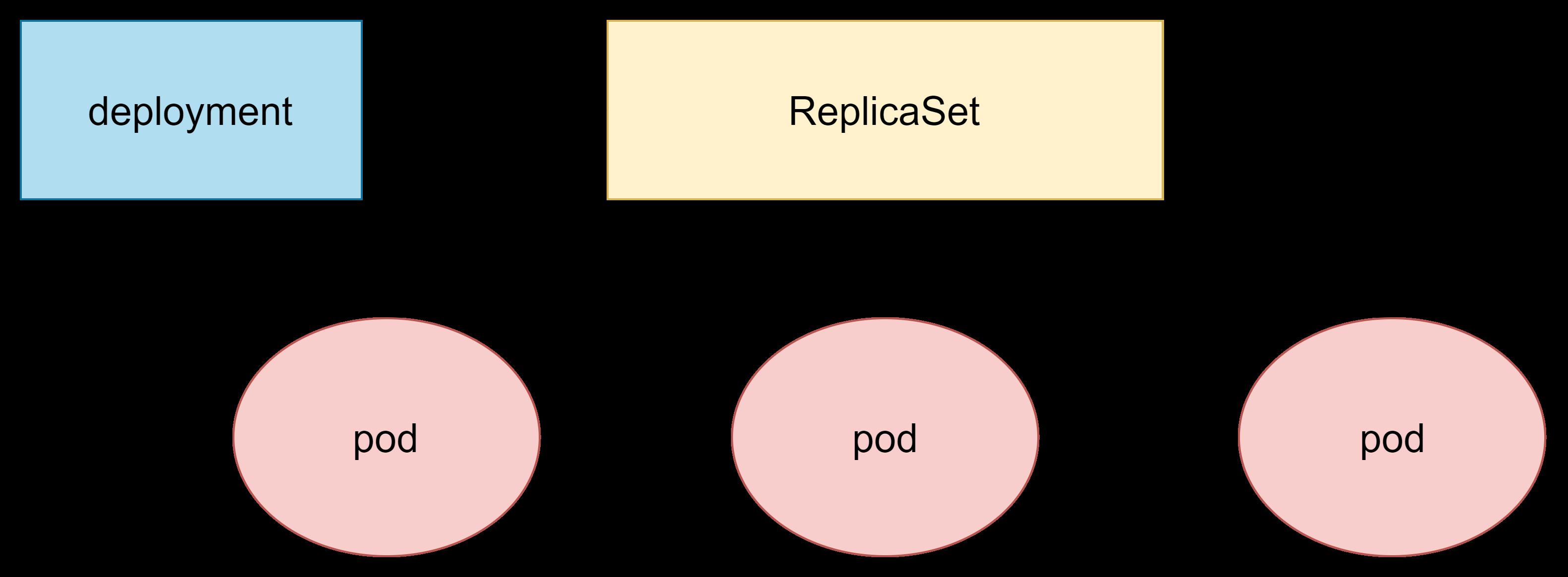
deployment的主要功能有下面几个:
- 支持replicaset的所有功能
- 支持发布的停止、继续
- 支持版本的滚动更新和版本回退
- 扩容和缩容
所以: 我们部署一个应用一般不直接写Pod,而是部署一个Deployment
Deployment 使用场景:Deployment 主要针对无状态服务,有状态服务使用 StatefulSet. 那么,什么是无状态服务, 什么是有状态服务, 这个咱们稍微晚点介绍。
Deploy编写规约
https://kubernetes.io/zh/docs/concepts/workloads/controllers/deployment/#writing-a-deployment-spec
Deployment的创建
编写一个Deployment的yaml赋予Pod自愈和故障转移能力。 基本格式如下:
.metadata.name指定deploy名字replicas指定副本数量selector指定匹配的Pod模板。template声明一个Pod模板
下面是一个例子 deployment-demo.yml
apiVersion: apps/v1 #版本号
kind: Deployment #类型
metadata: #元数据
name: demo-deployment #rs名称
namespace: default #所属命名空间
labels: #标签
controller: deploy
spec: #详情描述
replicas: 3 #副本数量
revisionHistoryLimit: 5 #保留历史版本,默认是10
paused: false #暂停部署,默认是false
progressDeadlineSeconds: 600 #部署超时时间(s),默认是600
strategy: #策略
type: RollingUpdate #滚动更新策略
rollingUpdate: #滚动更新
maxSurge: 1 #最大额外可以存在的副本数,可以为百分比,也可以为整数
maxUnavailable: 1 #最大不可用状态的pod的最大值,可以为百分比,也可以为整数
selector: #选择器,通过它指定该控制器管理哪些pod
matchLabels: #Labels匹配规则
app: nginx-gateway
matchExpressions: #Expression匹配规则
- key: app, operator: In, values: [nginx-gateway]
template: #模板,当副本数量不足时,会根据下面的模板创建pod副本
metadata:
labels:
app: nginx-gateway
spec:
containers:
- name: nginx-gateway
image: harbor.daemon.io/demo/nginx-gateway:1.0-SNAPSHOT
ports:
- containerPort: 80
通过 下面的命令进行操作:
# 创建 deployment 资源对象, 进一步创建 rs对象, pod 对象
kubectl apply -f deployment-demo.yml
# 查看 deployment 资源对象
kubectl get deployments
# 查看 ReplicaSet 资源对象
kubectl get ReplicaSet
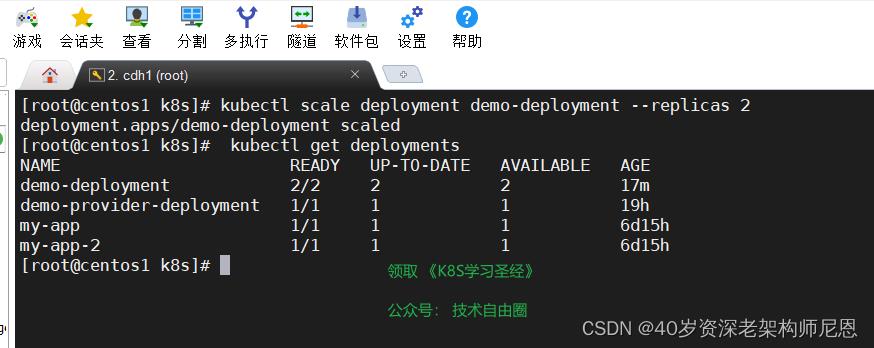
使用kubectl get deployments 查看 deployment 资源对象
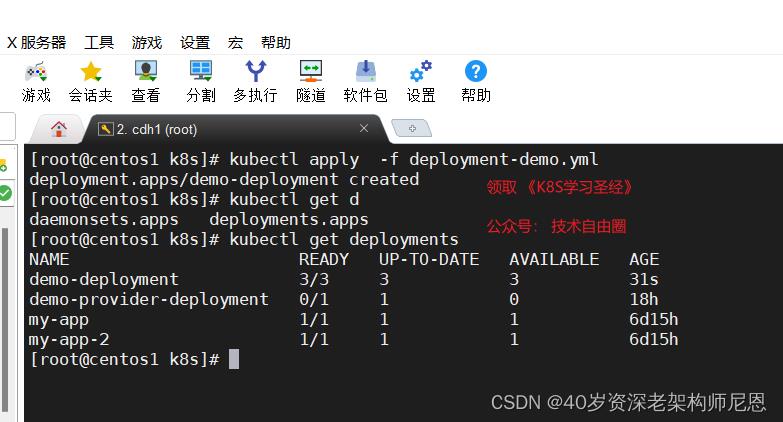
在检查集群中的 Deployment 时,所显示的字段有:
- NAME 列出了集群中 Deployment 的名称。
- READY 显示应用程序的可用的 副本 数。显示的模式是“就绪个数/期望个数”。
- UP-TO-DATE 显示为了达到期望状态已经更新的副本数。
- AVAILABLE 显示应用可供用户使用的副本数。
- AGE 显示应用程序运行的时间。
使用 kubectl get ReplicaSet 查看 ReplicaSet 资源对象
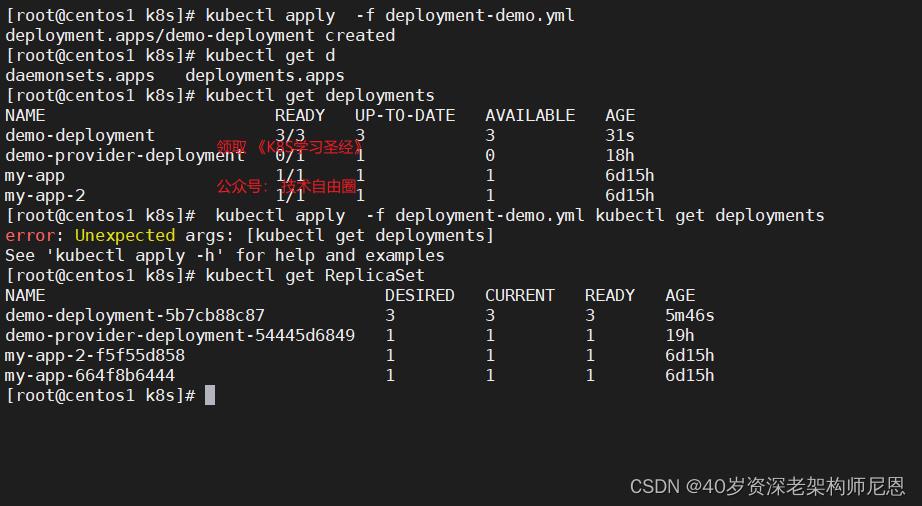
ReplicaSet 输出中包含以下字段:
- NAME 列出名字空间中 ReplicaSet 的名称;
- DESIRED 显示应用的期望副本个数,即在创建 Deployment 时所定义的值。 此为期望状态;
- CURRENT 显示当前运行状态中的副本个数;
- READY 显示应用中有多少副本可以为用户提供服务;
- AGE 显示应用已经运行的时间长度。
注意:
ReplicaSet 的名称始终被格式化为 [Deployment名称]-[随机字符串] 。
其中的随机字符串是使用 pod-template-hash 作为种子随机生成的。
Deployment 资源、replicaset资源、Pod资源 三者之间的关系
一个Deploy产生三个
- Deployment资源
- replicaset资源
- Pod资源
Deployment控制RS,RS控制Pod的副本数
ReplicaSet: 只提供了副本数量的控制功能
Deployment: 每部署一个新版本就会创建一个新的副本集,利用他记录状态
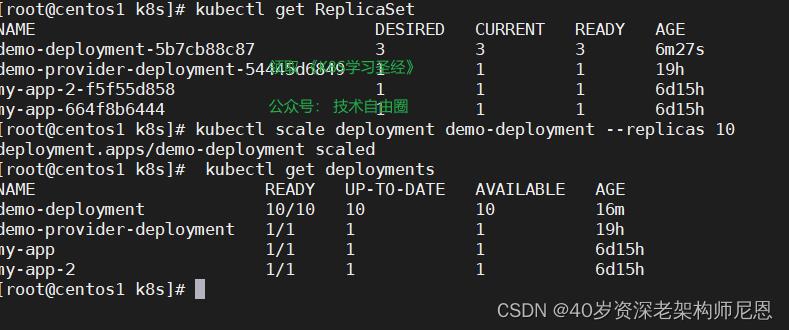
Deployment 基本操作
副本扩容
原本定义3个副本,现在扩容到10个副本
kubectl scale deployment demo-deployment --replicas 10
副本缩容
原本定义3个副本,现在缩容到2个副本
kubectl scale deployment demo-deployment --replicas 2
Deployment 更新机制
仅当 Deployment Pod 模板(即 .spec.template )发生改变时,例如模板的标签或容器镜像被更新, 就会触发 Deployment 滚动更新。 其他更新(如对 Deployment 执行扩缩容的操作)不会触发滚动更新动作。
滚动更新 原理:
创建新的rs,准备就绪后,替换旧的rs(此时不会删除,因为revisionHistoryLimit 指定了保留几个版本)
准备:升级镜像
升级一下 nginx 的镜像,并且导入
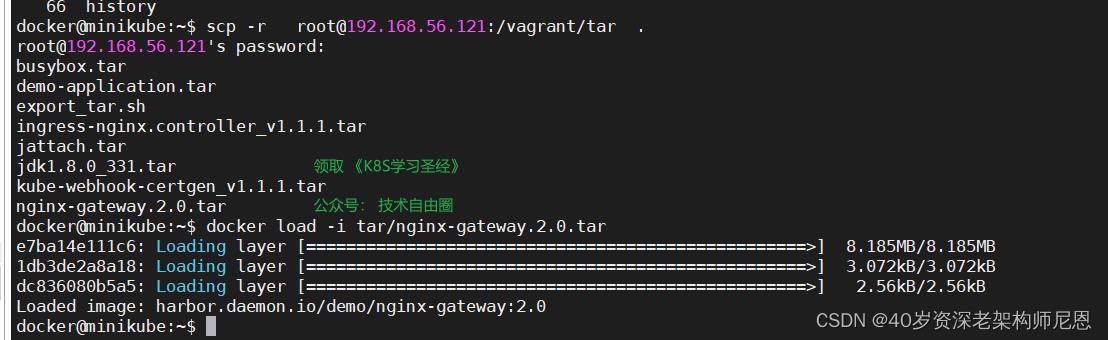
可以使用命令,将 镜像从1.0更新到2.0
kubectl set image deployment/demo-deployment nginx-gateway=harbor.daemon.io/demo/nginx-gateway:2.0
在线修改yaml
也可以使用 使用edit命令 在线修改yaml
kubectl edit deployment/demo-deployment
deployment "nginx-deployment" edited
滚动机制相关的命令
- 新创建: 当 Deployment controller 观测到有新的 deployment 被创建时,会直接创建出一个新的 ReplicaSet 来做这件事。
- 变更: 当更新了一个的已存在并正在进行中的 Deployment,每次更新 Deployment都会创建一个新的 ReplicaSet并扩容它,同时回滚之前扩容的 ReplicaSet ,将它添加到旧的 ReplicaSet 列表中,开始缩容。
查看可用的回滚版本
kubectl rollout history deployment demo-deployment
查看滚动状态
kubectl rollout status deployments demo-deployment
监控更新过程
kubectl get deployments demo-deployment --watch
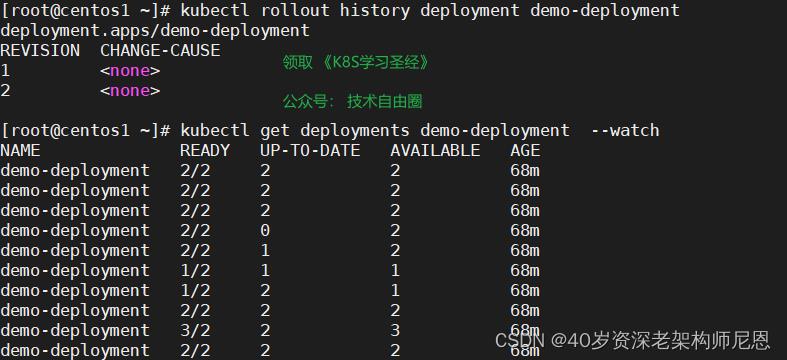
回滚到上一个步骤
kubectl rollout undo deployment/demo-deployment
暂停和恢复
在暂停状态下的更新操作,多次更改,只会触发一次 rolling 记录
kubectl rollout pause deployment/nginx-deployment
回滚策略
记录保留
.spec.revisionHistoryLimit默认设置保留数量为 2。
在 Deployment 中设置来指定保留多少旧的 ReplicaSet。余下的将在后台被当作垃圾收集。
滚动更新数量
.spec.strategy指定新的Pod替换旧的Pod的策略
使用Deployment 进行灰度发布
使用Deployment 进行金丝雀发布(灰度发布)、蓝绿发布、滚动发布 的原理与实操,
请参见《K8S学习圣经》的第九部分。

2:副本资源 RC、副本集RS 资源对象
RC: ReplicasController 副本控制器
RS:ReplicasSet:副本集;
Deployment【滚动更新特性】默认的 控制器的是ReplicasSet 副本集
实际上 RS 和 RC 的功能基本一致,目前唯一的一个区别就是 :
RC 只支持基于等式的 selector(env=dev 或 environment!=qa),但 RS 还支持基于表达式的 selector(version in (v1.0, v2.0)), RS对复杂的运维管理就非常方便了。
虽然ReplicasSet强大,但是我们也不直接写RS;都是直接写Deployment的,Deployment会自动产生RS。Deployment每次的滚动更新都会产生新的RS。
接下来, 咱们还是从RC开始介绍吧。
RC(Replication Controller)
Replication Controller 简称 RC,RC 是 Kubernetes 系统中的核心概念之一,简单来说,RC 可以保证在任意时间运行 Pod 的副本数量,能够保证 Pod 总是可用的。
如果实际 Pod 数量比指定的多,那就干掉多余的,
如果实际数量比指定的少就新启动一些 Pod,当 Pod 失败、被删除或者挂掉后,RC 都会去自动创建新的 Pod 来保证副本数量,所以生产场景中,哪怕只有一个pod,也应该使用 RC 来管理我们的 Pod。
就是由于RC的副本控制机制,哪怕运行 Pod 的节点挂了,RC 检测到 Pod 失败了,就会去合适的节点重新启动一个 Pod 就行,不需要我们手动去新建一个 Pod 了。
下面我们使用 RC 来管理一个 Nginx 的 Pod,YAML 文件如下:
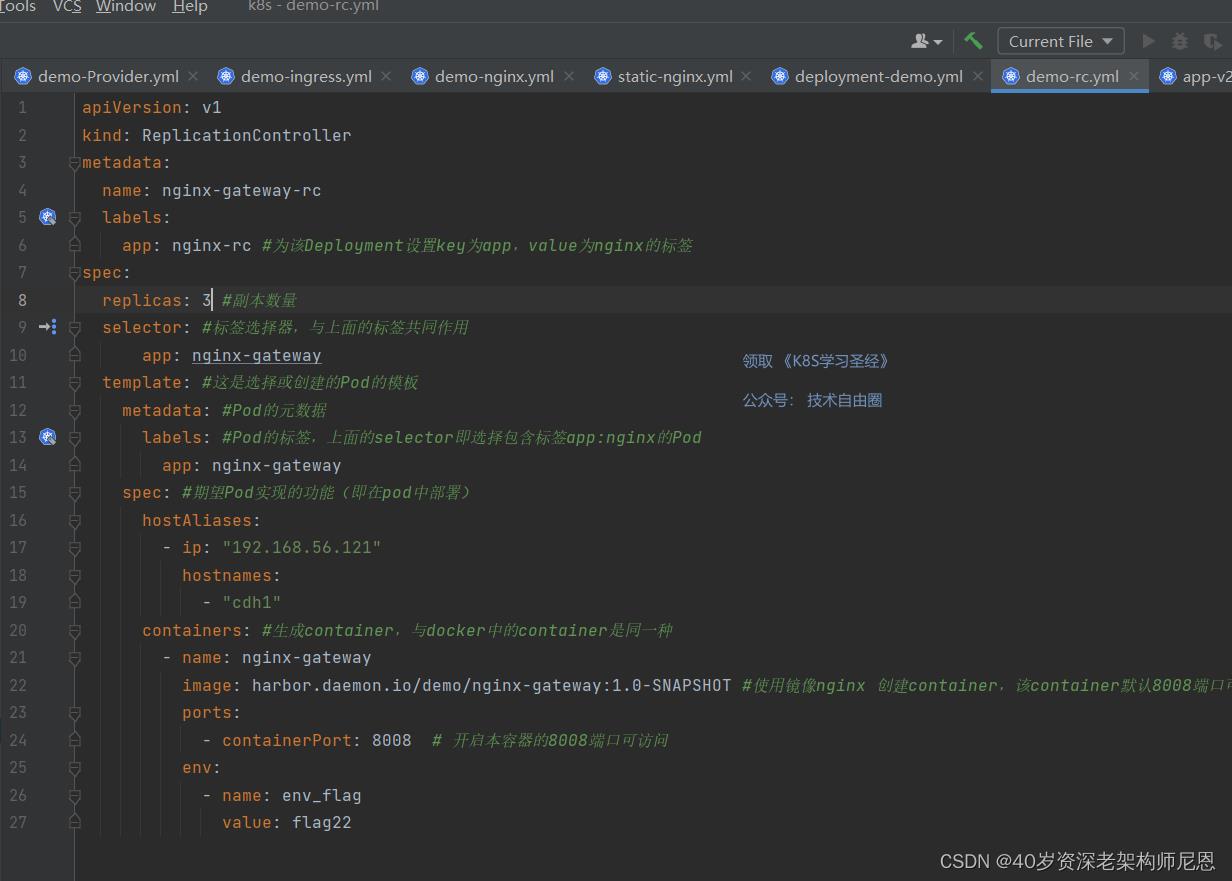
上面的 YAML 文件相对于我们之前的 Pod 的格式:
- kind:资源对象的种类,这里创建的是 RC
- spec.replicas: 指定 Pod 的副本数量,默认为 1,此处为 2
- spec.selector: RC 通过该属性,来筛选要控制的 Pod,可以理解为筛选对应标签
- spec.template: 这里就是我们之前的 Pod 的定义的模块,比如容器镜像、名称、端口、环境变量
- spec.template.metadata.labels: Pod的标签,注意这里的 Pod 的 labels 要和 spec.selector 相同,这样 RC 就可以来控制当前这个 Pod 了。
这个 YAML 文件中的意思就是定义了一个 RC 资源对象,它的名字叫 nginx-gateway-rc,保证一直会有 3个 Pod 运行。
注意 spec.selector 和 spec.template.metadata.labels 这两个字段必须相同,否则会创建失败的,
当然我们也可以不写 spec.selector,这样就默认与 Pod 模板中的 metadata.labels 相同了。
所以为了避免不必要的错误的话,不写为好。
然后我们来创建上面的 RC 对象(保存为 nginx-rc-demo.yaml):
kubectl create -f demo-rc.yaml
或者
kubectl apply -f ndemo-rc.yaml
查看 RC:
kubectl get rc
查看详细的描述信息:
kubectl describe rc nginx-gateway-rc
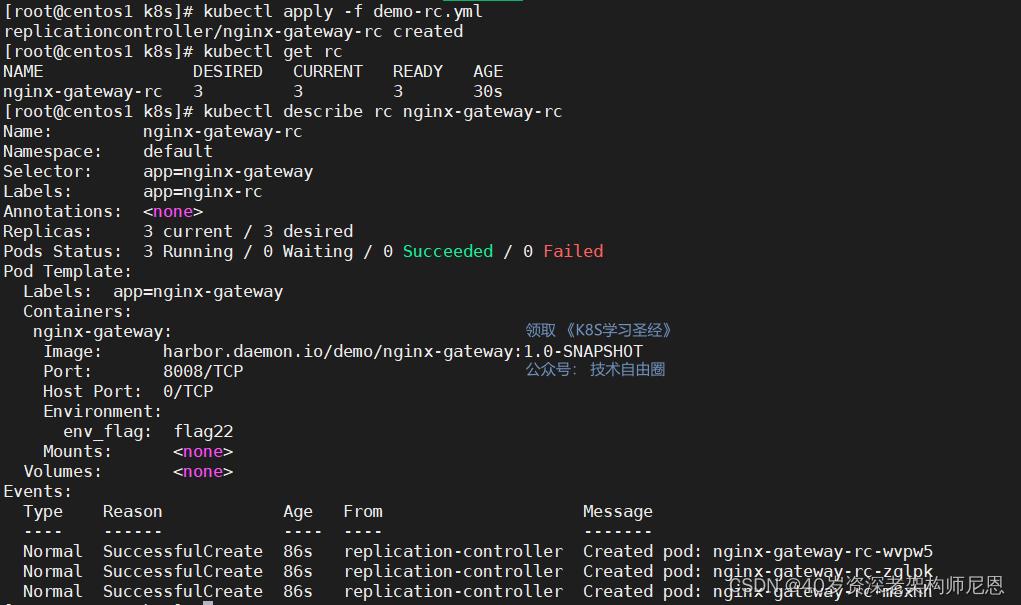
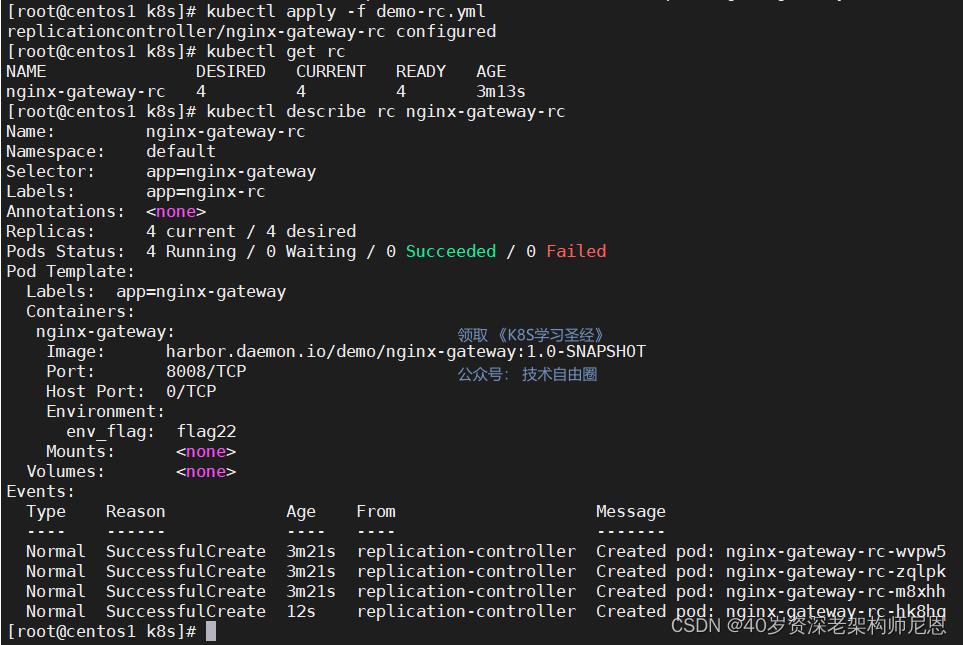
接下来我们再通过 RC 来修改下 Pod 的副本数量为 4:
kubectl apply -f nginx-rc-demo.yaml
或者执行下面的命令编辑 RC 也可以
kubectl edit rc nginx-rc-demo
RS(Replication Set)
Replication Set 简称 RS,随着 Kubernetes 的高速发展,官方已经推荐我们使用 RS 和 Deployment 来代替 RC 了,实际上 RS 和 RC 的功能基本一致,目前唯一的一个区别就是 RC 只支持基于等式的 selector(env=dev 或 environment!=qa),但 RS 还支持基于集合的 selector(version in (v1.0, v2.0)),这对复杂的运维管理就非常方便了。
kubectl 命令行工具中关于 RC 的大部分命令同样适用于我们的 RS 资源对象。
不过我们也很少会去单独使用 RS,它主要被 Deployment 这个更加高层的资源对象使用,除非用户需要自定义升级功能或根本不需要升级 Pod,在一般情况下,我们推荐使用 Deployment 而不直接使用 Replica Set。
ReplicatSet的三个部分
RS 资源对象的创建跟 RC 的创建方法大同小异。
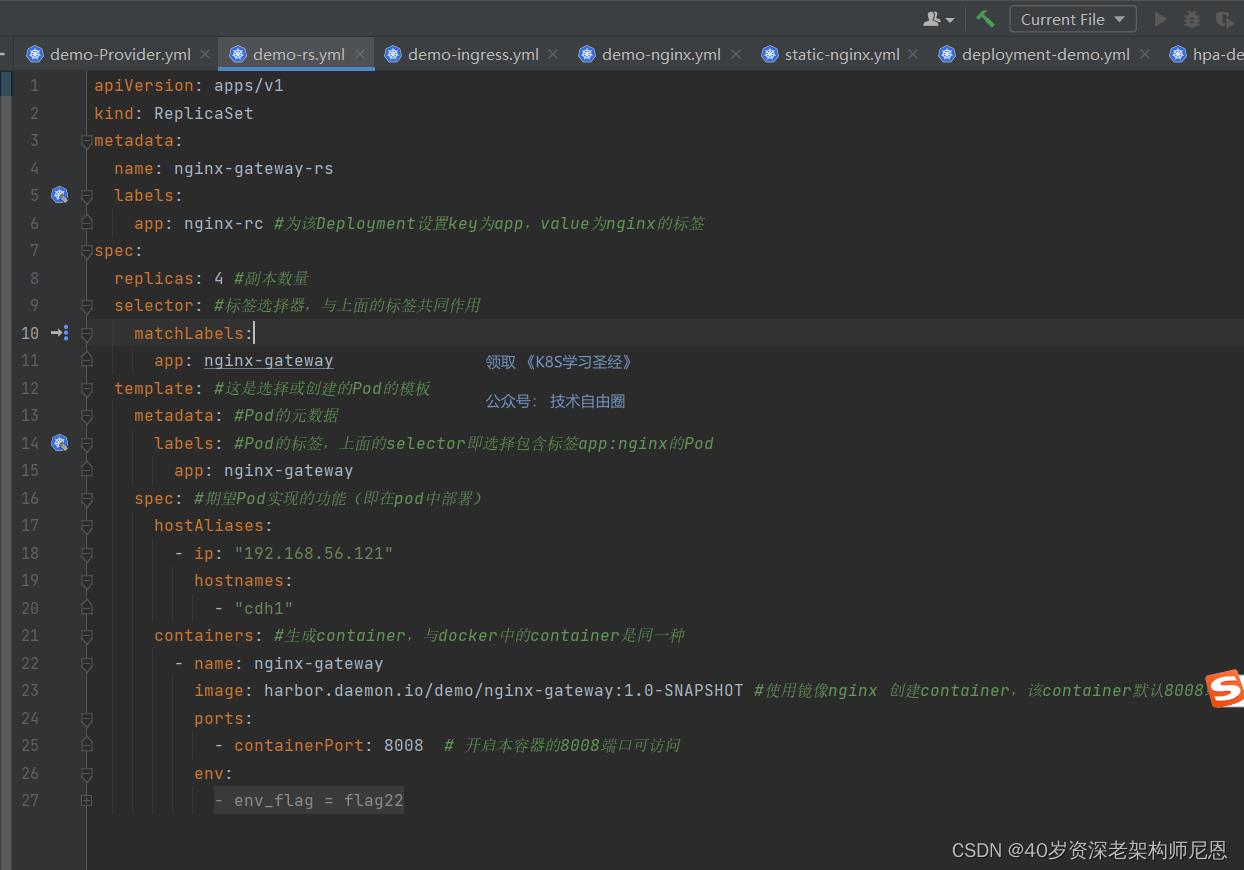
ReplicaSet 需要 apiVersion、kind 和 metadata 字段。
对于 ReplicaSet 而言,其 kind 始终是 ReplicaSet。
然后,ReplicaSet 也需要 .spec 部分。.spec 部分分为replicas 副本数、selector 选择器(选择算符)、Pod模板三个部分:
(1)一个用来标明应该维护的副本个数的数值、
(2)一个用来识别可获得的 Pod 的集合的选择算符、
(3)一个用来指定应该创建新 Pod 以满足副本个数条件时要使用的 Pod 模板。
replicas
你可以通过设置 .spec.replicas 来指定要同时运行的 Pod 个数。 如果实际的pod数量与预期不符合,ReplicaSet 创建、删除 Pod 以与此值匹配。每个 ReplicaSet 都通过根据需要创建和删除 Pod 以使得副本个数达到期望值, 进而实现Pod副本管理价值。
如果你没有指定 .spec.replicas,那么默认值为 1。
当 ReplicaSet 需要创建新的 Pod 时,会使用所提供的 Pod 模板。
selector 选择器
.spec.selector 字段是一个标签选择算符,这些是用来标识要被获取的 Pod 的标签。
在签名的 frontend.yaml 示例中,选择算符为:
matchLabels:
tier: frontend
在 ReplicaSet 中,.spec.template.metadata.labels 的值必须与 spec.selector 值相匹配,否则该配置会被 API 拒绝。
Pod 模板
.spec.template 是一个 Pod 模板, 要求设置标签。
在 demo-rs.yaml 示例中,我们指定了标签 app: nginx-gateway。
对于模板的重启策略 字段,.spec.template.spec.restartPolicy,唯一允许的取值是 Always,这也是默认值.
RS扩容缩容
两种方式:
(1)直接修改 replicaset.yaml 文件来扩容缩容
(2)通过 kubectl 命令来扩容缩容
方式一:直接修改 replicaset.yaml 文件来更新:
通过更新 .spec.replicas 字段,ReplicaSet 可以被轻松地进行扩缩。
ReplicaSet 控制器能确保匹配标签选择器的数量的 Pod 是可用的。
方式二:通过 kubectl 命令来扩容缩容:
kubectl scale replicaset nginx-gateway-rs --replicas 5
kubectl scale replicaset nginx-gateway-rs --replicas 1

3:DaemonSet 守护集
DaemonSet 用途
DaemonSet用来确保每个node节点(或者指定部分节点)运行一个Pod副本,
这个副本随着node节点的加入而自动创建;若node节点被移除,Pod也将会被移除。
注意:默认master除外,master节点默认不会把Pod调度过去; DaemonSet 无需指定副本数量;因为默认给每个机器都部署一个
应用场景:
- 在每个节点上运行集群的存储守护进程,例如 glusterd、ceph
- 在每个 Node 上运行日志收集守护进程,例如fluentd、logstash
- 在每个 Node 上运行监控守护进程,例如 Prometheus Node
DaemonSet 组成结构详解
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: example
namespace: kube-system
#===========Pod模版部分===============
spec:
selector: #如果指定了 .spec.selector,必须与.spec.template.metadata.labels 相匹配
matchLabels:
name: example
#matchExpressions:这个可以自定义更加复杂的Selector
#key: value
#如果 matchLabels 和 matchExpressions 都指定,
#则两个结果之间为 AND 关系
template: # 必填字段
metadata:
labels:
name: example
#这里的labels 必须要和 .spec.selector相匹配,
#这个例子中,都是 name: example
#++++++++++++POD容器设置部分++++++++++++++
spec:
containers:
- name: fluentd-elasticsearch
image: k8s.gcr.io/fluentd-elasticsearch:1.20
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
调度节点的选择
一共分为三种方式选择调度节点:
- 方式一:nodeSelector 根据 Node label 调度指定节点
- 方式二:nodeAffinity 多种条件判断调度,支持集合操作
- 方式三:podAffinity 调度到可以满足Pod条件的节点上
方式一:nodeSelector方式
在了解亲和性之前,我们先来了解一个非常常用的调度方式:nodeSelector。
label 标签是 kubernetes 中一个非常重要的概念,用户可以非常灵活的利用 label 来管理集群中的资源,比如最常见的 Service 对象通过 label 去匹配 Pod 资源,而 Pod 的调度也可以根据节点的 label 来进行调度。
现在我们先给节点node打上标签
kubectl label nodes node-01 important=very
kubectl get nodes --show-labels
可以上面的 --show-labels 参数可以查看上述标签是否生效。
当节点被打上了相关标签后,在调度的时候就可以使用这些标签了,只需要在 Pod 的 spec 字段中添加 nodeSelector 字段,里面是我们需要被调度的节点的 label 标签,比如,下面的 Pod 我们要强制调度到 node-01 这个节点上去,我们就可以使用 nodeSelector 来表示了
指定调度到 important=very 的节点
spec:
nodeSelector:
important=very
方式二:nodeAffinity方式
亲和性又分成节点亲和性(nodeAffinity)和 Pod 亲和性(podAffinity)。
Affinity中文意思 ”亲和性” ,跟nodeSelect 类似,根据节点上的标签来调度 POD 在哪些节点上创建。
nodeAffinity 根据软策略和硬策略分为2种:
- 硬策略(requiredDuringSchedulingIgnoredDuringExecution)
requiredDuringSchedulingIgnoredDuringExecution 表示:必须满足条件 。
表示POD 必须部署到满足条件的节点上,如果没有满足条件的节点,就不停重试。
- 软策略(preferredDuringSchedulingIgnoredDuringExecution)
preferredDuringSchedulingIgnoredDuringExecution 表示:优选条件 。
表示 POD 优先部署到满足条件的节点上,如果没有满足条件的节点,就忽略这些条件,按照正常逻辑部署
硬策略、软策略中间的 IgnoredDuringExecution ,表示 POD 部署完成之后,如果节点标签发生了变化,不再满足POD指定的条件,POD也会继续运行
nodeAffinity在匹配label时,可选的操作符有:
- In label的值在某个列表中
- NotIn label的值不在某个列表中
- Exists 某个label存在
- DoesNotExist 某个label不存在
- Gt label的值大于某个值(字符串比较)
- Lt label的值小于某个值(字符串比较)
示例1
调度到包含标签 “metadata.name” 并且值为“demo-node” 的Node上,
apiVersion: v1
kind: Pod
metadata:
name: demo-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: metadata.name
operator: In
values:
- demo-node
requiredDuringSchedulingIgnoredDuringExecution 这个代表nodeAffinity 必须在每次调度的时候,必须予以考虑的 条件
示例2
调度到包含标签key1并且值为aaa或bbb的Node上,并且优选带有标签key2=ccc的Node(权重+1)
apiVersion: v1
kind: Pod
metadata:
name: example
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: key1
operator: In
values:
- aaa
- bbb
preferredDuringSchedulingIgnoredDuringExecution:
#可以设置多个优选条件,不同的优选条件可以设置不一样的权重
- weight: 1
preference:
matchExpressions:
- key: key2
operator: In
values:
- ccc
containers:
- name: with-node-affinity
image: harbor.daemon.io/demo/nginx-gateway:1.0-SNAPSHOT
在 nodeAffinity 的定义处,可以支持更加丰富的语法,比如operator: In(即:部分匹配)。
方式三:podAffinity方式
pod affinity是用来定义pod与pod间的亲和性,
所谓pod与pod的亲和性是指,pod更愿意和那个或那些pod在一起;
与之相反的也有pod更不愿意和那个或那些pod在一起,这种我们叫做pod anti affinity,即pod与pod间的反亲和性;
所谓在一起是指和对应pod在同一个位置,这个位置可以是按主机名划分,也可以按照区域划分,这样一来我们要定义pod和pod在一起或不在一起,定义位置就显得尤为重要,也是评判对应pod能够运行在哪里标准;
podAffinity 提供两种条件选择方式:
- 调度到某一条件的节点 podAffinity
- 不调度到某一条件的节点 podAntiAffinity
示例
- 如果一个 “ Node所在Zone中包含至少一个带有security=S1标签且运行中的Pod ” ,那么可以调度到该Node
- 不调度到“包含至少一个带有security=S2标签且运行中Pod”的Node上
apiVersion: v1
kind: Pod
metadata:
name: with-pod-affinity
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: failure-domain.beta.kubernetes.io/zone
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S2
topologyKey: kubernetes.io/hostname
containers:
- name: with-pod-affinity
image: gcr.io/google_containers/pause:2.0
Toleration
DaemonSet 还会给这个 Pod 自动加上另外一个与调度相关的字段,叫作 tolerations。
这个字段意味着这个 Pod,会“容忍”(Toleration)某些 Node 的“污点”(Taint)。
示例
apiVersion: v1
kind: Pod
metadata:
name: with-toleration
spec:
tolerations:
- key: node.kubernetes.io/unschedulable
operator: Exists
effect: NoSchedule
在正常情况下,被标记了 unschedulable“污点”的 Node,是不会有任何 Pod 被调度上去的(effect: NoSchedule)。
可是,DaemonSet 自动地给被管理的 Pod 加上了这个特殊的 Toleration,就使得这些 Pod 可以忽略这个限制,继而保证每个节点上都会被调度一个 Pod。
当然,如果这个节点有故障的话,这个 Pod 可能会启动失败,而 DaemonSet 则会始终尝试下去,直到 Pod 启动成功。
Toleration作用
通过这样一个 Toleration,调度器在调度这个 Pod 的时候,就会忽略当前节点上的“污点”,从而成功地将网络插件的 Agent 组件调度到这台机器上启动起来。
这种机制,正是我们在部署 Kubernetes 集群的时候,能够先部署 Kubernetes 本身、再部署网络插件的根本原因:因为当时我们所创建的 Weave 的 YAML,实际上就是一个 DaemonSet。
4:StatefulSet 有状态集
Deployment 应用我们一般称为无状态应用(stateless) ; StatefulSet 称为有状态副本集
无状态应用:网络 可以变,存储挂载 可以会变,启动 次序 可以会变。主要用途为 就是业务代码(Deployment)
有状态应用:网络或 不可以变,存储挂载或 不可以会变,或 启动 次序 不 可以会变。主要用途为 中间件 MySQL、Redis、MQ 等等
StatefulSet和Deployment一样,可以保证集群中运行指定个数的pod,也支持横向扩展。除此之外StatefulSet中每一个pod会分配一个内部标记用来区分。
尽管StatefulSet的pod确实是从同一个pod模板创建的,但每个pod都是不可互换的。
无论pod被怎样调度,它们的内部标记都不会改变。
StatefulSet的这个特性,使得其下管理的每个pod具有不同的网络标识(可以指定发送请求到具体哪个pod,这些pod之间也可以相互通信),也可以绑定不同的持久化存储(pod重新调度之后,和它绑定的存储仍然是原先那个)。
StatefulSet 使用场景:
对于有如下要求的应用程序,StatefulSet 非常适用:
- 稳定、唯一的网络标识(dnsname)【必须配合Service】
- 稳定的、持久的存储;【每个Pod始终对应各自的存储路径(PersistantVolumeClaimTemplate)】
- 有序的、优雅的部署和缩放。【按顺序地增加副本、减少副本,并在减少副本时执行清理】
- 有序的、自动的滚动更新。【按顺序自动地执行滚动更新】
如果一个应用程序不需要稳定的网络标识,也不需要稳定的存储,也不需要按顺序部署、删除、增加副本,就应该考虑使用 Deployment 这类无状态(stateless)的控制器
StatefulSet的一些限制和要求
- pod的存储必须使用StorageClass关联的PVC提供,或者由管理员预先创建好。
- 删除StatefulSet或者是减小StatefulSet的replicas,k8s不会自动删除和已终止运行的pod绑定的数据卷。这样做是为了保证数据安全。
- 为了确保StatefulSet管理的每个pod的网络标识不同,需要创建对应的headless service。
- 当StatefulSet被删除的时候,它不能保证所有被管理的pod都停止运行。因此,在删除StatefulSet之前,需要先将它scale到0个pod。
- pod管理策略使用默认的OrderedReady,进行滚动升级的时候可能会出现问题,需要手工修复。
StatefulSet示例
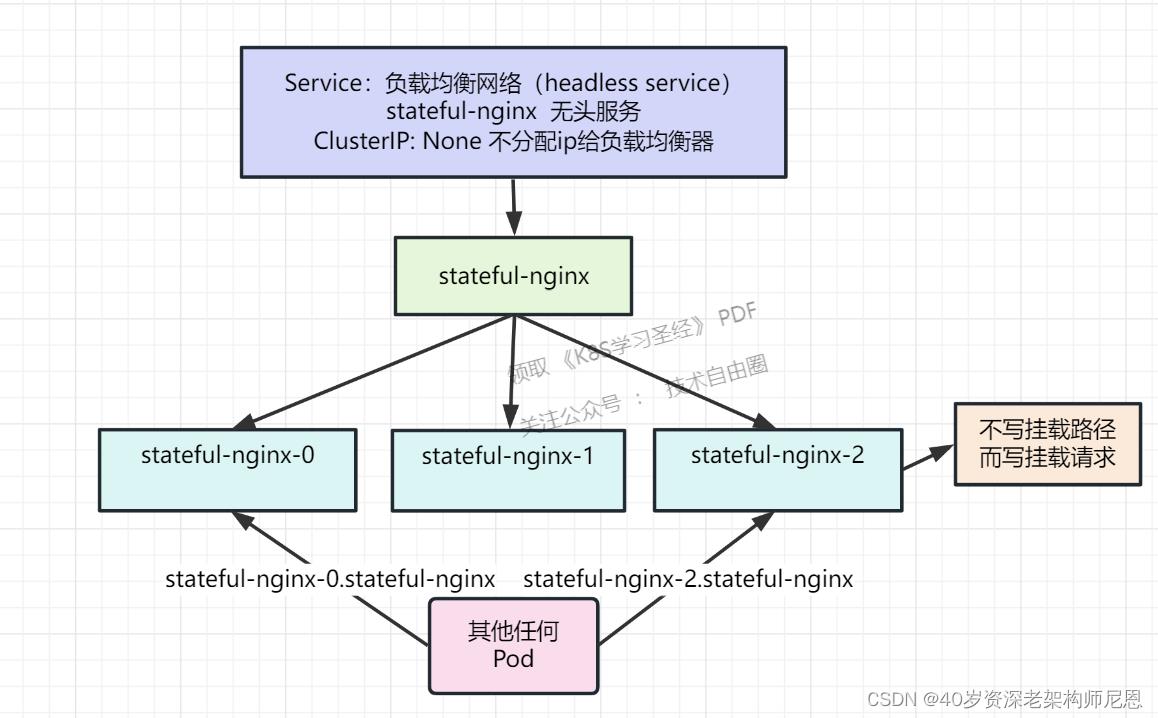
demo-stateful.yml配置文件
apiVersion: v1
kind: Service #定义一个 无头服务
metadata:
name: stateful-nginx
labels:
app: stateful-nginx
spec:
ports:
- port: 8008
name: web
targetPort: 8080
#NodePort:任意机器+NodePort都能访问,ClusterIP:集群内能用这个ip、service域名能访问,
#clusterIP: None;不要分配集群ip。headless;无头服务。稳定的域名
#Headless Services是一种特殊的service,其spec:clusterIP表示为None,这样在实际运行时就不会被分配ClusterIP。也被称为无头服务。
clusterIP: None
selector:
app: stateful-nginx
---
apiVersion: apps/v1
kind: StatefulSet #控制器。
metadata:
name: stateful-nginx
spec:
selector:
matchLabels:
app: stateful-nginx # has to match .spec.template.metadata.labels
serviceName: "stateful-nginx" #这里一定注意,必须提前有个service名字叫这个的
replicas: 3 # by default is 1
template:
metadata:
labels:
app: stateful-nginx # has to match .spec.selector.matchLabels
spec:
terminationGracePeriodSeconds: 10
containers:
- name: nginx-gateway
image: harbor.daemon.io/demo/nginx-gateway:1.0-SNAPSHOT
ports:
- containerPort: 8008
name: http
创建资源对象,并且查看 pod
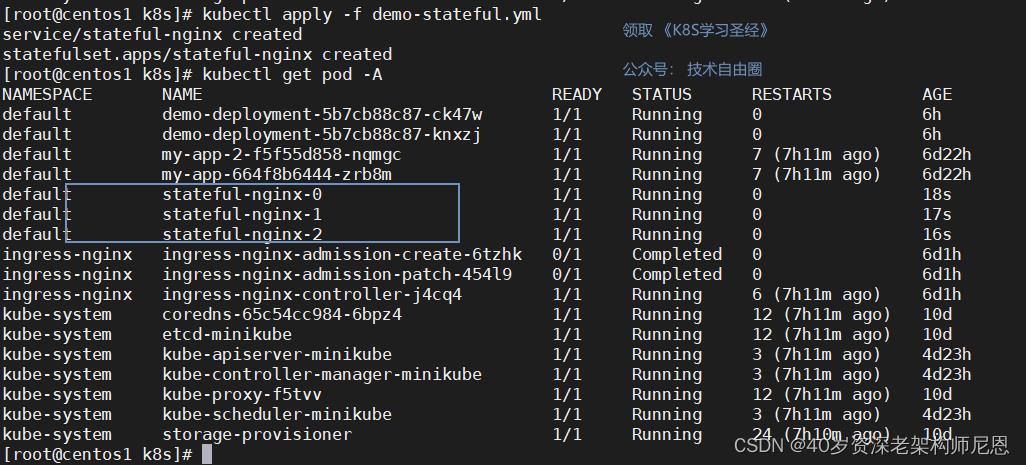
查看 svc

DNS解析
整个状态kubelet(DNS内容同步到Pod)和kube-proxy(整个集群网络负责)会同步
curl http://stateful-nginx:8008/ : 负载均衡到sts部署的Pod上
curl http://stateful-nginx:8008/ : 直接访问指定Pod
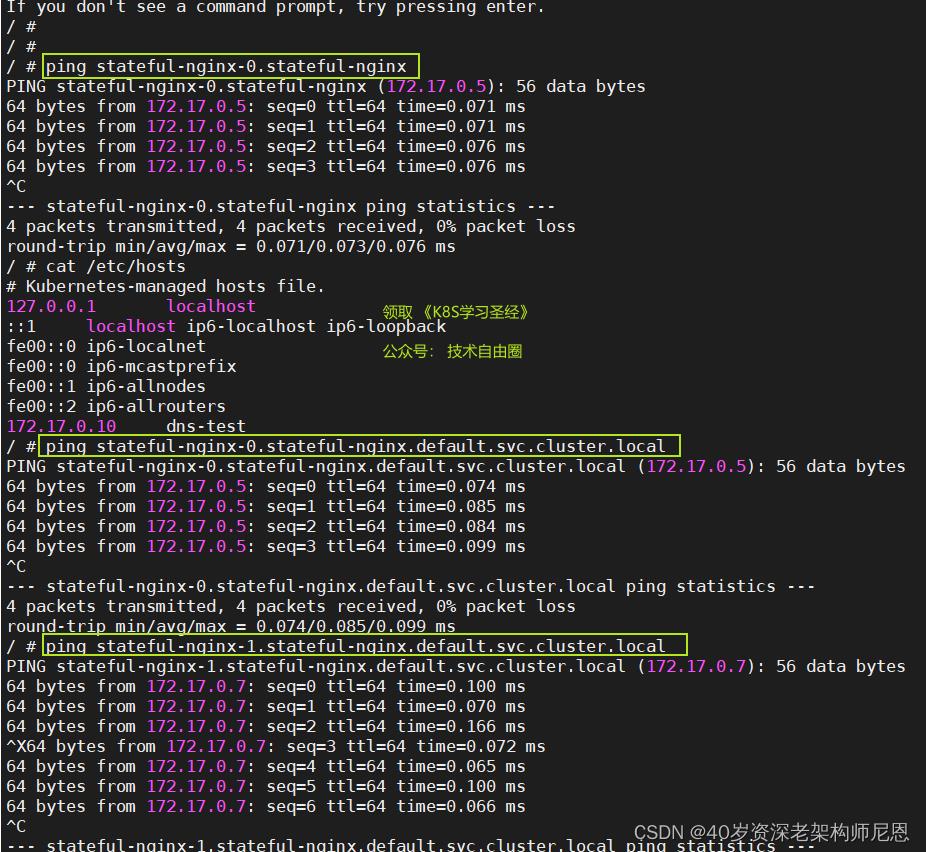
启动一个容器,做一下测试
kubectl run -i --tty --image busybox:latest dns-test --restart=Never --rm /bin/sh

ping stateful-nginx-0.stateful-nginx
ping stateful-nginx-0.stateful-nginx.default.svc.cluster.local
StatefulSet 的几个要点
StatefulSet 和Deployment不同的的属性,主要有:
(1)pod管理策略(podManagementPolicy)
(2)updateStrategy: 更新策略
(3)必须配置service
(1)pod管理策略(podManagementPolicy)
podManagementPolicy : 控制Pod创建、升级以及扩缩容逻辑
使用 kubectl explain StatefulSet.spec 查看
podManagementPolicy controls how pods are created during initial scale up, when replacing pods on nodes, or when scaling down. The default policy is OrderedReady , where pods are created in increasing order (pod-0, then pod-1, etc) and the controller will wait until each pod is ready before continuing. When scaling down, the pods are removed in the opposite order.
The alternative policy is Parallel which will create pods in parallel to match the desired scale without waiting, and on scale down will delete all pods at once.
配置项位于.spec.podManagementPolicy。用来配置pod的创建和销毁是否可以并行操作。有如下两个配置值:
- OrderedReady:pod安装顺序创建和销毁。且每个pod的创建和销毁都必须要求前一个pod已经完全创建或销毁完毕。这个是默认的行为。
- Parallel:允许同时创建和销毁多个pod,不必等待前一个pod创建或销毁完毕。仅仅对扩容缩容有效,pod update过程不受影响。
(2)updateStrategy: 更新策略
使用 kubectl explain StatefulSet.spec 查看
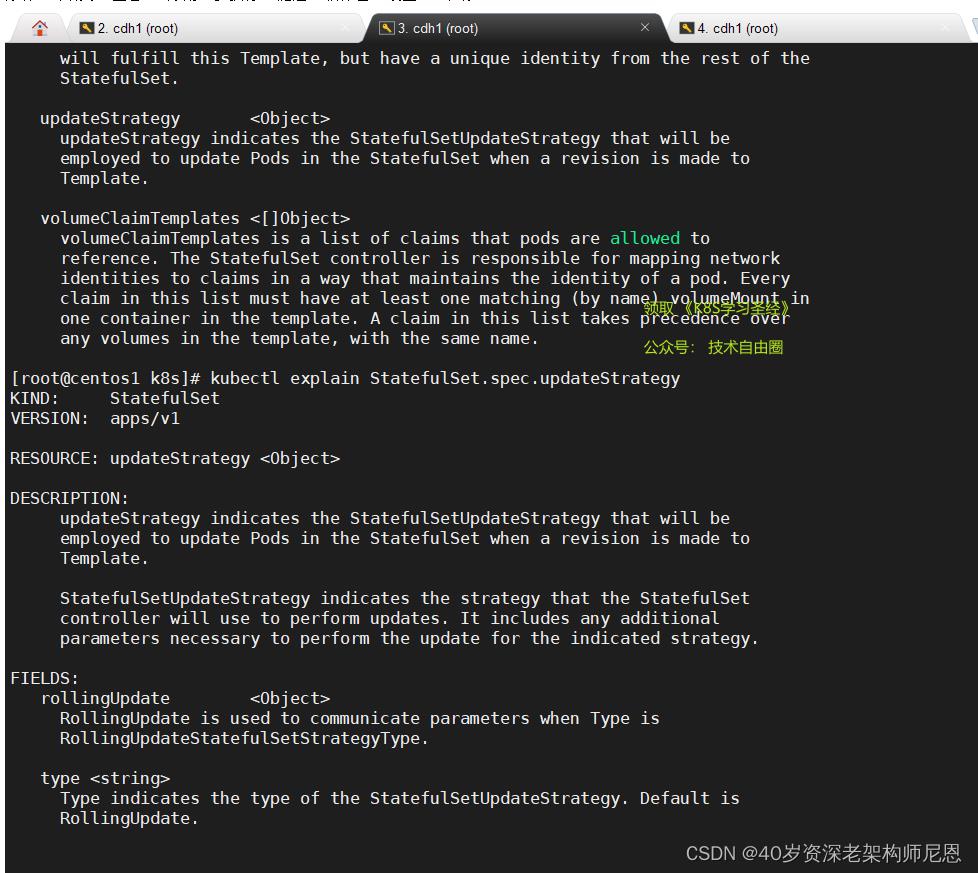
用来配置滚动升级的行为。
可供配置的值如下:
- OnDelete:
.spec.updateStrategy.type设置为OnDelete时,如果pod发生更新,StatefulSet不会更新已经运行的pod,必须将这些pod手工删除。新创建出来的pod是已更新过的pod。 - RollingUpdate:默认使用这个配置。设置为
RollingUpdate时,如果发生pod更新,StatefulSet会挨个删除并重新创建所有的pod。操作的顺序为从pod n-1 到 pod0,。即先删除pod n-1,等它彻底停止后,创建新的pod n-1。等pod n-1进入ready状态后,删除pod n-2 ……以此类推,直到操作完pod0。 - partition:配置一个
.spec.updateStrategy.rollingUpdate.partition整数值。发生更新的时候,所有序号大于等于partition的pod会更新,所有序号小于partition的pod不会更新。即便是把序号小于partition的pod删除了,pod还是会按照之前的版本创建,不会更新。
(3)对应的headless service
为了确保StatefulSet管理的每个pod的网络标识不同,需要创建对应的headless service。
注意在此之前创建了一个配套的headless service。
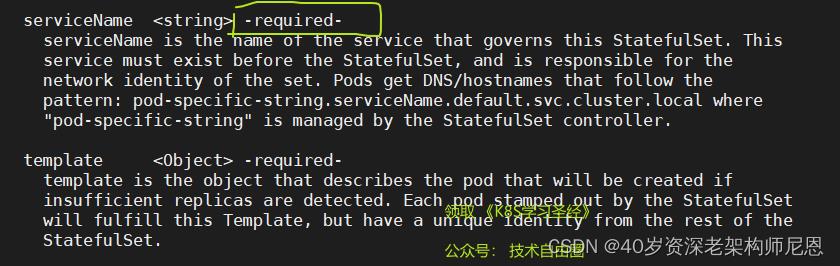
dns 的样式
pod-specific-string.serviceName.default.svc.cluster.local
前面的例子
ping stateful-nginx-0.stateful-nginx # 同一个命名空间
ping stateful-nginx-0.stateful-nginx.default.svc.cluster.local # 跨命名空间
5:Job 任务、CronJob 定时任务
Job 任务
Kubernetes中的 Job负责批处理任务,即仅执行一次的任务。
Job 对象将创建一个或多个 Pod,并确保指定数量的 Pod 可以成功执行到进程正常结束。
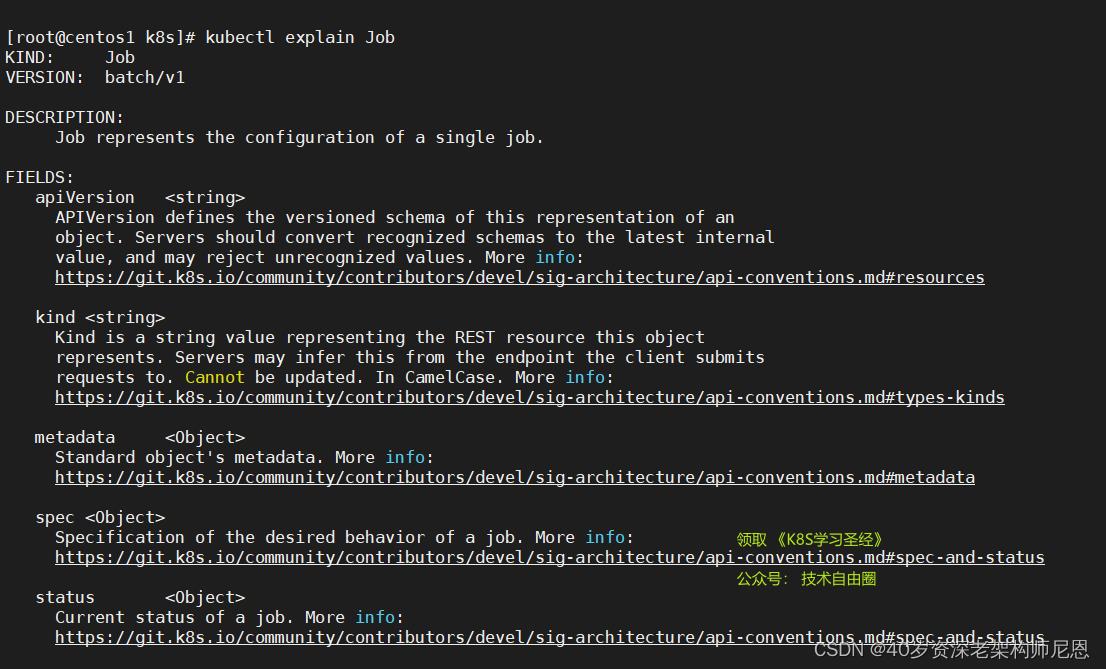
再看Job .spec 的核心字段:
.spec.template格式同Pod.spec.completions表示 Job 运行结束时,成功运行多少个 Pod,默认为1.spec.parallelism表示并行运行多少个Pod,默认为1.spec.activeDeadlineSeconds表示失败Pod的重试最大时间,超过这个时间不会继续重试
当 Job 创建的 Pod 执行成功并正常结束时,Job 将记录成功结束的 Pod 数量。当成功结束的 Pod 达到指定的数量时,Job 将完成执行。删除 Job 对象时,将清理掉由 Job 创建的 Pod
单个 Pod 时,默认 Pod 成功运行后 Job 即结束
job示例
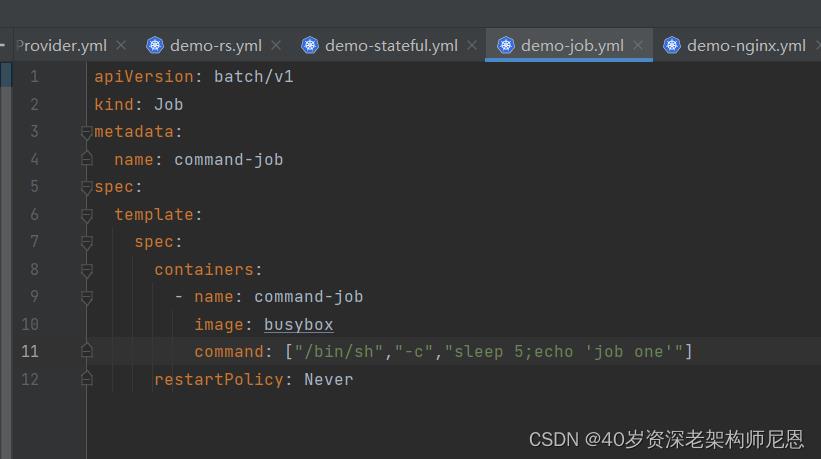
创建job
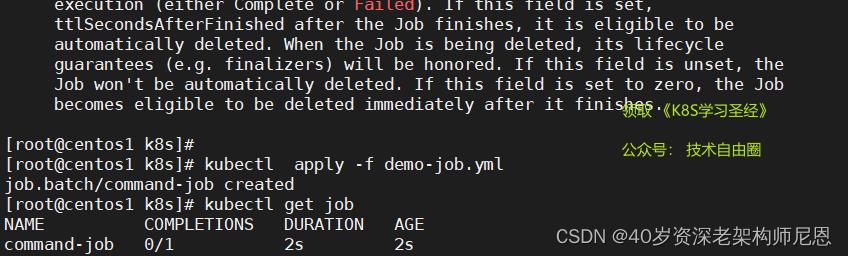
#查看job情况
kubectl get job
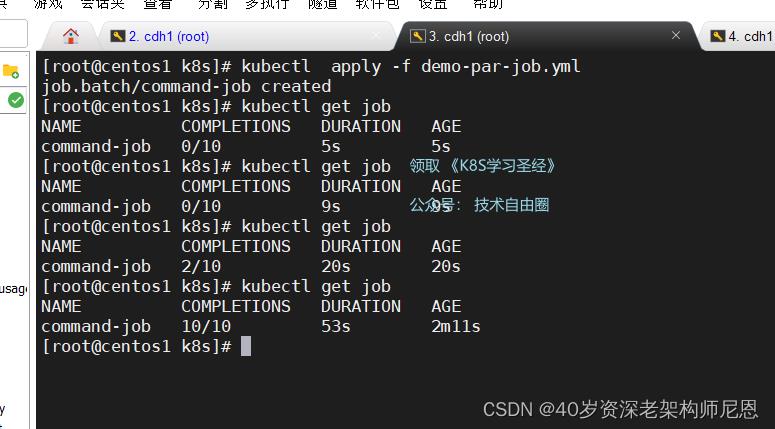
并行 job 示例
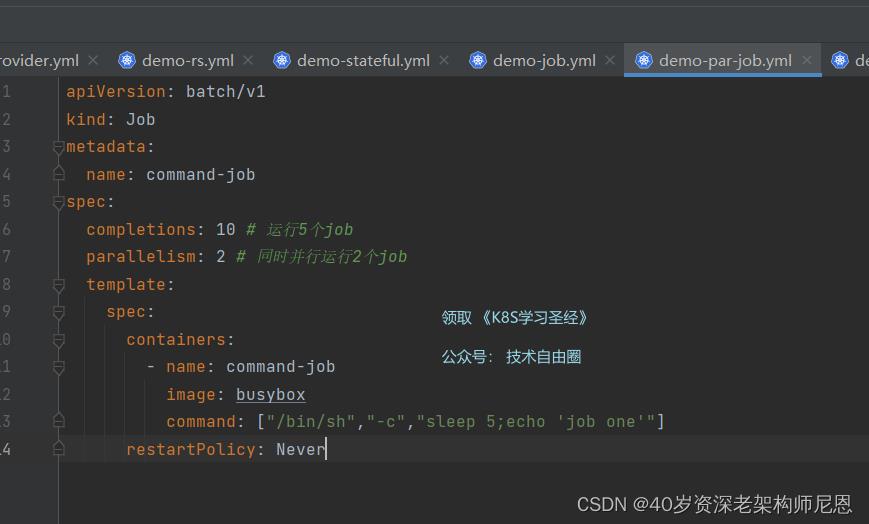
创建job
查看job情况 kubectl get job
CronJob 定时任务
CronJob 是基于 Job 来工作的:
- 在给定时间点,只运行一次
- 周期性的定时运行(数据库备份、发送邮件)
一个CronJob 对象类似于 crontab (cron table) 文件中的一行记录。
该对象根据 Cron 格式定义的时间计划,周期性地创建 Job 对象。
Schedule
所有 CronJob 的
schedule中所定义的时间,都是基于 master 所在时区来进行计算的。
一个 CronJob 在时间计划中的每次执行时刻,都创建 大约 一个 Job 对象。这里用到了 大约 ,是
因为在少数情况下会创建两个 Job 对象,或者不创建 Job 对象。尽管 K8S 尽最大的可能性避免这
种情况的出现,但是并不能完全杜绝此现象的发生。因此,Job 程序必须是 幂等的。
当以下两个条件都满足时,Job 将至少运行一次:
- startingDeadlineSeconds 被设置为一个较大的值,或者不设置该值(默认值将被采纳)
- concurrencyPolicy 被设置为 Allow
CronJob示例
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *" # 和linux的cron一样
concurrencyPolicy: Allow # 允许前后多个job同时运行
#可能前一个周期启动的备份job还没有完成,下一个周期的备份就已经开始了
#如果设置为 Forbid 的话,若前一个job没有完成,则后一个job不启动(跳过)
#如果设置为 Replace ,则让后一个job取代前一个,终止前一个启动后一个job
jobTemplate: #Job 模板,必需字段,指定需要运行的任务
spec:
template:
spec:
containers:
- name: hello
image: busybox:latest
args:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
Cron格式参考
# ┌───────────── minute (0 - 59)
# │ ┌───────────── hour (0 - 23)
# │ │ ┌───────────── day of the month (1 - 31)
# │ │ │ ┌───────────── month (1 - 12)
# │ │ │ │ ┌───────────── day of the week (0 - 6) (Sunday to Saturday;
# │ │ │ │ │ 7 is also Sunday on some systems)
# │ │ │ │ │
# │ │ │ │ │
# * * * * *
6:HPA(Horizontal Pod Autoscaling)水平自动伸缩
HPA使Pod水平自动缩放,不再需要手动扩容
HPA根据 CPU利用率自动化伸缩,还可以自定义指标自动化伸缩。
尼恩提示:本书《K8S圣经》的后面部分,会介绍更加高级的结合cAdvisor + Prometheus (推荐)实现 QPS 吞吐量 自动化伸缩,那属于高级内容。在学习高级内容之前, 咱们先掌握基础的: 基于metrics-server,实现 CPU 利用率的 简单HPA机制。
HPA 使用场景
Horizontal Pod Autoscaling仅适用于Deployment和ReplicaSet,
HPA由API server和controller共同实现。
Horizontal Pod Autoscaling,kubernetes能够根据监测到的 CPU 利用率(或者在 alpha 版本中支持的应用提供的 metric)自动的扩容 replication controller,deployment 和 replica set。
收集指标插件
HPA 依赖到性能指标,收集指标信息插件有metrics-server和heapster,从 v1.8 开始,资源使用情况的监控可以通过 Metrics API的形式获取,具体的组件为Metrics Server,用来替换之前的heapster,heapster从1.11开始逐渐被废弃。
Metrics Server 是 Kubernetes 内置自动缩放管道的可扩展、高效的容器资源指标来源。
Metrics Server 从 Kubelets 收集资源指标,并通过Metrics API在 Kubernetes apiserver 中公开它们,以供 Horizontal Pod Autoscaler和Vertical Pod Autoscaler使用。
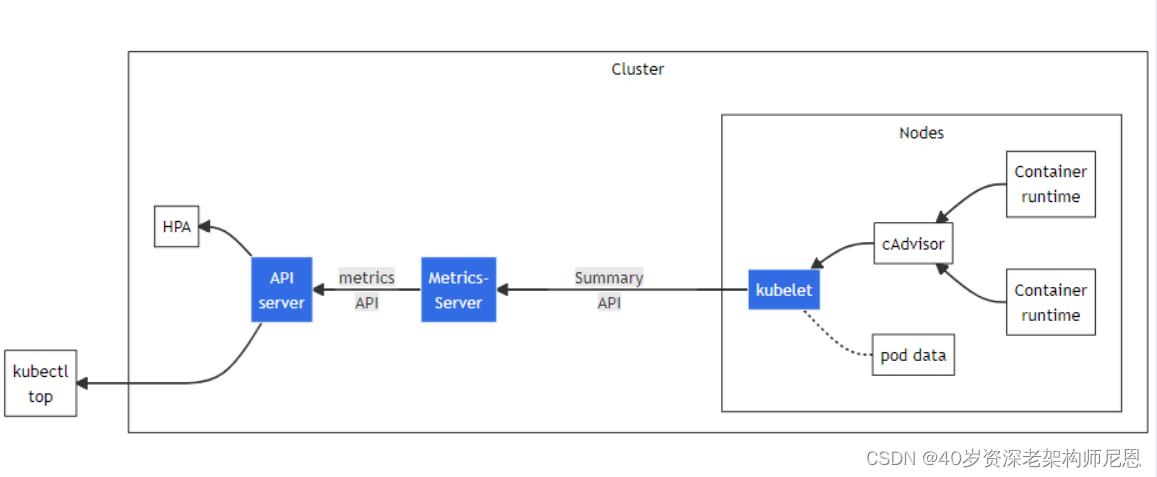
HPA - Horizontal Pod Autoscaler 和 VPA - Vertical Pod Autoscaler 是两种扩展容器应用处理能力的方式,HPA 是通过扩展 Pod 的数量实现的,而 VPA 是通过增加单个 Pod 的可用资源实现的。
通常 HPA 可用于水平扩展较容易的情况,例如 Serverless、FaaS、无状态微服务等。而 VPA 适用于水平扩展较复杂的情况,例如消息顺序处理、文件读写、数据库操作等。一般不建议对同一个资源同时应用 HPA 和 VPA。
咱们这里,仅仅关注 HPA。
Metrics API
介绍Metrics-Server之前,必须要提一下Metrics API的概念
Metrics API相比于之前的监控采集方式(hepaster)是一种新的思路,官方希望核心指标的监控应该是稳定的,版本可控的,且可以直接被用户访问(例如通过使用 kubectl top 命令),或由集群中的控制器使用(如HPA),和其他的Kubernetes APIs一样。
官方废弃heapster项目,就是为了将核心资源监控作为一等公民对待,即像pod、service那样直接通过api-server或者client直接访问,不再是安装一个hepater来汇聚且由heapster单独管理。
Metrics server出现后,新的Kubernetes监控架构,变成下图的样子
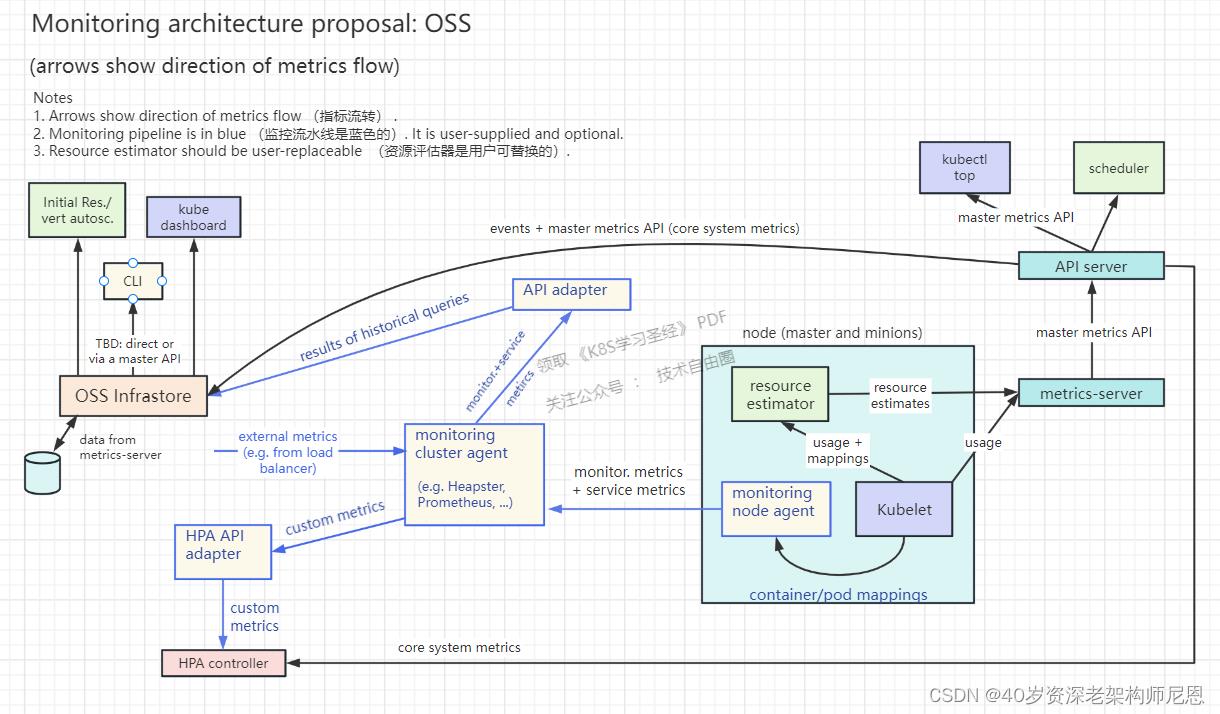
总体来说,K8S监控流程分为两个pipeline(流水线、或者通道):
- core metrics pipeline 核心指标流水线
- monitoring pipeline 非核心监控流水线
核心流程(黑色部分):这是 Kubernetes正常工作所需要的核心度量,从 Kubelet、cAdvisor 等获取度量数据,再由metrics-server提供给Dashboard、HPA控制器等使用。
非核心监控流程(蓝色部分):基于核心度量构建的监控流水线,比如Prometheus可以从metrics-server获取核心度量,从其他数据源(如Node Exporter等)获取非核心度量,再基于它们构建监控告警系统。
core metrics pipeline 核心指标流水线
metrics组件:Kubelet、resource estimator、metrics-server、metrics api
metrics用途:服务于k8s系统核心组件,如调度器调度pod、自动水平扩展,能够提供简单的开箱即用功能,如kubectl top,类似linux top
monitoring pipeline 监控流水线
从系统中收集各种指标并将其暴露给最终用户,也通过适配器暴露给Horizontal Pod Autoscaler(用于自定义指标)和Infrastore。
Kubernetes不会附带monitoring pipeline,用户可以从许多监视系统方案中选择,道通常由每个节点代理和集群级聚合器组成。
kubernetes 的运行只依赖于core metrics
kubernetes 的运行只依赖于core metrics,并且会内置metrics server,而非核心监控流水线Monitoring Pipeline由第三方实现。
再来看看 core metrics、Infrastore、Monitoring Pipeline 的构成:
core metrics
- Kubelet, providing per-node/pod/container usage information
- resource estimator
- metrics server从上述两个地方抓取core metrics,并提供metrics api
Infrastore
计划用于持久存储core metrics,并为kubernetes dashboard提供数据
Monitoring Pipeline
必需提供的metrics:
- system metrics (core and non-core metrics)
- service metrics(app or kubernetes metrics)
可用方案:
- cAdvisor + collectd + Heapster
- cAdvisor + Prometheus (推荐)
- snapd + Heapster
- snapd + SNAP cluster-level agent
- Sysdig
40岁老架构师尼恩提示
当然,本书《K8S圣经》的后面部分,会介绍更加高级的结合cAdvisor + Prometheus (推荐)实现 QPS 吞吐量 自动化伸缩,那属于高级内容。
在学习高级内容之前, 咱们先掌握基础的: 基于metrics-server,实现 CPU 利用率的 简单HPA机制。
在 core metrics pipeline 核心指标流水线 中,metrics-server 是一个非常核心的组件。
总之:metrics-server是一个集群范围内的资源数据集和工具,同样的,metrics-server也只是显示数据,并不提供数据存储服务,主要关注的是资源度量API的实现,比如CPU、文件描述符、内存、请求延时等指标,metric-server收集数据给k8s集群内使用,如kubectl,hpa,scheduler等
注意: 通过 Metrics API,只能获取 node 或 pod 当前的使用情况。
并且k8s不会存储这个数据,因此想要获取10分钟前的资源使用量是不行的。
前置条件: 开启聚合路由
启用API Aggregator,API Aggregation 允许在不修改 Kubernetes 核心代码的同时扩展 Kubernetes API,即:将第三方服务注册到 Kubernetes API 中,这样就可以通过 Kubernetes API 来访问第三方服务了,Metrics Server API 就是将自己的服务注册到 Kubernetes API 中。
注:另外一种扩展 Kubernetes API 的方法是使用 CRD(Custom Resource Definition,自定义资源定义)。后面介绍qps 水平伸缩的时候,使用CRD.
检查 API Server 是否开启了 Aggregator Routing
具体来说,就是 查看 API Server 是否具有 --enable-aggregator-routing=true 选项。
如果没有则需要添加
首先 ps -ef | grep apiserver

复制到editplus ,查找 enable-aggregator ,发现找不到
修改 API Server 的 kube-apiserver.yaml ,配置开启 Aggregator Routing。
修改 manifests 配置后 API Server 会自动重启生效。
修改 过程中,使用到的命令
复制到 本地
scp /etc/kubernetes/manifests/kube-apiserver.yaml root@192.168.56.121:/vagrant/chapter28/metrics/
使用editplus 修改, 然后scp 回去
scp /etc/kubernetes/manifests/kube-apiserver.yaml root@192.168.56.121:/vagrant/chapter28/metrics/
vi 检查一下
再重启
systemctl restart kubelet
systemctl restart kubelet 重启之后,能看到 成功开启 Aggregator Routing。

metrics安装方式一:minikube 中启用指标服务器作为插件
一种简单的方式为,在 minikube 中启用指标服务器作为插件
minikube addons enable metrics-server
启动插件的过程中,毫无疑问,一定会有 minikube metrics-server pod 错误
查看 metrics-server pod 错误,大致如下:
Failed to pull image "k8s.gcr.io/metrics-server-amd64:v0.5.2": rpc error: code = Unknown desc = Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
这个错误是k8s.gcr.io无法访问,需要替换成在国内的镜像,可以使用阿里云的。
registry.cn-hangzhou.aliyuncs.com/google_containers
完整镜像地址。
registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server-amd64:v0.5.2
进入 minikube docker 手动pull镜像。
minikube ssh
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server-amd64:v0.5.2
为了让metrics-server-deployment能工作需要手动打个tag,并且让pod拉取镜像的规则设置成IfNotPresent。
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server:v0.5.2 k8s.gcr.io/metrics-server/metrics-server:v0.5.2
最后,修改镜像拉取规则, 防止每次启动,优先去远程拉取。 改为优先使用本地的 镜像,只有本地没
K8S圣经12:SpringCloud+Jenkins+ K8s Ingress 自动化灰度发布
文章很长,持续更新,建议收藏起来,慢慢读!疯狂创客圈总目录 博客园版 为您奉上珍贵的学习资源 :
免费赠送 :《尼恩Java面试宝典》 持续更新+ 史上最全 + 面试必备 2000页+ 面试必备 + 大厂必备 +涨薪必备
免费赠送 :《尼恩技术圣经+高并发系列PDF》 ,帮你 实现技术自由,完成职业升级, 薪酬猛涨!加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷1)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷2)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷3)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 资源宝库: Java 必备 百度网盘资源大合集 价值>10000元 加尼恩领取
SpringCloud+Jenkins+ K8s Ingress 自动化灰度发布
尼恩的技术社群中(50+),尼恩一直到指导大家面试, 指导大家做简历优化。
生产环境 ,如何进行SpringCloud+Jenkins+ K8s Ingress 灰度发布, 是很多小伙伴都没有实操过的难题。
但是,灰度实操,又是高级开发,和架构师的必须课。 很多小伙伴,由于不懂灰度,不懂云原生,错失了高级开发或者架构师岗位,实在非常可惜。
所以,尼恩基于《K8S学习圣经》, 为大家系统化从原理到实操,介绍一下SpringCloud+Jenkins+ K8s Ingress 自动化灰度发布。作为《K8S学习圣经》的12部分。
《K8S学习圣经》的组成
- 第一部分:云原生(Cloud Native)的原理与演进
- 第二部分:穿透K8S的8大宏观架构
- 第三部分:最小化K8s环境实操
- 第四部分:Kubernetes 基本概念
- 第五部分:Kubernetes 工作负载
- 第六部分:Kubernetes 的资源控制
- 第七部分: SVC负载均衡底层原理
- 第八部分: Ingress底层原理和实操
- 第九部分: 蓝绿发布、金丝雀发布、滚动发布、A/B测试 实操
- 第十部分: 服务网格Service Mesh 宏观架构模式和实操
- 第十一部分: 使用K8S+Harber 手动部署 Springboot 应用
- 第十二部分: SpringCloud+Jenkins+ K8s Ingress 自动化灰度发布
- 第十三部分: k8s springboot 生产实践(高可用部署、基于qps动态扩缩容、prometheus监控)
- 第十四部分:k8s生产环境容器内部JVM参数配置解析及优化
米饭要一口一口的吃,不能急。
结合《K8S学习圣经》,尼恩从架构师视角出发,左手云原生+右手大数据 +SpringCloud Alibaba 微服务 核心原理做一个宏观的介绍。由于内容确实太多, 所以写多个pdf 电子书:
(1) 《 Docker 学习圣经 》PDF (V1已经完成)
(2) 《 SpringCloud Alibaba 微服务 学习圣经 》PDF (V1已经完成)
(3) 《 K8S 学习圣经 》PDF (coding…)
(4) 《 flink + hbase 学习圣经 》PDF (planning …)
以上学习圣经,并且后续会持续升级,从V1版本一直迭代发布。 就像咱们的《 尼恩 Java 面试宝典 》一样, 已经迭代到V60啦。
40岁老架构师尼恩的掏心窝: 通过一系列的学习圣经,带大家穿透“左手云原生+右手大数据 +SpringCloud Alibaba 微服务“ ,实现技术 自由 ,走向颠覆人生,让大家不迷路。
本PDF 《K8S 学习圣经》完整版PDF的 V1版本,后面会持续迭代和升级。供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
以上学习圣经的 基础知识是 尼恩的 《高并发三部曲》,建议在看 学习圣经之前,一定把尼恩的《 Java高并发三部曲 》过一遍,切记,切记。
本部分目录(第12部分)
如何进行 SpringCloud+Jenkins+ K8s Ingress 灰度发布?
生产环境 ,如何进行SpringCloud+Jenkins+ K8s Ingress 灰度发布, 是很多小伙伴都没有实操过的难题。
但是,这些又是高级开发,和架构师的必须课。
在 Kubernetes 上的应用实现灰度发布,最简单的方案是引入官方的 Nginx-ingress 来实现。我们通过部署两套 deployment 和 services,分别代表灰度环境和生产环境,通过负载均衡算法,实现对两套环境的按照灰度比例进行分流,进而实现灰度发布。
通常的做法是当项目打包新镜像后,通过修改 yaml 文件的镜像版本,执行 kubectl apply 的方式来更新服务。
如果发布流程还需要进行灰度发布,那么可以通过调整两套服务的配置文件权重来控制灰度发布,这种方式离不开人工执行。
那么,有没有一种方式能够实现逐步灰度呢?比如自动将灰度比例从 10% 权重提高到 100%,且并且出现问题秒级回退.
答案是肯定的,利用 jenkins 就能够满足此类需求。
本文,为大家介绍一下,SpringCloud+Jenkins+ K8s Ingress 自动化灰度发布
回顾 Nginx-ingress 架构和原理
回顾一下 Nginx-ingress 的架构和实现原理:
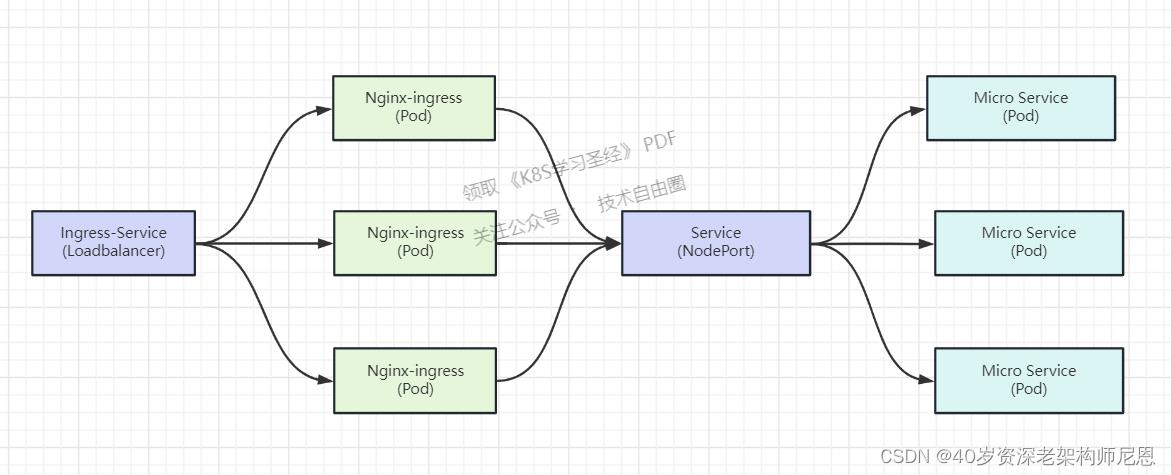
Nginx-ingress 通过前置的 Loadbalancer 类型的 Service 接收集群流量,将流量转发至 Nginx-ingress Pod 内并对配置的策略进行检查,再转发至目标 Service,最终将流量转发至业务容器。
传统的 Nginx 需要我们配置 conf 文件策略。
但 Nginx-ingress 通过实现 Nginx-ingress-Controller 将原生 conf 配置文件和 yaml 配置文件进行了转化,当我们配置 yaml 文件的策略后,Nginx-ingress-Controller 将对其进行转化,并且动态更新策略,动态 Reload Nginx Pod,实现自动管理。
那么 Nginx-ingress-Controller 如何能够动态感知集群的策略变化呢?
方法有很多种,可以通过 webhook admission 拦截器,也可以通过 ServiceAccount 与 Kubernetes Api 进行交互,动态获取。
Nginx-ingress-Controller 使用后者来实现。所以在部署 Nginx-ingress 我们会发现 Deployment 内指定了 Pod 的 ServiceAccount,以及实现了 RoleBinding ,最终达到 Pod 能够与 Kubernetes Api 交互的目的。
灰度实操之前的准备
部署一套稳定版本的 deployment 和 svc
然后再部署一套灰度版本的 deployment 和 svc
在进行流量的分发测试
部署和测试 stable 版本的 deployment 和 svc
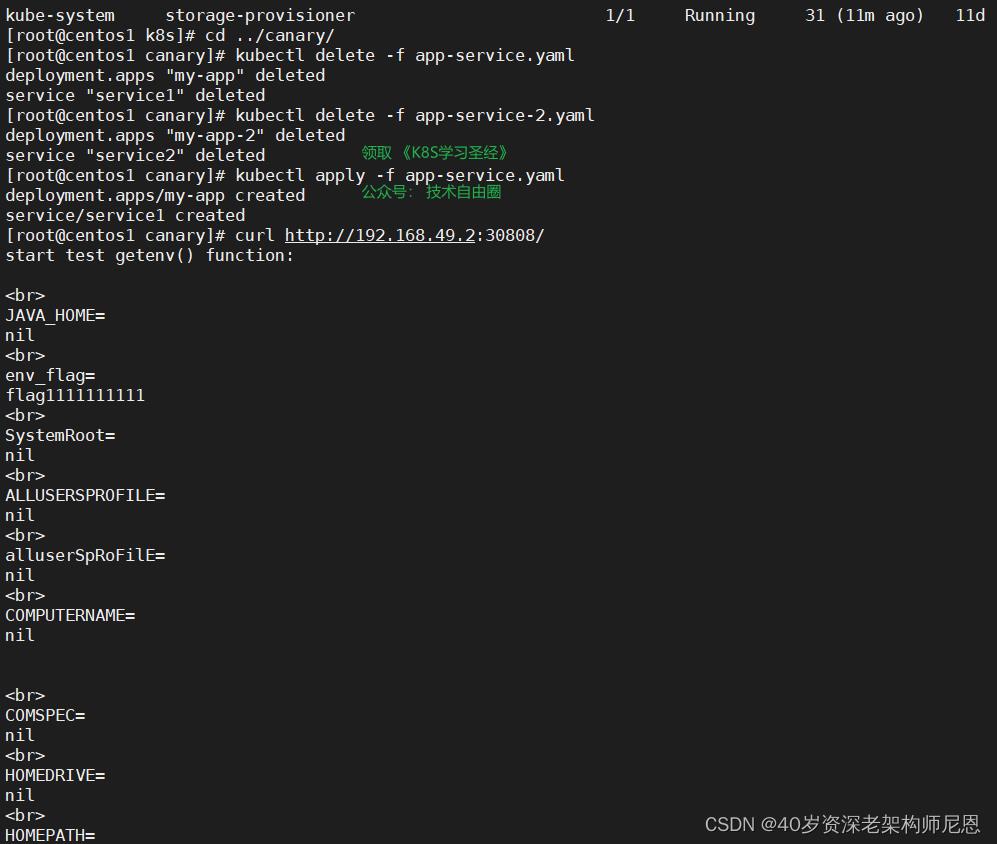
kubectl apply -f app-service.yaml 部署一下
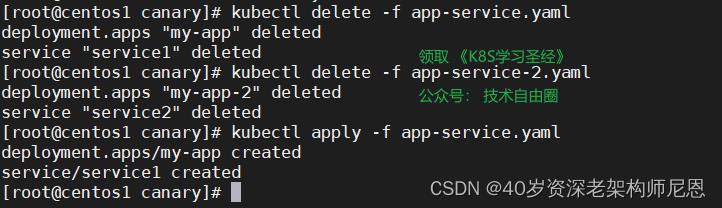
访问一下
curl http://192.168.49.2:30808
部署和测试 canary版本的 deployment 和 svc
canary版本 的 deployment 和 svc
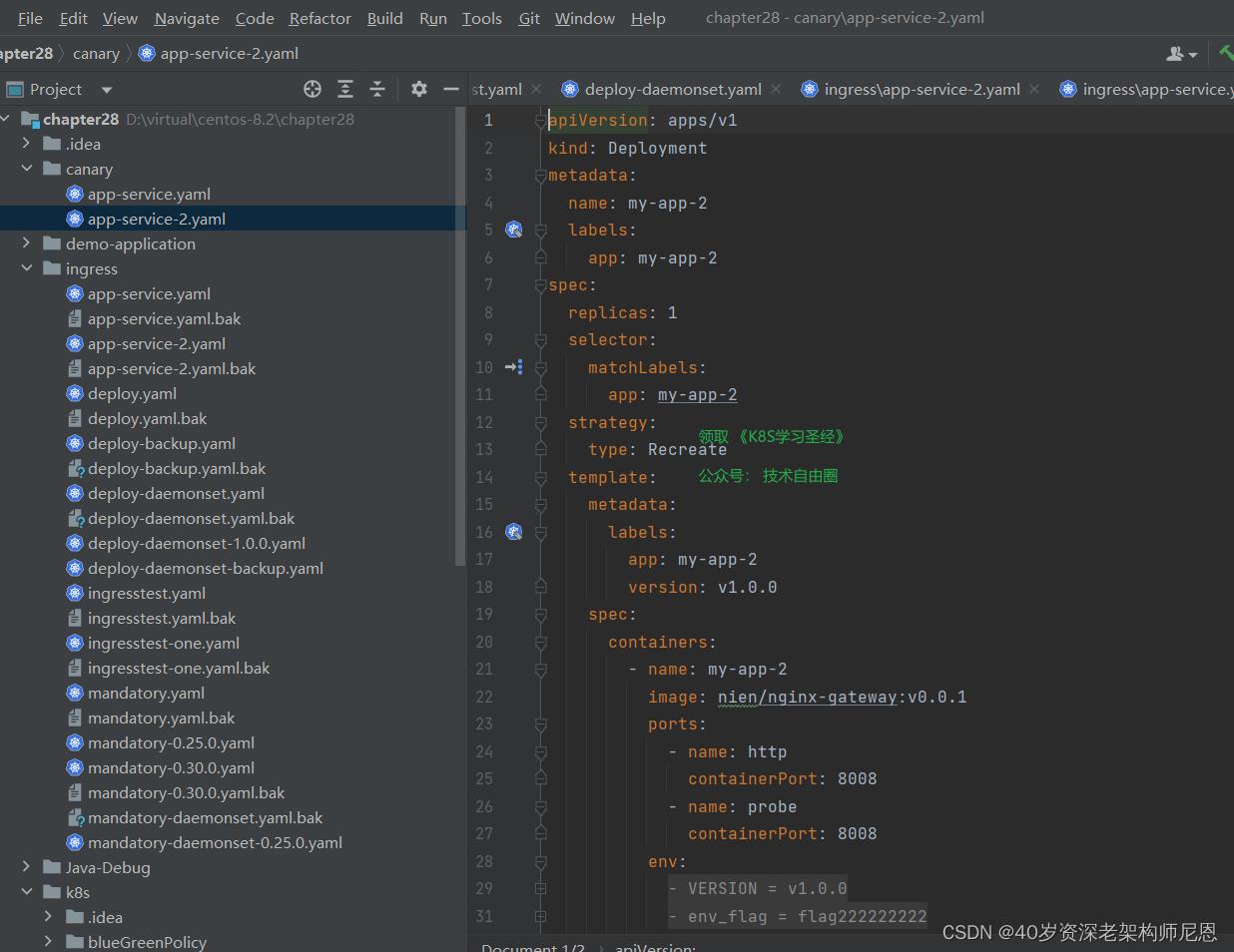
kubectl apply -f app-service.yaml 部署一下
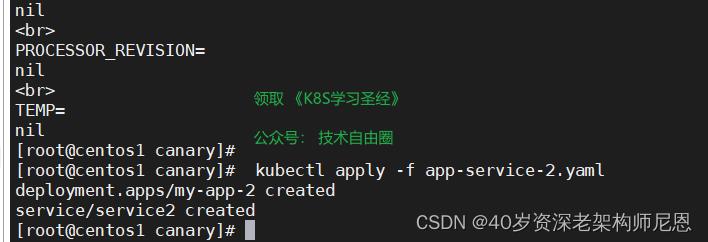
访问一下
curl http://192.168.49.2:30909
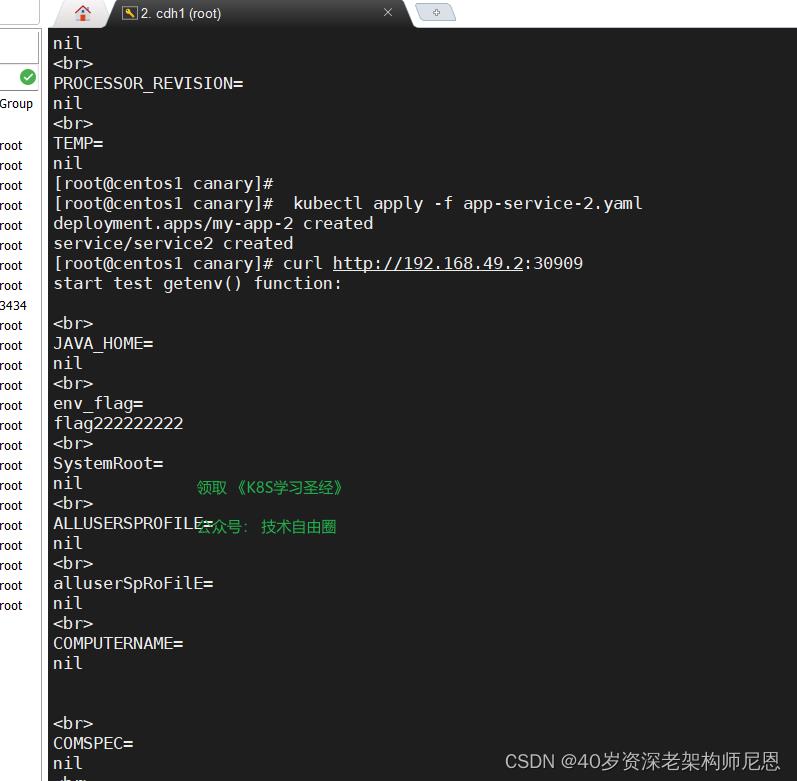
以上具体的实操过程, 请参见 尼恩的 《穿透云原生视频》
基于用户的灰度场景
简单的基于用户的发布场景, ingress 需要加上注解:
nginx.ingress.kubernetes.io/canary:"true"
nginxingress.kubernetes.io/canary-by-header:"canary"
用户的Request Header 的值有一个 canary header,当 canary header的值:
当 设置为 always时,请求将会被一直发送到 Canary 版本;
当 设置为 never时,请求不会被发送到 Canary 入口;
对于任何其他 Header 值,将忽略 Header,并通过优先级将请求与其他金丝雀规则进行优先级的比较。
具体如下图:
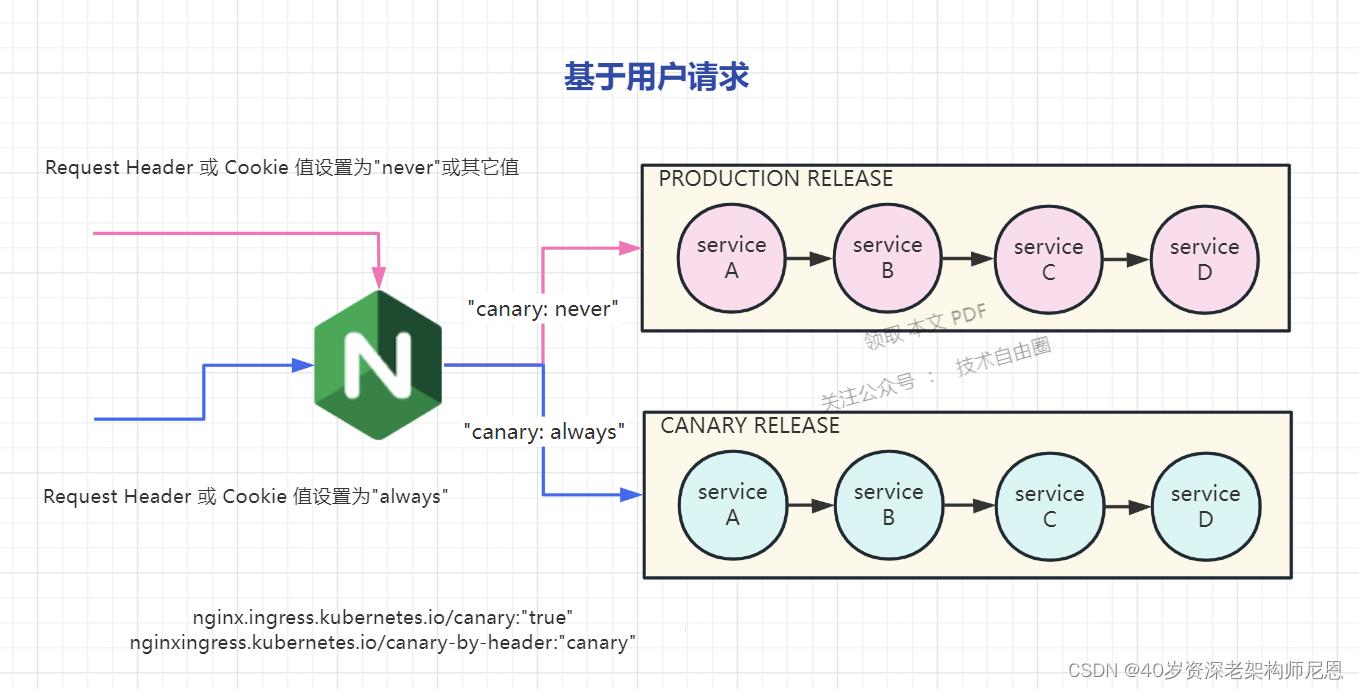
如果用户要自定义 Request Header 的值,必须与canary-by-header 注解(annotation )一起使用。
这里的例子,使用 nginx.ingress.kubernetes.io/canary-by-header,自定义 Request Header 进行流量切分,适用于灰度发布以及 A/B 测试。
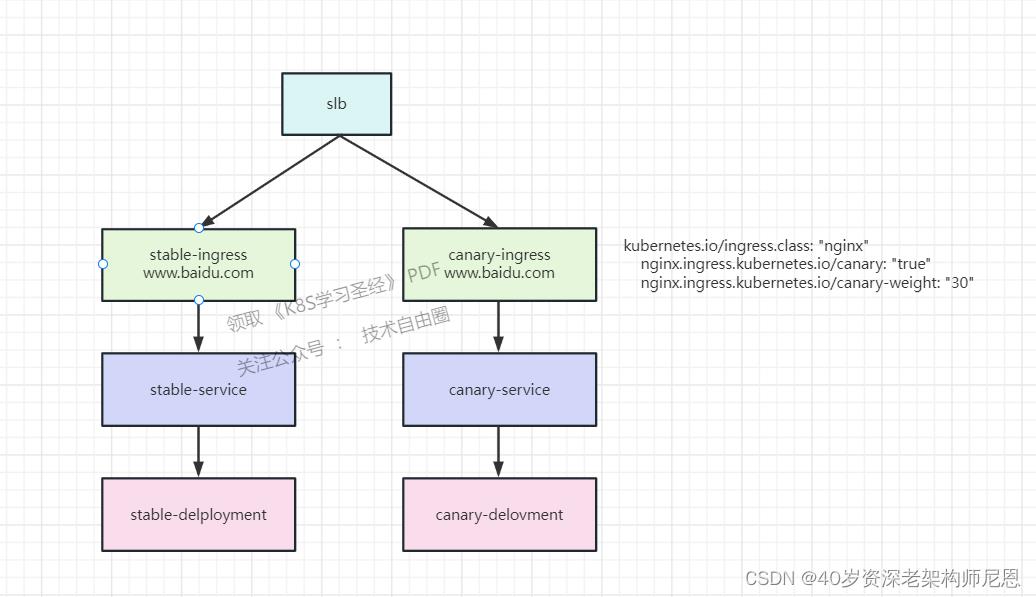
annotations:
kubernetes.io/ingress.class: "nginx"
nginx.ingress.kubernetes.io/canary: "true"
nginx.ingress.kubernetes.io/canary-by-header: "region"
nginx.ingress.kubernetes.io/canary-by-header-value: "beijing"
此灰度规则为:要匹配的 Request Header 的值,用于通知 Ingress 将请求路由到 Canary Ingress 中指定的服务。
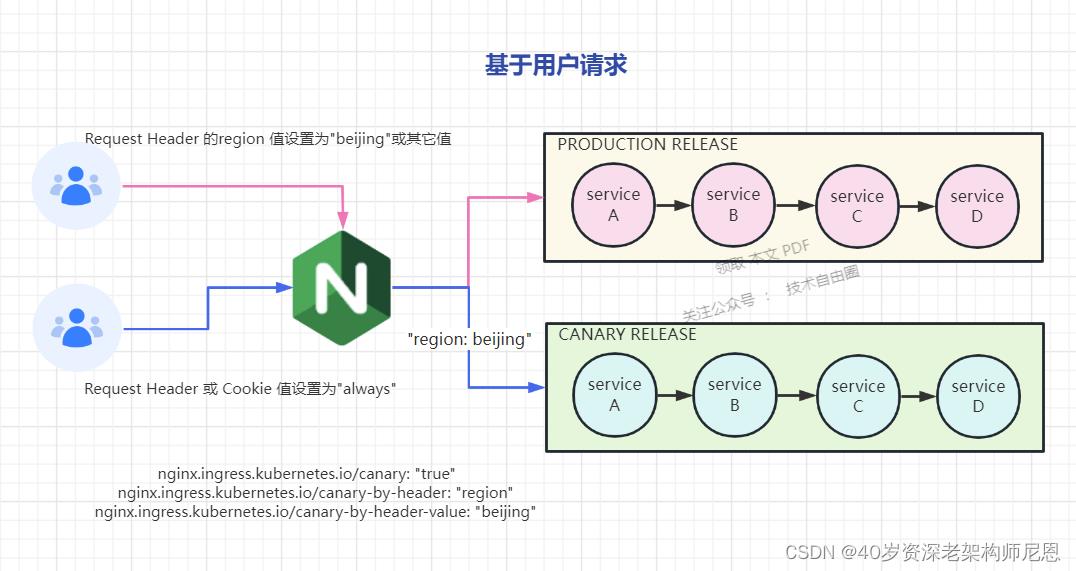
如果按照的配置,
当 Request Header的 region 设置为 beijing时,请求将会被一直发送到 Canary 版本;
当 Request Header 没有 region,或者 设置为非 beijing时,请求不会被发送到 Canary 入口;
接下来,开始基于 用户的灰度实操
配置stable版本的ingress
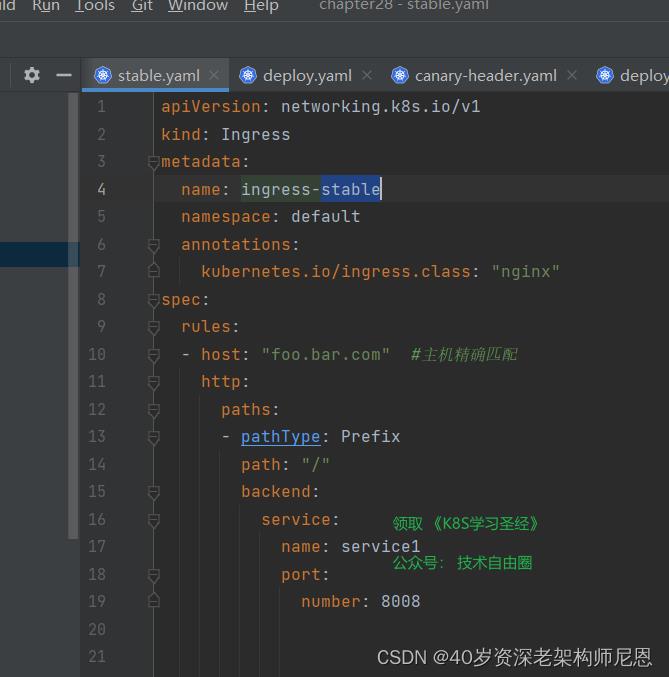
配置canary版本的ingress
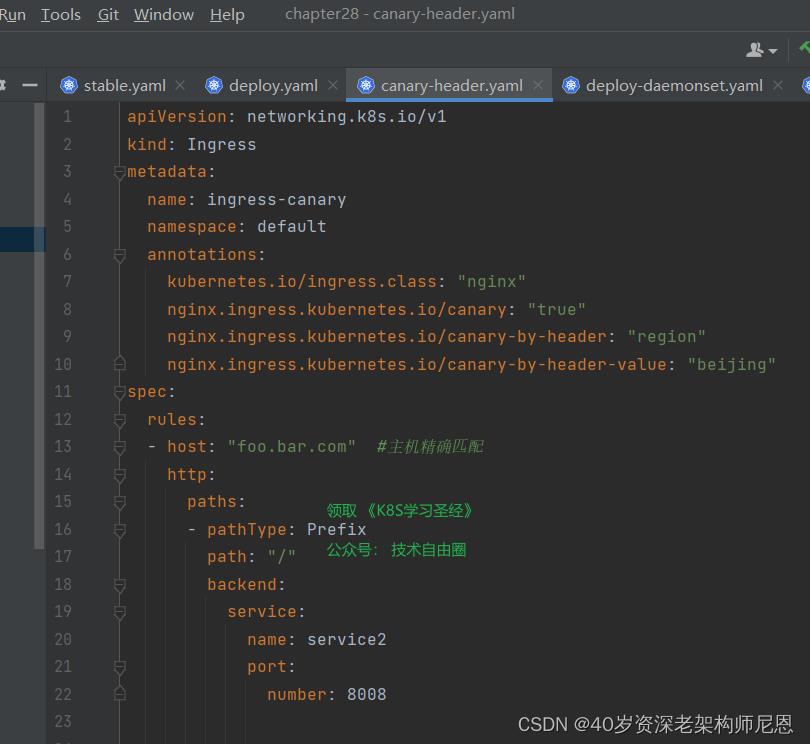
当我们访问的时候不带header,则只会访问stable版本应用,如下:
while sleep 1; do curl http://foo.bar.com/ | egrep flag; done
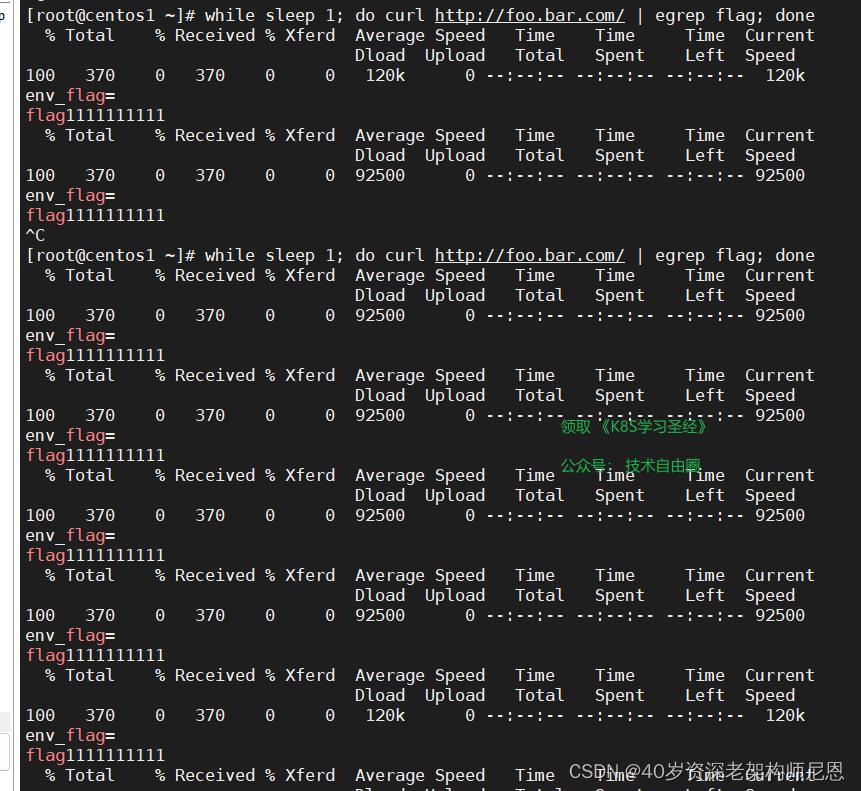
如果我们在访问的时候带上region: sichuan 的header,则只会访问到canary版本应用,如下:
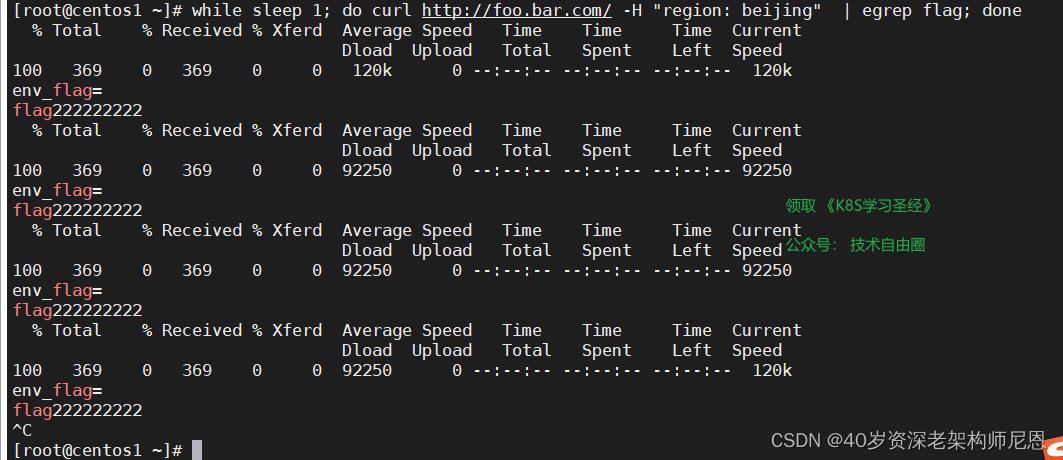
while sleep 1; do curl http://foo.bar.com/ -H "region: beijing" | egrep flag; done
以上具体的实操过程, 请参见 尼恩的 《穿透云原生视频》
基于权重的灰度场景
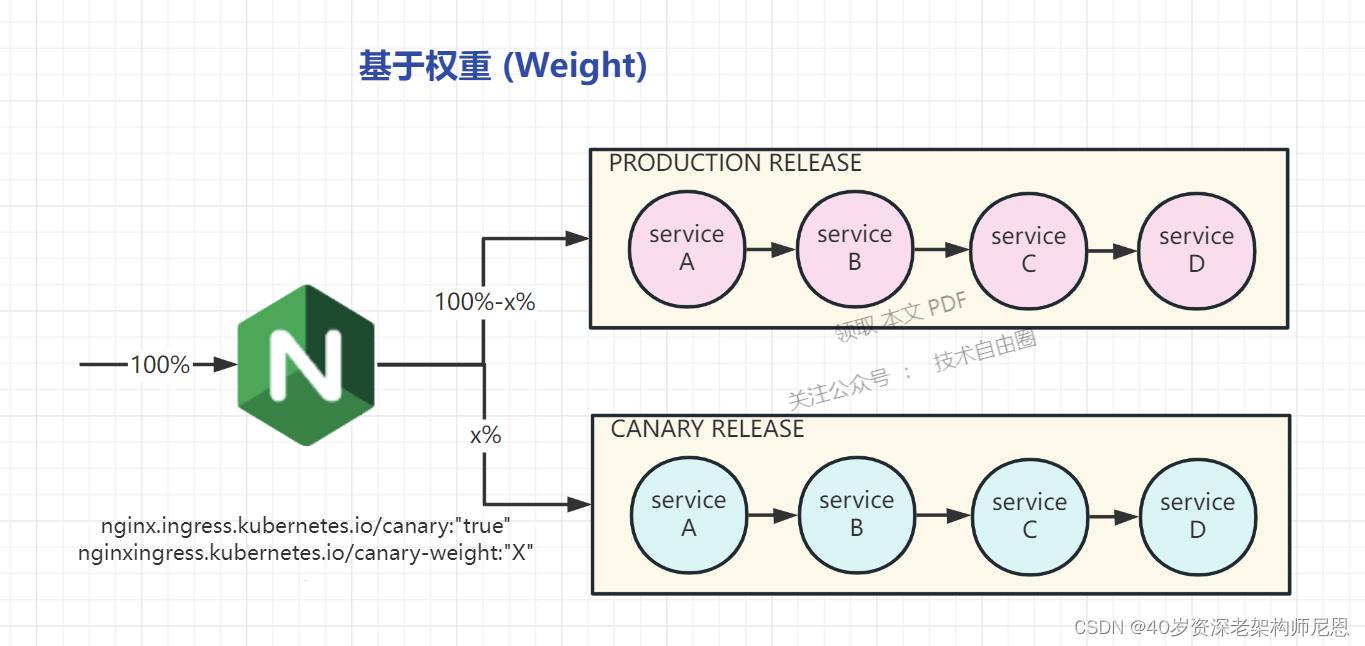
基于权重的 Canary 规则
使用 nginx.ingress.kubernetes.io/canary-weight 注解:
基于服务权重的流量切分,适用于蓝绿部署,权重范围 0 - 100 按百分比将请求路由到 Canary Ingress 中指定的服务。
权重为 0 意味着该金丝雀规则不会向 Canary 入口的服务发送任何请求。
权重为 100 意味着所有请求都将被发送到 Canary 入口。
基于权重的发布实操
(1)配置stable版本的ingress
同基于用户的灰度场景,这里不做赘述
(2)配置canary版本的ingress
具体如下。 源文件可以找尼恩获取。
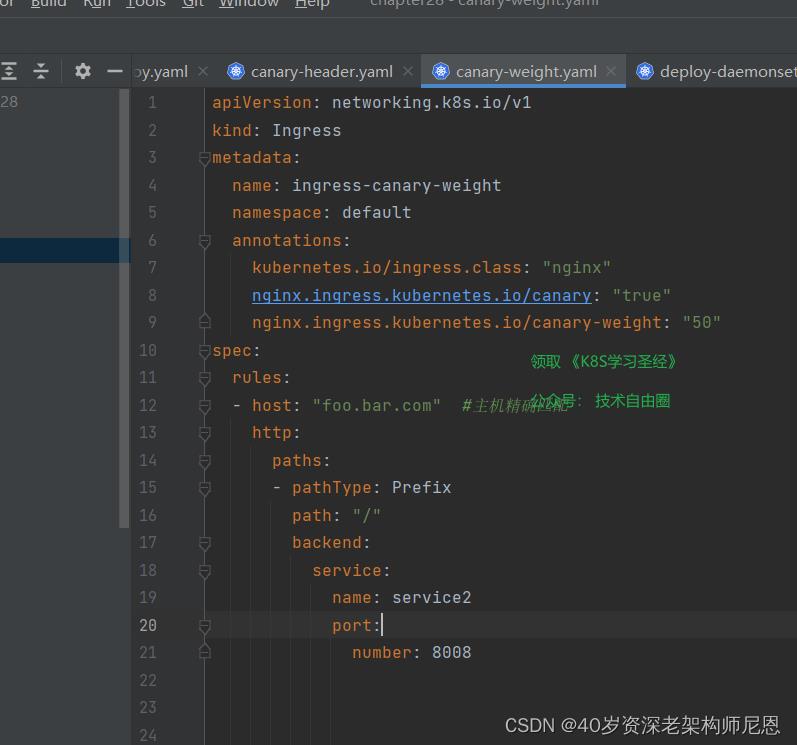
(3) 启动 基于权重的灰度 ingress
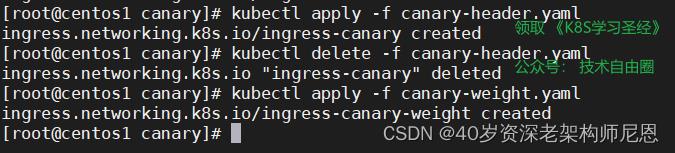
(4)然后我们通过访问测试,效果如下:
while sleep 1; do curl http://foo.bar.com/ | egrep flag; done
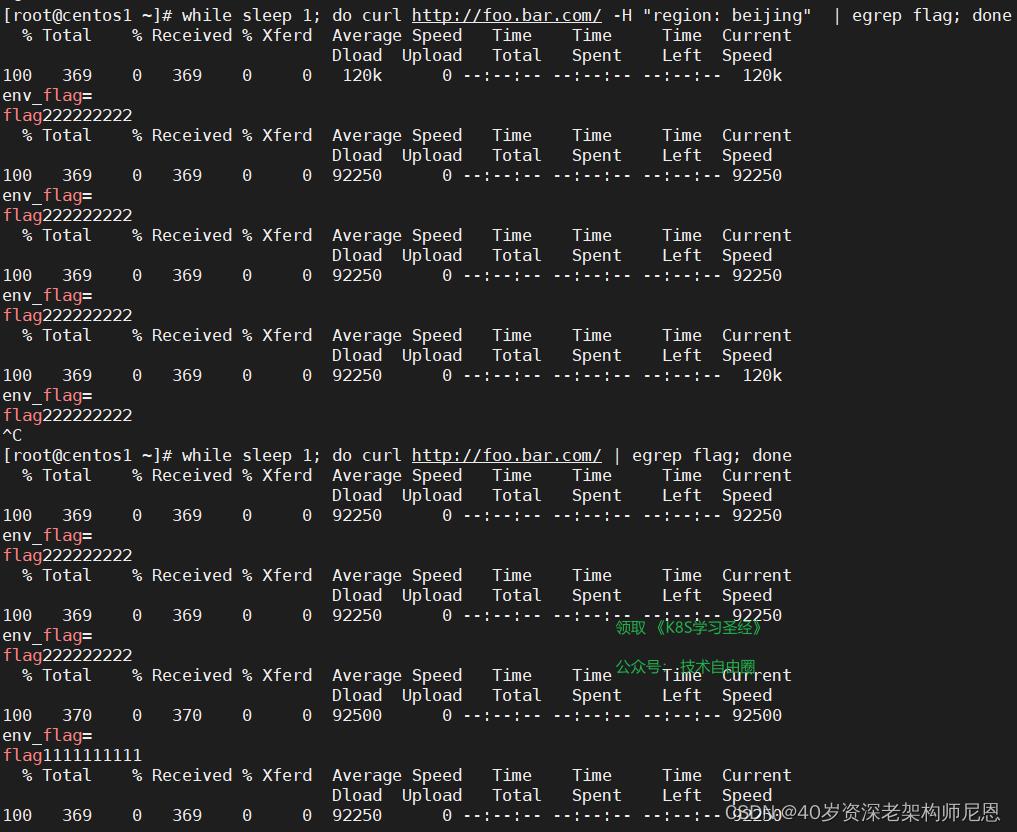
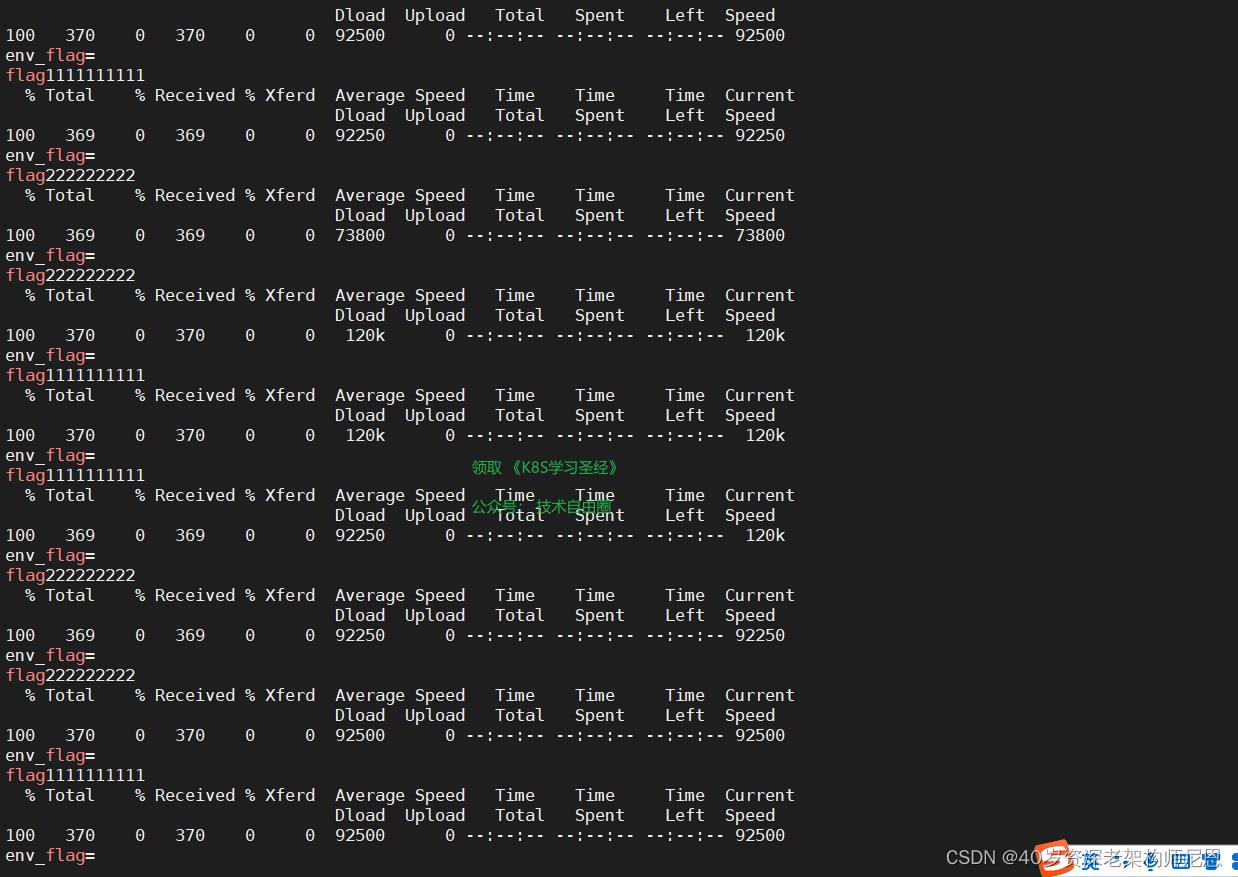
以上具体的灰度实操过程, 请参见 尼恩的 《穿透云原生视频》
如何进行自动化灰度?
在生产环境,通过上面的手工命令,一行一行的执行是不现实的
需要借助自动化的流水线
jenkins 安装和 pipeline 流水线的使用
Jenkins pipeline是基于Groovy语言实现的DSL,用于描述流水线如何进行,包括编译、打包、部署、测试等等步骤
此处我们使用离线安装包方式安装/docker-compose 的方式安装
Jenkins 官网:https://www.jenkins.io
官方安装文档指导:https://www.jenkins.io/doc/book/installing/
下载和启动 jenkins
这里简单介绍一下 Jenkins 的本机部署方式.
一般都是下载一个 Jenkins 的 war, 修改配置文件中的 JDK 路径, 然后 service start 就可以正常使用了.
我们在服务器上执行如下命令进行jenkins可运行包下载
mkdir -p /usr/local/jenkins
cd /usr/local/jenkins
下载这个包 https://get.jenkins.io/war-stable/2.375.1/jenkins.war
复制Jenkins war包到 安装目录
cp /vagrant/chapter28/jenkins.2.375.1.war .
找一个 start-jenkins.sh 脚本去启动jenkins。这个shell 和springboot的启动脚本一样,启动命令可以接参数start|restart|stop 分别标识启动,重启,停止服务
复制启动脚本到 安装目录
cp /vagrant/chapter28/deploy_jenkins.sh .
脚本内容如下:
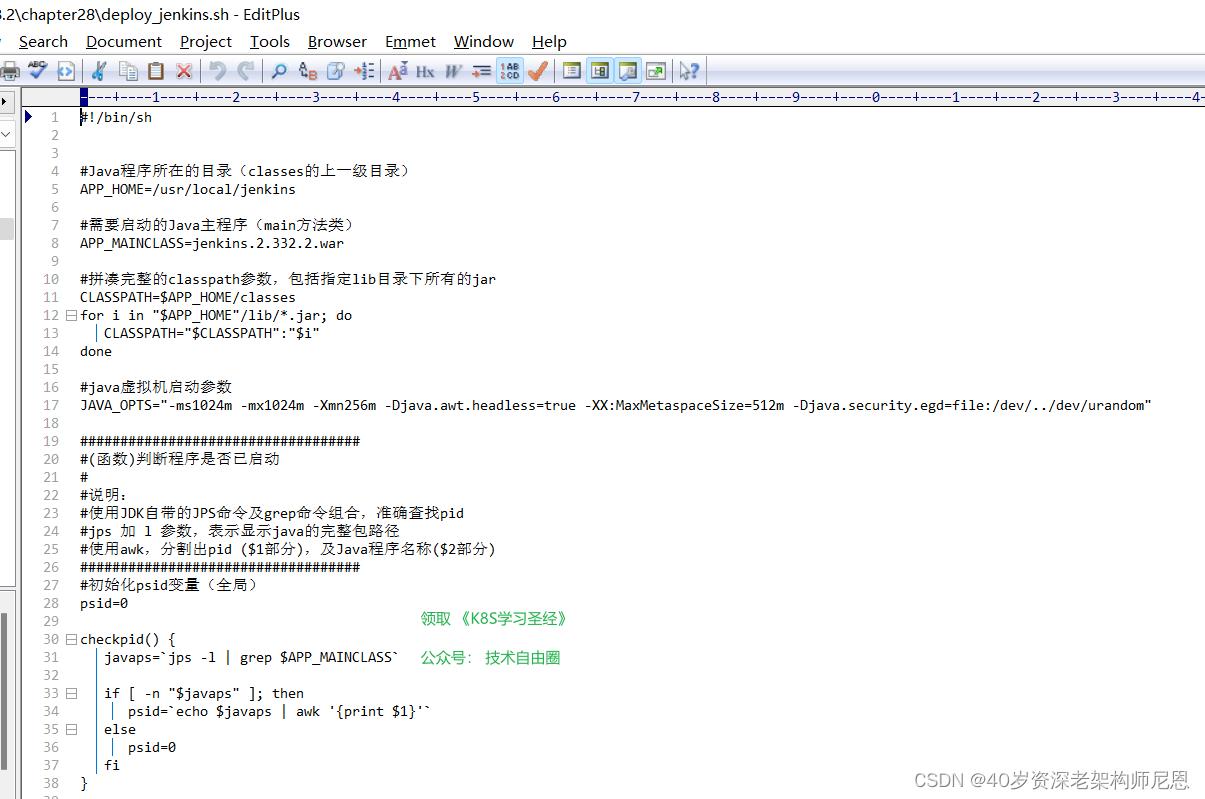
给启动脚本执行权限,并启动jenkins
chmod +x start-jenkins.sh
sh start-jenkins start
查看日志
tail -f nohup.out
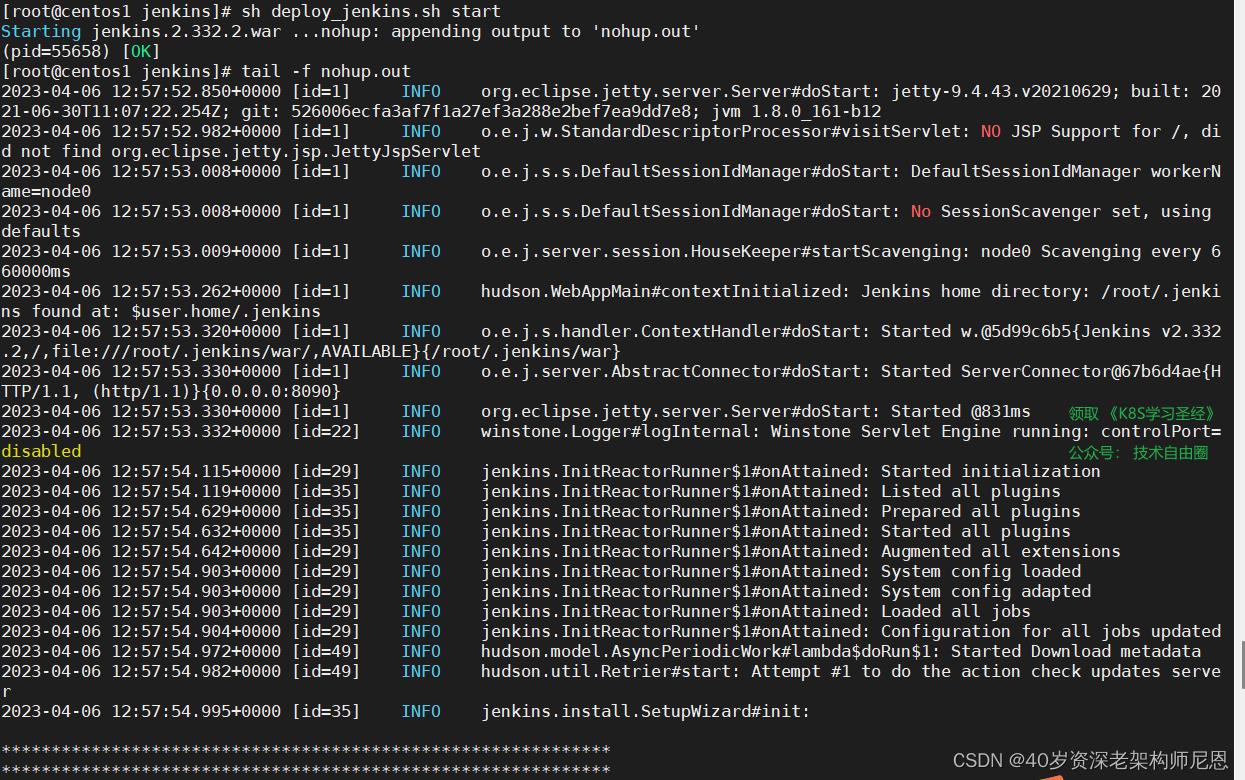
这种方式部署简单, 但是容易将我们的服务器环境变得十分复杂.
所以下面介绍本节docker-compose 搭建 Jenkins.
尼恩的环境,首先使用的这种方式。但是发现一个问题,新版本的 jenkins 需要依赖 jdk11, jkd8 不能用了
而尼恩的 公司有要求,一定要用jkd8
所以只能用 docker 安装 jenkins ,实现jdk的隔离。
docker-compose 编排文件 如下:
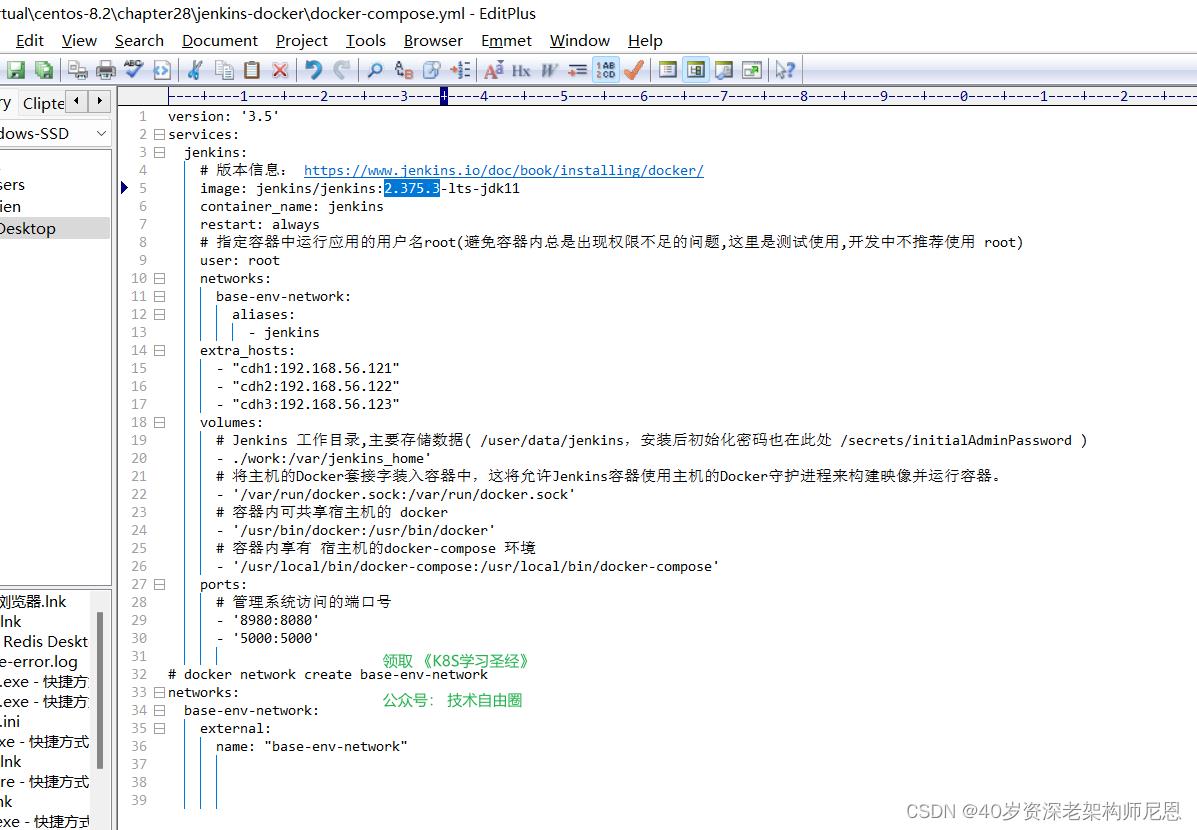
volumes:
#Jenkins 工作目录,主要存储数据( /user/data/jenkins,安装后初始化密码也在此处 /secrets/initialAdminPassword )
- ./data:/var/jenkins_home\'
#将主机的Docker套接字装入容器中,这将允许Jenkins容器使用主机的Docker守护进程来构建映像并运行容器。
- \'/var/run/docker.sock:/var/run/docker.sock\'
#容器内可共享宿主机的 docker
- \'/usr/bin/docker:/usr/bin/docker\'
#容器内享有 宿主机的docker-compose 环境
- \'/usr/local/bin/docker-compose:/usr/local/bin/docker-compose\'
使用尼恩的一键启动shell脚本,一键启动
具体实操,请参见尼恩视频
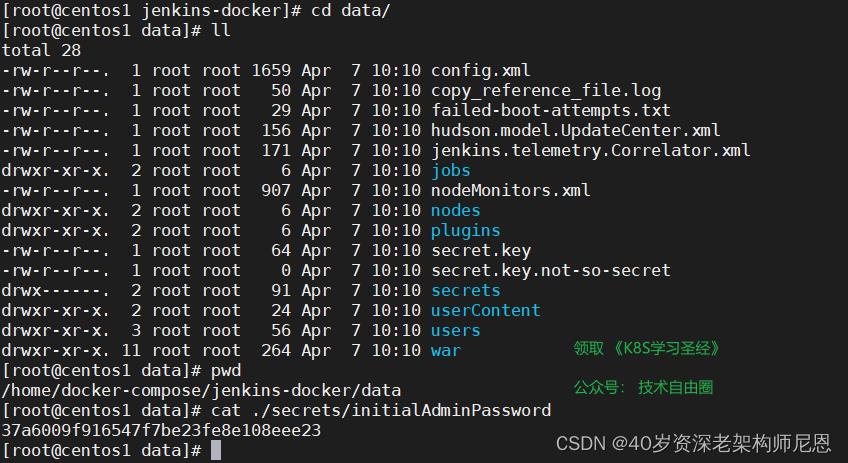
首次登录需要查看初始化密码:( 挂载数据文件内可以查看 )
cat ./secrets/initialAdminPassword
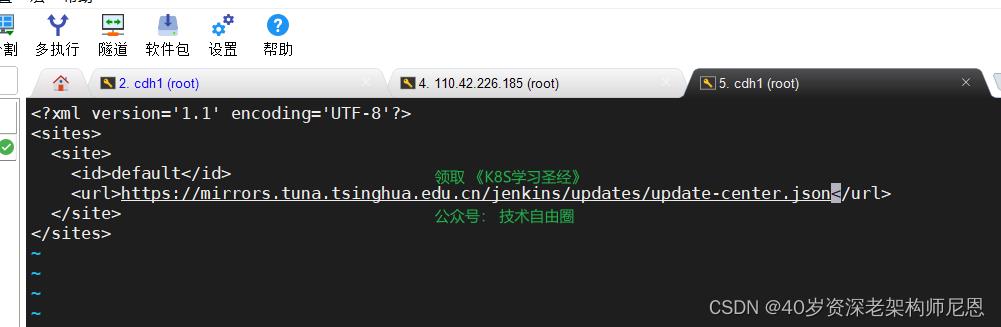
需要修改插件的镜像源地址为
https://mirrors.tuna.tsinghua.edu.cn/jenkins/updates/update-center.json
具体的修改方式为,修改
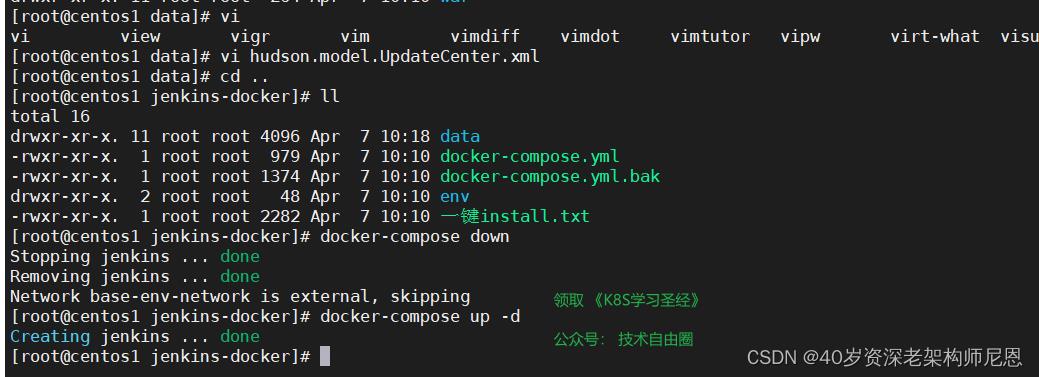
修改后,重新启动,就可以从清华大学的插件镜像站,下载插件了
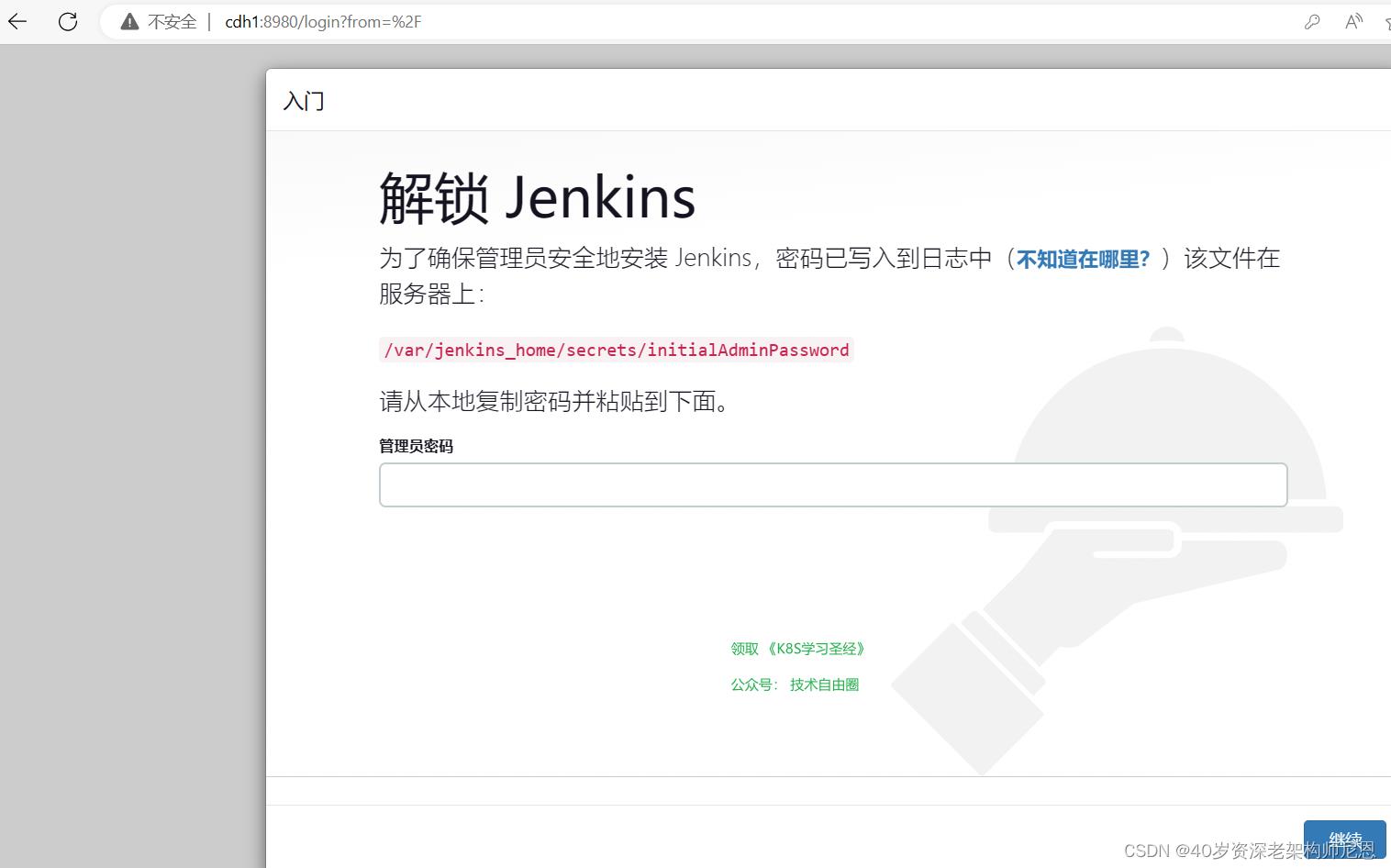
接下来访问 jenkins
登录 jenkins
查看启动日志,看到初始化管理员密码数据即表示启动成功,
copy对应的密码,通过ip+port方式进行访问,
上面shell 脚本中指定的端口为8980,我们在启动日志中也能够看到启动的端口为8090。
在浏览器中输入:
http://cdh1:8980
终于看到jenkins的登录界面
输入密码后,安装插件
点击选择插件来安装,然后取消掉几个默认安装的插件
插件安装完毕,有几个失败的,无所谓
关键是 pipeline 插件安装好了就行
接下来,创建第一个管理员用户
全部填 admin
进行一下实例配置
保存后完成
使用 pipeline 插件
Jenkins Pipeline是一套插件,支持在Jenkins中实施和集成持续交付管道。pipeline是部署流水线,它支持脚本和声明式语法,能够比较高自由度的构建jenkins任务.个人推荐使用这种方式去构建jenkins。
Pipeline在Jenkins上增加了一套强大的自动化工具,支持从简单的持续集成到全面的CD管道的用例。通过对一系列相关任务建模,用户可以利用Pipeline的更多功能,如:
- 可维护:管道是在代码中实现的,并且通常会被签入源代码管理,从而使团队能够编辑,审阅和迭代他们的交付管道。
- 可能出现:在继续进行管道运行之前,管道可以选择停止并等待人员输入或批准。
- 复杂场景:管道支持复杂的实际CD需求,包括分叉/连接,循环和并行执行工作的能力。
- 可扩展性:Pipeline插件支持对其DSL的定制扩展 。
一次持续交付(CD)管道是从用户到版本控制软件的自动化表达。对软件的每一次改变(在源代码控制中提交)都会在发布过程中经历一个复杂的过程。
这个过程包括以可靠和可重复的方式构建软件,以及通过测试和部署的多个阶段来推进构建的软件(称为“构建”)。
Pipeline提供了一套可扩展的工具,用于通过管道域特定语言(DSL)语法将“简单到复杂”的交付管道使用“代码”建模 。
安装 Pipeline 插件
如果没有安装 Pipeline 插件,那么还需要单独安装 Jenkins Pipeline 插件
注意,默认 Jenkins 使用 https://updates.jenkins.io/update-center.json 下载并安装扩展,但是速度较慢。
我们可以修改为使用国内镜像站点,比如清华大学镜像站点:
1)Manage Jenkins / Manage Plugins / Advanced
2)Update Site / URL https://mirrors.tuna.tsinghua.edu.cn/jenkins/updates/update-center.json
3)Submit
https://mirrors.tuna.tsinghua.edu.cn/jenkins/updates/update-center.json
pipeline 的 hello world
pipeline是部署流水线,它支持脚本和声明式语法。
通过界面手动配置来配置CD过程,想要配置一些复杂度高的任务,只能选择自由风格的项目,通过选项等操作进行配置,让jenkins可以下载代码、编译构建、然后部署到远程服务器,这样显然是不方便管理和移植的。
pipeline可以创建一个jenkinsfile来申明一个任务,方便管理和移植。
接下来我们创建一个最简单的pipeline。
登录jenkins,点击创建item:
在流水线中选择hello world 生成代码:
以上便是一个最简单的流水线。
点击build now (立即构建),jenkins任务开始执行,运行完成后点击查看执行记录:
在console output 中可以看到运行记录:
为了提高流水线的复用性以及便于流水线代码的管理,更多的是将pipeline的脚本在远程git仓库,当我们修改了远程仓库的流水线脚本,jenkins就会加载到最新的脚本执行。
在流水线配置中选择pipeline script from SCM:
按照提示配置好脚本git仓库地址,访问仓库的凭证,流水线脚本文件的名称(默认是Jenkinsfile),分支(默认是master)等。
配置完成后在仓库中添加文件Jenkinsfile把脚本提交并push, 最后执行任务,发现执行成功。
通过这个特性,我们可以把我们的流水线脚本和项目代码本身放到一个仓库中管理,达到多版本控制并和代码版本统一的效果。
如果我们编写jenkinsfile需要语法提示相关的编辑器,可以使用jenkins官方提供的vscode插件Jenkins Pipeline Linter Connector 。
使用idea Groovy 也能提示部分语法。
idea 设置jenkinsfile 语法提示方法 settings > editor > File Types > Groovy 新增一列Jenkinsfile.
pipeline 语法介绍
jenkins pipeline有2种语法:脚本式(Scripted)语法和声明式(Declar-ative)语法。
pipeline插件从2.5版本开始同时支持两种语法,官方推荐的是使用申明式语法,
在这里也只对申明式语法进行介绍。
申明式语法demo:
pipeline
agent any
stages
stage(\'pull\')
steps
echo \'拉取代码\'
stage(\'build\')
steps
echo \'构建代码\'
声明式语法中,以下结构是必须的,缺少就会报错:
- pipeline:固定语法,代表整条流水线
- agent 执行代理人:指定流水线在哪执行,
默认any即可,也可以指定在docker、虚拟机等等里执行
- environment 环境变量,类似全局变量
environment
//构建执行者
BUILD_USER = ""
- triggers 构建触发器,Jenkins自动构建条件
triggers
//每3分钟判断一次代码是否有变化
pollSCM(\'H/3 * * * *\')
-
stages:流水线阶段集合节点
该节点中至少有一个stage
-
stage:流水线的阶段节点
每个阶段中至少包含一个steps
-
steps:执行步骤集合
每个集合至少包含一个step。
-
step: 执行步骤。
下面是一个比较大的例子
pipeline
//代理,通常是一个机器或容器
agent any
//环境变量,类似全局变量
environment
//构建执行者
BUILD_USER = ""
//构建触发器,Jenkins自动构建条件
triggers
//每3分钟判断一次代码是否有变化
pollSCM(\'H/3 * * * *\')
stages
//构建阶段
stage(\'Build\')
//使用build user vars插件,获取构建执行者
steps
wrap([$class: \'BuildUser\'])
script
//将构建执行者注入到环境变量中,方便最后通知使用
BUILD_USER = "$env.BUILD_USER"
/* 从Bitbucket上拉取分支
* @url git地址
* @branch 分支名称
* @credentialsId Jenkins凭证Id,用于远程访问
*/
git(url: \'https://demo@bitbucket.org/demo/demo.git\', branch: \'master\', credentialsId: \'Bitbucket\')
//执行maven打包
//-B --batch-mode 在非交互(批处理)模式下运行(该模式下,当Mven需要输入时,它不会停下来接受用户的输入,而是使用合理的默认值);
//打包时跳过JUnit测试用例,
//-DskipTests 不执行测试用例,但编译测试用例类生成相应的class文件至target/test-classes下
//-Dmaven.test.skip=true,不执行测试用例,也不编译测试用例类
sh \'npm install && npm run build\'
//部署阶段
stage(\'Deliver\')
steps
//执行脚本
sh \'\'\'
cd /var/lib/jenkins/workspace/demo/
tar -cvf dist.tar.gz ./dist
\'\'\'
stage(\'SSH\')
steps
script
def remote = [:]
remote.name = \'test\'
remote.host = \'192.168.12.12\'
remote.allowAnyHosts = true
withCredentials([usernamePassword(credentialsId: \'192.168.12.12\', passwordVariable: \'password\', usernameVariable: \'username\')])
remote.user = "$username"
remote.password = "$password"
sshCommand remote: remote, command: "pwd"
sshRemove remote: remote, path: \'/usr/share/nginx/html/demo/dist\'
sshPut remote: remote, from: \'/var/lib/jenkins/workspace/demo/dist.tar.gz\', into: \'/usr/share/nginx/html/test-monitor/\'
sshCommand remote: remote, command: "cd /usr/share/nginx/html/demo/ && tar -xvf ./dist.tar.gz"
Jenkins 插件 SSH Pipeline Steps
安装插件 SSH Pipeline Steps, 以支持 跨机器执行脚本。
此插件可通过SSH在远程服务器执行命令和传输文件。
sshCommand 在远程节点上执行给定的命令并响应输出
node
def remote = [:]
remote.name = \'root\'
remote.host = \'cdh1\'
remote.user = \'root\'
remote.password = \'vagrant\'
remote.allowAnyHosts = true
stage(\'Remote SSH\')
sshCommand remote: remote, command: "ls -lrt"
sshCommand remote: remote, command: "for i in 1..5; do echo -n \\"Loop \\$i \\"; date ; sleep 1; done"
sshGet 从远程主机获取文件或目录
node
def remote = [:]
remote.name = \'test\'
remote.host = \'test.domain.com\'
remote.user = \'root\'
remote.password = \'password\'
remote.allowAnyHosts = true
stage(\'Remote SSH\')
sshGet remote: remote, from: \'abc.sh\', into: \'abc_get.sh\', override: true
sshPut 将文件或目录放入远程主机
node
def remote = [:]
remote.name = \'test\'
remote.host = \'test.domain.com\'
remote.user = \'root\'
remote.password = \'password\'
remote.allowAnyHosts = true
stage(\'Remote SSH\')
writeFile file: \'abc.sh\', text: \'ls -lrt\'
sshPut remote: remote, from: \'abc.sh\', into: \'.\'
sshRemove 删除远程主机上的文件或目录
node
def remote = [:]
remote.name = \'test\'
remote.host = \'test.domain.com\'
remote.user = \'root\'
remote.password = \'password\'
remote.allowAnyHosts = true
stage(\'Remote SSH\')
sshRemove remote: remote, path: "abc.sh"
sshScript 在远程节点上执行给定的脚本(文件)并响应输出
node
def remote = [:]
remote.name = \'test\'
remote.host = \'test.domain.com\'
remote.user = \'root\'
remote.password = \'password\'
remote.allowAnyHosts = true
stage(\'Remote SSH\')
writeFile file: \'abc.sh\', text: \'ls -lrt\'
sshScript remote: remote, script: "abc.sh"
结合 withCredentials 从 Jenkins 凭证存储中读取私钥
为了提高安全性,可以用Credentials Plugin屏蔽用户名密码。
def remote = [:]
remote.name = "node-1"
remote.host = "10.000.000.153"
remote.allowAnyHosts = true
node
withCredentials([sshUserPrivateKey(credentialsId: \'sshUser\', keyFileVariable: \'identity\', passphraseVariable: \'\', usernameVariable: \'userName\')])
remote.user = userName
remote.identityFile = identity
stage("SSH Steps Rocks!")
writeFile file: \'abc.sh\', text: \'ls\'
sshCommand remote: remote, command: \'for i in 1..5; do echo -n \\"Loop \\$i \\"; date ; sleep 1; done\'
sshPut remote: remote, from: \'abc.sh\', into: \'.\'
sshGet remote: remote, from: \'abc.sh\', into: \'bac.sh\', override: true
sshScript remote: remote, script: \'abc.sh\'
sshRemove remote: remote, path: \'abc.sh\'
pipeline支持的指令
pipeline的基本结构满足不了现实多变的需求。所以,jenkins pipeline通过各种指令(directive)来丰富自己。
Jenkins pipeline支持的指令有:
- environment:用于设置环境变量,可定义在stage或pipeline部分
- tools:可定义在pipeline或stage部分。它会自动下载并安装我们指定的工具,并将其加入PATH变量中
- input:定义在stage部分,会暂停pipeline,提示你输入内容
- options:用于配置jenkins pipeline本身的选项,比如options retry(3) 表示,当pipeline失败时再重试2次。options指令可定义在stage或pipeline部分
- parallel:并行执行多个step。
- parameters:与input不同,parameters是执行pipeline前传入的一些参数
- triggers:用于定义执行pipeline的触发器
- when:当满足when定义的条件时,阶段才执行。
ingress 灰度发布流水线设计
在使用ingress 进行灰度之前,直接使用service+deployment的方式进行灰度。这种场景下,可以 通过不同的镜像(含deployment)来进行灰度大概的流程如下:
- 发布canary版本应用进行测试
- 测试完成将canary版本替换成stable版本
- 删除canary版本的ingress配置
- 删除老的stable版本
整个过程中,对于已经部署好的deployment是不能直接修改labels标签的。
所以,在canary版本测试完成后,还要更新stable版本的镜像。当然,可以使用滚动更新的方式去完成。那我们流水线可以这样设计,如下:
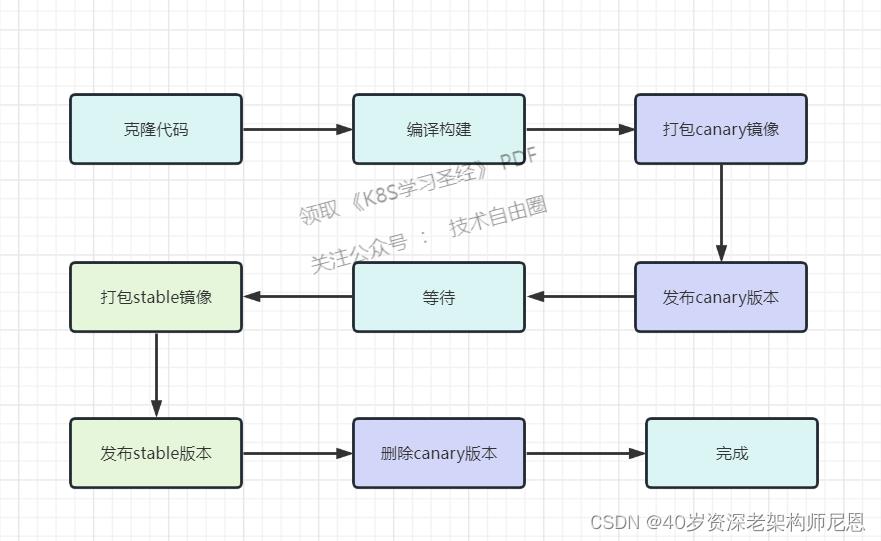
在使用ingress 进行灰度之后,灰度测试通过之后,就使用灰度镜像作为new stable 镜像使用,不需要重新的打包镜像,
但是在发布期间,线上同时会存在旧的 old stable 和 canary 两套镜像, 虽然浪费一些资源,但是好处随时可以回退。
其实尼恩告大家,版本的发布是惊心动魄, 回退的概率非常大。 同时存在两套版本,实现s级回退, 也是一件非常爽的事情。
在使用ingress 进行灰度之后,灰度的流程,可以变得更加灵活,更加丰富,更加稳健。
在使用ingress 进行灰度 ,总体流程为3部分,大致如下:
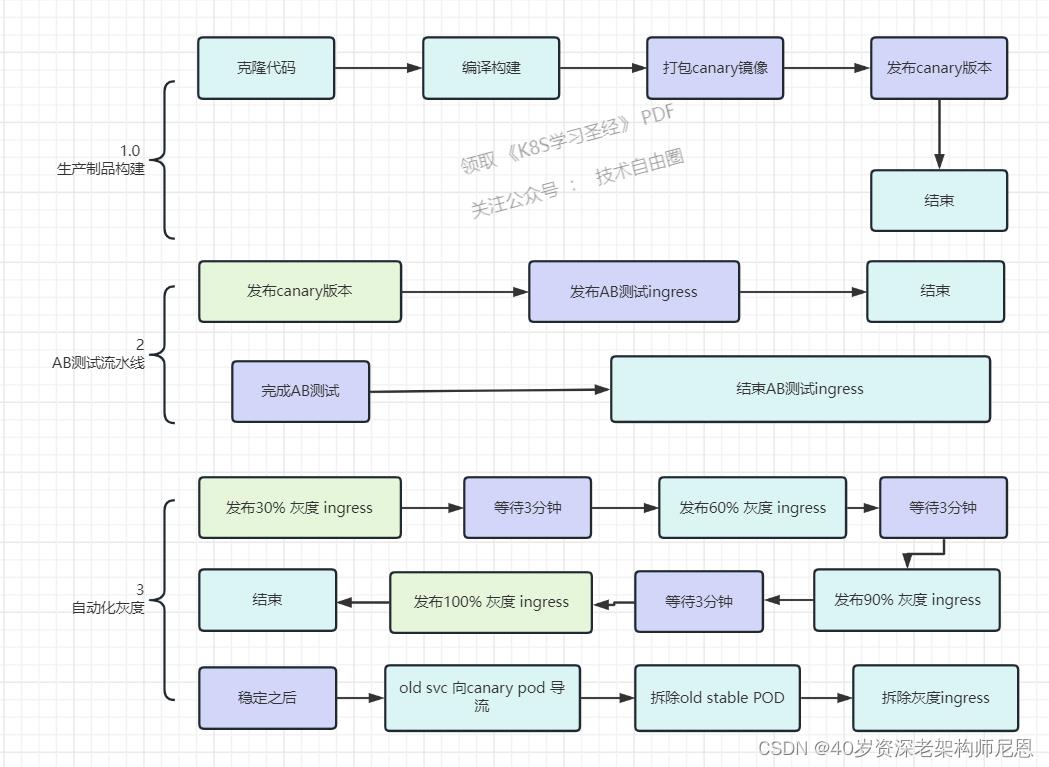
CICD 流水线预览
为了实现以上目标,我们设计了以下持续部署流水线。
AB测试和灰度,部署流水线主要实现了以下几个步骤:
1、自动化的制品发布,通过gitlab进行自动化打包之后,通过钩子方法触发流水线,打包镜像到harber仓库
2、生产环境进行 A/B 测试
3、生产环境自动灰度发布(自动进行4次逐渐提升灰度比例)
4、生产环境进行版本正式切换
step1:自动化的制品发布
自动化的制品发布流程图:
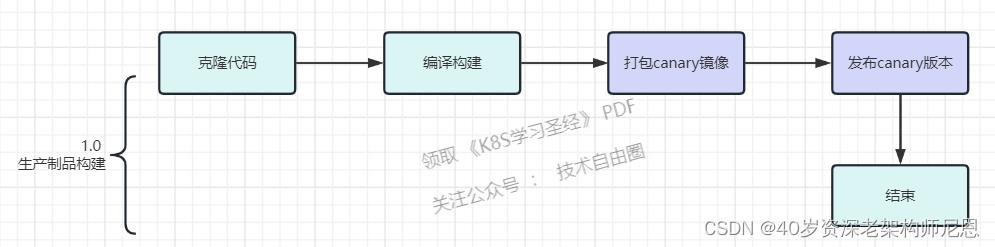
从 Gitlab 提交代码到自动触发持续集成的步骤:
1、提交代码后触发持续集成,自动构建镜像
2、镜像构建完成后,自动推送镜像到制品库
3、触发持续部署
在gitlab上, 有回调jenkins的hook 链接设置,设置之后,可以触发 jenkins 的 自动化制品构建流水线。
这里的制品就是docker 镜像。 制品的 仓库就是harber。
模拟的 制品构建流水线如下
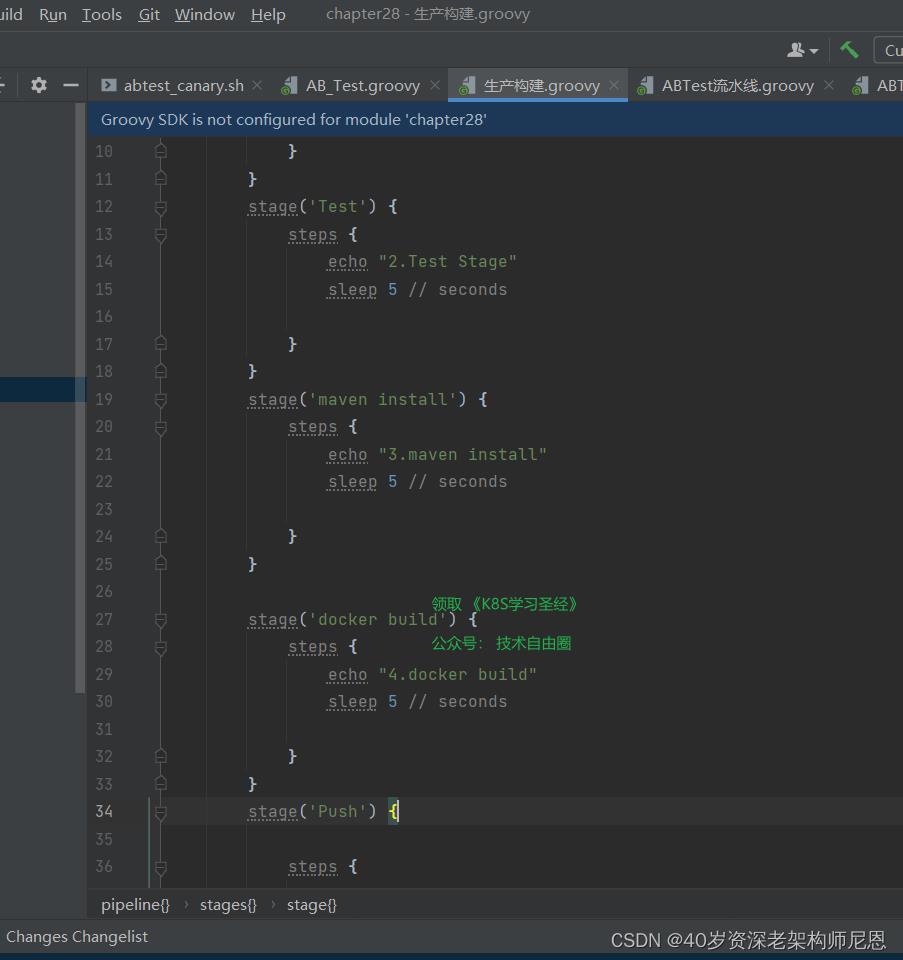
具体的步骤,大概如下:
1、克隆 springboot代码项目到本地
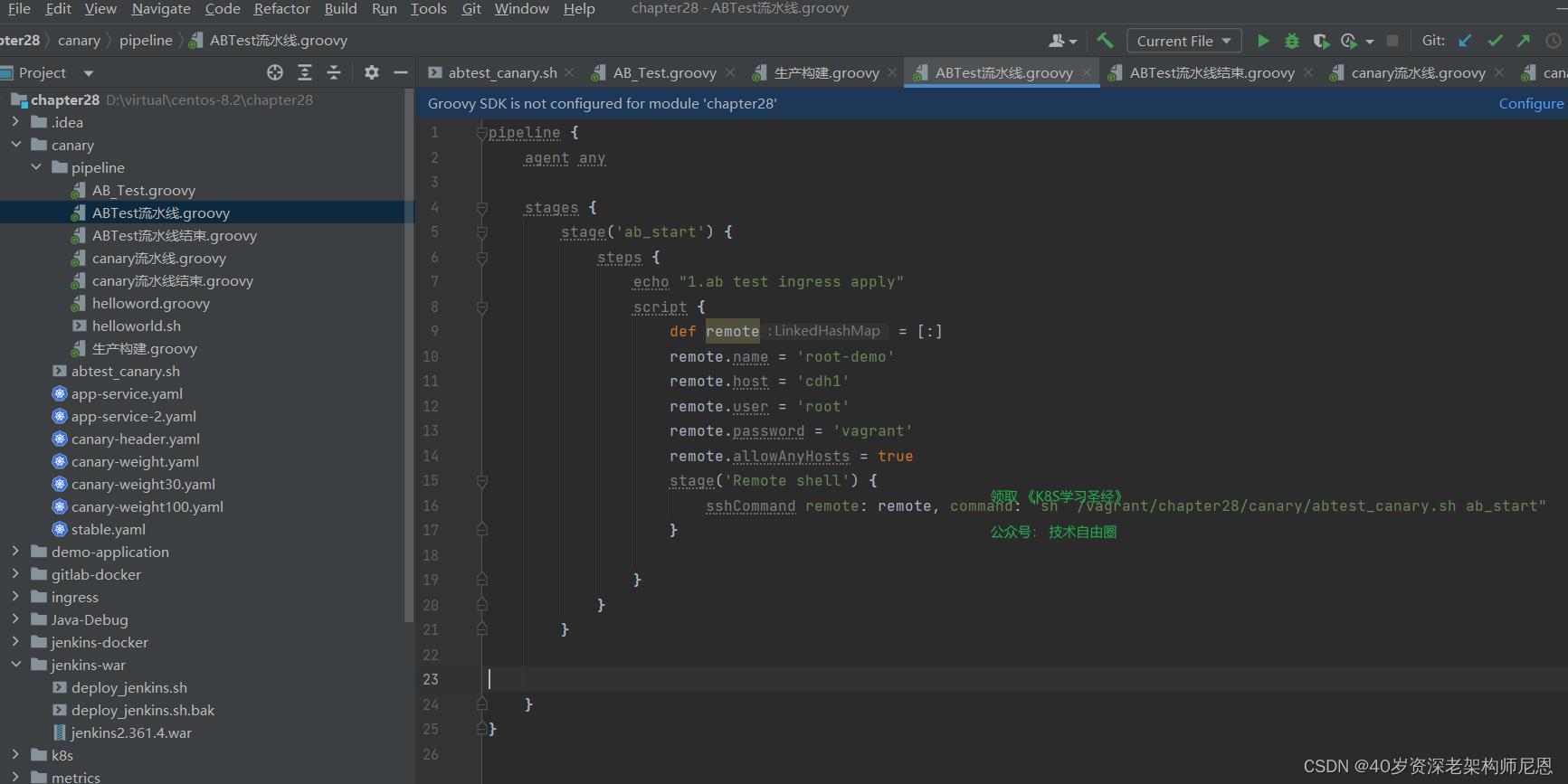
stage(\'Clone\')
echo "1.Clone Stage"
git url: "https://gitee.com/xujk-27400861/springboot-dubbo.git"
script
build_tag = sh(returnStdout: true, script: \'git rev-parse --short HEAD\').trim()
echo "$build_tag"
2、maven构建springboot代码项目
编写脚本,因为我们要编译构建项目的子项目,所以需要跳转到子目录去构建
stage(\'执行构建\')
container(\'maven\')
sh "mvn --version"
sh \'pwd\'
sh \'\'\'cd provider/
mvn clean package -DskipTests\'\'\'
//sh \'mvn package\'
echo \'构建完成\'
provider/为项目子目录,我们要编译的项目;-DskipTests参数,表示跳过代码测试
3、构建docker镜像
编写脚本,构建docker镜像;
stage(\'Build\')
echo "3.Build Stage"
container(\'docker\')
sh "docker -v"
sh \'pwd\'
sh """cd /home/jenkins/agent/workspace/linetest/provider/
ls
docker build -t xjk27400861/springbootapp:$build_tag ."""
4、推送docker镜像到harber上,完成制品发布
编写脚本,推送docker镜像;
stage(\'Push\')
echo "4.Push Docker Image Stage"
container(\'docker\')
sh "docker login --username=xjk27400861 -p xujingkun@123"
sh "docker push xjk27400861/springbootapp:$build_tag"
具体的实操,请参见 尼恩的云原生视频。
step2:生产环境进行 A/B 测试
进行 A/B 测试流程如下:
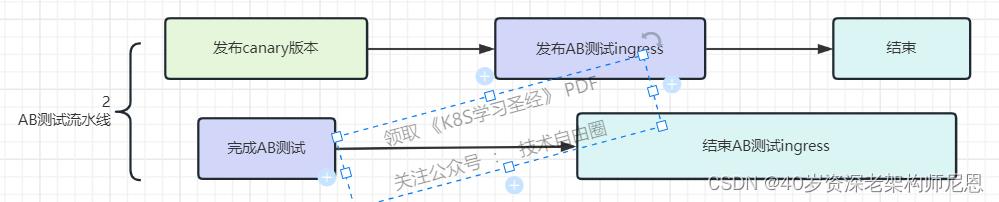
进行 A/B 测试时,只有 Header 包含 location=beijing 可以访问新版本,其他用户访问生产环境仍然为旧版本。
或者header可以设置为其他的参数。
这里要注意,可以把参与 A/B 测试 的用户,在数据库里边进行配置, 前端能带有AB测试的标志。
AB测试手动触发,流水线比较简单。
发布AB测试的ingress之后, 流量分发的架构图如下:
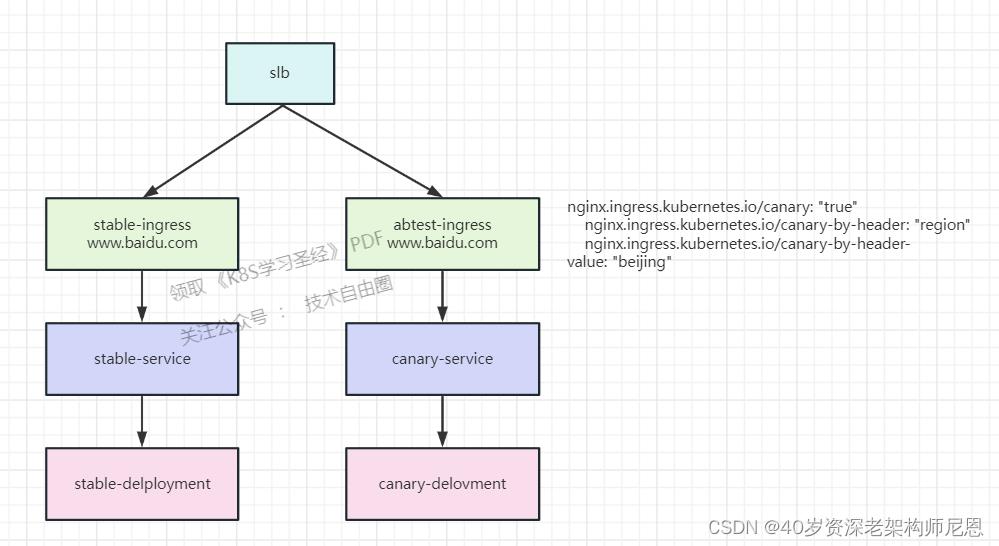
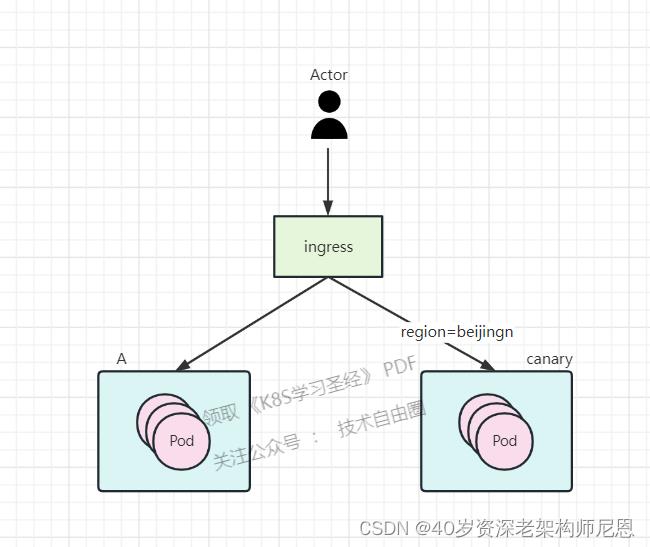
A/B 测试原理:
部署了两套应用,一套旧的稳定的stable应用,一套新版canary 灰度应用。
新旧的应用都配置了ingress相同的host。
而新的ingress还添加了注解canary:true 代表开启使用灰度发布
kubernetes.io/ingress.class: "nginx"
nginx.ingress.kubernetes.io/canary: "true"
nginx.ingress.kubernetes.io/canary-by-header: "region"
nginx.ingress.kubernetes.io/canary-by-header-value: "beijing"
只有 Header 包含 location=beijing 的流量是会从new-ingress这个ingress进来访问新版本应用。
其他流量从old-ingress的ingress去访问老版本的应用。
具体的实操,请参见 尼恩的云原生视频。
step3:生产环境进行 A/B 测试
在AB测试通过之后,可以结束ab测试的ingress,通过 流水线结束。
接下来,开始灰度,一共四轮灰度
第一次灰度:新版本 30% 的灰度比例,此时访问生产环境大约有 30% 的流量进入新版本灰度环境:
30s 后自动进行第二轮灰度:新版本 60% 的灰度比例:
60s 后自动进行第三轮灰度:新版本 90% 的灰度比例:
60s 后自动进行第四轮灰度:新版本 100% 的灰度比例:
每一轮灰度,可以两种方式步进:
(1) 人工确认:是否自动灰度发布, 流水线上设置确认按钮, 单击确认进入下一步
(2) 定时步进:流水线上设置时间,比如每轮间隔 30s
本案例中,配置了定时步进方式,渐进式进行,每次持续 30s 后自动进入下一个灰度阶段。
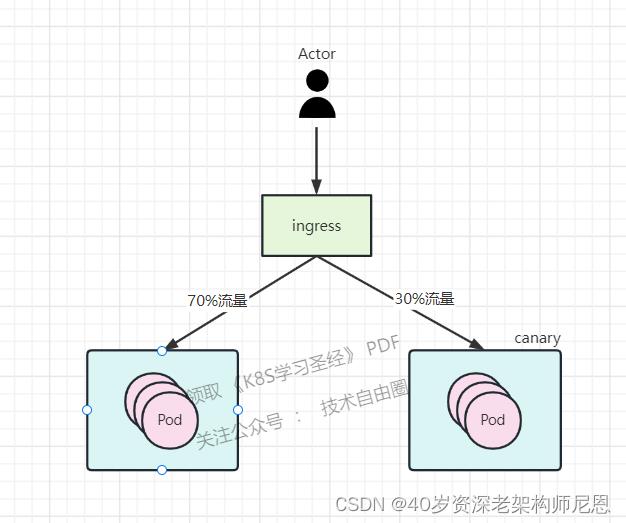
灰度过程中的流量架构图,大致如下:
 在不同的灰度阶段,会发现请求新版本出现的概率越来越高。
在不同的灰度阶段,会发现请求新版本出现的概率越来越高。
灰度流水线的示意图如下;
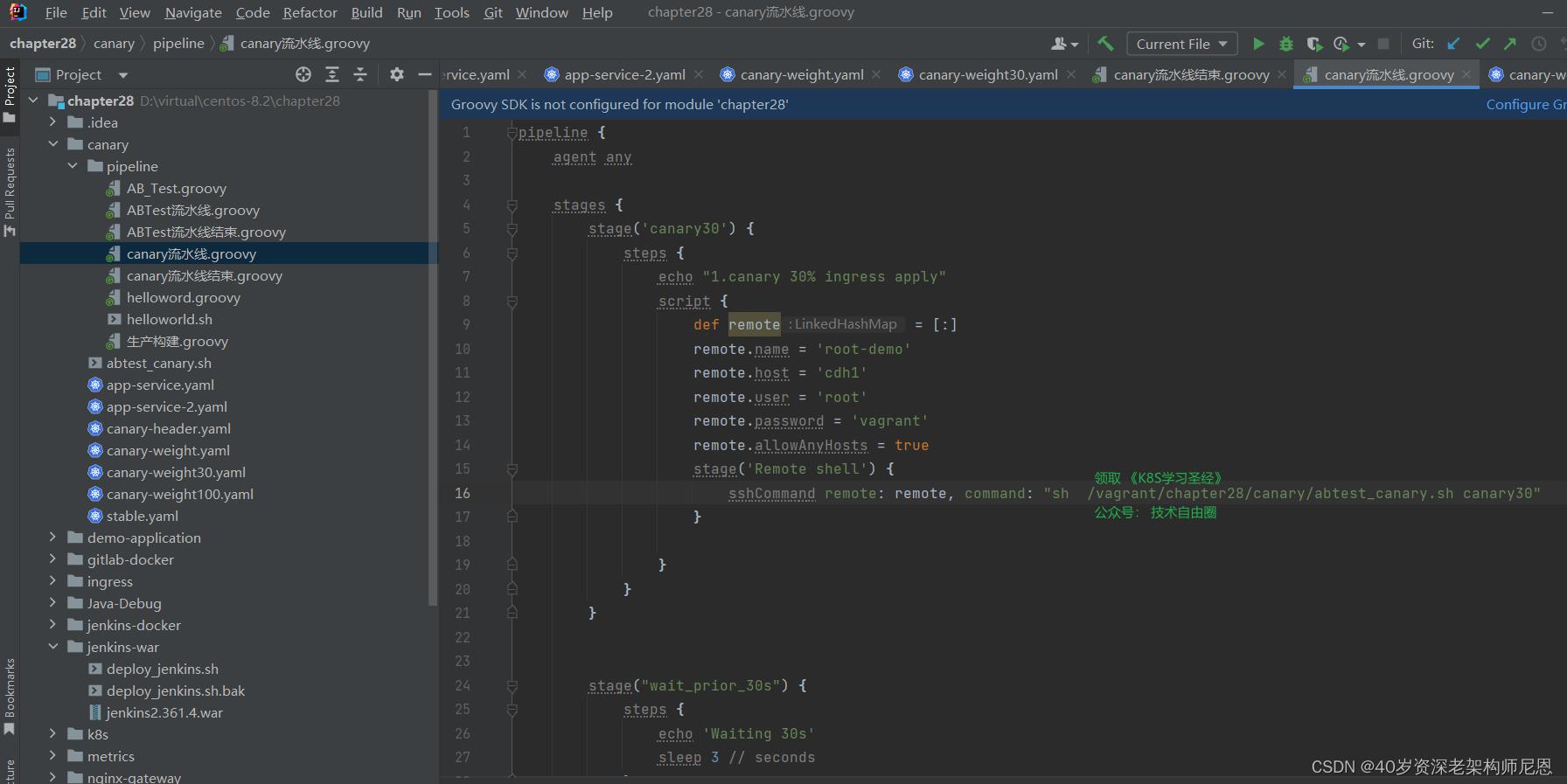
如果过程当中需要回退,可以结束流水线,然后执行 灰度撤销流水线。
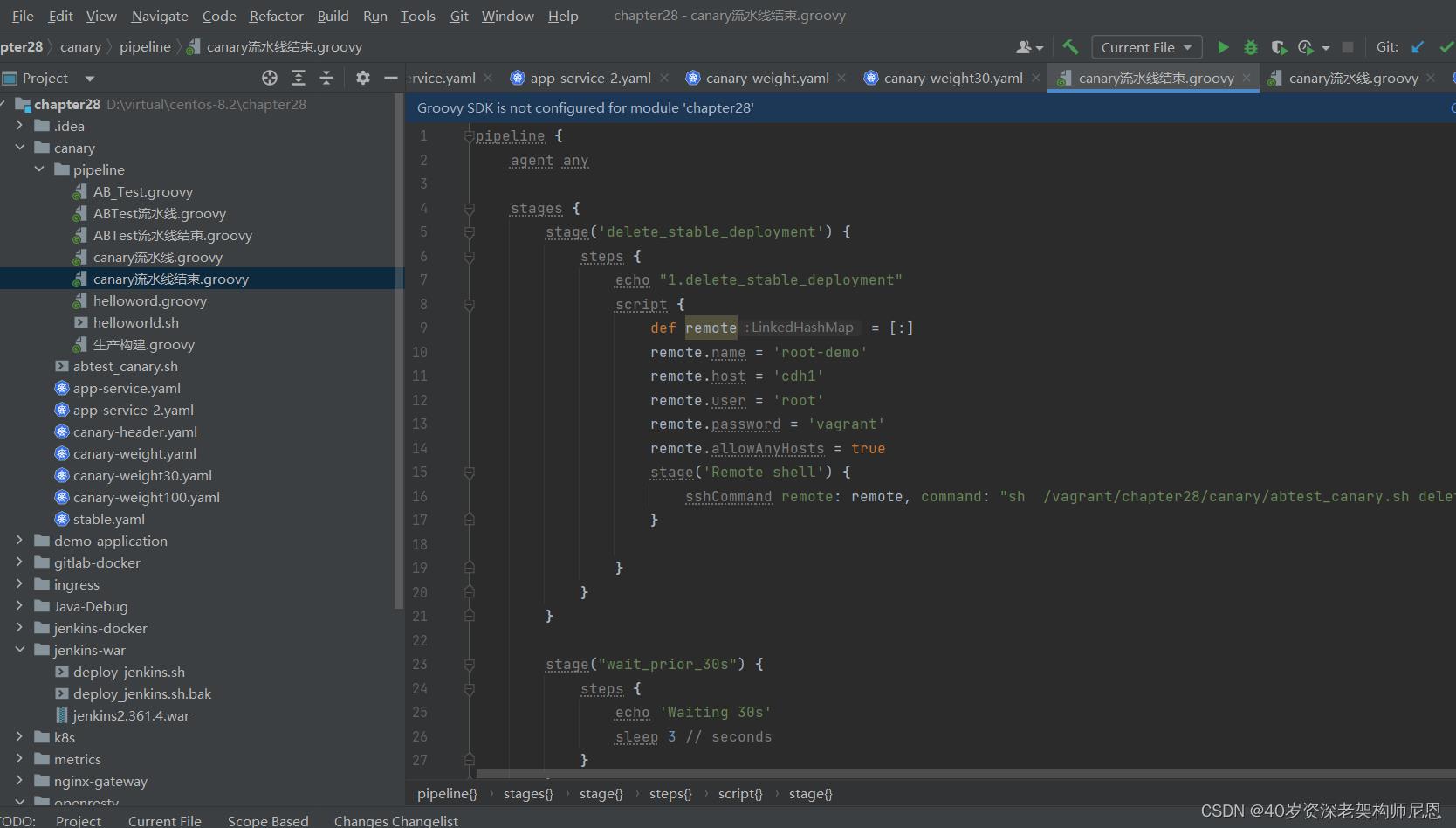
灰度撤销流水线的示意图,大致如下
jenkins 流水线上,更多的是shell脚本的编写
由此可见,shell脚本的编写能力,是多么重要
具体的实操,请参见 尼恩的云原生视频。
step4:生产环境进行版本正式切换
灰度版本稳定一段时间之后, 进行善后的工作
把老的稳定版本去掉, 完成生产环境进行版本正式切换
流程图如下:
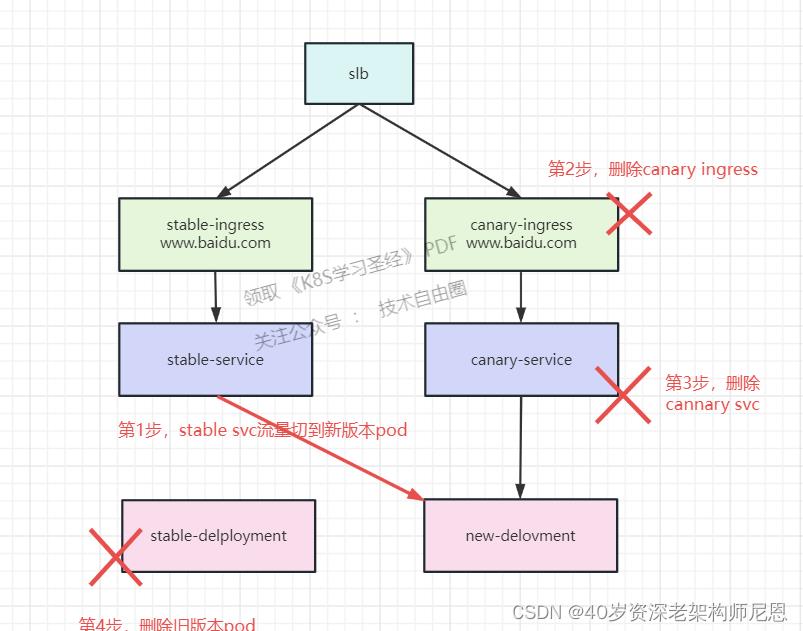
步骤:
1、把stable-service指向访问cannary-deloyment
应为canary 已经足够稳定了
2、删除canary-ingress
不需要 灰度的ingress 了
3、删除canary-service
不需要灰度的svc 了
4、删除stable-deployment
不需要 老的stable-deployment 了
canary deployment 已经足够稳定了,已经编程新的stable deployment
具体的实操,请参见 尼恩的云原生视频。
最后总结一下
上面的灰度流程, 很多环节也是手动的,需要人工参与的。
如果不需要手动参与,可以使用argo-rollouts结合argocd进行灰度发布,argo-rollouts自定义了一套CRD用于控制发布流程,可以省去很多手动操作过程,argocd是基于gitops实现的一套软件,便于我们进行CD控制,也提供了UI面板进行操作。
但是线上发布, 是非常重要,非常谨慎的一个操作。
而且很容易出问题,及时有预发布环境, 也容易出问题, 常常出现紧急回退的场景。
在尼恩亲手尽力的几百次发布过程中, 回退是大概率事件。
常常进行版本回退。
所以,不建议使用全自动的发布流程,全自动无值守,往往意味着高风险。
一句话:背锅的滋味,不好受呀。
技术自由的实现路径:
实现你的 架构自由:
《阿里二面:千万级、亿级数据,如何性能优化? 教科书级 答案来了》
《峰值21WQps、亿级DAU,小游戏《羊了个羊》是怎么架构的?》
… 更多架构文章,正在添加中
实现你的 响应式 自由:
这是老版本 《Flux、Mono、Reactor 实战(史上最全)》
实现你的 spring cloud 自由:
《Spring cloud Alibaba 学习圣经》 PDF
《分库分表 Sharding-JDBC 底层原理、核心实战(史上最全)》
《一文搞定:SpringBoot、SLF4j、Log4j、Logback、Netty之间混乱关系(史上最全)》
实现你的 linux 自由:
实现你的 网络 自由:
《网络三张表:ARP表, MAC表, 路由表,实现你的网络自由!!》
实现你的 分布式锁 自由:
实现你的 王者组件 自由:
《队列之王: Disruptor 原理、架构、源码 一文穿透》
《缓存之王:Caffeine 源码、架构、原理(史上最全,10W字 超级长文)》
《Java Agent 探针、字节码增强 ByteBuddy(史上最全)》
实现你的 面试题 自由:
以上是关于K8S学习圣经6:资源控制+SpringCloud动态扩容原理和实操的主要内容,如果未能解决你的问题,请参考以下文章
K8S学习圣经:大白话说K8S底层原理,14W字实现K8S自由
微服务圣经1:零基础搭建一套SpringCloud微服务脚手架(SpringCloud+Dubbo+Docker+Jenkins)