常见机器学习算法原理+实践系列4(决策树)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了常见机器学习算法原理+实践系列4(决策树)相关的知识,希望对你有一定的参考价值。
决策树分类
决策树算法借助于树的分支结构实现分类,决策树在选择分裂点的时候,总是选择最好的属性作为分类属性,即让每个分支的记录的类别尽可能纯。常用的属性选择方法有信息增益(Information Gain),增益比例(gain ratio),基尼指数(Gini index)。
- 信息增益
信息增益基于香浓的信息论,它找出的属性R具有这样的特点:以属性R分裂前后的信息增益比其他属性最大。这里信息(实际上就是熵)的定义如下:
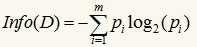
其中的m表示数据集D中类别C的个数,Pi表示D中任意一个记录属于Ci的概率,计算时Pi=(D中属于Ci类的集合的记录个数/|D|)。Info(D)表示将数据集D不同的类分开需要的信息量。
假设我们选择属性R作为分裂属性,数据集D中,R有k个不同的取值{V1,V2,…,Vk},于是可将D根据R的值分成k组{D1,D2,…,Dk},按R进行分裂后,将数据集D不同的类分开还需要的信息量为:
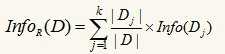
信息增益的定义为分裂前后,两个信息量只差:
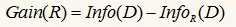
下面使用python来演示一个决策树构造的例子,使用的是信息增益方法:
主要包括如下步骤:
1.计算原始数据集的熵
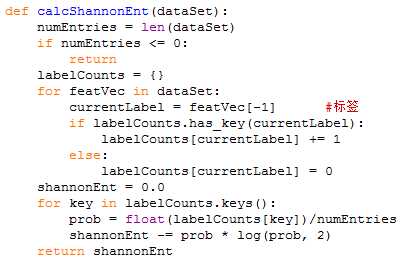
2.计算每个特征的信息增益,挑选一个最大的作为开始的分裂点
1)这里面包含两个步骤,首先是根据每个分裂点,分裂出来的数据子集
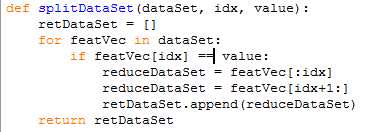
2)然后每个分裂点的信息增益,然后得到最大的分裂点

3)采用递归的方式求出每个分裂子集的树结构
实际上就是求出每个数据集的根节点(变量以及相应的值)。

以上是关于常见机器学习算法原理+实践系列4(决策树)的主要内容,如果未能解决你的问题,请参考以下文章
郑捷《机器学习算法原理与编程实践》学习笔记(第三章 决策树的发展)_Scikit-learn与回归树
Python机器学习(二十)决策树系列三—CART原理与代码实现