微服务圣经1:零基础搭建一套SpringCloud微服务脚手架(SpringCloud+Dubbo+Docker+Jenkins)
Posted 疯狂创客圈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了微服务圣经1:零基础搭建一套SpringCloud微服务脚手架(SpringCloud+Dubbo+Docker+Jenkins)相关的知识,希望对你有一定的参考价值。
文章很长,且持续更新,建议收藏起来,慢慢读!疯狂创客圈总目录 博客园版 为您奉上珍贵的学习资源 :
免费赠送 :《尼恩Java面试宝典》 持续更新+ 史上最全 + 面试必备 2000页+ 面试必备 + 大厂必备 +涨薪必备
免费赠送 :《尼恩技术圣经+高并发系列PDF》 ,帮你 实现技术自由,完成职业升级, 薪酬猛涨!加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷1)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷2)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷3)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 资源宝库: Java 必备 百度网盘资源大合集 价值>10000元 加尼恩领取
零基础 搭建一套SpringCloud微服务脚手架(SpringCloud+ Dubbo + Docker + Jenkins)
说在前面
在40岁老架构师尼恩的读者社群(50+)中,大量的小伙伴是架构师、高级开发,大家都有丰富的开发、架构经验。
在开发过程中,一般情况下,大家都是用现有的开发框架。
导致的一个严重问题是:很少有小伙伴能从0开始 搭建一套SpringCloud微服务脚手架(SpringCloud+ Dubbo + Docker + Jenkins)。然而,零基础 搭建一套SpringCloud微服务脚手架(SpringCloud+ Dubbo + Docker + Jenkins),这个实操对大家来说,至关重要。
尼恩一直在找一个契机,给大家梳理一个《零基础 搭建一套SpringCloud微服务脚手架》 博客。提升大家的实操能力,动手能力。
直到今天、契机终于来了。
从2020年开始,尼恩一直在写一本 微服务架构和开发领域的 至尊宝典 《SpringCloud 学习圣经》,全量的博客加起来全网阅读量在100W+。在这么大访问量的激励下,尼恩一直在对这本 《SpringCloud 学习圣经》进行迭代。
而且由于尼恩一人有精力有限,在尼恩的《技术自由圈》 高并发研究社群中,不断吸取有志之士的加入。咱们社群中一位资深的、华中科技大学硕士、有着10年开发和架构经验、并且管理一个20人团队的架构师 Andy加入了咱们技术迭代、技术研究的队伍。
他来给大家提供了一个优秀的微服务 基础架构实操案例,《零基础 搭建一套SpringCloud微服务脚手架》。
这,就是本文。当然,本文也收入了咱们的 10W字 至尊宝典 《SpringCloud alibaba 学习圣经》最新升级版, 《SpringCloud alibaba 学习圣经》宝典从此升级到了V3版本。
最新的 PDF 文档,可以通过 公众号 技术自由圈 领取。
本文目录
1、本文学习内容和目标
微服务架构通过将复杂的单体应用拆分为一组小型、自治的服务,为构建灵活、可扩展的应用提供了一种新的方式。
微服务框架具有以下优势:
- 模块化和可扩展性:微服务框架将应用程序拆分成多个独立的服务,每个服务可以独立开发、部署和扩展,提高了系统的灵活性和可伸缩性。
- 技术多样性:微服务框架支持使用不同的技术栈和编程语言来构建不同的服务,使团队可以根据具体需求选择最合适的技术。
- 高可用性和容错性:微服务框架通过服务注册与发现、负载均衡和容错机制,提供了高可用性和容错性,保证了系统的稳定性和可靠性。
- 独立部署和快速迭代:每个服务可以独立部署,使团队可以快速迭代和发布新功能,提高了开发和交付的效率。
在构建微服务系统时,选择一个适合的框架可以加速开发过程并提高系统的稳定性和可维护性。
本文旨在通过手把手教程,引导读者从零开始搭建一套Java微服务框架。
我们将使用Spring Cloud作为基础框架,并结合Nacos作为服务注册中心,Spring Cloud Gateway作为API网关,以及Feign作为服务之间的通信方式。
此外,我们还将探讨如何使用Docker容器化和Jenkins进行持续集成和部署,以构建一个完整的微服务架构。
通过本文的学习,读者将掌握以下技能:
- 设计和搭建微服务框架的基本原则
- 配置和使用Spring Cloud、Nacos、Spring Cloud Gateway和Feign等关键组件
- 实现服务注册与发现、服务调用和负载均衡、服务监控和日志管理、服务安全和认证授权等核心功能
- 应用Docker容器化和Jenkins进行持续集成和部署
在开始构建自己的Java微服务框架之前,让我们先了解下设计微服务框架要遵守的一些基本原则。
2、设计微服务框架的基本原则
在设计微服务框架时,我们需要遵循一些基本原则,以确保系统的可扩展性、可维护性和可靠性。以下是设计微服务框架的基本原则:
1.解耦和独立性:
微服务架构的核心概念之一是服务的解耦和独立性。每个微服务应该具有清晰的边界,它们可以独立开发、部署和扩展。在设计框架时,要保证各个微服务之间的解耦,使其可以独立演化而不会对其他服务产生过多的影响。
2.可伸缩性和容错性:
微服务架构的另一个重要目标是实现可伸缩性和容错性。框架应该能够根据负载的增加或减少,自动扩展或缩减服务实例的数量。同时,要考虑到服务的容错能力,当某个服务出现故障时,框架应该能够自动将请求路由到其他可用的服务实例上。
3.简化开发和部署过程:
微服务框架应该能够简化开发和部署的过程。提供一套标准化的开发模式和工具链,使开发人员可以快速构建和部署微服务。自动化的构建、测试和部署流程能够提高开发效率,减少人为错误。
4.兼容性和可扩展性:
框架应该具备良好的兼容性和可扩展性,能够与其他技术和组件进行集成。例如,能够无缝地与现有的数据存储、消息队列、认证授权系统等进行整合。此外,框架本身也应该是可扩展的,可以根据需求灵活地添加新的功能模块。
设计微服务框架时,需要综合考虑这些原则,并根据实际情况进行权衡和取舍。合理的框架设计能够提高开发效率、降低系统复杂度,并为微服务架构的可持续发展打下坚实的基础。在后续的章节中,我们将深入探讨如何应用这些原则,结合Spring Cloud、Nacos、Spring Cloud Gateway、Feign等组件,构建一套高效可靠的Java微服务框架。
3、搭建基础设施
在搭建微服务框架之前,我们需要配置一些基础设施,包括Java开发环境、构建工具、版本控制和集成开发环境(IDE)。下面是一些常用的工具和配置:
1.安装Java开发环境
工具介绍:
首先,确保你的系统上已经安装了Java开发工具包,Java开发环境包括Java Development Kit(JDK),它是开发和运行Java应用程序所必需的工具包。
你可以从Oracle官方网站或OpenJDK项目中下载并安装最新版本的JDK。
安装完成后,设置JAVA_HOME环境变量,指向JDK的安装目录。
下载地址:
- Oracle JDK: https://www.oracle.com/java/technologies/javase-jdk11-downloads.html
- OpenJDK: https://adoptopenjdk.net/
安装方式:
- 根据你的操作系统选择合适的Java发行版。
- 下载安装程序并运行。
- 按照安装向导的指引完成安装。
- 配置JAVA_HOME环境变量:
- Windows:在系统变量中新建一个名为JAVA_HOME的变量,值为JDK的安装路径(例如:
D:\\program\\Java\\jdk1.8.0_202)。 - macOS/Linux:在终端中编辑
~/.bashrc或~/.bash_profile文件,并添加以下行:export JAVA_HOME=/path/to/jdk。然后运行source ~/.bashrc或source ~/.bash_profile命令使配置生效。
- Windows:在系统变量中新建一个名为JAVA_HOME的变量,值为JDK的安装路径(例如:
操作示例:
- 打开命令行终端。
- 执行以下命令验证Java安装是否成功:
java -version
- 如果成功安装,会显示Java版本信息。
2.安装和配置Maven
工具介绍:
Apache Maven是一款流行的构建工具,用于管理Java项目的依赖和构建过程。你可以从Apache Maven官方网站下载Maven,并按照官方文档的指引进行安装和配置。配置完成后,确保你可以在命令行中使用mvn命令。
下载地址:
Maven官方网站:https://maven.apache.org/download.cgi
安装方式:
- 下载适用于你的操作系统的Maven二进制发行版(ZIP或tar.gz格式)。
- 解压下载的文件到你选择的目录。
- 配置MAVEN_HOME环境变量:
- Windows:在系统变量中新建一个名为MAVEN_HOME的变量,值为Maven的安装路径(例如:
C:\\apache-maven-3.8.3)。 - macOS/Linux:在终端中编辑
~/.bashrc或~/.bash_profile文件,并添加以下行:export MAVEN_HOME=/path/to/maven。然后运行source ~/.bashrc或source ~/.bash_profile命令使配置生效。
- Windows:在系统变量中新建一个名为MAVEN_HOME的变量,值为Maven的安装路径(例如:
- 将Maven的bin目录添加到系统的PATH环境变量中。
操作示例:
- 打开命令行终端。
- 执行以下命令验证Maven安装是否成功:
mvn -v
- 如果成功安装,会显示Maven版本信息。
3.安装和配置Git
工具介绍:
Git是一款分布式版本控制系统,常用于协作开发和代码管理。你可以从Git官方网站下载并安装Git客户端。安装完成后,通过命令行验证Git是否正确安装,并设置你的用户名和邮箱。
下载地址:
Git官方网站:https://git-scm.com/downloads
安装方式:
- 下载适用于你的操作系统的Git安装程序。
- 运行安装程序并按照安装向导的指引进行安装。
- 在安装过程中选择合适的选项,例如选择安装位置和默认编辑器。
操作示例:
- 打开命令行终端。
- 配置用户名和邮箱:
git config --global user.name "Your Name"
git config --global user.email "your.email@example.com"
- 执行以下命令验证Git安装是否成功:
git --version
- 如果成功安装,会显示Git版本信息。
4.安装集成开发环境(IDE)
工具介绍:
推荐使用IntelliJ IDEA作为开发微服务的集成开发环境,IntelliJ IDEA是一款强大的Java集成开发环境,提供了丰富的功能和工具来开发Java应用程序。你可以从JetBrains官方网站下载并安装IntelliJ IDEA的社区版或旗舰版,一般社区版能满足基本的开发需要。安装完成后,打开IntelliJ IDEA,并根据需要进行相应的配置,例如选择主题、安装必要的插件等。
下载地址:
IntelliJ IDEA官方网站:https://www.jetbrains.com/idea/download/
安装方式:
- 下载适用于你的操作系统的IntelliJ IDEA安装程序。
- 运行安装程序并按照安装向导的指引进行安装。
- 在安装过程中选择合适的选项,例如选择安装位置、启动器图标等。
操作示例:
- 打开安装后的IntelliJ IDEA。
- 配置IntelliJ IDEA的插件和主题等个性化设置。
5.创建项目和配置构建工具
-
打开IntelliJ IDEA。
-
在欢迎界面中选择"Create New Project"或点击菜单栏的"File" -> "New" -> "Project"。
-
使用 Spring Initializr 快速生成项目结构,
输入名称,存储位置,jdk等信息,点击下一步
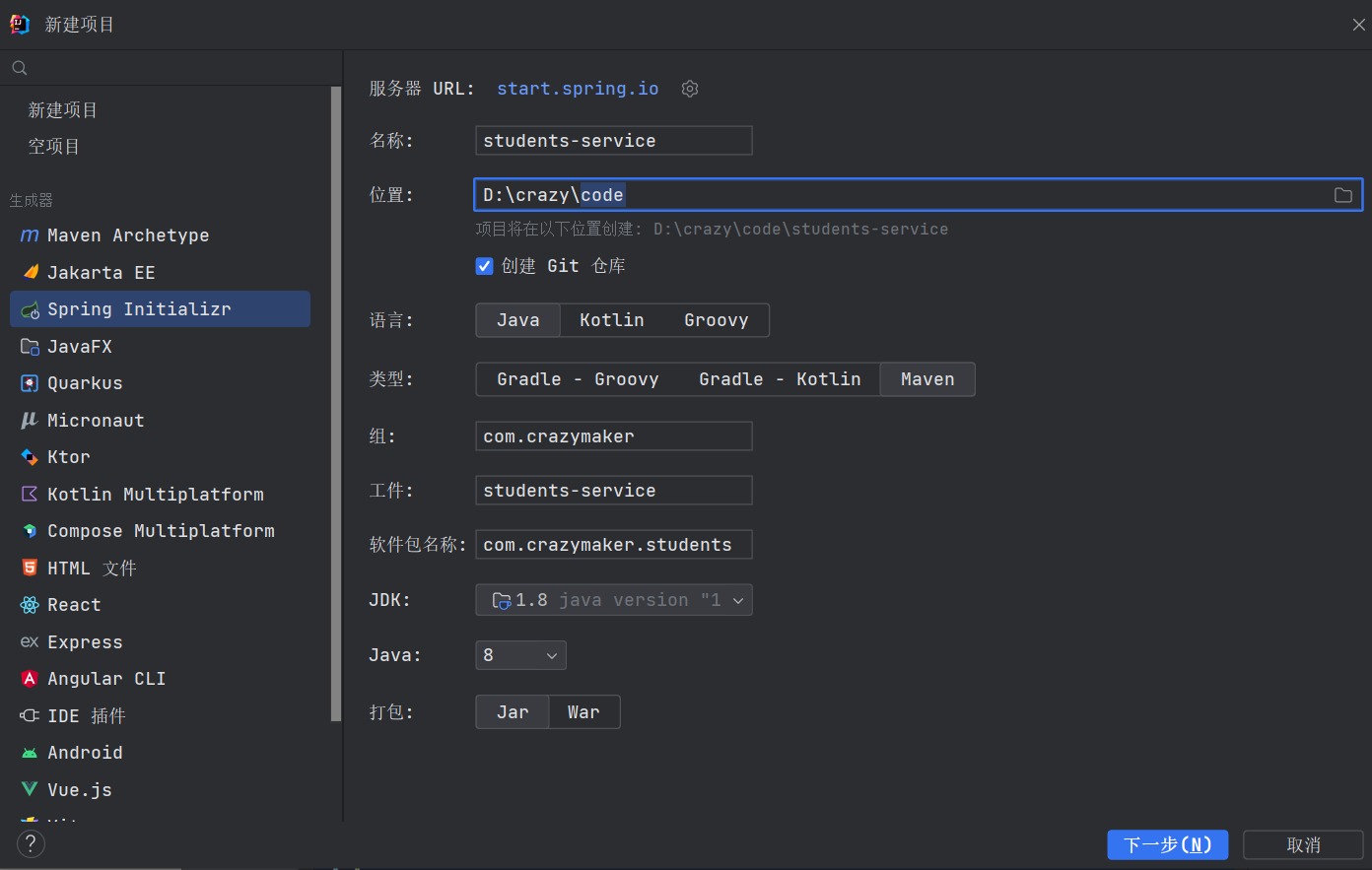
选择spring boot版本,选择所需依赖,点击创建
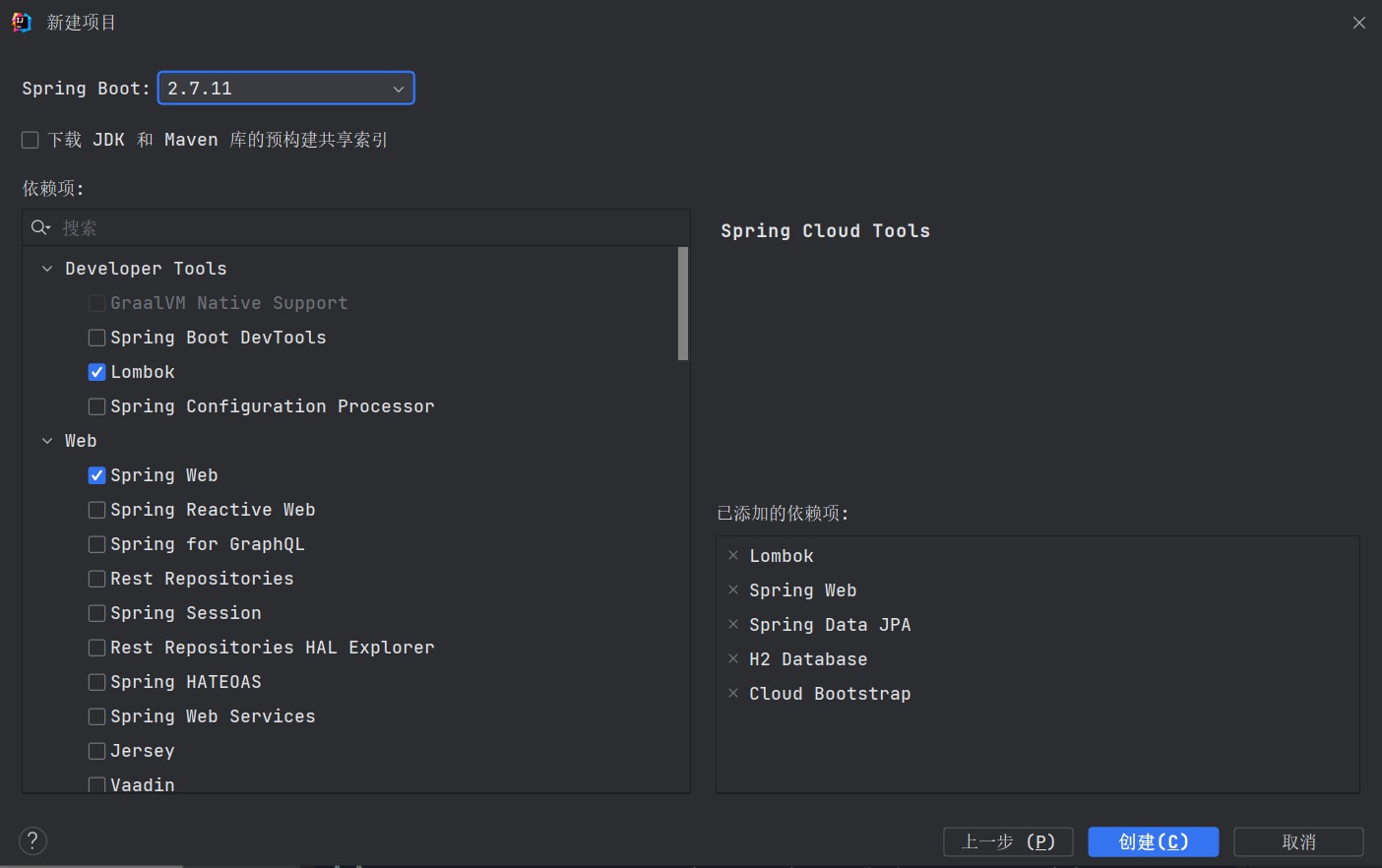
项目创建后,可以在pom.xml文件里继续配置依赖和构件项。
pom.xml示例如下:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>2.7.11</version>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>$spring-cloud.version</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2021.1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<finalName>$project.artifactId</finalName>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-resources-plugin</artifactId>
<version>3.0.1</version>
<configuration>
<encoding>UTF-8</encoding>
</configuration>
<executions>
<execution>
<id>attach-sources</id>
</execution>
</executions>
</plugin>
<!--test case plugin-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>3.0.0-M5</version>
<configuration>
<parallel>methods</parallel>
<threadCount>10</threadCount>
<argLine>-Dfile.encoding=UTF-8</argLine>
<skipTests>true</skipTests>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.3.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<!--default package plugin-->
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>repackage</goal>
</goals>
</execution>
</executions>
<configuration>
<fork>true</fork>
<jvmArguments>-Dfile.encoding=UTF-8</jvmArguments>
<addResources>true</addResources>
<classifier>exec</classifier>
</configuration>
</plugin>
</plugins>
</build>
以上是安装和配置Java、Maven、Git和IntelliJ IDEA的详细步骤。
请按照这些步骤进行操作,确保这些工具在你的开发环境中正确安装和配置。
接下来我们就可以继续进行下一步,开始搭建Java微服务框架。
4、定义微服务接口和协议
在设计微服务框架时,定义微服务接口和协议是非常重要的一步。
接下来以学生信息为例,结合JPA(Java Persistence API),提供相关的增删改查的代码示例。
JPA(Java Persistence API)是Java EE的一部分,是一种用于对象持久化的规范。
它提供了一种以面向对象的方式进行数据库操作的方式,通过简化数据库访问和数据对象之间的映射,提高了开发效率。
JPA使用注解来描述实体类和数据库表之间的映射关系,可以轻松地进行增删改查等常见数据库操作。它支持各种关系型数据库,并提供了事务管理、缓存等功能。
在我们的示例中,我们使用JPA来定义学生实体类,并通过注解来映射学生信息表的结构。这样,我们可以通过简单的代码操作来实现对学生信息的持久化和查询。
1.引入JPA依赖
在开始之前,我们需要在项目的pom.xml文件中添加JPA的依赖。JPA是Java Persistence API的缩写,它是Java EE中持久化操作的标准规范,用于简化数据库操作和实体对象的映射关系。
请在项目的pom.xml文件中添加以下依赖:
<dependencies>
<!-- JPA -->
<dependency>
<groupId>javax.persistence</groupId>
<artifactId>javax.persistence-api</artifactId>
<version>2.2</version>
</dependency>
<!-- Hibernate JPA 实现 -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>5.6.0.Final</version>
</dependency>
<!-- 数据库驱动 -->
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<version>1.4.200</version>
</dependency>
<!-- Spring Boot Data JPA -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!-- 其他依赖... -->
</dependencies>
这些依赖将启用JPA和Hibernate作为我们的持久化框架,并使用H2数据库作为示例数据库。你可以根据自己的需求替换为其他数据库。
2.示例表结构
在我们的示例中,我们将使用一个名为"student"的表来存储学生信息。该表包含三个列:id(主键),name和age。
请确保在你的数据库中创建了名为"student"的表,以及相应的列。以下是表的DDL示例:
CREATE TABLE student (
id INT PRIMARY KEY,
name VARCHAR(50),
age INT
);
3.application.yml配置
在项目中,我们需要配置application.yml文件来连接数据库和配置JPA。
请在src/main/resources目录下创建一个名为application.yml的文件,并添加以下内容:
server:
port: 8180
servlet:
context-path: /
spring:
application:
name: students-service
datasource:
url: jdbc:h2:mem:test
username: sa
password: password
driver-class-name: org.h2.Driver
jpa:
hibernate:
ddl-auto: create
show-sql: true
以上配置使用了H2内存数据库,并使用了默认的sa用户和password密码进行连接。同时,我们启用了Hibernate的DDL自动更新功能,并配置JPA显示SQL语句。
4.定义学生实体类
首先,定义一个学生实体类,用于表示学生的信息。可以包含学生的ID、姓名、年龄等属性。
import lombok.Data;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
@Entity
@Data
public class Student
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
private String name;
private int age;
5.定义学生信息的持久化接口
使用JPA来管理学生信息的持久化操作。定义一个学生信息的持久化接口,提供增删改查等方法。
import org.springframework.data.jpa.repository.JpaRepository;
public interface StudentRepository extends JpaRepository<Student, Long>
// 可以添加自定义的查询方法,如根据姓名查询学生信息等
6.定义学生信息的控制器接口
在微服务框架中,通过HTTP协议暴露学生信息的API接口供外部调用。定义一个学生信息的控制器接口,提供增删改查等API方法。
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import java.util.List;
@RestController
@RequestMapping("/students")
public class StudentController
@Autowired
private StudentRepository studentRepository;
@GetMapping
public List<Student> getAllStudents()
return studentRepository.findAll();
@PostMapping
public Student createStudent(@RequestBody Student student)
return studentRepository.save(student);
@GetMapping("/id")
public Student getStudentById(@PathVariable("id") Long id)
return studentRepository.findById(id).orElse(null);
@PutMapping("/id")
public Student updateStudent(@PathVariable("id") Long id, @RequestBody Student updatedStudent)
Student existingStudent = studentRepository.findById(id).orElse(null);
if (existingStudent != null)
existingStudent.setName(updatedStudent.getName());
existingStudent.setAge(updatedStudent.getAge());
return studentRepository.save(existingStudent);
return null;
@DeleteMapping("/id")
public void deleteStudent(@PathVariable("id") Long id)
studentRepository.deleteById(id);
通过以上代码示例,我们定义了一个学生信息的实体类、学生信息的持久化接口和学生信息的控制器接口。
这样就可以通过API来进行学生信息的增删改查操作。
在接下来的步骤中,我们将结合Spring Cloud、Nacos、Spring Cloud Gateway、Feign、Docker和Jenkins等组件,搭建一个完整的Java微服务框架。
5、实现服务注册与发现
服务注册与发现是微服务架构中非常重要的一部分,它允许我们动态地注册和发现微服务实例,从而实现微服务之间的通信。在这一节中,我们将详细介绍服务注册与发现的工作原理和实现方式。
- 服务注册
服务注册是指将微服务实例的信息(例如主机名、端口号、服务名称等)注册到服务注册中心,使得其他服务可以发现和调用它。下面是服务注册的步骤:
- 微服务启动时,它会向服务注册中心发送注册请求,提供自己的信息。
- 服务注册中心收到注册请求后,将微服务的信息保存起来,并为其生成一个唯一的标识符(例如服务ID)。
- 其他微服务可以通过服务注册中心查询和获取已注册的微服务实例列表。
- 服务发现
服务发现是指在需要调用其他微服务时,通过服务注册中心来获取可用的微服务实例信息。下面是服务发现的步骤:
- 微服务需要调用其他服务时,它向服务注册中心发送发现请求,指定需要调用的服务名称。
- 服务注册中心根据服务名称查询已注册的微服务实例列表,并返回给调用方。
- 调用方根据负载均衡策略选择一个可用的微服务实例进行调用。
- 实现方式
服务注册与发现可以采用不同的实现方式,常见的有以下几种:
- 基于服务注册中心的实现:使用独立的服务注册中心,例如Netflix Eureka、Consul或Nacos。微服务在启动时将自己注册到注册中心,其他微服务可以通过查询注册中心获取可用的微服务实例信息。
- 基于DNS的实现:每个微服务使用自己的主机名和端口号,其他微服务通过域名解析来发现和调用它们。这种方式通常用于较小规模的微服务架构。
- 基于边车代理的实现:使用边车代理(例如Zuul或Spring Cloud Gateway)来代理所有的微服务请求,并在代理层进行服务发现和负载均衡。
在实现服务注册与发现时,我们通常会使用专门的框架和工具来简化开发和管理。例如,结合Spring Cloud框架和Nacos注册中心,我们可以通过使用@EnableDiscoveryClient注解启用服务注册与发现功能,并通过配置中心来配置服务注册中心的地址。然后,我们可以通过注入DiscoveryClient来获取已注册的微服务实例列表,并根据需要进行调用。
通过服务注册与发现,我们可以实现微服务架构的弹性、可扩展和高可用性,使得微服务之间的通信更加灵活和可靠。
接下来,我们将使用Nacos作为服务注册与发现的中间件,并进行安装和配置。
Nacos(Naming and Configuration Service)是一个开源的服务注册与发现中间件,由阿里巴巴集团开发和维护。它提供了服务注册、发现、配置管理和动态配置更新的功能,可以帮助我们构建弹性可伸缩的微服务架构。
Nacos支持主流的服务注册和发现协议,如Eureka、Consul和Nacos自身的服务注册协议。它还提供了灵活的配置管理功能,支持动态配置刷新,可以帮助我们实现微服务的配置中心。
1.安装和配置Nacos
首先,我们需要安装Nacos Server。请按照以下步骤进行操作:
步骤 1:下载Nacos Server
你可以从Nacos的官方GitHub仓库下载最新版本的Nacos Server。
下载地址:https://github.com/alibaba/nacos/releases
步骤 2:解压Nacos Server
将下载的Nacos压缩文件解压到你选择的目录中。
步骤 3:启动Nacos Server
进入解压后的Nacos目录,执行以下命令启动Nacos Server:
PS D:\\program\\nacos\\bin> .\\startup.cmd -m standalone
"nacos is starting with standalone"
,--.
,--.\'|
,--,: : | Nacos 2.2.2
,`--.\'`| \' : ,---. Running in stand alone mode, All function modules
| : : | | \' ,\'\\ .--.--. Port: 8848
: | \\ | : ,--.--. ,---. / / | / / \' Pid: 16948
| : \' \'; | / \\ / \\. ; ,. :| : /`./ Console: http://10.23.48.43:8848/nacos/index.html
\' \' ;. ;.--. .-. | / / \'\' | |: :| : ;_
| | | \\ | \\__\\/: . .. \' / \' | .; : \\ \\ `. https://nacos.io
\' : | ; .\' ," .--.; |\' ; :__| : | `----. \\
| | \'`--\' / / ,. |\' | \'.\'|\\ \\ / / /`--\' /
\' : | ; : .\' \\ : : `----\' \'--\'. /
; |.\' | , .-./\\ \\ / `--\'---\'
\'---\' `--`---\' `----\'
2023-05-17 11:20:55,045 INFO Tomcat initialized with port(s): 8848 (http)
Nacos Server将在默认端口(8848)启动,并以单机模式运行。
步骤 4:访问Nacos控制台
在浏览器中访问以下地址,进入Nacos控制台:
http://10.23.48.43:8848/nacos
2.引入Nacos相关依赖
在开始之前,我们需要在项目的pom.xml文件中添加Nacos相关依赖。请添加以下依赖:
xmlCopy code<dependencies>
<!-- Nacos Discovery -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
<version>2021.1</version>
</dependency>
<!-- spring cloud,基于spring cloud才会读取bootstrap.yml -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bootstrap</artifactId>
</dependency>
<!-- 其他依赖... -->
</dependencies>
以上依赖将引入Nacos服务注册与发现的功能。
3.系统配置变更
现在,我们需要进行一些系统配置变更,以便我们的微服务可以与Nacos进行交互。请在bootstrap.yml文件中添加以下配置:
spring:
cloud:
nacos:
discovery:
server-addr: 10.23.48.43:8848
以上配置指定了Nacos Server的地址和端口。
4.示例代码
接下来,我们将编写示例代码,实现服务注册与发现的功能。请添加以下代码到Spring Boot应用程序中的启动类上方:
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
@EnableDiscoveryClient
@SpringBootApplication
public class StudentsServiceApplication
public static void main(String[] args)
SpringApplication.run(StudentsServiceApplication.class, args);
在以上代码中,我们使用了@EnableDiscoveryClient注解来启用服务注册与发现功能。
现在,你的微服务将能够与Nacos进行通信,实现服务的注册和发现。

在接下来的步骤中,我们将继续编写代码来实现其他功能,如服务网关、服务间通信等。
6、实现服务调用和负载均衡
在微服务架构中,服务之间的调用是非常常见的场景。为了简化服务调用的过程并实现负载均衡,我们可以使用Feign与Nacos结合来实现。本节将详细介绍服务调用的概念以及如何使用Feign与Nacos来实现服务调用和负载均衡。
- 服务调用的概念
服务调用是指一个微服务向另一个微服务发起请求,获取所需的数据或执行特定的操作。在微服务架构中,服务调用可以跨越多个微服务实例,因此需要一种机制来管理和处理服务之间的通信。
- 使用Feign与Nacos实现服务调用和负载均衡
-
Feign是一个声明式的Web服务客户端,它可以与多种服务注册中心集成,包括Nacos。通过使用Feign,我们可以通过简单的接口定义来调用其他微服务,并且不需要手动编写具体的HTTP请求代码。
-
Nacos作为服务注册中心,提供了服务发现和负载均衡的功能。它可以自动维护微服务实例列表,并根据负载均衡策略选择合适的实例进行调用。
下面是使用Feign与Nacos结合实现服务调用和负载均衡的步骤:
- 步骤 1: 引入依赖
在项目的pom.xml文件中添加Feign相关的依赖:
<dependencies>
<!-- Feign -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency>
<!-- 其他依赖... -->
</dependencies>
- 步骤 2: 启用Feign客户端
在启动类上添加@EnableFeignClients注解,启用Feign客户端:
import org.springframework.cloud.openfeign.EnableFeignClients;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@EnableDiscoveryClient
@EnableFeignClients
@SpringBootApplication
public class StudentsServiceApplication
public static void main(String[] args)
SpringApplication.run(StudentsServiceApplication.class, args);
- 步骤 3: 创建Feign客户端接口
创建一个Feign客户端接口,使用@FeignClient注解指定要调用的微服务名称和相关配置:
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.GetMapping;
@FeignClient(name = "students-service")
public interface StudentFeignClient
@GetMapping("/students/id")
Student getStudentById(@PathVariable("id") Long id);
- 步骤 4: 使用Feign客户端进行服务调用
通过注入Feign客户端接口,并调用相应的方法来进行服务调用:
import com.crazymaker.students.entity.Student;
import com.crazymaker.students.feign.StudentFeignClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class StudentService
private StudentFeignClient feignClient;
@Autowired
public StudentService(StudentFeignClient feignClient)
this.feignClient = feignClient;
public Student getStudentById(Long id)
return feignClient.getStudentById(id);
在上面的示例中,通过serviceClient.getStudentById()来调用目标微服务的接口。
通过以上步骤,我们可以使用Feign与Nacos结合来实现服务调用和负载均衡。Feign将负责处理底层的HTTP通信细节,而Nacos将负责维护微服务实例列表和选择合适的实例进行调用,从而实现了服务调用和负载均衡的功能。
7、实现服务监控和日志管理
服务监控是指对微服务架构中的各个服务进行实时监控和管理,以确保系统的稳定性和可靠性。通过监控服务的运行状态、性能指标和异常情况,可以及时发现问题并采取相应措施,以提高系统的可用性和响应能力。
日志管理是指对微服务架构中生成的日志进行收集、存储、分析和展示的过程。日志是系统运行的重要记录,通过对日志进行管理和分析,可以了解系统的运行状况、故障信息和异常情况,以便于问题排查和系统优化。
服务监控和日志管理对于微服务架构具有重要的必要性和优势:
- 实时监控和管理:通过服务监控,可以实时监测服务的运行状态、性能指标和异常情况,及时发现问题并采取措施,保证系统的稳定性和可靠性。
- 故障排查和问题定位:通过日志管理,可以收集和分析系统生成的日志信息,帮助快速定位问题、排查故障,提高故障处理的效率。
- 性能优化和系统优化:通过监控和分析服务的性能指标,可以发现性能瓶颈和优化空间,以提升系统的性能和响应能力。
- 数据分析和业务洞察:通过对日志进行分析和挖掘,可以获得有价值的业务洞察,帮助优化业务流程和决策制定。
下面我们通过分别搭建和配置Spring Boot Admin 和 ELK 服务来实现性能监控和日志管理:
1.Spring Boot Admin 服务监控
Spring Boot Admin是一个开源的服务监控和管理工具,它提供了一个Web界面,用于监控和管理基于Spring Boot的应用程序。通过Spring Boot Admin,可以实时监控和管理应用程序的运行状态、健康状况、性能指标等,并提供了强大的可视化和告警功能。
安装和配置Spring Boot Admin的步骤如下:
-
按上文步骤新建一个Spring Boot项目, 添加Spring Boot Admin的依赖
- 在Spring Boot应用程序的pom.xml文件中添加Spring Boot Admin的依赖:
<dependency>
<groupId>de.codecentric</groupId>
<artifactId>spring-boot-admin-starter-server</artifactId>
<version>3.0.3</version>
</dependency>
- 配置
bootstrap.yml和application.yml文件
spring:
cloud:
nacos:
discovery:
server-addr: 10.23.48.43:8848
server:
port: 8181
servlet:
context-path: /
spring:
application:
name: admin-service
- 启动Spring Boot Admin Server
@EnableDiscoveryClient
@SpringBootApplication
@EnableAdminServer
public class AdminServiceApplication
public static void main(String[] args)
SpringApplication.run(AdminServiceApplication.class, args);
启动应用程序, 点击 http://10.23.48.43:8181/applications 访问监控页面
- 微服务项目配置Spring Boot Admin
1)pom.xml 里添加admin依赖
<dependency>
<groupId>de.codecentric</groupId>
<artifactId>spring-boot-admin-starter-server</artifactId>
<version>3.0.3</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
2)在Spring Boot应用程序的配置文件(如application.yml)中,配置Spring Boot Admin Server的相关信息:
spring:
boot:
admin:
client:
url: http://10.23.48.43:8181 # Spring Boot Admin Server的地址
management:
endpoints:
web:
exposure:
include: \'*\'
endpoint:
health:
show-details: ALWAYS
- 重新启动应用程序
重新启动应用程序, 它将自动注册到Spring Boot Admin Server。
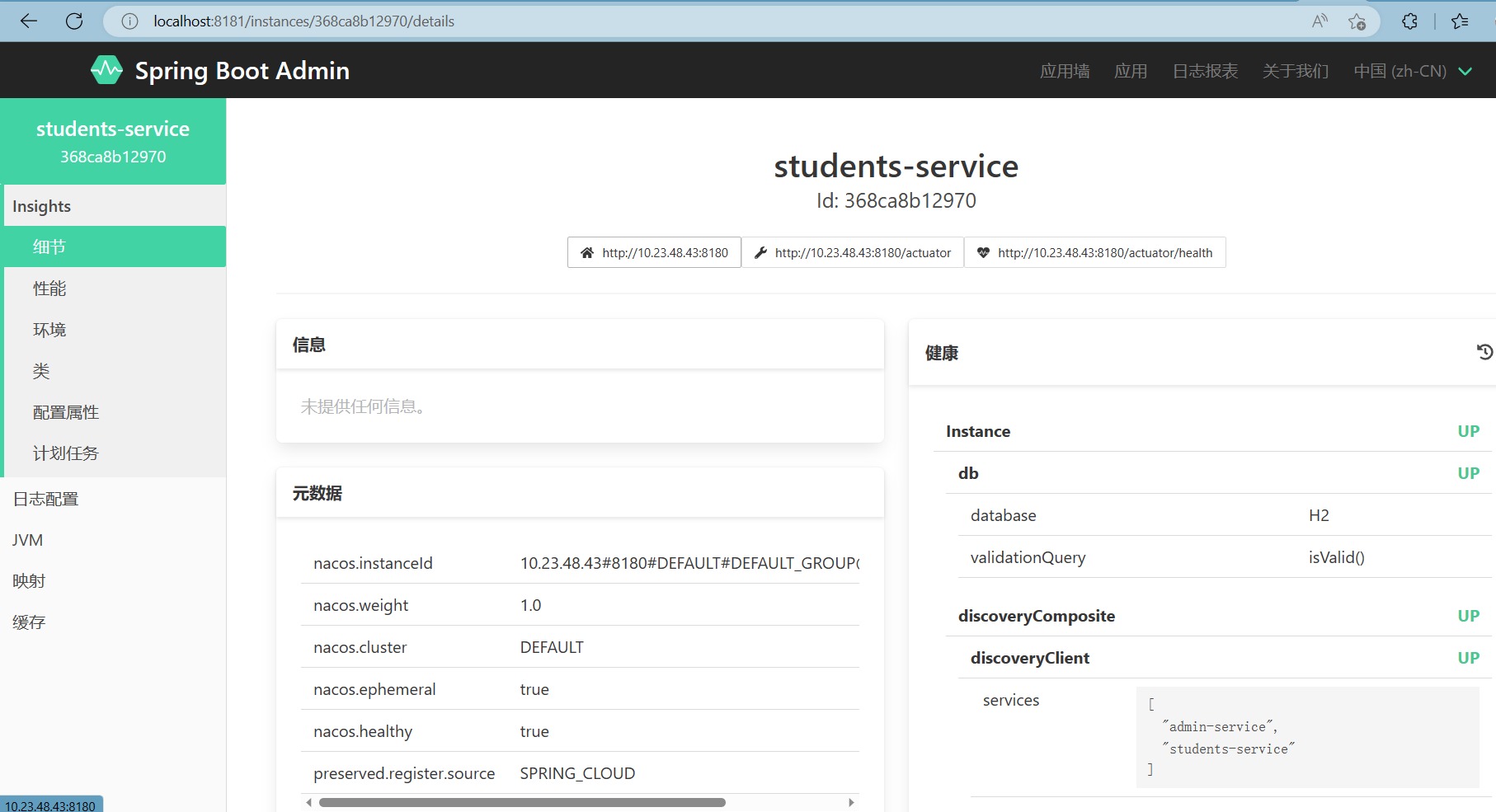
通过以上配置,我们可以实现Spring Boot Admin与Nacos的结合,使得应用程序能够通过Spring Boot Admin进行监控和管理。
2.ELK 日志监控
ELK是一个流行的日志管理和分析解决方案,由Elasticsearch、Logstash和Kibana三个项目组成,常用于日志收集和分析。
日志主要包括系统日志、应用程序日志和安全日志。运维和开发人员可以通过日志了解服务器运行过程中发生的错误及错误产生的原因。定期分析日志可以了解服务器的运行情况、性能、安全性等。
每台服务器或应用程序都会产生日志,如果每次都登录这些服务器查看日志并分析会耗费大量时间,而且效率低下,这时我们就需要思考如何将日志汇总起来统一查看。日志集中管理之后又会产生新的问题,日志量太大,日志统计和检索又成为新的问题,如何能实现高性能的检索统计呢?ELK能完美解决我们的问题。
- Elasticsearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
- Logstash是一个完全开源的工具,他可以对你的日志进行收集、分析,并将其存储供以后使用。
- kibana 也是一个开源和免费的工具,它可以为 Logstash 和 Elasticsearch 提供的日志分析友好的 Web 界面,可以汇总、分析和搜索重要数据日志。
关于ELK的原理和实操,强烈推荐:
ELK日志平台(elasticsearch +logstash+kibana)原理和实操(史上最全):
https://www.cnblogs.com/crazymakercircle/p/16732034.html
ELK安装
本文这里为了方便演示,仅演示利用docker容器在本机部署ELK,在实际生产环境下,推荐使用多台linux服务器,安装ELK集群。
首先新建elk目录,在目录下新建相关文件夹:
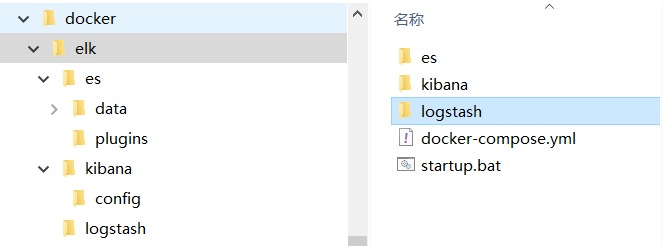
docker-compose.yml内容如下:
version: \'3.2\'
services:
elasticsearch:
image: elasticsearch:7.17.4
volumes:
- ./es/plugins:/usr/share/elasticsearch/plugins #插件文件挂载
- ./es/data:/usr/share/elasticsearch/data #数据文件挂载
- ./es/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml #配置
ports:
- \'9200:9200\'
- \'9300:9300\'
container_name: elasticsearch
environment:
- \'cluster.name=elasticsearch\' #设置集群名称为elasticsearch
- \'discovery.type=single-node\' #以单一节点模式启动
- \'ES_JAVA_OPTS=-Xms1024m -Xmx1024m\' #设置使用jvm内存大小
networks:
- elk
logstash:
image: logstash:7.17.4
container_name: logstash
volumes:
- \'./logstash/logstash.conf:/usr/share/logstash/pipeline/logstash.conf\'
ports:
- \'5044:5044\'
- \'50000:50000/tcp\'
- \'50000:5000/udp\'
- \'9600:9600\'
environment:
LS_JAVA_OPTS: -Xms1024m -Xmx1024m
TZ: Asia/Shanghai
MONITORING_ENABLED: false
links:
- elasticsearch:es #可以用es这个域名访问elasticsearch服务
networks:
- elk
depends_on:
- elasticsearch
kibana:
image: kibana:7.17.4
container_name: kibana
volumes:
- ./kibana/config/kibana.yml:/usr/share/kibana/config/kibana.yml
ports:
- \'5601:5601\'
links:
- elasticsearch:es #可以用es这个域名访问elasticsearch服务
environment:
- ELASTICSEARCH_URL=http://elasticsearch:9200 #设置访问elasticsearch的地址
- \'elasticsearch.hosts=http://es:9200\' #设置访问elasticsearch的地址
- I18N_LOCALE=zh-CN
networks:
- elk
depends_on:
- elasticsearch
networks:
elk:
name: elk
driver:
bridge
在es目录下新建 data、plugins 文件夹, 以及elasticsearch.yml文件,内容如下:
cluster.name: elasticsearch # 集群名称
node.name: node-1 # 节点名称
network.host: 0.0.0.0 # 监听地址
http.port: 9200 # 监听端口
http.cors.enabled: true
http.cors.allow-origin: "*"
在logstash目录下新建logstash.conf文件, 内容如下:
input
tcp
port => 5000
codec => json
filter
# 进行过滤和转换规则的配置
output
elasticsearch
hosts => ["es:9200"] # Elasticsearch的地址
index => "my-application-%+YYYY.MM.dd" # 索引名称,可按日期划分
在kibana目录下,创建config文件夹,并新建kibana.yml文件,内容如下:
# Default Kibana configuration for docker target
server.host: \'0.0.0.0\'
server.shutdownTimeout: \'5s\'
elasticsearch.hosts: [\'http://elasticsearch:9200\']
monitoring.ui.container.elasticsearch.enabled: true
server.port: 5601 # 监听端口
启动:
docker-compose -f docker-compose.yml up -d
微服务应用接入
- 在应用系统中,将日志输出到Logstash的监听端口。以下是一个Logback配置的示例
logback-spring.xml:
<configuration>
<appender name="logstash" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<destination>10.23.48.43:5000</destination>
<encoder class="net.logstash.logback.encoder.LogstashEncoder" />
</appender>
<root level="info">
<appender-ref ref="logstash" />
</root>
</configuration>
- 引入logstash依赖
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>7.2</version>
</dependency>
- 使用Kibana访问Elasticsearch,配置索引模式、定义可视化仪表板和图表等,以展示和分析日志数据。
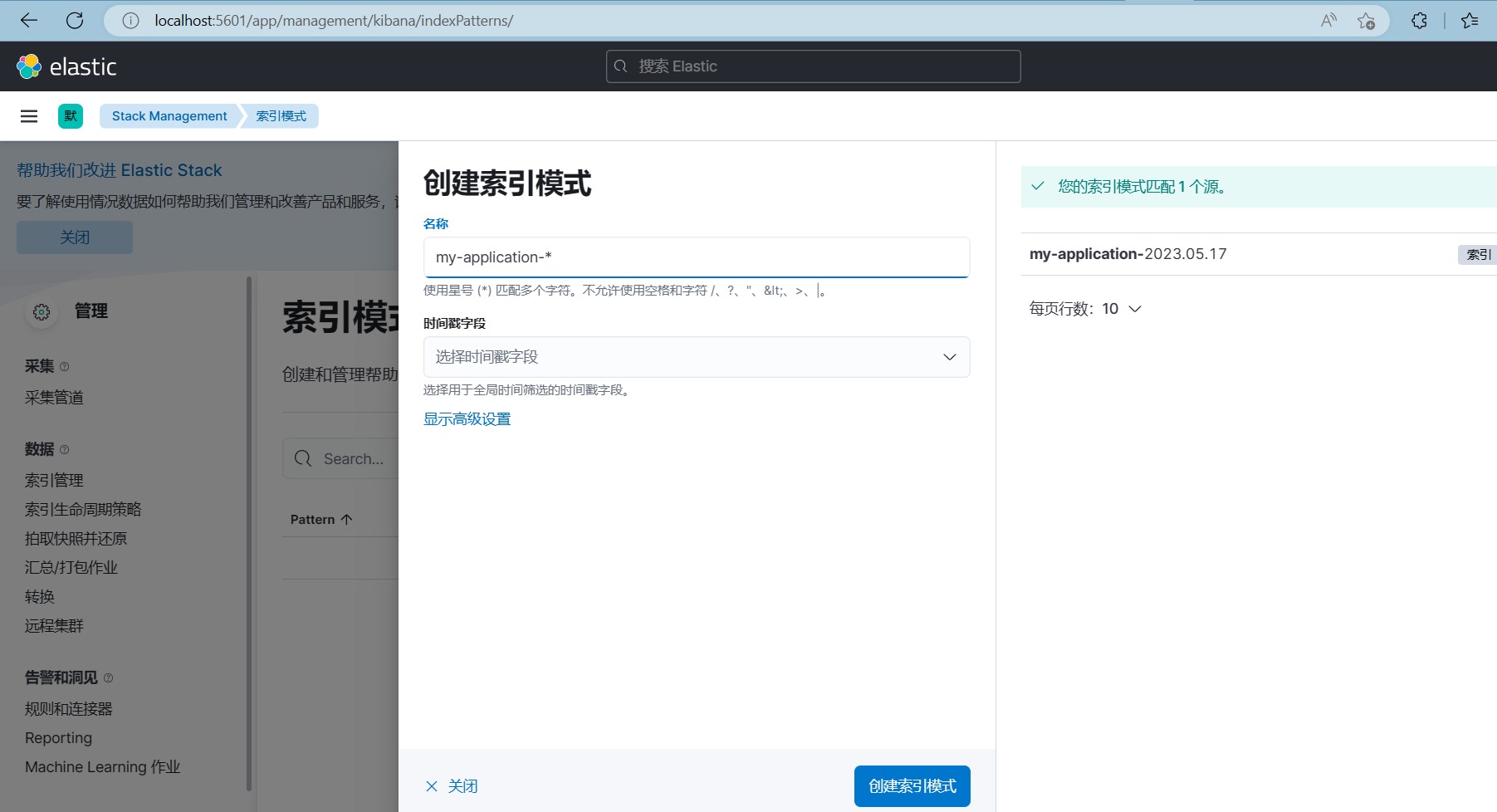
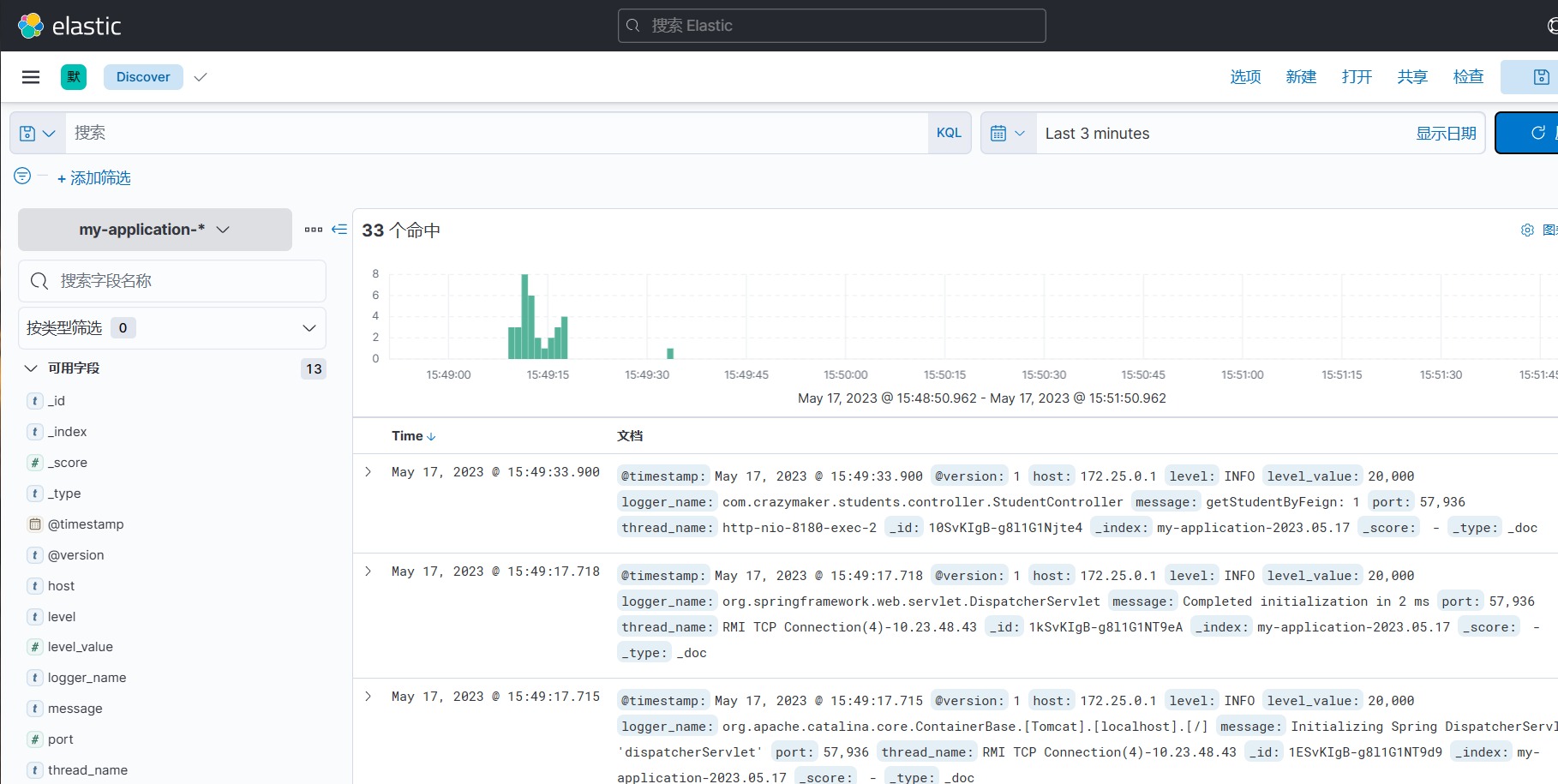
通过以上步骤,我们可以搭建起ELK Stack,并将应用系统接入到ELK Stack中进行日志的收集、存储、分析和可视化展示。这样,我们可以方便地对日志进行搜索、过滤、聚合和可视化,帮助我们快速定位问题、监控系统的运行状况,并提供数据支持进行性能优化和故障排查。
通过结合这些开源中间件,我们可以实现对微服务的全面监控和日志管理,帮助我们及时发现问题、优化性能,并提供可视化的展示和分析工具,从而提升微服务架构的可靠性和稳定性。
8、保护服务安全
在微服务架构中,服务安全保护是至关重要的,它们可以保护微服务免受未经授权的访问,并确保只有经过身份验证和授权的用户才能访问受保护的资源。
Spring Cloud Gateway是一个基于Spring Framework 5、Project Reactor和Spring Boot 2构建的轻量级网关服务,用于构建和管理微服务架构中的API网关。
API网关在微服务架构中安全方面扮演着重要的角色,它作为系统的入口,它可以提供以下安全功能:
-
访问控制:API网关可以对传入的请求进行访问控制,确保只有经过身份验证和授权的用户能够访问受保护的资源。它可以验证请求中的身份验证令牌或证书,并根据配置的权限规则进行访问控制。
-
安全认证和授权:API网关可以与认证和授权中间件(如OAuth2)集成,实现对微服务的安全认证和授权。它可以验证请求中的访问令牌,并将认证和授权信息传递给后端的微服务,以确保只有具有足够权限的用户能够访问特定的资源。
-
保护后端服务:API网关可以隐藏后端的微服务架构,只暴露必要的接口给外部客户端,从而降低了被恶意攻击的风险。它可以阻止未经授权的请求直接访问后端服务,并提供请求的限流和缓冲功能,以保护后端服务免受过载或恶意攻击。
-
安全审计和日志记录:API网关可以记录请求和响应的详细信息,包括访问时间、来源IP、请求内容等,以便进行安全审计和故障排查。它可以将日志记录到集中的日志管理系统中,方便监控和分析。
-
攻击防护:API网关可以实施一些安全防护措施,如防止跨站脚本攻击(XSS)、跨站请求伪造(CSRF)和注入攻击等。它可以对传入的请求进行验证和过滤,以识别和阻止潜在的恶意行为。
综上所述,API网关在安全方面具有重要的作用。它可以提供访问控制、安全认证和授权、保护后端服务、安全审计和日志记录以及攻击防护等功能,帮助确保微服务架构的安全性和可靠性。
通过合理配置和使用适当的安全机制,API网关可以成为微服务架构中的首道防线,保护系统免受潜在的安全威胁。
下面是搭建和配置Spring Cloud Gateway的步骤示例:
首先创建一个Spring Boot应用, 在项目的pom.xml文件中添加相应的依赖配置。
<dependencies>
<!-- Spring Cloud Gateway -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<!-- Spring Cloud Nacos Discovery -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
</dependencies>
接下来,在application.yml文件中配置Spring Cloud Gateway和Nacos的相关信息。
# Spring Cloud Gateway配置
server:
port: 8182
spring:
cloud:
gateway:
discovery:
locator:
enabled: true
lower-case-service-id: true
# Nacos配置
spring:
cloud:
nacos:
discovery:
server-addr: $nacos.server-addr # Nacos Server地址
# 网关路由配置
spring:
cloud:
gateway:
routes:
- id: sample-service # 路由ID
uri: lb://student-service # 后端服务名
predicates:
- Path=/student/** # 匹配的路径
filters:
- StripPrefix=1 # 去除前缀
以上配置中,需要将nacos.server-addr替换为实际的Nacos Server地址。
然后,创建一个启动类并添加@EnableDiscoveryClient注解,启用服务发现功能。
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
@SpringBootApplication
@EnableDiscoveryClient
public class GatewayApplication
public static void main(String[] args)
SpringApplication.run(GatewayApplication.class, args);
最后,通过配置路由规则,将请求转发到后端的微服务。可以使用@Bean注解在配置类中定义路由规则,或者使用配置文件中的spring.cloud.gateway.routes属性进行配置。
import org.springframework.cloud.gateway.route.RouteLocator;
import org.springframework.cloud.gateway.route.builder.RouteLocatorBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class GatewayConfig
@Bean
public RouteLocator customRouteLocator(RouteLocatorBuilder builder)
return builder.routes()
.route("student-service", r -> r.path("/student/**")
.uri("lb://student-service"))
.build();
通过以上配置,Spring Cloud Gateway将根据路由规则将/sample/**路径的请求转发到名为sample-service的后端微服务。
请注意,示例中的sample-service是一个示意的后端微服务名称,需要根据实际情况替换为真实的微服务名称。
这样,结合Spring Cloud Gateway和Nacos的示例就完成了。启动应用后,它将根据配置的路由规则将请求转发到相应的后端微服务,并通过Nacos进行服务的注册和发现。
Spring Cloud Gateway作为微服务架构的入口,除了提供了路由转发,还提供了负载均衡、过滤器、安全认证、请求限流和监控等功能,
关于服务保护,本圣经后面有专栏介绍。当然,有兴趣的小伙伴可以阅读
SpringCloud gateway (史上最全) - 疯狂创客圈:https://www.cnblogs.com/crazymakercircle/p/11704077.html
进一步学习和掌握相关知识。
9、实现持续集成和部署
持续集成(Continuous Integration)是一种软件开发实践,旨在频繁地将代码集成到主干版本控制系统中。持续部署(Continuous Deployment)是持续集成的延伸,自动将通过持续集成构建的可部署软件包发布到生产环境。
以下是一种基本的实现方式:
-
版本控制:使用版本控制系统(如Git)管理代码,确保团队成员可以协同开发,并且每个更改都有明确的记录。
-
自动化构建:使用构建工具(如Maven)配置构建脚本,定义项目的编译、打包、测试等步骤。
-
持续集成服务器:使用持续集成服务器(如Jenkins)来触发构建,并执行自动化构建过程。
-
自动化测试:编写并执行自动化测试脚本,包括单元测试、集成测试和端到端测试等,以确保代码质量和功能稳定性。
-
自动化部署:使用容器化技术(如Docker)打包应用程序,并将其部署到预先定义的
手把手带你搭建SpringCloud, 从公共模块搭建一套完整微服务架构
话不多说,好久没更新了,因为最近真的是太忙了,加上身体出了点问题,就一直在休息,也没怎么给大家更新新的内容,今天,就直接上大招,从公共模块开始,搭建SpringCloud架构,如果刚好你也在做这件事,希望能对你有所帮助
公共模块封装
在一个完整的微服务架构体系中,字符串和日期的处理往往是最多的。在一些安全应用场景下,还会用到加密算法。为了提升应用的扩展性,我们还应对接口进行版本控制。因此,我们需要对这些场景进行一定的封装,方便开发人员使用。本章中,我们优先从公共模块入手搭建一套完整的微服务架构。
common 工程常用类库的封装
common工程是整个应用的公共模块,因此,它里面应该包含常用类库,比如日期时间的处理、字符串的处理、加密/解密封装、消息队列的封装等。日期时间的处理
在一个应用程序中,对日期时间的处理是使用较广泛的操作之一,比如博客发布时间和评论时间等。而时间是以时间戳的形式存储到数据库中的,这就需要我们经过一系列处理才能返回给客户端。
因此,我们可以在common工程下创建日期时间处理工具类Dateutils,其代码如下:
import java.text.ParseException;
import java.text.SimpleDateFormat;import java.util.calendar;
import java.util.Date;
public final class DateUtils {
public static boolean isLegalDate(String str, String pattern){
try {
SimpleDateFormat format = new SimpleDateFormat(pattern);format.parse(str);
return true;
} catch (Exception e){
return false;
}
}
public static Date parseString2Date(String str,String pattern){
try {
SimpleDateFormat format = new SimpleDateFormat(pattern);return format.parse( str);
}catch (ParseException e){
e.printstackTrace();return null;
}
}
public static calendar parseString2calendar(String str,String pattern){
return parseDate2Calendar(parsestring2Date(str, pattern));
}
public static String parseLong2DateString(long date,String pattern){
SimpleDateFormat sdf = new SimpleDateFormat(pattern);
String sd = sdf.format(new Date(date));
return sd;
}
public static Calendar parseDate2Calendar(Date date){
Calendar calendar = Calendar.getInstance();
calendar.setTime(date);
return calendar;
}
public static Date parseCalendar2Date(calendar calendar){
return calendar.getTime();
}
public static String parseCalendar2String(calendar calendar,String pattern){
return parseDate2String(parsecalendar2Date(calendar), pattern);
}
public static String parseDate2String(Date date,String pattern) {
SimpleDateFormat format = new SimpleDateFormat(pattern);
return format.format(date);
}
public static String formatTime( long time){
long nowTime = System.currentTimeMillis();long interval = nowTime - time;
long hours = 3600 * 1000;
long days = hours * 24;long fiveDays = days *5;if (interval < hours){
long minute = interval / 1008/ 60;
if (minute == 0) {
return“刚刚";
}
return minute +"分钟前";}else if (interval < days){
return interval / 1000/ 360日 +"小时前";}else if (interval< fiveDays) {
return interval / 1000 / 3600/ 24+"天前";}else i
Date date = new Date(time);
return parseDate2String(date,"MM-dd");
}
}
}在处理日期格式时,我们可以调用上述代码提供的方法,如判断日期是否合法的方法isLegalDate。我们在做日期转换时,可以调用以 parse开头的这些方法,通过方法名大致能知道其含义,如parseCalendar2String表示将calendar类型的对象转化为String类型,parseDate2String 表示将Date类型的对象转化为string类型,parseString2Date表示将String类型转化为Date类型。
当然,上述代码无法囊括所有对日期的处理。如果你在开发过程中有新的处理需求时,可以在DateUtils 中新增方法。
另外,我们在做项目开发时应遵循“不重复造轮子”的原则,即尽可能引入成熟的第三方类库。目前,市面上对日期处理较为成熟的框架是 Joda-Time,其引入方法也比较简单,只需要在pom.xml加入其依赖即可,如:
<dependency>
<groupId>joda-time</groupId>
<artifactId>joda-time</ artifactId><version>2.10.1</version>
</dependency>使用Joda-Time 也比较简单,只需构建DateTime对象,通过DateTime对象进行日期时间的操作即可。如取得当前日期后90天的日期,可以编写如下代码:
DateTime dateTime = new DateTime();
System.out.println(dateTime.plusDays(90).toString("yyyy-MM-dd HH:mm:ss"));Joda-Time是一个高效的日期处理工具,它作为JDK原生日期时间类的替代方案,被越来越多的人使用。在进行日期时间处理时,你可优先考虑它。
字符串的处理
在应用程序开发中,字符串可以说是最常见的数据类型,对它的处理也是最普遍的,比如需要判断字符串的非空性、随机字符串的生成等。接下来,我们就来看一下字符串处理工具类stringUtils:
public final class StringUtils{
private static final char[] CHARS ={ '0','1','2','3', '4', '5','6', '7',' 8','9'};
private static int char_length =CHARS.length;
public static boolean isEmpty( string str){return null == str ll str.length()== 0;
}
public static boolean isNotEmpty(string str){
return !isEmpty(str);
}
public static boolean isBlank(String str){
int strLen;
if (null == str ll(strLen = str.length())== 0){
return true;
}
for (int i= e; i< strLen; i++){
if ( !Character.iswhitespace(str.charAt(i))){
return false;
}
}
return true;
}
public static boolean isNotBlank(String str){
return !isBlank(str);
}
public static String randomString(int length){
StringBuilder builder = new StringBuilder(length);Random random = new Random();
for (int i = 0; i< length; i++){
builder.append(random.nextInt(char_length));
}
return builder.toString();
}
public static string uuid()i
return UUID.randomUUID().toString().replace("-","");
}
private StringUtils(){
throw new AssertionError();
}
}字符串亦被称作万能类型,任何基本类型(如整型、浮点型、布尔型等)都可以用字符串代替,因此我们有必要进行字符串基本操作的封装。
上述代码封装了字符串的常用操作,如 isEmpty 和 isBlank均用于判断是否为空,区别在于:isEmpty单纯比较字符串长度,长度为0则返回true,否则返回false,如“”(此处表示空格)将返回false;而isBlank判断是否真的有内容,如“”(此处表示空格)返回true。同理,isNotEmpty和isNotBlank均判断是否不为空,区别同上。randomString表示随机生成6个数字的字符串,常用于短信验证码的生成。uuid用于生成唯一标识,常用于数据库主键、文件名的生成。
加密/解密封装
对于一些敏感数据,比如支付数据、订单数据和密码,在HTTP传输过程或数据存储中,我们往往需要对其进行加密,以保证数据的相对安全,这时就需要用到加密和解密算法。
目前常用的加密算法分为对称加密算法、非对称加密算法和信息摘要算法。
对称加密算法:加密和解密都使用同一个密钥的加密算法,常见的有AES、DES和XXTEA。非对称加密算法:分别生成一对公钥和私钥,使用公钥加密,私钥解密,常见的有RSA。信息摘要算法:一种不可逆的加密算法。顾名思义,它只能加密而无法解密,常见的有MD5.SHA-1和 SHA-256。
本书的实战项目用到了AES、RSA、MD5和 SHA-1算法,故在common 工程下对它们分别进行了封装。
(1)在pom.xml 中下添加依赖:
<dependency>
<groupId>commons-codec</groupId>
<artifactId>commons-codec</artifactId></dependency>
<dependency>
<groupId>commons-io</groupid>
<artifactId>commons-io</ artifactId><version>2.6</version>
</dependency>在上述依赖中,commons-codec是 Apache基金会提供的用于信息摘要和 Base64编码解码的包。在常见的对称和非对称加密算法中,都会对密文进行 Base64编码。而 commons-io是 Apache基金会提供的用于操作输入输出流的包。在对RSA 的加密/解密算法中,需要用到字节流的操作,因此需要添加此依赖包。
(2)编写AES 算法:
import javax.crypto.spec. SecretKeySpec;
public class AesEncryptUtils {
private static final String ALGORITHMSTR = "AES/ECB/PKCSSPadding";
public static String base64Encode(byte[] bytes) i
return Base64.encodeBase64String( bytes);
}
public static byte[] base64Decode(String base64Code) throws Exception {
return Base64.decodeBase64(base64Code);
}
public static byte[] aesEncryptToBytes(String content,String encryptKey) throws
Exception {
KeyGenerator kgen = KeyGenerator.getInstance("AES");
kgen.init(128);
Cipher cipher = Cipher.getInstance(ALGORITHMSTR);
cipher.init(Cipher.ENCRYPT_MODE,new SecretKeySpec(encryptKey.getBytes(),"AES"));
return cipher.doFinal(content.getBytes("utf-8"));
}
public static String aesEncrypt(String content, String encryptKey) throwS Exception {
return base64Encode(aesEncryptToBytes(content,encryptKey));
}
public static string aesDecryptByBytes(byte[] encryptBytes, String decryptKey)throws
Exception {
KeyGenerator kgen = KeyGenerator.getInstance("AES");kgen.init(128);
Cipher cipher = Cipher.getInstance(ALGORITHMSTR);
cipher.init(Cipher.DECRYPT_MODE,new SecretKeySpec(decryptKey.getBytes(),"AES"));byte[] decryptBytes = cipher.doFinal(encryptBytes);
return new String(decryptBytes);
}
public static String aesDecrypt(String encryptStr, String decryptKey) throws
Exception i
return aesDecryptByBytes(base64Decode(encryptStr),decryptKey);
}
}上述代码是通用的AES加密算法,加密和解密需要统一密钥,密钥是自定义的任意字符串,长度为16位、24位或32位。这里调用aesEncrypt方法进行加密,其中第一个参数为明文,第二个参数为密钥;调用aesDecrypt进行解密,其中第一个参数为密文,第二个参数为密钥。
我们注意到,代码中定义了一个字符串常量 ALGORITHMSTR,其内容为AES/ECB/PKCS5Padding,它定义了对称加密算法的具体加解密实现,其中 AES表示该算法为AES算法,ECB为加密模式,PKCS5Padding为具体的填充方式,常用的填充方式还有 PKCS7Padding和 NoPadding等。使用不同的方式对同一个字符串加密,结果都是不一样的。因此,我们在设置加密算法时需要和客户端统一,否则客户端无法正确解密服务端返回的密文。
(3)编写RSA算法:
public class RSAUtils {
public static final String CHARSET ="UTF-8";
public static final String RSA_ALGORITHM="RSA";
public static Map<String,String>createKeys(int keySize){
KeyPairGenerator kpg;
try{
kpg =KeyPairGenerator.getInstance(RSA_ALGORITHM);
Security.addProvider(new com.sun.crypto.provider. SunJCE());}catch(NoSuchAlgorithmException e){
throw new IllegalArgumentException("No such algorithm-->[" + RSA_ALGORITHM +"]");
}
kpg.initialize(keySize);
KeyPair keyPair = kpg.generateKeyPair();
Key publicKey = keyPair.getPublic();
string publicKeyStr = Base64.encodeBase64String(publicKey.getEncoded());
Key privateKey = keyPair.getPrivate();
String privateKeyStr = Base64.encodeBase64String(privateKey.getEncoded());
Map<String,String> keyPairMap = new HashMap<>(2);
keyPairMap.put("publicKey", publicKeyStr);
keyPairMap.put( "privateKey", privateKeyStr);
return keyPairMap;
}
public static RSAPublicKey getPublicKey(String publicKey) throws NoSuchAlgorithmException,InvalidKeySpecException {
KeyFactory keyFactory = KeyFactory.getInstance(RSA_ALGORITHM);
x509EncodedKeySpec x509KeySpec = new X509EncodedKeySpec(Base64.decodeBase64(publicKey)) ;
RSAPublicKey key = (RSAPublicKey) keyFactory.generatePublic( x509KeySpec);
return key;
}
public static RSAPrivateKey getPrivateKey(String privateKey) throws
NoSuchAlgorithmException,InvalidKeySpecException {
KeyFactory keyFactory = KeyFactory.getInstance(RSA_ALGORITHM);
PKCS8EncodedKeySpec pkcs8KeySpec = new PKCS8EncodedKeySpec(Base64.decodeBase64
(privateKey));
RSAPrivateKey key = (RSAPrivateKey) keyFactory.generatePrivate(pkcs8KeySpec);
return key;
}
public static String publicEncrypt(String data,RSAPublicKey publicKey){
try{
Cipher cipher = Cipher.getInstance("RSA/ECB/PKCS1Padding");
cipher.init(Cipher. ENCRYPT_MODE,publicKey);
return Base64.encodeBase64String(rsaSplitCodec(cipher,Cipher. ENCRYPT_MODE,
data.getBytes(CHARSET),publicKey.getModulus().bitLength()));
}catch(Exception e){
throw new RuntimeException("加密字符串["+data +"]时遇到异常",e);
}
}
public static String privateDecrypt(String data,RSAPrivateKey privateKey){
try{
Cipher cipher = Cipher.getInstance("RSA/ECB/PKCS1Padding");
cipher.init(Cipher. DECRYPT_MODE, privateKey);
return new String(rsaSplitCodec(cipher,Cipher. DECRYPT_MODE,
Base64.decodeBase64(data),privateKey.getModulus().bitLength()),CHARSET);
}catch(Exception e){
e.printStackTrace();
throw new RuntimeException("解密字符串["+data+"]时遇到异常",e);
}
}
private static byte[] rsaSplitCodec(Cipher cipher, int opmode, byte[] datas,int keySize){
int maxBlock = 0;
if(opmode == Cipher. DECRYPT_MODE){
maxBlock = keysize / 8;
}else{
maxBlock =keysize / 8 -11;
}
ByteArrayOutputStream out = new ByteArrayoutputStream();int offSet = 0;
byte[] buff;int i = 0;try{
while(datas. length > offSet)f
if(datas.length-offSet > maxBlock){
buff = cipher.doFinal(datas,offSet,maxBlock);}else{
buff = cipher.doFinal(datas,offSet, datas.length-offSet);
}
out.write(buff, 0,buff.length);
i++;
offSet = i * maxBlock;
}
}catch(Exception e){
e.printStackTrace();
throw new RuntimeException("加解密阈值为["+maxBlock+"]的数据时发生异常",e);
}
byte[] resultDatas = out.toByteArray();IOUtils.closeQuietly(out);
return resultDatas;
}
}前面提到了RSA是一种非对称加密算法,所谓非对称,即加密和解密所采用的密钥是不一样的。RSA 的基本思想是通过一定的规则生成一对密钥,分别是公钥和私钥,公钥是提供给客户端使用的,即任何人都可以得到,而私钥存放到服务端,任何人都不能通过正常渠道拿到。
通常情况下,非对称加密算法在客户端使用公钥加密,传到服务端后,服务端利用私钥进行解密。例如,上述代码提供了加解密方法,分别是publicEncrypt和 privateDecrypt方法,但是这两个方法不能直接传公私钥字符串,而是通过getPublicKey和getPrivateKey方法返回RSAPublicKey和RSAPrivateKey对象后再传给加解密方法。
公钥和私钥的生成方式有很多种,如OpenSSL 工具、第三方在线工具和编码实现等。由于非对称加密算法分别维护了公钥和私钥,其算法效率比对称加密算法低,但安全级别比对称加密算法高,读者在选用加密算法时应综合考虑,采取适合项目的加密算法。
(4)编写信息摘要算法:
import java.security.MessageDigest;
public class MessageDigestutils {
public static string encrypt(String password,string algorithm){
try {
MessageDigest md =MessageDigest.getInstance(algorithm);byte[] b = md.digest(password.getBytes("UTF-8"));
return ByteUtils.byte2HexString(b);
}catch (Exception e){
e.printStackTrace();return null;
}
}
}JDK自带信息摘要算法,但返回的是字节数组类型,在实际中需要将字节数组转化成十六进制字符串,因此上述代码对信息摘要算法做了简要的封装。通过调用MessageDigestutils.encrypt方法即可返回加密后的字符串密文,其中第一个参数为明文,第二个参数为具体的信息摘要算法,可选值有MD5、SHA1和SHA256等。
信息摘要加密是一种不可逆算法,即只能加密,无法解密。在技术高度发达的今天,信息摘要算法虽然无法直接解密,但是可以通过碰撞算法曲线破解。我国著名数学家、密码学专家王小云女士早已通过碰撞算法破解了MD5和SHA1算法。因此,为了提高加密技术的安全性,我们一般使用“多重加密+salt”的方式加密,如ND5(MD5(明文+salt)),读者可以将salt理解为密钥,只是无法通过salt解密。
消息队列的封装
消息队列一般用于异步处理、高并发的消息处理以及延时处理等情形,它在当前互联网环境下也被广泛应用,因此同样对它进行了封装,以便后续消息队列使用。
安装完成后,点击Win+R键,在打开的运行窗口中输人命令services.msc并按下Enter键,可以打开服务列表,如图6-1所示。
在这里插入图片描述
可以看到,RabbitMQ已启动。在默认情况下,RabbitMQ安装后只开启5672端口,我们只能通过命令的方式查看和管理RabbitMQ。为了方便,我们可以通过安装插件来开启RabbitMQ的 Web管理功能。打开cmd命令控制台,进入 RabbitMQ安装目录的 sbin目录,输入
rabbitmq-plugins enablerabbitmq_management即可,如图6-2所示。

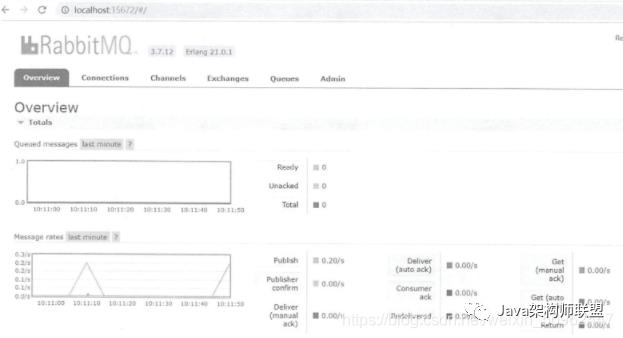
在这里插入图片描述
Web管理界面的默认启动端口为15672。在浏览器中输人localhost:15672,默认的账号和密码都是guest,填写后可以进入Web管理主界面,如图6-3所示。
在这里插入图片描述
接下来,我们就封装消息队列。
(1)添加 RabbitMQ依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bus-amqp</ artifactId>
</dependency>消息队列都是通过Spring Cloud组件Spring Cloud Bus集成的,通过添加依赖spring-cloud-starter-bus-amqp,就可以很方便地使用RabbitMQ。
(2)创建RabbitMQ配置类RabbitConfiguration,用于定义RabbitMQ基本属性:
import org.springframework.amqp.core.Queue;
import org.springframework.boot.SpringBootConfiguration;
import org.springframework.context.annotation. Bean;
@SpringBootConfiguration
public class Rabbitconfiguration {
@Bean
public Queue queue(){
return new Queue( "someQueue");
}
}前面已经讲过,Spring Boot可以利用@SpringBootConfiguration注解对应用程序进行配置。我们集成RabbitMQ依赖后,也需要对其进行基本配置。在上述代码中,我们定义了一个 Bean,该Bean的作用是自动创建消息队列名。如果不通过代码创建队列,那么每次都需要手动去RabbitMQ的Web管理界面添加队列,否则会报错,如图6-4所示。

在这里插入图片描述
但是每次都通过Web管理界面手动创建队列显然不可取,因此,我们可以在上述配置类中事先定义好队列。
(3) RabbitMQ是异步请求,即客户端发送消息,RabbitMQ服务端收到消息后会回发给客户端。发送消息的称为生产者,接收消息的称为消费者,因此还需要封装消息的发送和接收。
创建一个名为MyBean的类,用于发送和接收消息队列:
@Component
public class MyBean {
private final AmqpAdmin amqpAdmin;
private final AmqpTemplate amqpTemplate;
@Autowired
public MyBean(AmqpAdmin amqpAdmin,AmqpTemplate amqpTemplate){
this.amqpAdmin = amqpAdmin;
this.amqpTemplate = amqpTemplate;
}
@RabbitHandler
@RabbitListener(queues = "someQueue")
public void processMessage(String content){
//消息队列消费者
system.out.println( content);
}
public void send(string content){
//消息队列生产者
amqpTemplate.convertAndSend("someQueue", content);
}
}其中,send为消息生产者,负责发送队列名为someQueue 的消息,processNessage为消息消费者,在其方法上定义了@RabbitHandler和@RabbitListener注解,表示该方法为消息消费者,并且指定了消费哪种队列。
接口版本管理
一般在第一版产品发布并上线后,往往会不断地进行迭代和优化,我们无法保证在后续升级过程中不会对原有接口进行改动,而且有些改动可能会影响线上业务。因此,想要对接口进行改造却不能影响线上业务,就需要引人版本的概念。顾名思义,在请求接口时加上版本号,后端根据版本号执行不同版本时期的业务逻辑。那么,即便我们升级改造接口,也不会对原有的线上接口造成影响,从而保证系统正常运行。
版本定义的思路有很多,比如:
本节将介绍第三种版本号的定义思路,最简单的方式就是直接在RequestMapping 中写入固定的版本号,如:
@RequestMapping("/v1/index")我们希望的效果是,如果传入的版本号在项目中无法找到,则自动找最高版本的接口,怎么做呢?请参照以下代码实现。
(1)定义注解类:
@Target(ElementType. TYPE)
@Retention(RetentionPolicy.RUNTIME)@Mapping
@Documented
public @interface ApiVersion {
int value();
}(2)自定义RequestMappingHandler:
public class CustomRequestMappingHandlerMapping extends
RequestMappingHandlerMapping i
@override
protected RequestCondition<ApiVersionCondition> getCustomTypeCondition(Class<?>
handlerType) {
ApiVersion apiVersion = Annotationutils.findAnnotation(handlerType,
Apiversion.class);
return createCondition( apiversion);
}
@override
protected RequestCondition<ApiVersionConditionz getCustomMethodCondition(Nethod method){
ApiVersion apiversion = AnnotationUtils.findAnnotation(method,ApiVersion.class);
return createCondition(apiversion) ;
}
private RequestCondition<ApiVersionCondition> createCondition(ApiVersion apiVersion)f
return apiversion == null ? null : new ApiVersionCondition(apiVersion.value());
}
}Spring MVC在启动应用后会自动映射所有控制器类,并将标有@RequestMapping注解的方法加载到内存中。由于我们继承了RequestMappingHandlerMapping 类,所以在映射时会执行重写的getCustomTypeCondition和getCustomMethodCondition方法,由方法体的内容可以知道,我们创建了自定义的RequestCondition,并将版本信息传给Requestcondition。
(3) CustomRequestMappingHandlerMapping类只继承了RequestMappingHandlerMapping类,Spring Boot并不知晓,因此还需要在配置类中定义它,以便使Spring Boot 在启动时执行自定义的RequestMappingHandlerMapping 类。
在public 工程中创建webConfig 类,并继承 webNvcConfigurationSupport类,然后重写requestMappingHandlerMapping方法,如:
@Override
public RequestMappingHandlerMapping requestMappingHandlerMapping(){
RequestMappingHandlerMapping handlerMapping = new CustomRequestMappingHandlerMapping();handlerMapping.set0rder(0);
return handlerMapping;
}在上述代码中,我们重写了requestMappingHandlerMapping方法并实例化了RequestMapping-HandlerMapping对象,返回的是前面自定义的CustomRequestMappingHandlerMapping类。
@RequestMapping("{version}")
@RestController
@ApiVersion(1)
public class TestV1controller{
@GetMapping("index ")
public String index(){
return "";
}
}输入参数的合法性校验
我们在定义接口时,需要对输入参数进行校验,防止非法参数的侵入。比如在实现登录接口时,手机号和密码不能为空,手机号必须是11位数字等。虽然客户端也会进行校验,但它只针对正常的用户请求,如果用户绕过客户端,直接请求接口,就可能会传入一些异常字符。因此,后端同时对输人参数进行合法性校验是必要的。进行合法性校验最简单的方式是在每个接口内做if-else判断,但这种方式不够优雅。Spring 提供了校验类validator,我们可以对其做文章。
在公共的控制器类中添加以下方法即可:
protected void validate(BindingResult result){
if(result.hasFieldErrors()){
List<FieldError> errorList = result.getFieldErrors();
errorList.stream().forEach(item -> Assert.isTrue(false,item.getDefaultMessage()));
}
}Validator的校验结果会存放到BindingResult类中,因此上述方法传入了BindingResult类。在上面的代码中,程序通过 hasFieldErrors判断是否存在校验不通过的情况,如果存在,则通过getFieldErrors方法取出所有错误信息并循环该错误列表,一旦发现错误,就用Assert 断言方法抛出异常,6.4节将介绍异常的处理,统一返回校验失败的提示信息。
我们使用断言的好处在于它抛出的是运行时异常,即我们不需要用显式在方法后面加 throwsException,也能够保证扩展性较好,同时简化了代码量。
然后在控制器接口的参数中添加@valid注解,后面紧跟 BindingResult类,在方法体中调用validate(result)方法即可,如:
@GetMapping( "index")
public String index(@valid TestRequest request, BindingResult result){
validate(result);
return "Hello " +request.getName();
}要实现接口校验,需要在定义了@valid注解的类中,将每个属性加入校验规则注解,如:
@Data
public class TestRequest {
@NotEmpty
private String name;
}下面列出常用注解,供读者参考。
@NotNull:不能为空。
@NotEmpty:不能为空或空字符串。
@Max:最大值。
@Min:最小值。
@Pattern:正则匹配。
@Length:最大长度和最小长度。
异常的统一处理
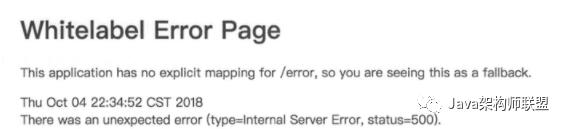
异常,在产品开发中是较为常见的,譬如程序运行或数据库连接等,这些过程中都可能会抛出异常,如果不进行任何处理,客户端就会接收到如图6-5所示的内容。
在这里插入图片描述
可以看出,直接在界面上返回了500,这不是我们期望的。正常情况下,即便出错,也应返回统一的JSON格式,如:
{
"code" :0,
"message" :"不能为空" ,"data" :null
}其实很简单,它利用了Spring的AOP特性,在公共控制器中添加以下方法即可:
@ExceptionHandler
public SingleResult doError(Exception exception){
if(Stringutils.isBlank(exception.getMessage())){
return SingleResult.buildFailure();
}
return SingleResult.buildFailure(exception.getMessage());
}在doError方法上加入@ExceptionHandler注解表示发生异常时,则执行该注解标注的方法,该方法接收Exception类。我们知道,Exception类是所有异常类的父类,因此在发生异常时,SpringMVC会找到标有@ExceptionHandler注解的方法,调用它并传人具体的异常对象。
我们要返回上述JSON格式,只需要返回SingleResult对象即可。注意,SingleResult是自定义的数据结果类,它继承自Result类,表示返回单个数据对象;与之相对应的是MultiResult类,用于返回多个结果集,所有接口都应返回Result。关于该类,读者可以参考本书配套源码,在common工程的 com.lynn.blog.common.result包下。
更换JSON转换器
Spring MVC默认采用Jackson框架作为数据输出的JSON格式的转换引擎,但目前市面上涌现出了很多JSON解析框架,如 FastJson、Gson等,Jackson作为老牌框架已经无法和这些框架媲美。Spring 的强大之处也在于其扩展性,它提供了大量的接口,方便开发者可以更换其默认引擎,JSON转换亦不例外。下面我们就来看看如何将Jackson更换为FastJson。
(1)添加FastJson依赖:
<dependency>
<groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.47</version>
</ dependency>FastJson是阿里巴巴出品的用于生成和解析JSON 数据的类库,其执行效率也是同类框架中出类拔萃的,因此本书采用FastJson作为JSON的解析引擎。
(2)在webConfig 类中重写configureMessageConverters方法:
@override
public void configureMessageConverters(List<HttpMessageConverter< ?>> converters){
super.configureMessageConverters(converters);
FastJsonHttpMessageConverter fastConverter=new Fast]sonHttpMessageConverter();FastJsonConfig fastJsonconfig=new FastsonConfig();
fastJsonconfig.setSerializerFeatures(
SerializerFeature.PrettyFormat
);
List<MediaType> mediaTypeList = new ArrayList<>();mediaTypeList.add(MediaType.APPLICATION_JSON_UTF8);fastConverter.setSupportedMediaTypes(mediaTypeList);fastConverter.setFastsonConfig(fastsonConfig);
converters.add(fastConverter);
}当程序启动时,会执行configureMessageConverters方法,如果不重写该方法,那么该方法体是空的,我们查看源码即可得知。代码如下:
/**
* Override this method to add custom {@link HttpMessageConverter}s to use* with the {@link RequestMappingHandlerAdapter} and the
* {@link ExceptionHandlerExceptionResolver}. Adding converters to the
* list turns off the default converters that would otherwise be registered* by default. Also see {@link #addDefaultHttpNessageConverters(List)} that* can be used to add default message converters.
* @param converters a list to add message converters to;* initially an empty list.
*/
protected void configureMessageConverters(List<HttpNessageConverter<?>> converters) {}这时, Spring MVC将Jackson作为其默认的JSON解析引擎,所以我们一旦重写configureMessage-Converters方法,它将覆盖Jackson,把我们自定义的JSON解析器作为JSON解析引擎。
得益于Spring的扩展性设计,我们可以将JSON解析引擎替换为FastJson,它提供了AbstractHttp-MessageConverter 抽象类和GenericHttpMessageConverter接口。通过实现它们的方法,就可以自定义JSON解析方式。
在上述代码中,FastJsonHttpMessageConverter就是FastJson为了集成Spring而实现的一个转换器。因此,我们在重写configureMessageConverters方法时,首先要实例化FastJsonHttpMessage-Converter对象,并进行Fast]sonConfig基本配置。PrettyFormat表示返回的结果是否是格式化的;而MediaType 设置了编码为UTF-8的规则。最后,将Fast3sonHttpMessageConverter对象添加到conterters列表中。
这样我们在请求接口返回数据时,Spring MVC 就会使用FastJson转换数据。
Redis的封装
Redis 作为内存数据库,使用非常广泛,我们可以将一些数据缓存,提高应用的查询性能,如保存登录数据(验证码和 token等)、实现分布式锁等。
本文实战项目也用到了Redis,且 Spring Boot操作Redis非常方便。SpringBoot集成了Redis并实现了大量方法,有些方法可以共用,我们可以根据项目需求封装一套自己的Redis操作代码。
(1)添加 Redis 的依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>spring-boot-starter-data包含了与数据相关的包,比如jpa、mongodb和elasticsearch等。因此,Redis也放到了spring-boot-starter-data 下。
(2)创建Redis类,该类包含了Redis 的常规操作,其代码如下:
@Component
public class Redis i
@Autowired
private StringRedisTemplate template;
public void set(String key, String value,long expire){
template.opsForValue().set(key, value,expire,TimeUnit.SECONDS);
}
public void set(String key,string value){
template.opsForValue().set(key, value);
}
public Object get(String key) i
return template.opsForValue().get(key);
}
public void delete(String key) {
template.delete(key);
}
}在上述代码中,我们先注入StringRedisTemplate类,该类是Spring Boot 提供的Redis操作模板类,通过它的名称可以知道该类专门用于字符串的存取操作,它继承自RedisTemplate类。代码中只实现了Redis的基本操作,包括键值保存、读取和删除操作。set方法重载了两个方法,可以接收数据保存的有效期,TimeUnit.SECONDS 指定了该有效期单位为秒。读者如果在项目开发过程中发现这些操作不能满足要求时,可以在这个类中添加方法满足需求。
小结
本篇主要封装了博客网站的公共模块,即每个模块都可能用到的方法和类库,保证代码的复用性。读者也可以根据自己的理解和具体的项目要求去封装一些方法,提供给各个模块调用。
关注我,每日更新技术好文

点个

在看
你最好看
最近一段时间,小编请假在家,在这里也提醒各位程序员们,身体第一也没什么收入,就是再吃老本,好处是在家里,妈妈可以好好照顾我,闲来无事,就安利了一下基金股票什么的,总不能一点收入不进不是,但是,这玩意,跟TMD有毒一样,越研究越上瘾,问一下公司的同事还有身边的朋友,好像都在研究这个东西,所以整理一些自己看到比较好的文章,给大家共勉
OPENNING
福利推荐
以上是关于微服务圣经1:零基础搭建一套SpringCloud微服务脚手架(SpringCloud+Dubbo+Docker+Jenkins)的主要内容,如果未能解决你的问题,请参考以下文章
手把手带你搭建SpringCloud, 从公共模块搭建一套完整微服务架构
(十九)从零开始搭建k8s集群——使用KubeSphere管理平台搭建一套微服务的压力测试性能监控平台(Grafana8.5.2+influxdb2.2.0+Jmeter5.4.1)
(十九)从零开始搭建k8s集群——使用KubeSphere管理平台搭建一套微服务的压力测试性能监控平台(Grafana8.5.2+influxdb2.2.0+Jmeter5.4.1)
微服务实践之服务注册与发现(Nacos)-SpringCloud(2020.0.x)-1
(二十)从零开始搭建k8s集群——使用KubeSphere管理平台搭建一套微服务的压力测试性能监控平台(Grafana8.5.2+Prometheus v2.35.0+Jmeter5.4.1)