python里怎么计算信息增益,信息增益比,基尼指数
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python里怎么计算信息增益,信息增益比,基尼指数相关的知识,希望对你有一定的参考价值。
参考技术A1、首先自定义一份数据,分别计算信息熵,条件信息熵,从而计算信息增益。

2、然后我们按下图输入命令计算信息熵。
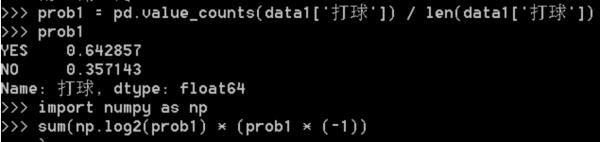
3、再按照下图输入命令计算条件信息熵。
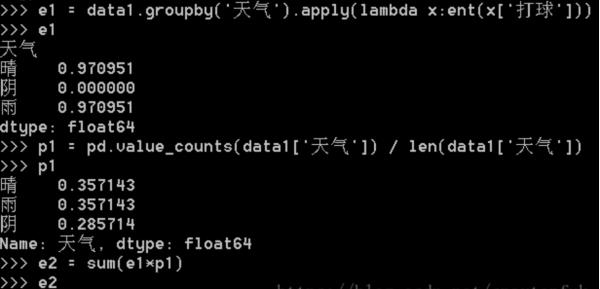
4、再输入下图命令,计算信息增益。

5、输入下列代码计算信息增益比。

6、最后按照下图代码计算出基尼指数。

ID3 和 C4.5:“增益比”如何规范“增益”?
【中文标题】ID3 和 C4.5:“增益比”如何规范“增益”?【英文标题】:ID3 and C4.5: How Does "Gain Ratio" Normalize "Gain"? 【发布时间】:2012-10-24 20:21:58 【问题描述】:ID3 算法使用“信息增益”度量。
C4.5 使用“增益比”度量,即信息增益除以 SplitInfo,而 SplitInfo 对于记录在不同结果之间平均分配的拆分较高,否则较低。
我的问题是:
这如何帮助解决信息增益偏向于具有许多结果的分裂的问题?我看不出原因。 SplitInfo 甚至不考虑结果的数量,只考虑拆分中记录的分布。
很可能是结果数量很少(比如 2 个),并且记录在这 2 个结果之间平均分配。在这种情况下,SplitInfo 较高,增益率较低,C4.5 不太可能选择结果较少的拆分。
另一方面,可能结果数量很少,但分布很不均匀。在这种情况下,SplitInfo 较低,增益率较高,并且更有可能选择具有多种结果的拆分。
我错过了什么?
【问题讨论】:
这个问题可能更适合programmers.stackexchange.com。 @JoachimPileborg 不,这是一个理论问题。但它可能更适合 stats.stackexchange.com。 【参考方案1】:SplitInfo 甚至不考虑结果的数量,只考虑拆分中记录的分布。
但它确实考虑了结果的数量。 (即使它 也 依赖于分布,正如您所指出的)。您的比较是在结果数量相同(“低”)的两种情况之间进行比较,因此它无法说明SplitInfo 如何随着结果数量的变化而变化。
考虑以下 3 种情况,为了便于比较,均采用均匀分布:
均匀分布的 10 种可能结果
SplitInfo = -10*(1/10*log2(1/10)) = 3.32
100 个均匀分布的可能结果
SplitInfo = -100*(1/100*log2(1/100)) = 6.64
1000 种可能的结果,分布均匀
SplitInfo = -1000*(1/1000*log2(1/1000)) = 9.97
因此,如果您必须在 3 种可能的拆分方案之间进行选择,仅使用 ID3 中的Information Gain,则将选择后者。但是,在GainRatio 中使用SplitInfo,应该清楚的是,随着选择数量的增加增加,SplitInfo 也会增加,GainRatio 也会增加向下。
所有这些都是在假设分布均匀的情况下解释的。然而,即使分布不均匀,上述情况仍然适用。 SplitInfo 将随着可能结果的数量增加而变得更高。是的,如果我们保持可能结果的数量不变并改变结果分布,那么SplitInfo 将会有一些差异......但Information Gain 也会有。
【讨论】:
以上是关于python里怎么计算信息增益,信息增益比,基尼指数的主要内容,如果未能解决你的问题,请参考以下文章
决策树(Decision Tree)决策树的构建决策树流程树的生长熵信息增益比基尼系数