如何使用 MegEngine 生态落地一个算法
Posted MegEngine
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何使用 MegEngine 生态落地一个算法相关的知识,希望对你有一定的参考价值。
在当今人工智能领域,深度学习算法已经广泛应用于图像处理、自然语言处理、语音识别等各种领域。然而,实现一个高效的深度学习算法需要运用大量的技术和工具,并要面临着许多挑战,如训练计算资源消耗大,模型转换难,高效快捷的推理部署等问题。MegEngine 作为一个训推一体的深度学习框架,其生态工具集合了图像对比、模型转换、硬件性能优化、pipeline 搭建等多种功能,能够满足用户在多种场景下的需求,为算法的实现提供了更多的便利。本文会简要描述如何使用 MegEngine 生态系列工具落地一个算法,以及不同工具之间的协作方式。
文内含有大量文档超链,适合收藏慢慢阅读,enjoy~

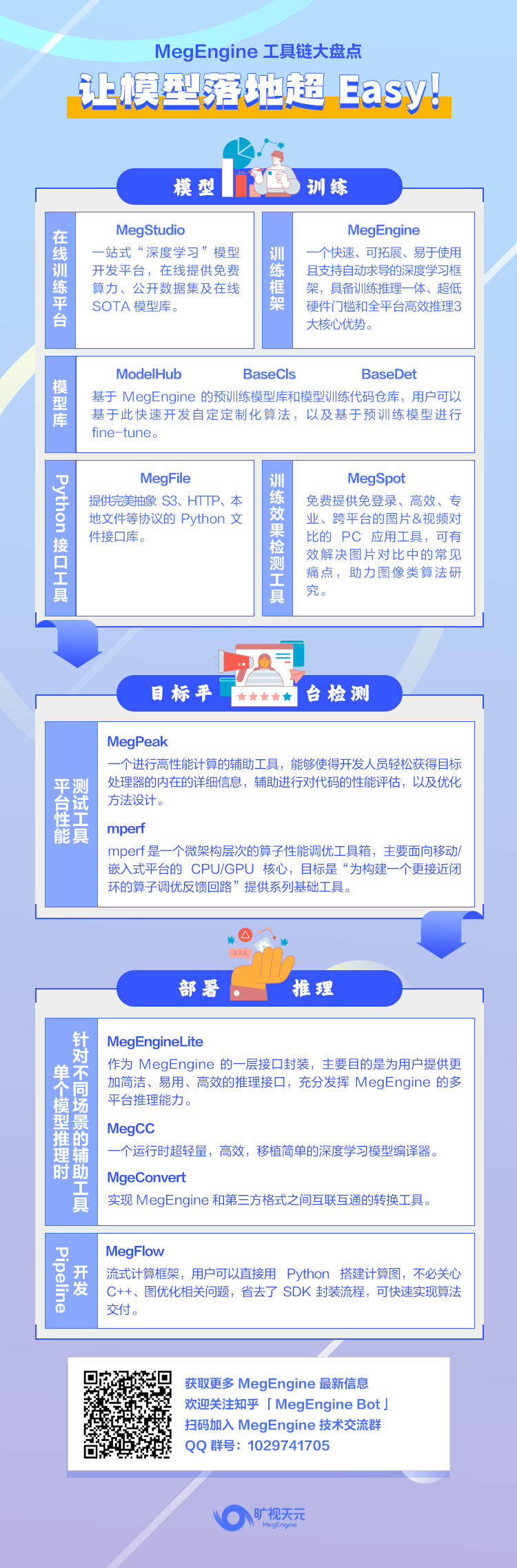
模型训练
在线开发平台 MegStudio
深度学习的入门中,最大的门槛之一就是怎么样搭建编程环境,一站式深度学习模型开发平台 MegStudio 提供了一整套完善的生态系统,帮助用户可以更加便捷地进行算法训练。平台内置 MegEngine,用户无需安装、配置,可随时在线使用,并提供定制化在线 Jupyter Notebook 开发环境。在这里你可以启动免费的算力资源云服务,包括 CPU、多卡 GPU 等,以及体验更便捷的后台运行,远程 kernel 服务,让模型 runtime 更高效。除此之外,MegStudio 还提供了丰富的教程和文档支持,用户可以通过在线文档、视频教程等方式了解如何使用 MegStudio 进行算法训练,快速上手使用。
当然,如果你有丰富的计算资源,也可以选择在本地从模型构建开始进行你的模型训练。
模型构建
神经网络模型的构建就是用 MegEngine、tensorflow,pytorch 等深度学习框架去构建一个模型,一般来说想要训练一个神经网络的步骤包括:准备数据,搭建网络结构,使用优化器进行训练优化。大家可以跟着 MegEngine 快速上手 教程体验 MegEngine 的最基本使用流程。包括:使用 MegEngine 框架开发出经典的 LeNet 神经网络模型;使用它在 MNIST 手写数字数据集上完成训练和测试;将模型用于实际的手写数字分类任务。
同时,MegEngine 提供了 DataLoader、Module、MegFile、Optimizer 等多个功能组件,帮助实现更多功能:
-
在数据处理阶段,dataloader 可以帮助做数据集读取,并支持并行高效的数据预处理和数据增强功能;文档
-
MegFile 是一个完美抽象 S3、HTTP、本地文件等协议的 python 文件接口库,可以对我们的各种数据集做出通用的抽象;文档
-
同时,用户可以通过 Module 的堆叠来搭建网络结构(文档),而 Module 接口中还提供了许多有用的属性和方法,来帮助用户完成这一过程,如:
-
使用 .parameters() 可以方便地获取参数,可被用来追踪梯度,方便进行自动求导;
-
每个 Module 有自己的名字 name, 通过 .named_module() 可以获取到名字和对应的 Module;
-
使用 .state_dict() 和 .load_state_dict() 获取和加载状态信息。
-
最后将网络的输出和真实 label 送入优化器,去进行反向传播和梯度更新,从而实现网络的迭代优化。文档
预训练模型库
由于时间或计算资源的限制,不可能总是从头开始构建一个模型,对于一些常见的模型,MegEngine 生态提供了预训练模型库和模型训练代码仓库,用户可以基于此快速定制发开新的算法,并基于预训练模型进行 fine-tune。
-
ModelHub:基于 MegEngine 实现的各种主流深度学习模型,并提供预训练权重,用户可以不必头开始训练模型,减少训练的时长;
-
BaseCls:极其全面的分类模型库,提供了 EfficientNet、HRNet、MobileNet、RegNet、RepVGG、Swin Transformer、ViT 等多个经典分类模型的训练代码和预训练权重;
DTR 及分布式训练
而为了满足更大规模的模型训练需求,MegEngine 支持 DTR & 分布式训练,可以降低显存需求,提升训练规模。
-
DTR:自 MegEngine v1.4 版本中引入 DTR 技术后,通过不断优化,目前只要一行代码,即可一键开启 DTR 功能,支持动态度及静态图计算,显存占用将至 1/4;使用文档、原理解析
-
分布式训练:MegEngine 作为一个原生就支持分布式计算的框架, 目前开放的接口支持单机多卡,多机多卡以及流水线并行的方式。文档
训练结果验证
在完成上面的设置后我们可以得到一个完整的可训练的 workload。
对于 图片超分,降噪以及视频等算法,在完成训练后,进行最终训练结果验证时,欢迎使用免费的图片&视频对比工具 MegSpot。目前 MegSpot 提供 Mac,Linux,Windows 系统的跨平台支持,同时借助 Electron 框架可低成本完成跨平台应用的开发,并保障各平台体验的一致性。
端上推理
目标平台评测
模型的推理落地,可能需要在嵌入式设备或移动设备上运行。然而,由于这些设备的计算资源和存储容量有限,在此类平台上部署时,目标平台评测便成为了非常重要的一步。将训练完成的深度学习模型部署到目标平台上,通过评估目标平台上的计算能力,可以了解模型在实际应用场景下的性能和功耗等情况,并为模型的进一步优化提供指导。
MegPeak 可以测试目标处理器:指令的峰值带宽、指令延迟、内存峰值带宽、任意指令组合峰值带宽。虽然以上部分信息可以通过芯片的数据手册查询相关数据,然后结合理论计算得到。但是很多情况下我们无法获取目标处理器详尽的性能文档,另外通过 MegPeak 进行测量更直接和准确,并且可以测试特定指令组合的峰值带宽。所以,通过使用 MegPeak 建立对目标部署平台的算力水平的一个初步估计,加上目标模型的 gflops,可做为初步性能评估以及部署后做为一个pipline性能是否异常的一个评价标准。使用文档
深度学习模型的结构通常比较庞大,需要大量的算力才能满足实时运行的需求。如果你想基于 MegEngine 源代码做进一步性能剖析,希望进一步压榨算法性能,不妨试用 mperf。mperf 是一个微架构层次的算子性能调优工具箱,主要面向移动/嵌入式平台的 CPU/GPU 核心,目标是“为构建一个更接近闭环的算子调优反馈回路”提供系列基础工具。(使用文档、快速上手指南)
模型部署
如何将模型高效地部署到不同的硬件平台是一个非常有挑战的问题,针对模型部署的多硬件平台适配问题,MegEngine 提供了多款产品,便于用户按需选择:
-
X86 等 CUDA 平台:MegEngine Lite 作为 MegEngine 推理的第一选择,其具有高性能、多平台支持、支持多种数据精度等特点。可为用户提供更加简洁、易用、高效的推理接口,包括: C++ / C / Python 接口。同时 MegEngine Lite 底层也可以接入其它的推理框架,以及其他的 NPU 支持。 相比较直接调用 MegEngine 的接口进行推理,使用 MegEngine Lite 的接口有使用方便、接口简单、功能齐全等优点, 其底层实现依然是 MegEngine,因此继承了 MegEngine 的所有优点。(文档)
-
ARM /X86/ Risc-v 等 CPU 平台:如果你苦恼于移动端深度学习逻辑的运行时库过大的问题,那么 MegCC 是一个很好的选择。MegCC 使用模型预编译的方案,生成模型推理必要的代码,去除掉了和模型推理无关的代码,因此极大程度上减少了推理引擎的体积。其具备极其轻量的 Runtime 二进制体积,高性能,方便移植,极低内存使用以及快启动等核心特点。用户可在 MLIR 上进行计算图优化,内存规划,最后通过预先写好的 code 模版进行代码生成。目前,MegCC 已支持 Arm64,Armv7,x86,risc-v 以及单片机平台。使用文档、操作指南
-
NPU 平台:MgeConvert 作为适用于 MegEngine 模型的转换器,可将MegEngine导出的 mge静态图模型或 TracedModule 模型转换为第三方模型文件。目前支持转换的第三方框架有 Caffe、ONNX 和 TFLite,支持的模型包括 ResNet、ResNext、ShuffleNet 等。(文档)
高效 pipeline 搭建之 MegFlow
在完成模型的训练及推理部署后,可以借助 MegFlow 实现快速视觉应用落地流程,最快 15 分钟搭建起视频分析服务。MegFlow 的核心特性为:
-
直接用 Python 搭建计算图(如先检测、再跟踪、最后质量判断加识别),不必关心 C++、图优化相关问题;
-
省去 SDK 集成、提升开发体验,通过流程改进应对人力不足、时间紧、功能多的情况;
-
提供 pipeline 搭建、测试、调试、部署、结果可视化一条龙服务。
总结
MegEngine 生态工具,希望能为用户提供一个快速、高效、灵活的深度学习算法落地平台,以更好地实现算法落地。用户可以选择不同的工具组件,实现优化算法性能、提高开发效率、降低计算资源消耗等多种便利。希望本文能够帮助大家更好的了解 MegEngine 生态,并在实际应用中取得更好的效果。

为了更好的顺应行业需求,未来,MegEngine 也将集中发力在提升框架的计算性能、降低大模型计算时需要的显存以及加强分布式计算的能力等方面做优化,以支持大模型的训练和推理。
目前 AIGC 大模型成为 AI 的焦点,各类新技术,新模型不断涌现,后续 MegEngine 团队将一如既往的为社区提供大模型训练和推理的各种基础设施
以上是关于如何使用 MegEngine 生态落地一个算法的主要内容,如果未能解决你的问题,请参考以下文章
MegEngine 使用小技巧:使用 Optimizer 优化参数
MegEngine 使用小技巧:使用 Netron 实现模型可视化