K8S学习圣经5:Pod负载管理的十八般兵器
Posted 疯狂创客圈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了K8S学习圣经5:Pod负载管理的十八般兵器相关的知识,希望对你有一定的参考价值。
文章很长,持续更新,建议收藏起来,慢慢读!疯狂创客圈总目录 博客园版 为您奉上珍贵的学习资源 :
免费赠送 :《尼恩Java面试宝典》 持续更新+ 史上最全 + 面试必备 2000页+ 面试必备 + 大厂必备 +涨薪必备
免费赠送 :《尼恩技术圣经+高并发系列PDF》 ,帮你 实现技术自由,完成职业升级, 薪酬猛涨!加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷1)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷2)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷3)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 资源宝库: Java 必备 百度网盘资源大合集 价值>10000元 加尼恩领取
Kubernets学习圣经:底层原理和实操
说在前面:
现在拿到offer超级难,甚至连面试电话,一个都搞不到。
尼恩的技术社群中(50+),很多小伙伴凭借 “左手云原生+右手大数据”的绝活,拿到了offer,并且是非常优质的offer,据说年终奖都足足18个月。
而云原生的核心组件是 K8S,但是 K8S 又很难。Kubernets 简称 k8s,用于自动部署,扩展和管理容器化应用程序的开源系统。也就是能帮我们部署和管理分布式系统。

市面上很多的pdf和视频,都是从技术角度来说的,讲的晦涩难懂。
在这里,尼恩从架构师视角出发,基于自己的尼恩Java 架构师知识体系和知识宇宙,对K8S的核心原理做一个宏观的介绍, 一共十二部分, 组成一本《K8S学习圣经》PDF
《K8S学习圣经》 带大家穿透K8S,实现K8S自由,让大家不迷路。
注:本文以 PDF 持续更新,最新尼恩 架构笔记、面试题 的PDF文件,请从这里获取:码云
《K8S学习圣经》的组成
- 第一部分:云原生(Cloud Native)的原理与演进
- 第二部分:穿透K8S的8大宏观架构
- 第三部分:最小化K8s环境实操
- 第四部分:Kubernetes 基本概念
- 第五部分:Kubernetes 工作负载
- 第六部分:Kubernetes 的资源控制
- 第七部分: SVC负载均衡底层原理
- 第八部分: Ingress底层原理和实操
- 第九部分: 蓝绿发布、金丝雀发布、滚动发布、A/B测试 实操
- 第十部分: 服务网格Service Mesh 宏观架构模式和实操
- 第十一部分: 使用K8S+Harber 手动部署 Springboot 应用
- 第十二部分: CICD核心实操 :jenkins流水线部署springboot应用到k8s集群
- 第十三部分: k8s springboot 生产实践(高可用部署、基于qps动态扩缩容、prometheus监控)
- 第十四部分:k8s生产环境容器内部JVM参数配置解析及优化
米饭要一口一口的吃,不能急。
结合《K8S学习圣经》,尼恩从架构师视角出发,左手云原生+右手大数据 +SpringCloud Alibaba 微服务 核心原理做一个宏观的介绍。由于内容确实太多, 所以写多个pdf 电子书:
(1) 《 Docker 学习圣经 》PDF (V1已经完成)
(2) 《 SpringCloud Alibaba 微服务 学习圣经 》PDF (V1已经完成)
(3) 《 K8S 学习圣经 》PDF (coding…)
(4) 《 flink + hbase 学习圣经 》PDF (planning …)
以上学习圣经,并且后续会持续升级,从V1版本一直迭代发布。 就像咱们的《 尼恩 Java 面试宝典 》一样, 已经迭代到V60啦。
40岁老架构师尼恩的掏心窝: 通过一系列的学习圣经,带大家穿透“左手云原生+右手大数据 +SpringCloud Alibaba 微服务“ ,实现技术 自由 ,走向颠覆人生,让大家不迷路。
本PDF 《K8S 学习圣经》完整版PDF的 V1版本,后面会持续迭代和升级。供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
以上学习圣经的 基础知识是 尼恩的 《 高并发三部曲 》,建议在看 学习圣经之前,一定把尼恩的《 Java高并发三部曲 》过一遍,切记,切记。
第四部分:Kubernetes 基本概念
1、基础概念理解
K8S集群 是一组节点,这些节点可以是物理服务器或者虚拟机之上安装了Kubernetes平台。
K8S平台是一个围绕容器打造的分布式系统,和其他的分布式系统比如rocketmq、kafka、elasticsearch在宏观上是非常类似的。

具体介绍,请参见前面的尼恩架构视频。
etcd是Kubernetes提供默认的存储系统,保存所有集群数据,使用时需要为etcd数据提供备份计划。
K8S集群
集群 Node 分为两个核心大组件:
- master :worker 管理+元数据管理
- worker(node): 容器的生命周期管理
Node 1:master 管理节点
master 负责worker 管理+元数据管理
master 上的主要组件是 api-server + 一大堆的控制器
Node 2:worker计算节点
worker 上主要的组件就是 kubelet (容器管理)+ kube-proxy(流量负载均衡)
Node的核心组件
node组件运行在每一个节点上,包括master和worker节点,负责运维运行中pod并负责提供k8s运行环境。
核心组件1: kubelet
此组件是运行在每一个集群节点上的代理程序,它确保pod 中的容器处于运行状态。kubelet通过多种途径获取PodSpec定义,并确保PodSpec定义中所描述的容器处于运行和监控的状态。
node节点上创建、删除容器并利用探针进行健康性检查,向apiserver汇报pod状态和资源利用率,只要在结点上有操作动作,都归kubelet管
核心组件2: kube-proxy
kube-proxy 是一个网络代理程序,运行在集群的每一个节点上,是实现kubernets Service概念的重要部分。
kube-proxy在节点上维护网络规则,这些规则可以在集群内外正确的于Pod进行网络通信。
如果操作系统中存在packet filtering layer, kube-porxy将使用这一特性,(iptabes代理模式),否则,kube-proxy将自行转发网络请求(User space代理模式)
在node节点维护iptables转发和ipvs规则,保持容器间的正常网络通讯,
每个节点上都会有一个kubelet和kebu-proxy
核心组件3: 容器引擎
容器引擎负责运行容器,支持多种容器,包括docker,containderd,cri-o,rktlet以及任何实现的k8s容器引擎接口的容器引擎。
Pod
K8s应用最终以Pod为一个基本单位部署
Pod安排在节点上,包含一组容器和卷。
同一个Pod里的可以有一个容器,也可以多个容器。
同一个Pod里的容器共享同一个网络命名空间,可以使用localhost互相通信。Pod是短暂的,不是持续性实体。
Label
很多资源都可以打标签
一些pod有Lable,一个label 是attach到pod的一堆键值对,用来传递用户定义的属性。
比如通过label来标记前端pod容器,使用label标记后端pod容器。
然后使用selectors选择带有特定label的pod。
Deployment
应用部署用它,deployment最终会产生Pod
Service
负载均衡机制
Addons
Addons使用k8s资源( DaemonSet,Deployment等)实现集群级别的功能特性。
Addons 可以理解为 附件, 扩展, 插件。
Addons 由于提供集群级别的功能特性,
Addons 使用到的kubernetes 资源都放在kube-system名称空间下。
以下为常用的Addons
(1) DNS : 集群内布DNS解析
(2)dashborad:用户图形界面
(3)resource-usage-monitoring:容器资源监测
(4) Cluster-level Logging:集群层面日志
除了DNS Addon以外,其他的addon都不是必须的,所有的kubernetes 集群都应该有Cluster DNS
DNS
Cluster DNS 是一个 DNS 服务器,是对您已有环境中其他 DNS 服务器的一个补充,存放了 Kubernetes Service 的 DNS 记录。
Kubernetes 启动容器时,自动将该 DNS 服务器加入到容器的 DNS 搜索列表中。
Web UI (Dashboard)
Dashboard (opens new window)是一个Kubernetes集群的 Web 管理界面。用户可以通过该界面管理集群。
2、k8s对象(kubernetes Objects)
上面讲到, k8s里面操作的资源实体,就是k8s的对象,可以使用yaml来声明对象。
对象的yaml结构
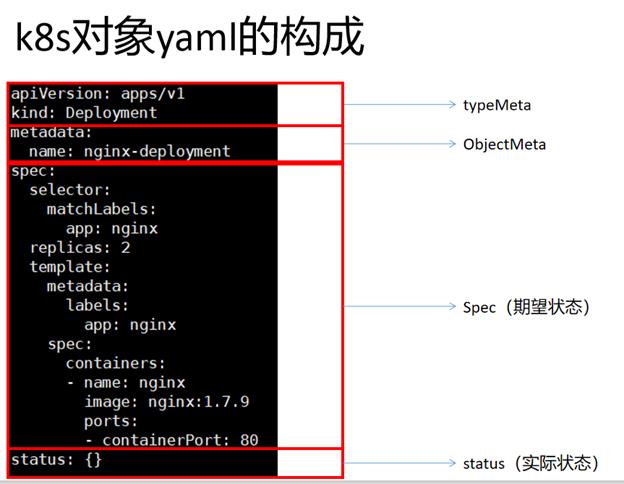
在上述的 .yaml 文件中,如下字段是必须填写的:
- apiVersion用来创建对象时所使用的Kubernetes API版本
- kind被创建对象的类型
- metadata用于唯一确定该对象的元数据:包括name 和namespace,如果namespace 为空,则默认值为default
- spec描述您对该对象的期望状态
不同类型的 Kubernetes,其 spec 对象的格式不同(含有不同的内嵌字段),通过 API 手册 (opens new window)可以查看 Kubernetes 对象的字段和描述。
说明:
不同类型的 Kubernetes,其
spec对象的格式不同(含有不同的内嵌字段),通过 API 手册 可以查看 Kubernetes 对象的字段和描述。例如,
假设您想了解 Pod 的 spec 定义,可以在 这里 找到,
Deployment 的 spec 定义可以在 这里 找到
https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.21/
这就是我们以后要完全参照的文档。
关于 yaml文件的分割
多个资源对象的yaml文件,比如Deployment和Service ,可以放在一个文件,可以放在不同的yaml文件中单独执行,
如果放在同一个yaml文件中,需要用连续的三个短横线隔开。
2.1、一个简单的Kubernetes API 对象
Kubernetes 资源对象, 都是使用 API 对象 来配置。
kubernetes 推荐使用 配置文件 运行一个或者多个容器,当然也支持命令行方式。
API 对象 的配置文件可以是:
- yaml 格式的文件
- json 格式的文件
yaml 文件比较易读,因此后面都会使用 yaml 风格的文件去描述一个 kubernetes 对象的各种属性。
即:把容器的定义、参数、配置,统统记录在一个 YAML 文件中,然后用这样一句指令把它运行起来:
kubectl apply -f 资源对象的配置文件
例子:
kubectl apply -f demo-Provider.yml

使用配置文件的好处是,可以很好的记录下 kubernetes 都运行了什么。
下面是一个运行 nginx 容器的例子
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.8
ports:
- containerPort: 80
保存以上内容到一个 .yml 结尾的文件中, 这里用的是 nginx.yml
像这样的一个 YAML 文件,对应到 Kubernetes 中,就是一个 API Object(API 对象)。
其中的 属性,简单介绍如下:
apiVersion 指定 Kubernetes API 的版本
metadata API 对象的元数据,它也是我们从 Kubernetes 里找到这个对象的主要依据。都是 key-value 的形式,这部分的内容大部分的 API 对象都一样。
kind 指定了这个 API 对象的类型(Type)这里的类型是 Deployment。
Deployment 就是负责在 Pod 定义发生变化时,对每个副本进行滚动更新(Rolling Update)。
spec 就是对具体的 API 对象进行详细描述。这部分每个 API 对象都有自己的特征,所以内容也不一样。
selector 是一个选择器,对需要调度的目标对象进行筛选。
是针对 spec.template.metadata.labels 下定义的键值对进行筛选的。
replicas 指定副本的个数
template 定义 Pod的模板,也就是 Pod 的具体长什么样子
containers 定义关于 Pod 中容器的相关属性
当你为这个对象的各个字段填好值并提交给 Kubernetes 之后,Kubernetes 就会负责创建出这些对象所定义的容器或者其他类型的 API 资源。
要运行它,执行如下命令:
kubectl apply -f nginx.yml
其实上面这样一个 YAML 文件中定义的都是 Kubernetes API 对象。
在 Kubernetes 系统中,Kubernetes 对象 是持久化的实体。Kubernetes 使用这些实体去表示整个集群的状态。
特别地,它们描述了如下信息:
- 哪些容器化应用在运行(以及在哪些节点上)
- 可以被应用使用的资源
- 关于应用运行时表现的策略,比如重启策略、升级策略,以及容错策略
Kubernetes 对象是 “目标性记录” —— 一旦创建对象,Kubernetes 系统将持续工作以确保对象存在。
通过创建对象,本质上是在告知 Kubernetes 系统,所需要的集群工作负载看起来是什么样子的, 这就是 Kubernetes 集群的 期望状态(Desired State)。
什么是k8s 资源对象
官方的介绍
https://kubernetes.io/zh/docs/concepts/overview/working-with-objects/kubernetes-objects/
API 对象 的配置文件可以是:
- yaml 格式的文件
- json 格式的文件
有了配置文件之后, 然后让k8s根据yaml的声明创建出这个对象;
kubectl apply/create/run /expose. . .
要点1:对象的创建、修改,或者删除,都需要用到 Kubernetes API
操作 Kubernetes 对象 —— 无论是创建、修改,或者删除 —— 需要使用Kubernetes API 。
比如,当使用 kubectl 命令行接口时,CLI 会执行必要的 Kubernetes API 调用
要点2:对象Kubernetes系统的持久化实体,通过etcd持久化
Kubernetes对象指的是Kubernetes系统的持久化实体,所有这些对象合起来,代表了你集群的实际情况。
常规的应用里,我们把应用程序的数据存储在数据库中,Kubernetes将其数据以Kubernetes对象的形式通过 api server存储在 etcd 中。
具体来说,这些数据(Kubernetes对象)描述了:
- 集群中运行了哪些容器化应用程序(以及在哪个节点上运行)
- 集群中对应用程序可用的资源(网络,存储等)
- 应用程序相关的策略定义,例如,重启策略、升级策略、容错策略
- 其他Kubernetes管理应用程序时所需要的信息
kubernetes 对象必需字段
在想要创建的 Kubernetes 对象对应的 .yaml 文件中,需要配置如下的字段:
- apiVersion - 创建该对象所使用的 Kubernetes API 的版本
- kind - 想要创建的对象的类别,比如 Pod, Deployment,Service 等
- metadata - 帮助唯一性标识对象的一些数据,包括一个 name 字符串、 UID 和可选的 namespace
你也需要提供对象的 spec 字段。
对象 spec 的精确格式对每个 Kubernetes 对象来说是不同的,包含了特定于该对象的嵌套字段。
2.2、kubernetes API的版本
k8s是分布式系统,它本身有各个组件,各个组件之间的通信,对外提供的都是rest接口的http服务。
这些接口就统称为 k8s API。
k8s的api也很有特点,首先它是分组的,它有很多api组。这些api组都有不同的功能,有的api组负责权限,有的api组负责存储。
每个api组还有版本的区分,它其实也有大小版本区分,但是不是我们常用的1.1.1这种版本号,k8s api 大的版本都是以v1, v2 这种为迭代的,
每个大的版本里面区别三个等级
第一种是Alpha等级,这个等级就是还在调试的,基本我们不作为开发者的话,这种等级的接口版本不会接触到。
它会在大版本后面直接跟着alpha,比如v1alpha2, 就代表是v1大版本的alpha等级第2小版本。
第二个等级就是Beta等级,这个等级说明接口基本可以使用了,也经过完整测试了。
会比正常的稳定版本有更多的功能。它的版本格式如v1beta2。
第三个等级就是Stable版本,这个等级说明这个是个稳定版,可以放心使用。
一、查看apiversion 可用版本
查看apiversion 可用版本,在k8s中查看apiversion可用版本的命令如下:
kubectl api-versions
或
sudo kubectl api-versions
在安装有k8s的机器上执行命令,可用看到类似如下的输出:

二、各种apiVersion的含义
1、alpha
- 该软件可能包含错误。启用一个功能可能会导致bug。
- 随时可能会丢弃对该功能的支持,恕不另行通知。
2、beta
- 软件经过很好的测试。启用功能被认为是安全的。
- 默认情况下功能是开启的。
- 细节可能会改变,但功能在后续版本不会被删除。
3、stable
- 该版本名称命名方式:vX这里X是一个整数。
- 稳定版本、放心使用。
- 将出现在后续发布的软件版本中。
4、v1
- Kubernetes API的稳定版本,包含很多核心对象:pod、service等。
5、apps/v1beta2
- 在kubernetes1.8版本中,新增加了
apps/v1beta2的概念,apps/v1beta1同理。
DaemonSet,Deployment,ReplicaSet 和StatefulSet的当时版本迁入apps/v1beta2,兼容原有的extensions/v1beta1。
6、apps/v1
- 在
kubernetes1.9版本中,引入apps/v1,deployment等资源从extensions/v1beta1,
apps/v1beta1和apps/v1beta2迁入apps/v1,原来的v1beta1等被废弃。
apps/v1代表:包含一些通用的应用层的api组合,如:Deployments, RollingUpdates, and ReplicaSets。
7、batch/v1
- 代表job相关的api组合。
在kubernetes1.8版本中,新增了batch/v1beta1,后CronJob 已经迁移到了
batch/v1beta1,然后再迁入batch/v1。
8、autoscaling/v1
- 代表自动扩缩容的api组合,kubernetes1.8版本中引入。 这个组合中后续的alpha 和
beta版本将支持基于memory使用量、其他监控指标进行扩缩容。
9、extensions/v1beta1
- deployment等资源在1.6版本时放在这个版本中,后迁入到apps/v1beta2,再到apps/v1中统一管理。
10、certificates.k8s.io/v1beta1
- 安全认证相关的api组合。
11、authentication.k8s.io/v1
- 资源鉴权相关的api组合。
补充说明:Kubernetes的官方文档中并没有对apiVersion的详细解释,而且因为K8S本身版本也在快速迭代,有些资源在低版本还在beta阶段,到了高版本就变成了stable。
2.3、获取各个属性字段的含义
kubernetes 对象的定义字段,非常多,
如果 需要了解 各个属性字段的含义,有两个方式:
方式1:从命令行获取方式
方式2:官方 API 文档方式
方式1:从命令行获取方式
kubectl explain 查看 创建对象所使用的API版本,
比如: kubectl explain deloyment.apiVersion命令获取deloyment的 api 版本。
kubectl explain pod
kubectl explain deployment
kubectl explain deployment.spec
kubectl explain deployment.spec.template
方式2:官方 API 文档方式
Kubernetes API 参考 能够帮助我们找到任何我们想创建的对象的 spec 格式。
例如:
- 可以从 core/v1 PodSpec 查看 Pod 的 spec 格式
- 可以从 apps/v1 DeploymentSpec 查看 Deployment 的 spec 格式。
2.4、管理k8s对象
Kubernetes对象指的是Kubernetes系统的持久化实体,所有这些对象合起来,代表了你集群的实际情况。常规的应用里,我们把应用程序的数据存储在数据库中,Kubernetes将其数据以Kubernetes对象的形式通过 api server存储在 etcd 中。具体来说,这些数据(Kubernetes对象)描述了:
- 集群中运行了哪些容器化应用程序(以及在哪个节点上运行)
- 集群中对应用程序可用的资源
- 应用程序相关的策略定义,例如,重启策略、升级策略、容错策略
- 其他Kubernetes管理应用程序时所需要的信息
一个Kubernetes对象代表着用户的一个意图(a record of intent),一旦您创建了一个Kubernetes对象,Kubernetes将持续工作,以尽量实现此用户的意图。创建一个 Kubernetes对象,就是告诉Kubernetes,您需要的集群中的工作负载是什么(集群的 目标状态)。
| 管理方式 | 操作对象 | 推荐的环境 | 参与编辑的人数 | 学习曲线 |
|---|---|---|---|---|
| 指令性的命令行 | Kubernetes对象;kubectl xxxxx。 cka | 开发环境 | 1+ | 最低 |
| 指令性的对象配置 | 单个 yaml 文件 | 生产环境 | 1 | 适中 |
| 声明式的对象配置 | 包含多个 yaml 文件的多个目录。kustomize | 生产环境 | 1+ | 最高 |
同一个Kubernetes对象应该只使用一种方式管理,否则可能会出现不可预期的结果
1、命令式
用户通过向 kubectl 命令提供参数的方式,直接操作集群中的 Kubernetes 对象。
命令式 就是 命令行 的模式,一个一个的敲命令。
kubectl run nginx --image nginx
kubectl create deployment nginx --image nginx
apply -f : 没有就创建,有就修改
此时,用户无需编写或修改 .yaml 文件。
这是在 Kubernetes 集群中执行一次性任务的一个简便的办法。
由于这种方式直接修改 Kubernetes 对象,也就无法提供历史配置查看的功能。
优点
与编写.yaml文件进行配置的方式相比,优点
- 命令简单,容易记忆
- 只需要一个步骤,就可以对集群执行变更
缺点
- 无法进行review管理
- 不提供日志审计
- 没有创建新对象的模板
2、指令性
使用指令性的对象配置(imperative object configuration)时,需要向 kubectl 命令指定具体的操作(create,replace,apply,delete等),
可选参数以及至少一个配置文件的名字。
配置文件中必须包括一个完整的对象的定义,可以是 yaml 格式,也可以是 json 格式。
#创建对象
kubectl create -f nginx.yaml
#删除对象
kubectl delete -f nginx.yaml -f redis.yaml
#替换对象
kubectl replace -f nginx.yaml
与指令性命令行相比的优点:
- 对象配置文件可以存储在源代码管理系统中,例如 git
- 对象配置文件可以整合进团队的变更管理流程,并进行审计和复核
- 对象配置文件可以作为一个模板,直接用来创建新的对象
与指令性命令行相比的缺点:
- 需要理解对象配置文件的基本格式
- 需要额外编写 yaml 文件
与声明式的对象配置相比的优点:
- 指令性的对象配置更简单更易于理解
- 指令性的对象配置更成熟
与声明式的对象配置相比的缺点:
- 指令性的对象配置基于文件进行工作,而不是目录
- 如果直接更新 Kubernetes 中对象,最好也同时修改配置文件,否则在下一次替换时,这些更新将丢失
3、声明式
当使用声明式的对象配置时,用户操作本地存储的Kubernetes对象配置文件,然后,在将文件传递给 kubectl 命令时,并不指定具体的操作,由 kubectl 自动检查每一个对象的状态并自行决定是创建、更新、还是删除该对象。
使用这种方法时,可以直接针对一个或多个文件目录进行操作(对不同的对象可能需要执行不同的操作)。
示例
处理 configs 目录中所有配置文件中的Kubernetes对象,根据情况创建对象、或更新Kubernetes中已经存在的对象。可以先执行 diff 指令查看具体的变更,然后执行 apply 指令执行变更
kubectl diff -f configs/
kubectl apply -f configs/
#递归处理目录中的内容:
kubectl diff -R -f configs/
kubectl apply -R -f configs/
#移除
kubectl delete -f configs/
与指令性的对象配置相比,优点有:
- 直接针对Kubernetes已有对象的修改将被保留,即使这些信息没有合并到配置文件中。
- 声明式的对象配置可以支持多文件目录的处理,可以自动探测应该对具体每一个对象执行什么操作(创建、更新、删除)
缺点:
- 声明式的对象配置复杂度更高,Debug更困难
- 部分更新对象时,带来复杂的合并操作
2.5、对象名称与ID
Kubernetes REST API 中,可以通过 namespace + name 唯一性地确定一个 RESTFUL 对象,
例如:
/api/v1/namespaces/namespace/pods/name
Names
同一个名称空间下,同一个类型的对象,可以通过 name 唯一性确定。
如果删除该对象之后,可以再重新创建一个同名对象。
依据命名规则,Kubernetes对象的名字应该:
- 最长不超过 253个字符
- 必须由小写字母、数字、减号 - 、小数点 . 组成
- 某些资源类型有更具体的要求
例如,下面的配置文件定义了一个 name 为 nginx-demo 的 Pod,该 Pod 包含一个 name 为 nginx 的容器:
apiVersion: v1
kind: Pod
metadata:
name: nginx-demo ##pod的名字
spec:
containers:
- name: nginx ##容器的名字
image: nginx:1.7.9
ports:
- containerPort: 80 UIDs
UID
Kubernetes 中的 UID 是全局唯一的标识符(UUIDs,符合规范 ISO/IEC 9834-8 以及 ITU-T X.667)
UID 唯一确定一个 Kubernetes 对象,
这个对象不是 RESTFUL 对象 , 是Kubernetes 创建的资源对象
Kubernetes 集群中,每创建一个对象,都有一个唯一的 UID。
UID 用于区分多次创建的同名对象(如前所述,按照名字删除对象后,重新再创建同名对象时,两次创建的对象 name 相同,但是 UID 不同。)
Kubernetes 所有的对象都是通过 UID 唯一性确定
UID 是由 Kubernetes 系统生成的,唯一标识某个 Kubernetes 对象的字符串。
用于区分多次创建的同名 RESTFUL 对象(如前所述,按照名字删除对象后,重新再创建同名对象时,两次创建的对象 name 相同,但是 UID 不同。)
2.6、对象规约(Spec)与状态(Status)
对象规约(Spec)与状态(Status)
几乎每个 Kubernetes 对象包含两个嵌套的对象字段spec、status,它们负责管理对象的配置,两个字段的中文含义:
spec : 对象规约
status : 对象 状态
spec 描述你希望对象所具有的特征: 期望状态(Desired State) 。
status 描述了对象的 当前状态(Current State),它是由 Kubernetes 系统和组件 设置并更新的。
spec 规约
当您在 Kubernetes 中创建一个对象时,您必须提供 对象规约(Spec).,例如如下所述:
- 名称
- 使用什么镜像
- 多少个副本
- 挂载的文件或目录
- 使用多少资源等
spec 是静态的,是存在于 YAML 文件中的。
可以使用 kubectl 命令行创建对象,业可以编写 .yaml 格式的文件进行创建,包含对象规约(Spec)
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2 # 运行 2 个容器化应用程序副本
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
#1、部署
kubectl apply -f deployment.yaml
#2、移除
kubectl delete -f deployment.yaml
集群中所有的资源,都在那里? k8s只依赖一个存储就是etcd。
status 状态
status 描述了对象在系统中的 当前状态(Current State),它是由 Kubernetes 系统和组件 设置并更新的。
在大多数情况下,用户不需要对此进行更改。
使用如下命令可获取:
kubectl get pods 具体的一个容器名称 -o yaml
在任何时刻,Kubernetes 控制平面 都一直积极地管理着对象的实际状态,以使之与期望状态相匹配。
例如,Kubernetes 中的 Deployment 对象能够表示运行在集群中的应用。
当创建 Deployment 时,可能需要设置 Deployment 的 spec,以指定该应用需要有 3 个副本运行。
Kubernetes 系统读取 Deployment 规约,并启动我们所期望的应用的 3 个实例 —— 更新状态以与规约相匹配。
如果这些实例中有的失败了(一种状态变更),Kubernetes 系统通过执行修正操作 来响应规约和状态间的不一致 —— 在这里意味着它会启动一个新的实例来替换。
scheduler先计算应该去哪个节点部署
对象的spec和status
每一个 Kubernetes 对象都包含了两个重要的字段:
spec必须由您来提供,描述了您对该对象所期望的 目标状态status只能由 Kubernetes 系统来修改,描述了该对象在 Kubernetes 系统中的 实际状态Kubernetes通过对应的控制器,不断地使实际状态趋向于您期望的目标状态
关于对象 spec、status 的更多信息,可参阅 [Kubernetes API 约定](community/api-conventions.md at master · kubernetes/community (github.com))。
2.7、名称空间
Kubernetes通过名称空间(namespace)在同一个物理集群上支持多个虚拟集群。
kubectl get namespaces
kubectl describe namespaces <name>
#隔离 mysql mapper.xml--》dao.
Kubernetes 安装成功后,默认有初始化了三个名称空间:
- default 默认名称空间,如果 Kubernetes 对象中不定义 metadata.namespace 字段,该对象将放在此名称空间下
- kube-system Kubernetes系统创建的对象放在此名称空间下
- kube-public 此名称空间自动在安装集群是自动创建,并且所有用户都是可以读取的(即使是那些未登录的用户)。主要是为集群预留的,例如,某些情况下,某些Kubernetes对象应该被所有集群用户看到。
除了默认的命名空间,还可以创建名称空间
apiVersion: v1
kind: Namespace
metadata:
name: my-namespace
kubectl create -f ./my-namespace.yaml
kubectl delete -f ./my-namespace.yaml
#直接用命令
kubectl create namespace <名称空间的名字>
#删除
kubectl delete namespaces <名称空间的名字>
名称空间的名字必须与 DNS 兼容:
- 不能带小数点
. - 不能带下划线
_ - 使用数字、小写字母和减号 - 组成的字符串
默认情况下,安装Kubernetes集群时,会初始化一个 default 名称空间,用来将承载那些未指定名称空间的 Pod、Service、Deployment等对象
创建了命名空间之后,可以使用命名空间,为请求设置命名空间
#要为当前请求设置命名空间,请使用 --namespace 参数。
kubectl run nginx --image=nginx --namespace=<insert-namespace-name-here> kubectl get pods --namespace=<insert-namespace-name-here>
#在对象yaml中使用命名空间
apiVersion: v1
kind: Pod
metadata:
name: nginx-demo ##pod的名字
namespace: default #不写就是default
spec:
containers:
- name: nginx ##容器的名字
image: nginx:1.7.9
ports:
- containerPort: 80
名称空间的用途之一是 对象隔离
为不同团队的用户(或项目)提供虚拟的集群空间,也可以用来区分开发环境/测试环境、准上线环境/生产环境。
名称空间为 名称 提供了作用域。
名称空间内部的同类型对象不能重名,但是跨名称空间可以有同名同类型对象。名称空间不可以嵌套,任何一个Kubernetes对象只能在一个名称空间中。
名称空间的用途之二是 团队隔离
名称空间可以用来在不同的团队(用户)之间划分集群的资源,在 Kubernetes 将来的版本中,同名称空间下的对象将默认使用相同的访问控制策略。
注意:当KUbernetes对象之间的差异不大时,无需使用名称空间来区分,例如,同一个软件的不同版本,只需要使用 labels 来区分即可
名称空间的使用参考:
1)基于环境隔离(prod,test)
prod:部署的所有应用
test:部署的所有应用
2)基于产品线的名称空间(商城,android,ios,backend);
3)基于团队隔离
如何访问其他名称空间的东西?
原则是:名称空间资源隔离,网络不隔离
1)不能访问其他 名称空间下的配置,如果把其他空间的配置直接拿来用,是不可以的。
2)但是,可以访问其他空间的网络地址,网络地址没有屏蔽。
查看名称空间
执行命令 kubectl get namespaces 可以查看名称空间,输出结果如下所示:
NAME STATUS AGEdefault Active 1dkube-system Active 1dkube-public Active 1d
Kubernetes 安装成功后,默认有初始化了三个名称空间:
- default默认名称空间,如果 Kubernetes 对象中不定义metadata.namespace 字段,该对象将放在此名称空间下
- kube-systemKubernetes系统创建的对象放在此名称空间下
- kube-public此名称空间自动在安装集群是自动创建,并且所有用户都是可以读取的(即使是那些未登录的用户)。主要是为集群预留的,例如,某些情况下,某些Kubernetes对象应该被所有集群用户看到。
在执行请求的时设定namespace
执行 kubectl 命令时,可以使用 --namespace 参数指定名称空间,例如:
kubectl run nginx --image=nginx --namespace=<您的名称空间>
kubectl get pods --namespace=<您的名称空间>
设置名称偏好
可以通过 set-context 命令改变当前 kubectl 上下文 的名称空间,后续所有命令都默认在此名称空间下执行
kubectl config set-context --current --namespace=<您的名称空间>
# 验证结果
kubectl config view --minify | grep namespace:
名称空间与DNS
当您创建一个 Service 时,Kubernetes 为其创建一个对应的 DNS 条目。
该 DNS 记录的格式为 <service-name>.<namespace-name>.svc.cluster.local,也就是说,如果在容器中只使用 <service-name>,其DNS将解析到同名称空间下的 Service。
这个特点在多环境的情况下非常有用,例如将开发环境、测试环境、生产环境部署在不同的名称空间下,应用程序只需要使用 <service-name> 即可进行服务发现,无需为不同的环境修改配置。
如果您想跨名称空间访问服务,则必须使用完整的域名(fully qualified domain name,FQDN)
名称空间的作用
一个Kubernetes集群应该可以满足多组用户的不同需要。
Kubernetes名称空间可以使不同的项目、团队或客户共享同一个 Kubernetes 集群。
实现的方式是,提供:
名称 的作用域
为不同的名称空间定义不同的授权方式和资源分配策略Resource Quota 和resource limit range
每一个用户组都期望独立于其他用户组进行工作。通过名称空间,每个用户组拥有自己的:
- Kubernetes 对象(Pod、Service、Deployment等)
- 授权(谁可以在该名称空间中执行操作)
- 资源分配(该用户组或名称空间可以使用集群中的多少计算资源)
可能的使用情况有:
- 集群管理员通过一个Kubernetes集群支持多个用户组
- 集群管理员将集群中某个名称空间的权限分配给用户组中的受信任的成员
- 集群管理员可以限定某一个用户组可以消耗的资源数量,以避免其他用户组受到影响
- 集群用户可以使用自己的Kubernetes对象,而不会与集群中的其他用户组相互干扰
并非所有对象都在命名空间中
大多数 kubernetes 资源(例如 Pod、Service、副本控制器等)都位于某些命名空间中。
但是命名空间资源本身并不在命名空间中。而且底层资源,例如 nodes 和持久化卷不属于任何命名空间。
大部分的 Kubernetes 对象(例如,Pod、Service、Deployment、StatefulSet等)都必须在名称空间里。但是某些更低层级的对象,是不在任何名称空间中的,例如 nodes、persistentVolumes、storageClass 等
执行一下命令可查看哪些 Kubernetes 对象在名称空间里,哪些不在:
# 在名称空间里
kubectl api-resources --namespaced=true
# 不在名称空间里
kubectl api-resources --namespaced=false
2.8 、标签和选择器
标签(Label)是附加在Kubernetes对象上的一组名值对,其意图是按照对用户有意义的方式来标识Kubernetes对象,同时,又不对Kubernetes的核心逻辑产生影响。
标签可以用来组织和选择一组Kubernetes对象。
您可以在创建Kubernetes对象时为其添加标签,也可以在创建以后再为其添加标签。
每个Kubernetes对象可以有多个标签,同一个对象的标签的 Key 必须唯一,例如:
metadata:
labels:
key1: value1
key2: value2
使用标签(Label)可以高效地查询和监听Kubernetes对象,在Kubernetes界面工具(如 Kubenetes Dashboard 或 Kuboard)和 kubectl 中,标签的使用非常普遍。
那些非标识性的信息应该记录在 注解(annotation)
为什么要使用标签
使用标签,用户可以按照自己期望的形式组织 Kubernetes 对象之间的结构,而无需对 Kubernetes 有任何修改。
应用程序的部署或者批处理程序的部署通常都是多维度的(例如,多个高可用分区、多个程序版本、多个微服务分层)。管理这些对象时,很多时候要针对某一个维度的条件做整体操作,例如,将某个版本的程序整体删除,这种情况下,如果用户能够事先规划好标签的使用,再通过标签进行选择,就会非常地便捷。
标签的例子有:
- release: stable 、 release: canary
- environment: dev 、 environment: qa 、 environment: production
- tier: frontend 、 tier: backend 、 tier: cache
- partition: customerA 、 partition: customerB
- track: daily 、 track: weekly
上面只是一些使用比较普遍的标签,您可以根据您自己的情况建立合适的使用标签的约定。
句法和字符集
标签是一组名值对(key/value pair)。标签的 key 可以有两个部分:可选的前缀和标签名,通过 / 分隔。
- 标签名:
- 标签名部分是必须的
- 不能多于 63 个字符
- 必须由字母、数字开始和结尾
- 可以包含字母、数字、减号
-、下划线_、小数点.
- 标签前缀:
- 标签前缀部分是可选的
- 如果指定,必须是一个DNS的子域名,例如:k8s.eip.work
- 不能多于 253 个字符
- 使用 / 和标签名分隔
如果省略标签前缀,则标签的 key 将被认为是专属于用户的。Kubernetes的系统组件(例如,kube-
scheduler、kube-controller-manager、kube-apiserver、kubectl 或其他第三方组件)向用户的Kubernetes 对象添加标签时,必须指定一个前缀。 kubernetes.io/ 和 k8s.io/ 这两个前缀是 Kubernetes 核心组件预留的。
标签的 value 必须:
- 不能多于 63 个字符
- 可以为空字符串
- 如果不为空,则
- 必须由字母、数字开始和结尾
- 可以包含字母、数字、减号 - 、下划线 _ 、小数点 .
apiVersion: v1
kind: Pod
metadata:
name: label-demo
labels:
environment: production
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
标签选择器
通常来讲,会有多个Kubernetes对象包含相同的标签。通过使用标签选择器(label selector),用户/客户端可以选择一组对象。标签选择器(label selector)是 Kubernetes 中最主要的分类和筛选手段。
Kubernetes api server支持两种形式的标签选择器, equality-based 基于等式的 和 set-based 基于集合的 。标签选择器可以包含多个条件,并使用逗号分隔,此时只有满足所有条件的 Kubernetes 对象才会被选中
使用基于等式的选择方式,可以使用三种操作符 =、==、!=。
前两个操作符含义是一样的,都代表相等,后一个操作符代表不相等
#
kubectl get pods -l environment=production,tier=frontend
# 选择了标签名为 ènvironment` 且 标签值为 `production` 的Kubernetes对象
environment = production
# 选择了标签名为 `tier` 且标签值不等于 `frontend` 的对象,以及不包含标签 `tier` 的对象
tier != frontend
使用基于集合的选择方式
Set-based 标签选择器可以根据标签名的一组值进行筛选。支持的操作符有三种:in、notin、exists。例如
# 选择所有的包含 ènvironment` 标签且值为 `production` 或 `qà 的对象
environment in (production, qa)
# 选择所有的 `tier` 标签不为 `frontend` 和 `backend`的对象,或不含 `tier` 标签的对象
tier notin (frontend, backend)
# 选择所有包含 `partition` 标签的对象
partition
# 选择所有不包含 `partition` 标签的对象
!partition
# 选择包含 `partition` 标签(不检查标签值)且 ènvironment` 不是 `qà 的对象
partition,environment notin (qa)
kubectl get pods -l \'environment in (production),tier in (frontend)\'
#Job、Deployment、ReplicaSet 和 DaemonSet 同时支持基于等式的选择方式和基于集合的选择方式。
# 例如:
selector:
matchLabels:
component: redis
matchExpressions:
- key: tier, operator: In, values: [cache]
- key: environment, operator: NotIn, values: [dev]
# matchLabels 是一个 key,value 组成的 map。map 中的一个 key,value 条目相当于matchExpressions 中的一个元素,其 key 为 map 的 key,operator 为 In, values 数组则只包含 value 一个元素。matchExpression 等价于基于集合的选择方式,支持的 operator 有 In、NotIn、Exists 和 DoesNotExist。当 operator 为 In 或 NotIn 时,values 数组不能为空。所有的选择条件都以 AND 的形式合并计算,即所有的条件都满足才可以算是匹配
#添加或者修改标签
kubectl label --help
# Update pod \'foo\' with the label \'unhealthy\' and the value \'true\'.
kubectl label pods foo unhealthy=true
# Update pod \'foo\' with the label \'status\' and the value \'unhealthy\', overwriting any existing value.
kubectl label --overwrite pods foo status=unhealthy
# Update all pods in the namespace
kubectl label pods --all status=unhealthy
# Update a pod identified by the type and name in "pod.json"
kubectl label -f pod.json status=unhealthy
# Update pod \'foo\' only if the resource is unchanged from version 1.
kubectl label pods foo status=unhealthy --resource-version=1
# Update pod \'foo\' by removing a label named \'bar\' if it exists.
# Does not require the --overwrite flag.
kubectl label pods foo bar-
2.9、注解annotation
注解(annotation)可以用来向 Kubernetes 对象的 metadata.annotations 字段添加任意的信息。
Kubernetes 的客户端或者自动化工具可以存取这些信息以实现其自定义的逻辑。
metadata:
annotations:
key1: value1
key2: value2
2.8、字段选择器
字段选择器 ( Field selectors )允许您根据一个或多个资源字段的值 筛选 Kubernetes 资源 。
下面是一些使用字段选择器查询的例子:
- metadata.name=my-service
- metadata.namespace!=default
- status.phase=Pending
kubectl get pods --field-selector status.phase=Running
三个命令玩转所有的yaml写法‘
- kubectl get xxx -oyaml
- kubectl create deploy xxxxx --dry-run-client -oyaml
- kubectl explain pod.spec.xx
写完yaml kubectl apply -f 即可
2.10、认识kubectl 客户端命令
区分一下,这些容易混淆的词儿:Minikube、 kubectl、 kubelet、kubeadm
Minikube是一种可以在本地轻松运行一个单节点Kubernetes群集的工具。
Kubectl是一个命令行工具,可以使用该工具控制Kubernetes集群管理器,如检查群集资源,创建、删除和更新组件,查看应用程序。kubectl是API,供我们调用,键入命令对k8s资源进行管理。
Kubelet是一个代理服务,它在每个节点上运行,并使从服务器与主服务器通信。kubelet 用来调用下层的container管理器,从而对底层容器进行管理。
kubeadm是管理器,我们可以使用它进行k8s节点的管理。
minikube 只能够搭建 Kubernetes 环境,要操作 Kubernetes,还需要另一个专门的客户端工具kubectl。
kubectl 的作用有点类似之前我们学习容器技术时候的工具 docker ,它也是一个命令行工具,作用也比较类似,同样是与 Kubernetes 后台服务通信,把我们的命令转发给 Kubernetes,实现容器和集群的管理功能。
kubectl 是一个与 Kubernetes、minikube 彼此独立的项目,所以不包含在 minikube 里,但 minikube 提供了安装它的简化方式,你只需执行下面的这条命令:
minikube kubectl
它就会把与当前 Kubernetes 版本匹配的 kubectl 下载下来,存放在内部目录(例.minikube/cache/linux/v1.23.1)

其中的kubeadm是管理器,我们可以使用它进行k8s节点的管理。最常用的功能有三个:
(1)init:初始化k8s节点,运行此命令来搭建 Kubernetes 控制平面节点。
(2)join:将worker节点加入到k8s集群
(3)reset:尽最大努力还原init或者join对集群的影响
其中的 kubectl 就是 那一个命令行工具,可以使用该工具控制Kubernetes集群管理器,如检查群集资源,创建、删除和更新组件,查看应用程序。kubectl是API,供我们调用,键入命令对k8s资源进行管理。
所以,在 minikube 环境里,我们会用到两个客户端:
客户端1 : minikube 管理 Kubernetes 集群环境;
客户端2:kubectl 操作实际的 Kubernetes 功能;
kubectl的所有命令参考:
通过 kubectl , 我们就可以使用它来对 Kubernetes “发号施令”了。
命令参考: https://kubernetes.io/docs/reference/generated/kubectl/kubectl-commands
2.11、自动补全
k8s集群包括很多的命令,我们可以配置"tab"键的命令补全功能,帮助我们输入k8s相关的命令。
https://kubernetes.io/zh/docs/tasks/tools/included/optional-kubectl-configs-bash-linux/
# 安装
yum install bash-completion
# 自动补全
echo \'source <(kubectl completion bash)\' >>~/.bashrc
kubectl completion bash >/etc/bash_completion.d/kubectl
source /usr/share/bash-completion/bash_completion
2.12、给idea安装kubernetes插件
资源对象,都是通过 yaml 文件编写,但是 yaml文件的格式, 很容易 出错,
所以可以通过工具来协助 资源对象 yaml 文件的编辑
idea有kubernetes插件, 可以方便的编写 yaml 文件
1、plugins kubernetes
kubernetes plugin 为我们提供了一些便捷操作: 比如 命令提示、模板生成等。
File > Settings > Plugins > Marketplace > 在
Type / to see options里 搜索Kubernetes

下面我们简单介绍几个简单的功能演示:
2、快速生成kubernetes 资源文件模板
idea 中并未提供yaml的快捷创建方式,我们设置一下:
File > Settings > Editor > File and Code Templates > Files > Create Template
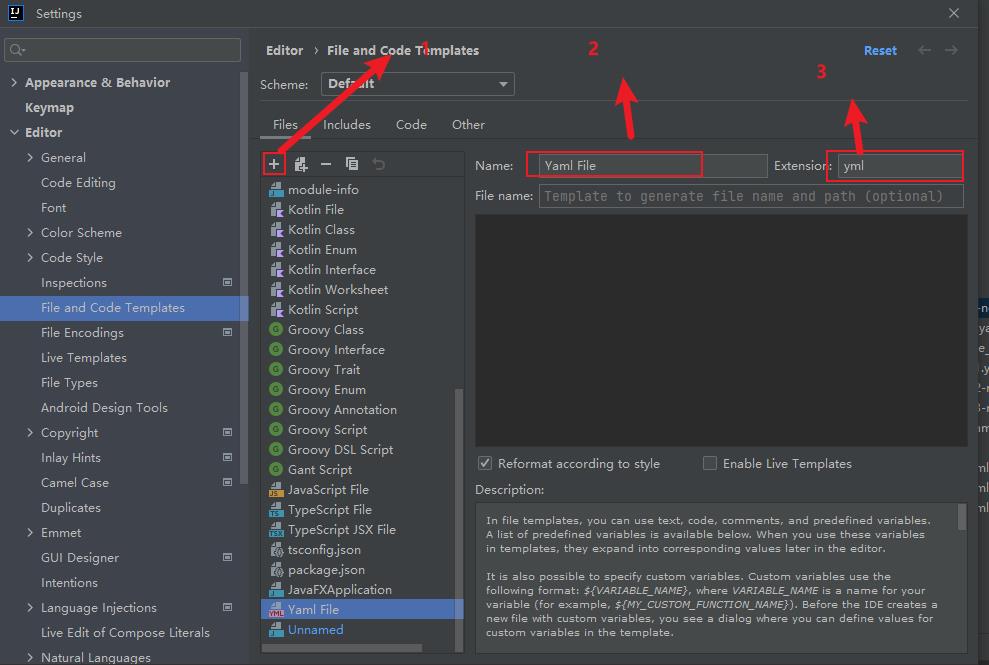
如图所示,我们创建yml类型的模板文件,而后我们在新建文件时就可以选择yaml类型的文件了。

我们新建一个test.yml 文件,使用 k* 命令去创建kubernetes 资源模板文件
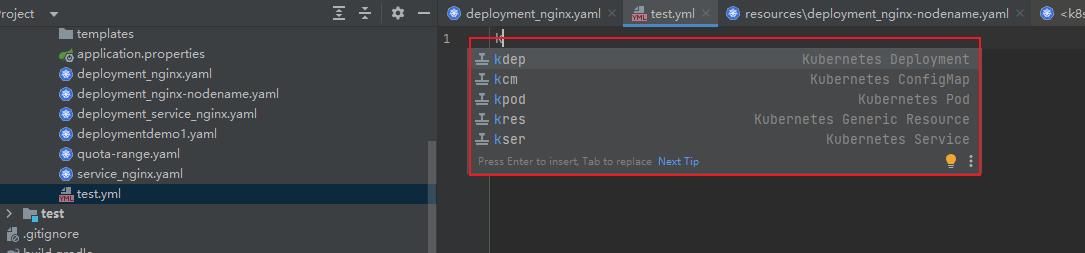
3、输入k即可触发自动命令提示
我们只需要在 yaml 文件中 输入k即可触发自动命令提示:
- kdep ---- kubernetes deployment
- kcm ---- kubernetes configMap
- kpod ---- kubernetes pod
- kres ---- kubernetes generic resource
- kser ---- kubernetes service
选择我们要创建的模板类型,生成模板,我们在name处 输入名称,它会自动填充其他属性,而后我们只需要 输入要引用的 image 即可
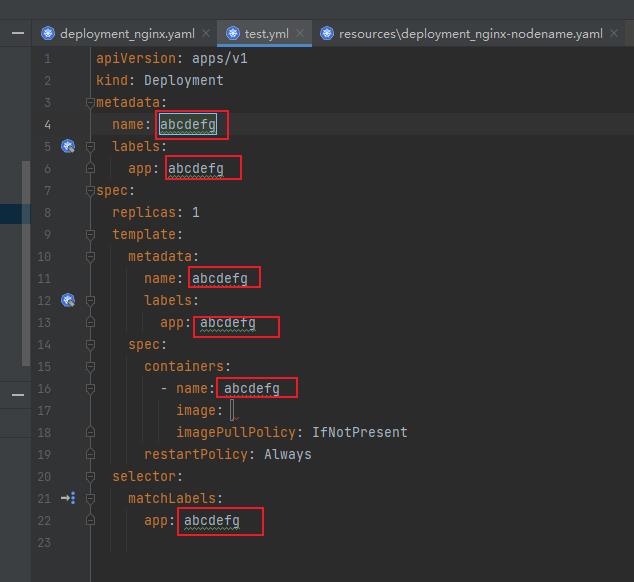

在image 处也会有提示,包括版本信息
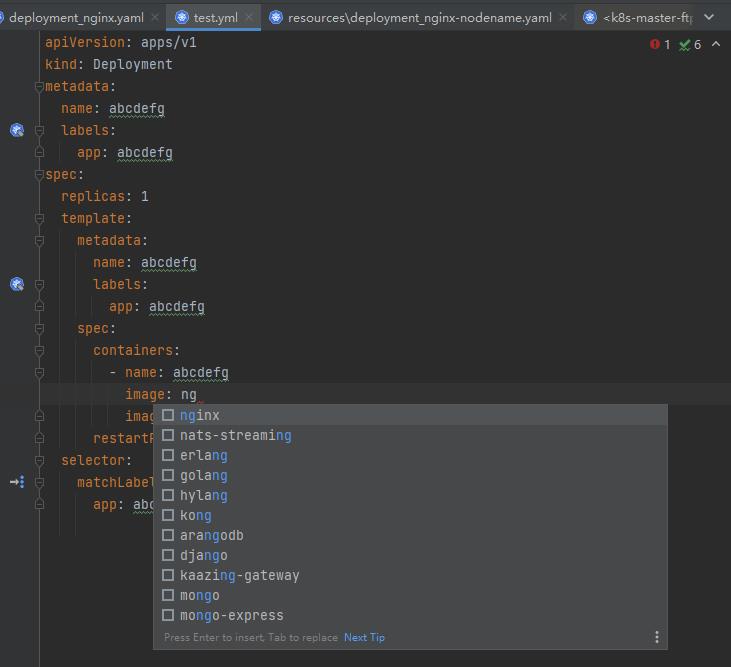

我们把鼠标放到某个属性上(restartPolicy),也会有api提示,

第五部分:Kubernetes 工作负载
什么是Workloads?
问题1: 什么是工作负载(Workloads)?
- 工作负载是运行在 Kubernetes 上的一个应用程序。
- 一个应用很复杂,可能由单个组件或者多个组件共同完成。
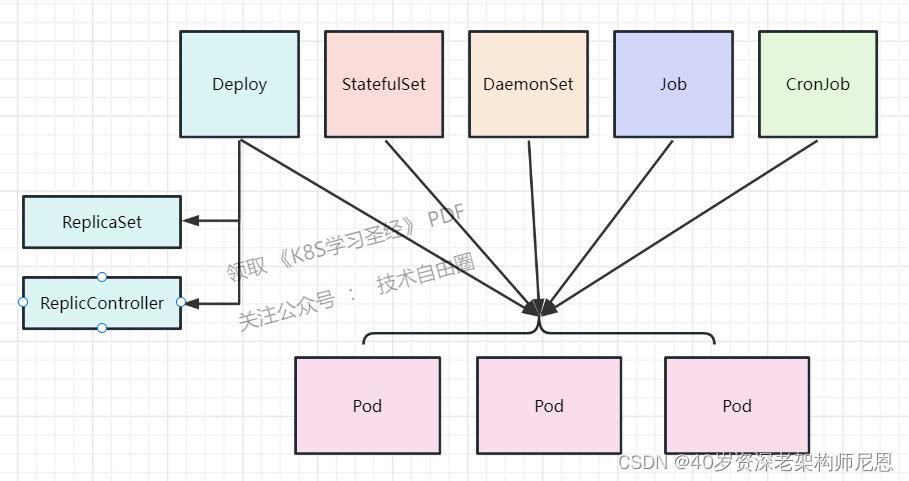
无论怎样我们,可以用一组Pod来表示一个 工作负载 (应用程序)
问题2:什么是Pod?
Pod又是一组容器(Containers)
所以关系又像是这样
- 工作负载(Workloads)控制一组Pod
- Pod控制一组容器(Containers)
比如Deploy(部署) 一个3个副本的nginx Pod(3个Pod)应用,每个nginx Pod里面是真正的nginx容器(container)
所以,在Kubernetes中,Pod是最小的管理单元,包含一个或者一组紧密关联的容器。
但是,单独的Pod并不能保障总是可用,比如我们创建一个nginx的Pod,因为某些原因,该Pod被意外删除,我们希望其能够自动新建一个同属性的Pod。
如何实现pod的高可用?很遗憾,单纯的Pod并不能满足需求。
为此,Kubernetes实现了一系列控制器来管理Pod,使Pod的期望状态和实际状态保持一致。
目前常用的控制器有:
- Deployment
- StatefulSet
- DaemonSet
- Job/CronJob
Pod的原理与生命周期
1、什么是Pod
再一次深入到一个基础问题: 什么是Pod?
在部署第一个应用程序中创建Deployment后,k8s创建了一个pod(容器组)来放置应用程序实例(container容器)。
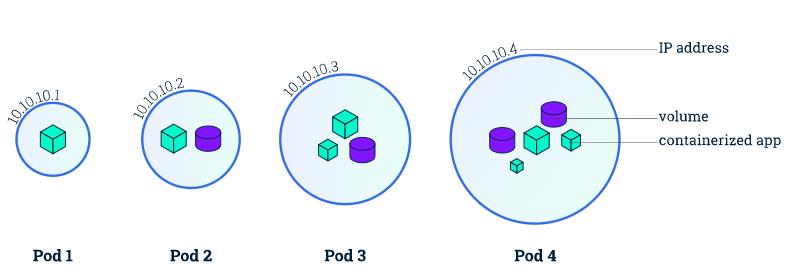
pod容器组是一个k8s中一个抽象的概念,用于存放一组 container(可包含一个或多个 container 容器,即图上正方体),以及这些container(容器)的一些共享资源。这些资源包括:
- 共享存储,称为卷(Volumes),即图上紫色圆柱
- 网络,每个pod(容器组)在集群中有个唯一的ip,pod(容器组)中的container(容器)共享该ip地址
- container(容器)的基本信息,例如容器的镜像版本,对外暴露的端口等
例如,pod可能即包含带有Java应用程序的container容器,也可以包含另一个非Java的container容器。
pod中的容器共享ip地址和端口空间(同一pod中的不同container端口不能相互冲突),始终同一node位置并共同调度,并在同一node节点上的共享上下文中运行。
同一个pod内的容器可以使用localhost+端口互相访问。
pod(容器组)是k8s集群上的最基本的单元。当我们在k8s 上创建Deployment 时,会在集群上创建包含容器的pod(而不是直接创建容器)。
每个pod都与运行它的worker节点(node)绑定,并保持在那里知道终止或呗删除。
如果节点(node)发生故障,则会在集群中的其他可用节点(node)上运行相同的pod(从同样的镜像创建container,使用相同的配置,ip地址不同,pod名字不同)。
- pod 是一组容器(可包含一个或多个应用程序容器),以及共享存储(卷volumes)、ip 地址和有关如何运行容器的信息。
- 如果多个容器紧密耦合并且需要共享磁盘等资源,则他们应该被部署在同一个pod(容器组)中。
下图显示一个node(节点)上含有4个pod(容器组)
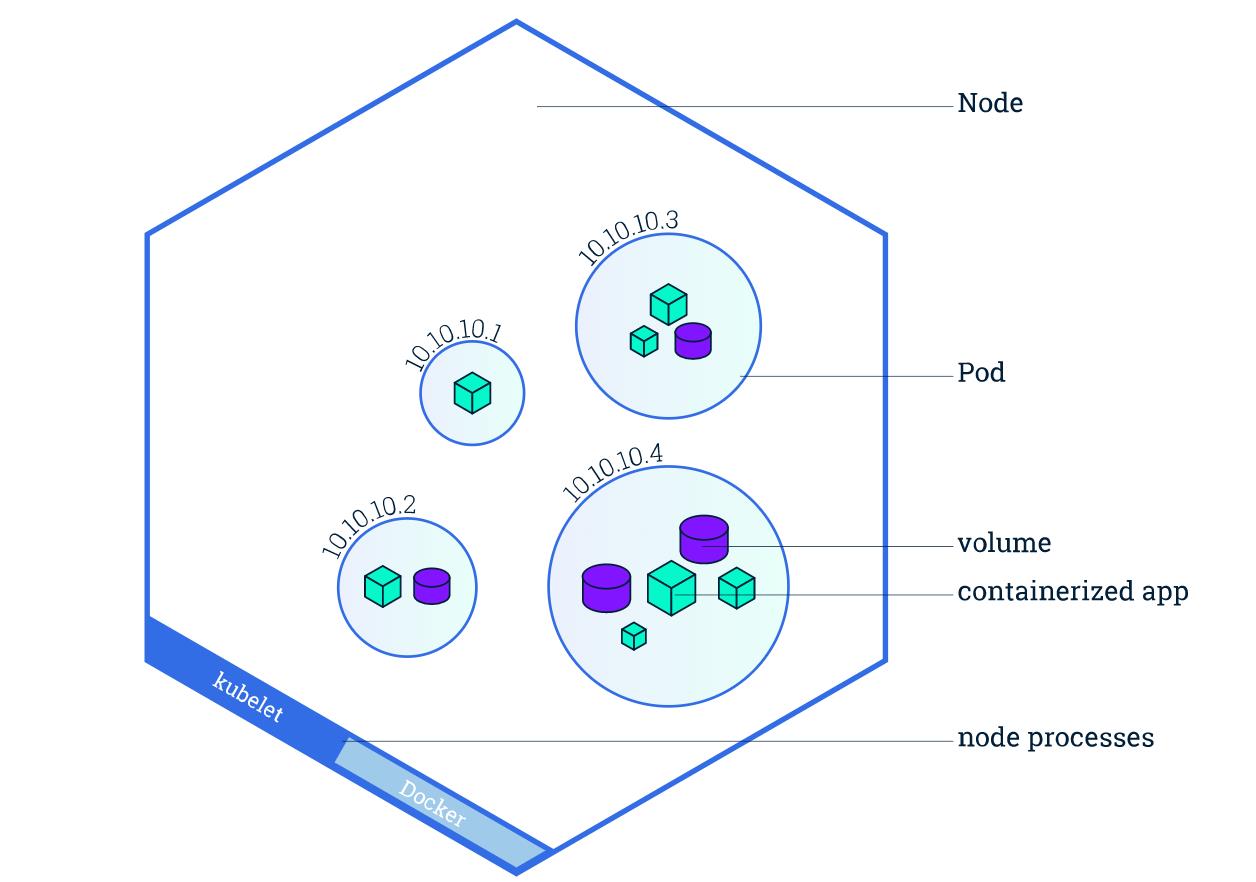
pod(容器组)总是在node(节点)上运行。
node(节点)是kubernetes集群中的计算机节点。可以是物理机或虚拟机。每个node(节点)都由master管理。
一个node(节点)上可以部署多个pod(容器组),kubernetes master会根据每一个node(节点)上的可用资源情况,自动调度pod(容器组)到最佳的node(节点)上。
一个kubernetes node(节点)至少运行:
- kubelet, 负责master节点和worker节点之间通信的进程;管理pod(容器组)和pod(容器组)内运行的Container(容器)。
- 容器运行环境(如docker)负责下载镜像、创建和运行容器等。
一个Pod 是一组(一个或多个) 容器(docker容器)的集
第143天学习打卡( Kubernetes 初识K8s Pod)
Kubernetes
MESOS APACHE 分布式资源管理框架
Docker Swarm
Kubernetes 特点:
- 轻量级:消耗资源小
- 开源
- 弹性伸缩
- 负载均衡:IPVS
K8S是一个开源的,用于管理云平台中多个主机上的容器化的应用, K8S的目标是让部署容器化的应用简单并且高效,K8S提供应用部署,规划,更新和维护的一种机制。
传统的应用部署方式是通过插件或脚本来安装应用的,这样做的缺点是应用的运行、配置、管理、所有生存周期将与当前操作系统绑定,这样做并不利于应用的升级更新/回滚等操作,当然也可以通过创建虚拟机的方式来实现某些功能,但是虚拟机非常重,不利于可移植性。
新的方式是通过部署容器方式实现,每个容器之间互相隔离,每个容器有自己的文件系统,容器之间进程不会相互影响,能区分计算资源。相对于虚拟机,容器能快速部署,由于容器与底层设施、机器文件系统解耦的,所以他能在不同云、不同版本操作系统之间进行迁移。
容器占用资源少,部署快,每个应用可以被打包成一个容器镜像,每个应用与容器间成一对一关系也使容器有更大优势,使用容器可以在build或release的阶段,为应用创建容器镜像,因为每个应用不需要与其余的应用堆栈组合,也不依赖于生产环境基础结构,这使得从研发到测试,生产能提供一致环境。类似的,容器比虚拟机轻量,更透明,这便于监控和管理。
K8S功能:
-
自动装箱
- 基于容器对应用运行环境的资源配置要求自动部署应用容器
-
自我修复(自愈能力
- 容器失败时,会对容器进行重启
- 当所部署的Node节点有问题时,会对容器进行重新部署和重新调度
- 当容器未通过监控检查时,会关闭此容器直到容器正常运行时,才会对外提供服务
-
水平扩展
- 通过简单的命令、用户UI界面或基于CPU等资源使用情况,对应用容器进行规模扩大或规模剪裁
-
服务发现
- 用户不需要使用额外的服务发现机制,就能基于K8S自身能力实现服务发现和负载均衡
-
滚动更新
- 可以根据应用的变化,对应用容器运行的应用,进行一次性或批量式更新
-
版本退回
- 可以根据应用部署情况,对应用容器运行的应用,进行历史版本即时回退
-
密钥和配置管理
- 在不需要重新构建镜像的情况下,可以部署和更新密钥和应用配置,类似热部署
-
存储编排
- 自动实现存储系统挂载及应用,特别对有状态应用实现数据持久化非常重要,存储系统可以来自本地目录、网络存储(NFS、Gluster、Ceph等)、公共云存储服务
-
批处理
- 提供一次性任务,定时任务;满足批量数据处理和分析的场景。
基础概念:什么是Pod 控制器类型 K8s 网络通讯模式
kubernetes:构建K8s集群
资源清单:资源, 掌握资源清单的语法,编写Pod 掌握Pod的生命周期
Pod控制器:掌握各种控制器的特点以及使用定义方式
服务发现:掌握SVC原理及其构建方式
存储:掌握多种存储类型的特点,并且能够在不同环境中选择合适的存储方案
调度器:掌握调度器原理 能够根据要求把Pod定义到想要的节点运行
安全:集群的认证 鉴权 访问控制 原理及其流程
HELM: Linux yum 掌握HELM原理 HELM自定义模板 HELM部署一些常用插件
运维:修改Kubeadm达到证书可用期限为10年或者更久, 能够构建高可用的Kubernetes集群。
服务分类:
- 有状态服务 :DBMS
- 无状态服务:LVS APACHE
高可用集群副本数据最好是 >=3 基数个
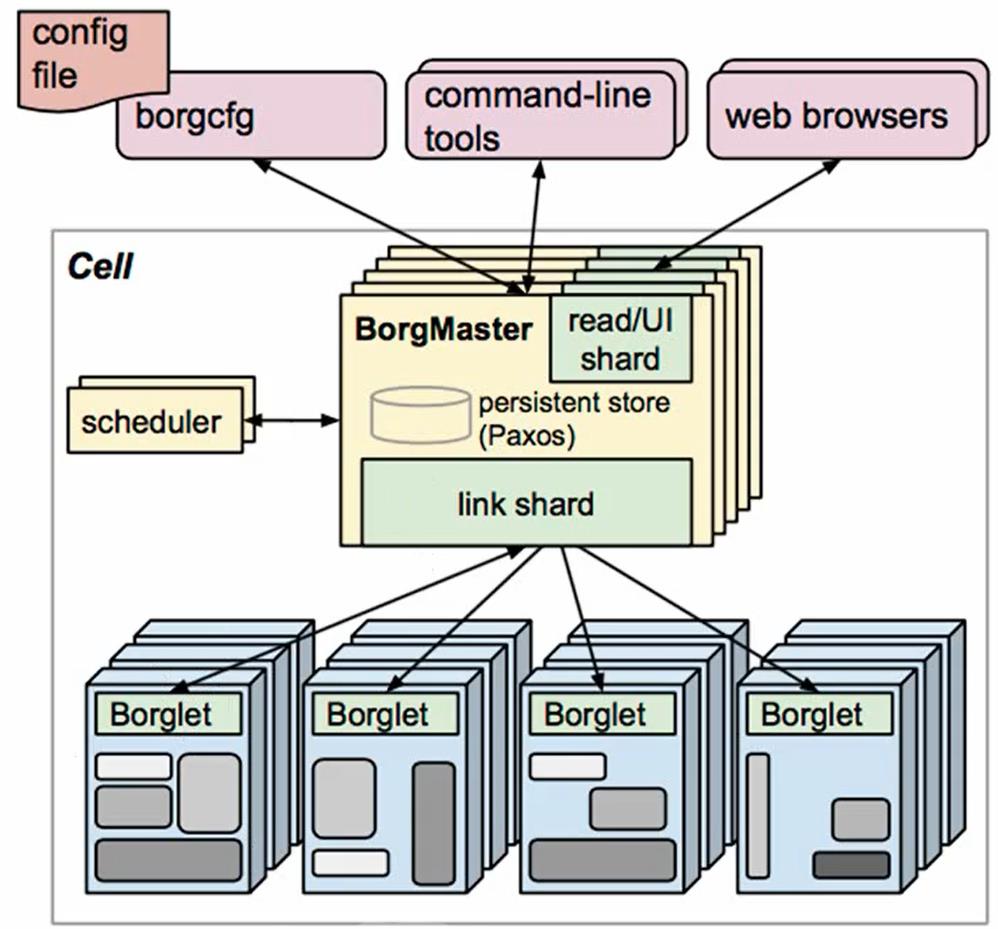
K8S架构:
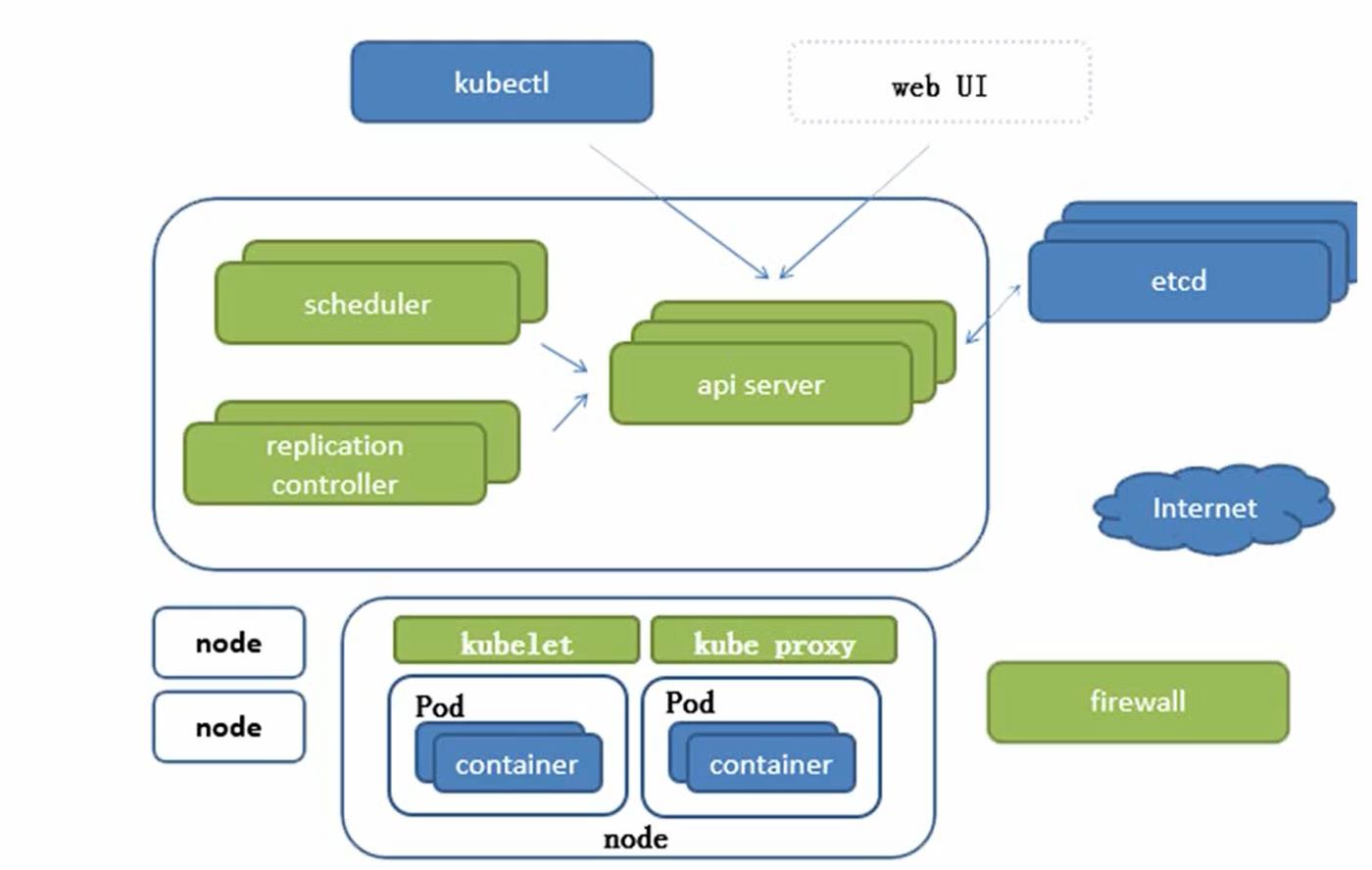
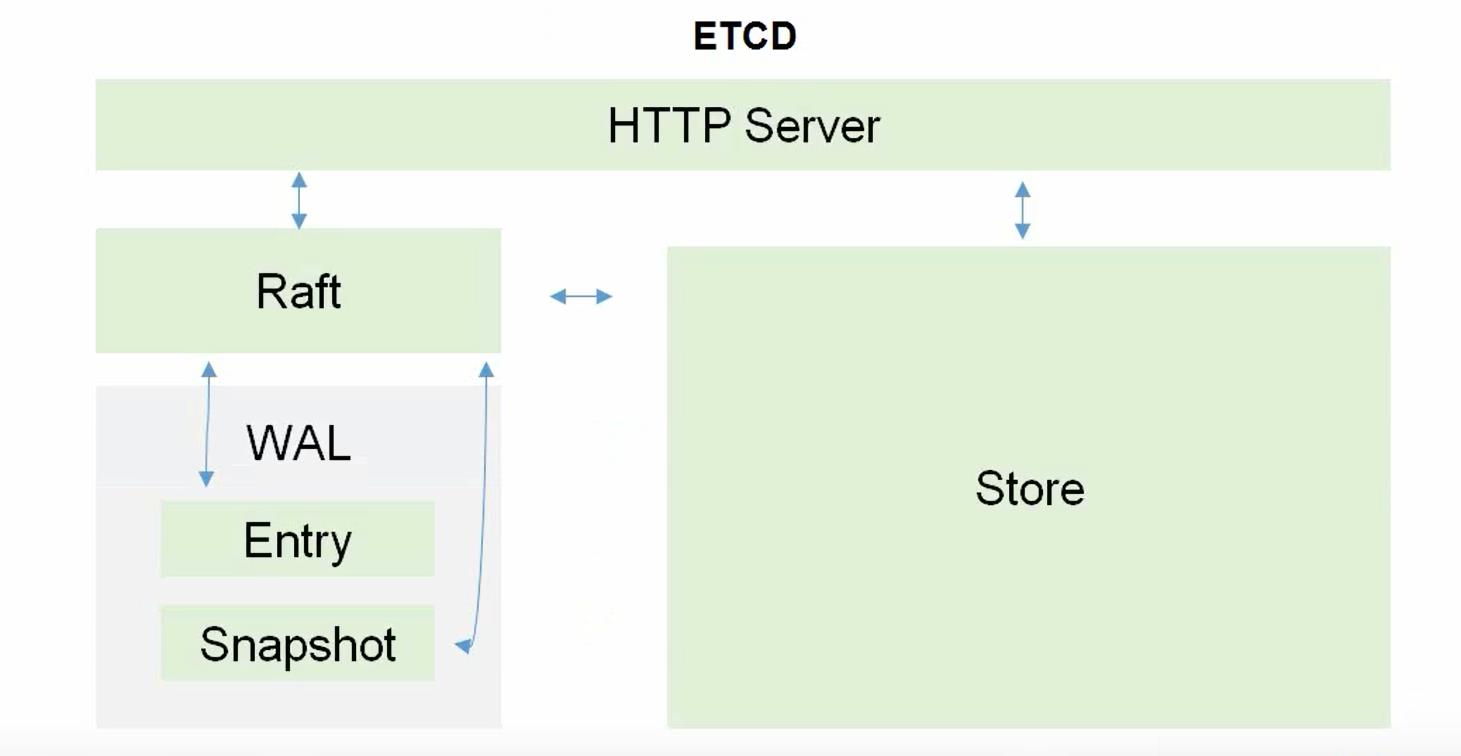
etcd 的官方将它定位成一个可信赖的分布式键值存储服务,它能够为整个分布式集群存储一些关键数据,协助分布式集群的正常运转。
etcd的目标是构建一个高可用的分布式键值(key-value)数据库。etcd内部采用raft协议作为一致性算法,etcd基于Go语言实现。
etcd作为服务发现系统,有以下的特点:
- 简单:安装配置简单,而且提供了HTTP API进行交互,使用也很简单
- 安全:支持SSL证书验证
- 快速:根据官方提供的benchmark数据,单实例支持每秒2k+读操作
- 可靠:采用raft算法,实现分布式系统数据的可用性和一致性
APISERVER:所有服务访问统一入口
ControllerManager:维持副本期望数目
Scheduler: 负责介绍任务,选择合适的节点进行分配任务
ETCD:键值对数据库,存储K8S集群所有的重要信息(持久化)
Kubelet:直接根容器引擎交互实现容器的生命周期管理
Kube-proxy:负责写入规则至IPTABLES、IPVS实现服务映射访问的
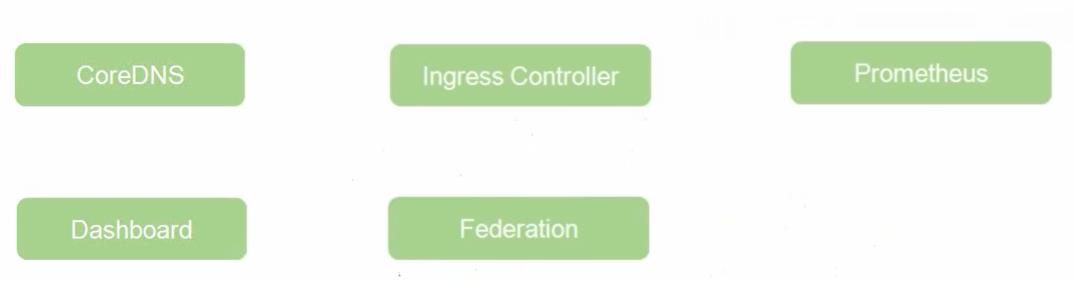
COREDNS:可以为集群中的SVC创建一个域名IP的对应关系解析
Dashboard:给K8S集群提供一个B / S结构访问体系
INGRESS CONTROLLER: 官方只能实现四层代理,INGRESS可以实现七层代理
FEDERATION:提供一个可以跨集群中心多K8S统一管理功能。
Prometheus:提供K8S集群的监控能力
ELK:提供K8S集群日志统一分析接入平台.
Pod
自主式Pod
控制器管理的Pod
ReplicationController & ReplicaSet & Deployment
ReplicationController用来确保容器应用的副本数始终保持在用户定义的副本数,即如果有容器异常退出,会自动创建新的Pod来替代,而如果异常多出来的容器也会自动回收。在新版的Kubernetes中建议使用ReplicaSet来取代ReplicationController.
ReplicaSet跟ReplicationController没有本质的不同,只是名字不一样,并且ReplicaSet支持集合式的selector
虽然 ReplicaSet 可以独立使用,但一般还是建议使用Deployment来自动管理 ReplicaSet ,这样就无需担心跟其他机制的不兼容问题(比如 ReplicaSet 不支持rolling-update但Deployment支持)
**Horizontal Pod Autoscaling 仅适用于Deployment和ReplicaSet,**在V1版本中仅支持根据Pod的CPU利用率扩容,在vlalpha版本中,支持根据内存和用户自定义的metric扩缩容。
StatefulSet是为了解决有状态服务的问题(对应Deployments和ReplicaSets是为无状态服务而设计),其应用场景包括:
- 稳定的持久化存储,即Pod重新调度后还是能访问到相同的持久化数据,基于PVC来实现
- 稳定的网络标志,即Pod重新调度后其PodName和HostName不变,基于Headless Service(即没有Cluster IP 的Service)来实现
- 有序部署,有序扩展,即Pod是有顺序的,在部署或者扩展的时候要依据定义的顺序依次进行(即从0到N-1, 在下一个Pod运行之前的Pod必须都是Running 和 Ready状态),基于init containers来实现
- 有序收缩,有序删除(即从N-1到0)
B站学习网址:k8s教程由浅入深-尚硅谷_哔哩哔哩_bilibili
以上是关于K8S学习圣经5:Pod负载管理的十八般兵器的主要内容,如果未能解决你的问题,请参考以下文章