工业python项目开放是啥课程
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了工业python项目开放是啥课程相关的知识,希望对你有一定的参考价值。
您好,工业Python项目开发是一门针对Python开发者的课程,旨在教授工业级Python开发的实践技能。这门课程的目标是帮助学员了解如何使用Python开发可靠、高效、可维护的工业级应用程序。课程内容包括Python编程基础、面向对象编程、Python模块和库、Python框架、测试和调试、性能优化、部署和维护等方面的知识。在这门课程中,学员将学习如何使用Python编写高质量的代码,并学会使用Python中的常用工具和框架来开发工业级应用程序。课程还将介绍如何使用Python进行测试和调试,以及如何进行性能优化,以确保应用程序的高效运行。此外,课程还将涵盖如何部署和维护Python应用程序,以确保其长期稳定运行。
总之,工业Python项目开发课程是一门面向Python开发者的实践性课程,旨在帮助学员掌握工业级Python开发的实践技能。通过学习这门课程,学员将能够开发出高质量、可靠、高效的Python应用程序,并能够将其部署和维护在生产环境中。 参考技术A 工业Python项目开放是一门面向工业级应用的Python课程,旨在让学生更好地了解Python在工业级应用中的原理和用法,以及如何使用Python进行工业级开发。课程将介绍Python的语法和基本编程概念,以及如何使用Python脚本来控制硬件设备和生成图形。此外,还将介绍与工业级应用相关的概念,如实时控制,数据采集和处理,机器学习,数据可视化等。本课程将帮助学生更好地掌握Python的基本知识,以及如何使用Python进行工业级应用的开发和部署。 参考技术B 工业python项目开放课程是一种实际应用的python课程,课程内容包括python编程基础、工业级工程应用和工业级系统集成等,旨在帮助大家学习和掌握python在工业领域的应用,提高工程师的编程能力,更好的解决工业实际问题。课程中还包括如控制系统、智能控制、机器视觉、智能机器人等工业级应用技术,旨在融合多种技术,为大家带来更好的工业应用。 参考技术C 工业python项目是一门课程,主要让学生学习如何使用python语言开发应用程序,以及如何将python应用于实际的工业环境中。该课程的重点是使学生掌握python编程语言的基本概念和技术,学会使用python编程语言创建可靠、可维护和可扩展的软件应用程序。在该课程中,学生将学习到如何使用python编程语言开发应用程序,如何将python应用于工业环境中,以及如何结合工业环境中的其他技术来开发可靠的、可维护的和可扩展的应用程序。此外,该课程还让学生学习如何使用python语言与工业环境中的硬件和控制系统集成、如何解决工业环境中常见的问题等等。通过学习这门课程,学生将学会如何使用python编程语言开发可靠、可维护和可扩展的软件应用程序,以及如何将python应用于实际的工业环境中。 参考技术D 工业Python项目开放课程是一个以工业级Python应用为主题,以实践为导向的学习体系,旨在帮助学习者快速掌握Python编程思想,提升工业级Python应用开发能力的课程。该课程主要分为讲解Python基础知识、Python编程基础、Python面向对象编程、工业级Python应用开发实践等4个部分,从理论到实践,为学习者提供了从入门到精通的Python编程学习体系,以及丰富的实践项目,帮助学习者全面提升Python编程技能。
Python工业项目实战:服务器性能监控Prometheus及项目总结
知识点01:课程目标
- 服务器性能监控工具
- 整体作为了解
- 实现部署安装以及监控构建
- 项目总结
- 需求分析、技术架构
- 数仓设计:主题划分、分层设计、维度设计
- 优化、问题、数据量及集群规模
- 简历模板
知识点02:监控需求及常见工具
-
目标:了解服务器性能监控需求及常见监控工具
-
路径
- step1:监控需求
- step2:常见工具
-
实施
-
监控需求
- 问题:数据量越来越大,机器数量越来越多,如何保证所有服务器稳定的的运行,确保所有业务不掉线?
- 资源:CPU、内存、磁盘、网络
- 阈值:80%
- 解决:高效的监控系统可以对运维数据进行分析整理,将运维工作透明化可视化,方便运维人员及时找出问题,保障系统稳定运行,提高运维效率,满足不同业务需求,适用不同服务器场景,也是决定运维成本和效率的重要因素
- 需求
- 覆盖式监控:监控所有机器、所有服务的运行
- 统一监控内容:CPU、内存、磁盘、网络IO
- 分离告警和显示:实时的监控机器负载,程序运行,并针对不同业务实现不同方式的告警和报表
- 问题:数据量越来越大,机器数量越来越多,如何保证所有服务器稳定的的运行,确保所有业务不掉线?
-
常见工具
-
zabbix
基于WEB界面的提供分布式系统监视以及网络监视功能的企业级的开源解决方案 zabbix能监视各种网络参数,保证服务器系统的安全运营 提供灵活的通知机制以让系统管理员快速定位/解决存在的各种问题
-
-
- **Nagios**
```
一款开源的免费网络监视工具,能有效监控Windows、Linux和Unix的状态,交换机路由器等网络设备,打印机等
在系统或服务状态异常时发出邮件或短信报警第一时间通知网站运维人员,在状态恢复后发出正常的邮件或短信通知
```
- **Prometheus**
```
Prometheus是由SoundCloud开发的开源监控报警系统和时序列数据库(TSDB),它启发于 Google 的 borgmon 监控系统,由工作在 SoundCloud 的 google 前员工在 2012 年创建,作为社区开源项目进行开发,并于 2015 年正式发布。
2016 年,Prometheus 正式加入 Cloud Native Computing Foundation,成为受欢迎度仅次于 Kubernetes 的项目。
```
-
小结
- 了解服务器性能监控需求及常见监控工具
知识点03:Prometheus的介绍
-
目标:了解Prometheus的功能和特点
-
路径
- step1:功能
- step2:特点
-
实施
- https://prometheus.io/
-
功能:服务器性能指标监控及时序数据存储
- Prometheus实现了高纬度数据模型,时间序列数据由指标名称和键值对指标组成。
- PromQL允许对收集的时间序列数据进行切片和切块,生成ad-hoc图形、图表、告警
- Prometheus有多种数据可视化模式:内置表达式浏览器,grafana集成、控制台模板语言
- Prometheus使用有效的自定义格式将时间序列数据存储在内存中和本地磁盘,通过函数式分片和联邦进行弹性扩展。
- 每个服务器都是独立的,仅依赖于本地存储。用go语言编写,所有二进制文件都是静态链接,易于部署。
- 告警是基于PromQL灵活定义的,并保留维度信息,告警管理器控制告警信息的通知与否。
-
特点
- 多维度数据模型。
- 灵活的查询语言。
- 不依赖分布式存储,单个服务器节点是自主的。
- 通过基于HTTP的pull方式采集时序数据。
- 可以通过中间网关进行时序列数据推送。
- 通过服务发现或者静态配置来发现目标服务对象。
- 支持多种多样的图表和界面展示,比如Grafana等。
-
小结
- 了解Prometheus的功能和特点
知识点04:Prometheus的架构
-
目标:了解Prometheus的架构
-
实施
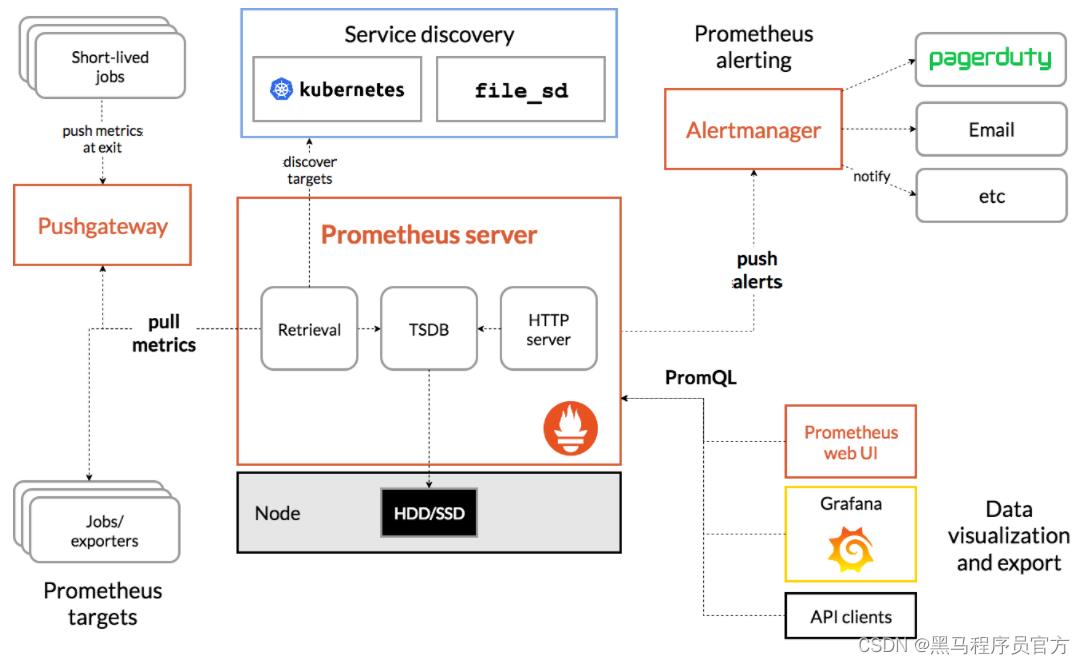
-
Prometheus server:Prometheus主服务器,它会收集并存储时间序列数据
-
Alalert manager:处理告警信息
-
Push gateway:支持短暂任务的推送网关
-
Client libraries:用于检测应用程序代码的客户端库
-
Exporters:特定的导出器服务,例如:HAProxy,StatsD,Graphite等服务。
-
小结
- 了解Prometheus的架构
知识点05:Prometheus的部署
-
目标:实现Prometheus的部署
-
实施
-
上传解压
cd ~ rz # 解压安装包 tar zxvf prometheus-2.26.0.linux-amd64.tar.gz -C /opt # 修改文件名 mv /opt/prometheus-2.26.0.linux-amd64/ /opt/prometheus-2.26 # 进入解压后的安装包 cd /opt/prometheus-2.26 -
验证
./prometheus --version -
查看配置:prometheus.yml
# my global config global: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s). # Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: # - alertmanager:9093 # Load rules once and periodically evaluate them according to the global 'evaluation_interval'. rule_files: # - "first_rules.yml" # - "second_rules.yml" # A scrape configuration containing exactly one endpoint to scrape: # Here it's Prometheus itself. scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'prometheus' # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ['localhost:9090'] -
注册系统服务
vim /etc/systemd/system/prometheus.service[Unit] Description=Prometheus Documentation=Prometheus Monitoring System [Service] ExecStart=/opt/prometheus-2.26/prometheus --config.file=/opt/prometheus-2.26/prometheus.yml Restart=on-failure [Install] WantedBy=multi-user.target -
启动
# 设置开机自启动 systemctl enable prometheus # 启动服务 systemctl start prometheus # 查看服务状态 systemctl status prometheus -
验证:node1:9090
-
-
小结
- 实现Prometheus的部署
知识点06:node_exporter插件
-
目标:实现node_exporter插件的安装监控Linux指标
-
实施
-
上传安装
cd ~ rz tar zxvf node_exporter-1.1.2.linux-amd64.tar.gz -C /opt/prometheus-2.26/ mv /opt/prometheus-2.26/node_exporter-1.1.2.linux-amd64 /opt/prometheus-2.26/node_exporter -
注册
# 创建并编辑文件 vim /etc/systemd/system/node_exporter.service[Unit] Description=node_exporter Documentation=Prometheus node_exporter plugin [Service] ExecStart=/opt/prometheus-2.26/node_exporter/node_exporter Restart=on-failure [Install] WantedBy=multi-user.target -
启动
# 设置开机自启动 systemctl enable node_exporter # 启动服务 systemctl start node_exporter # 查看服务状态 systemctl status node_exporter -
配置Prometheus
vim /opt/prometheus-2.26/prometheus.ymlscrape_configs: - job_name: 'prometheus' static_configs: - targets: ['localhost:9090'] # 增加以下内容 - job_name: 'linux' static_configs: - targets: ['localhost:9100'] labels: instance: node1-
重启prometheus
systemctl restart prometheus.service
-
-
验证:http://node1:9090
-

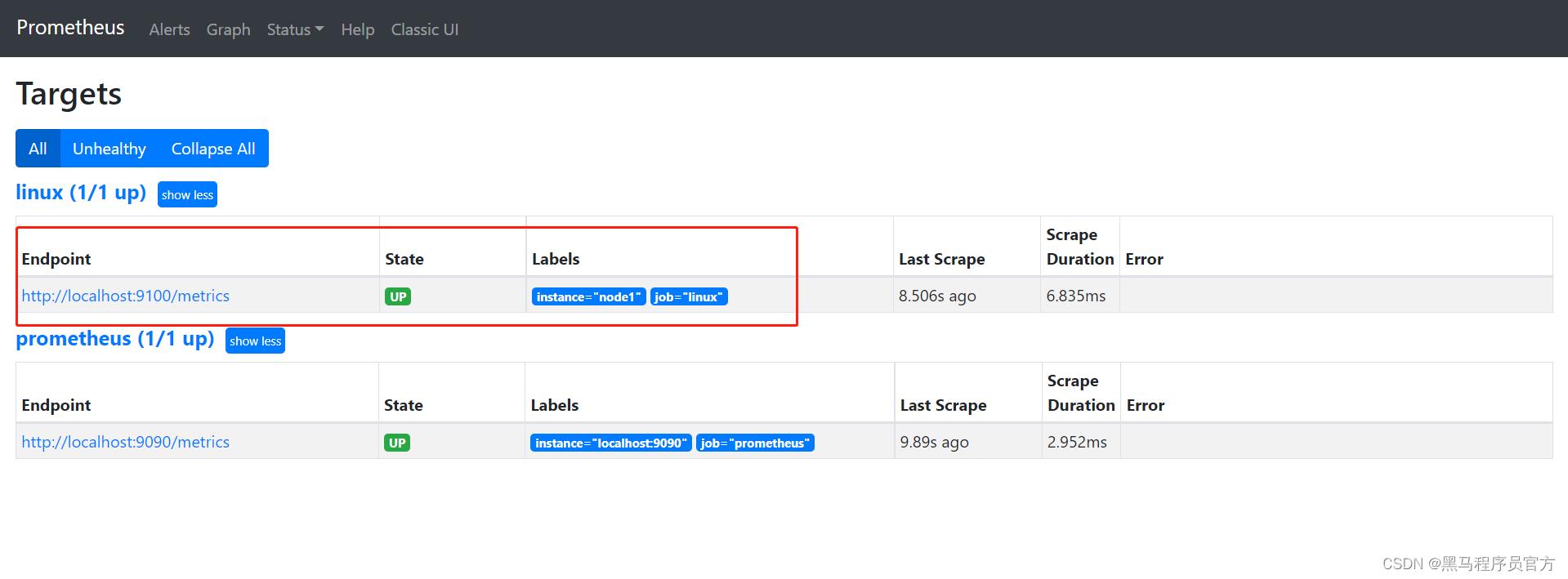
- 查看当前主机的CPU使用情况:node_cpu_seconds_total

- 查看当前主机的CPU负载情况 :node_load15

-
小结
- 实现node_exporter插件的安装监控Linux指标
知识点07:mysqld_exportor插件
-
目标:实现mysqld_exportor插件的安装监控MySQL指标
-
实施
-
上传安装
cd ~ rz tar zxvf mysqld_exporter-0.13.0-rc.0.linux-amd64.tar.gz -C /opt/prometheus-2.26/ mv /opt/prometheus-2.26/mysqld_exporter-0.13.0-rc.0.linux-amd64/ /opt/prometheus-2.26/mysqld_exporter/ -
配置MySQL用户授权
mysql -uroot -p SHOW VARIABLES LIKE 'validate_password%'; set global validate_password_policy=LOW; set global validate_password_length=6; # 授权 GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO 'mysql_exporter'@'localhost' IDENTIFIED BY '123456' WITH MAX_USER_CONNECTIONS 3; flush privileges;- DDL:数据定义语言:建库建表
- DML:数据操作语言:增删改
- DQL:数据查询语言:查询
- DCL:grant、revoke
-
注册服务
vim /etc/systemd/system/mysqld_exporter.service[Unit] Description=mysqld_exporter Documentation=Prometheus mysql exporter plugin [Service] Type=simple User=mysql Environment=DATA_SOURCE_NAME=mysql_exporter:123456@(localhost:3306)/ ExecStart=/opt/prometheus-2.26/mysqld_exporter/mysqld_exporter --config.my-cnf /etc/my.cnf \\ --collect.slave_status \\ --collect.slave_hosts \\ --log.level=error \\ --collect.info_schema.processlist \\ --collect.info_schema.innodb_metrics \\ --collect.info_schema.innodb_tablespaces \\ --collect.info_schema.innodb_cmp \\ --collect.info_schema.innodb_cmpmem Restart=on-failure [Install] WantedBy=multi-user.target -
启动服务
# 设置开机自启动 systemctl enable mysqld_exporter # 启动服务 systemctl start mysqld_exporter # 查看服务状态 systemctl status mysqld_exporter -
配置Prometheus
vim /opt/prometheus-2.26/prometheus.ymlscrape_configs: # 增加以下内容 - job_name: 'mysql' scrape_interval: 1s static_configs: - targets: ['localhost:9104'] labels: instance: 'mysqld_exporter'-
重启prometheus
systemctl restart prometheus.service
-
-
验证
- mysql_exporter_collector_duration_seconds
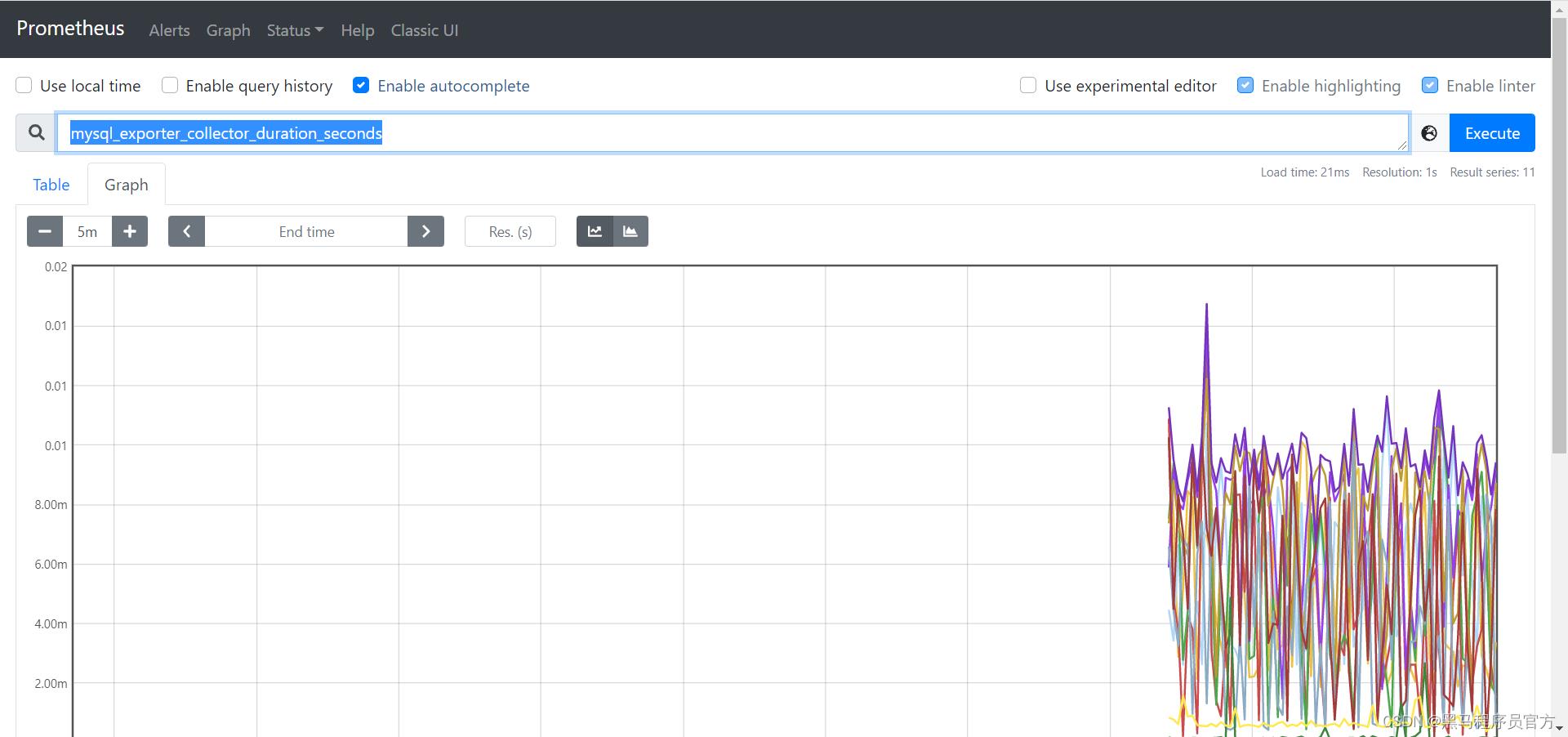
-
-
小结
- 实现mysqld_exportor插件的安装监控MySQL指标
知识点08:可视化工具Grafana介绍
-
目标:了解Grafana的功能及特点
-
路径
- step1:功能
- step2:特点
-
实施
- https://grafana.com/
-
功能:Grafana是一个跨平台的开源的度量分析和可视化工具,可以通过将采集的数据查询然后可视化的展示,并及时通知
-
特点
- 展示方式多样:快速灵活的客户端图表,面板插件有许多不同方式的可视化指标和日志,官方库中具有丰富的仪表盘插件,比如热图、折线图、图表等多种展示方式
- 数据源丰富:Graphite,InfluxDB,OpenTSDB,Prometheus,Elasticsearch,CloudWatch和KairosDB等
- 多种通知提醒:以可视方式定义最重要指标的警报规则,Grafana将不断计算并发送通知,在数据达到阈值时通过Slack、PagerDuty等获得通知
- 混合展示:在同一图表中混合使用不同的数据源,可以基于每个查询指定数据源,甚至自定义数据源
- 注释:使用来自不同数据源的丰富事件注释图表,将鼠标悬停在事件上会显示完整的事件元数据和标记
- 过滤器:Ad-hoc过滤器允许动态创建新的键/值过滤器,这些过滤器会自动应用于使用该数据源的所有查询
-
小结
- 了解Grafana的功能及特点
知识点09:可视化工具Grafana部署
-
目标:实现可视化工具Grafana的部署
-
实施
-
上传安装
cd ~ rz yum install -y grafana-7.5.3-1.x86_64.rpm -
启动服务
# 设置开机自启动 systemctl enable grafana-server # 启动服务 systemctl start grafana-server # 查看服务状态 systemctl status grafana-server -
验证:http://node1:3000/
- 默认用户名密码均为admin
-
- 可以自行修改
- 进入主界面
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-O1XB3p25-1672197296276)(Day1016_服务器性能监控Prometheus及项目总结.assets/image-20211005203525381.png)]
-
小结
- 实现可视化工具Grafana的部署
知识点10:Grafana集成Prometheus
-
目标:实现Grafana集成Prometheus
-
实施
- 添加数据源
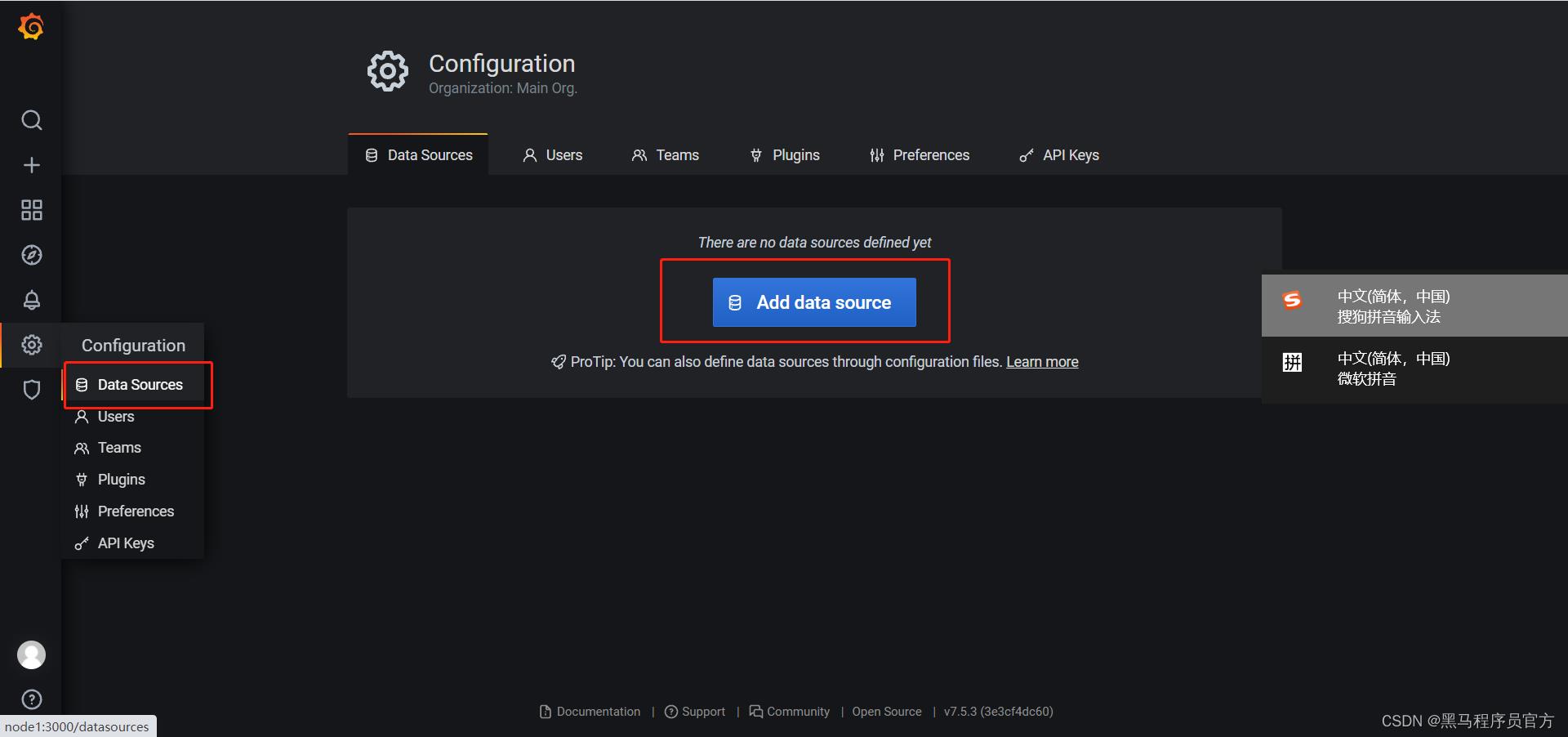

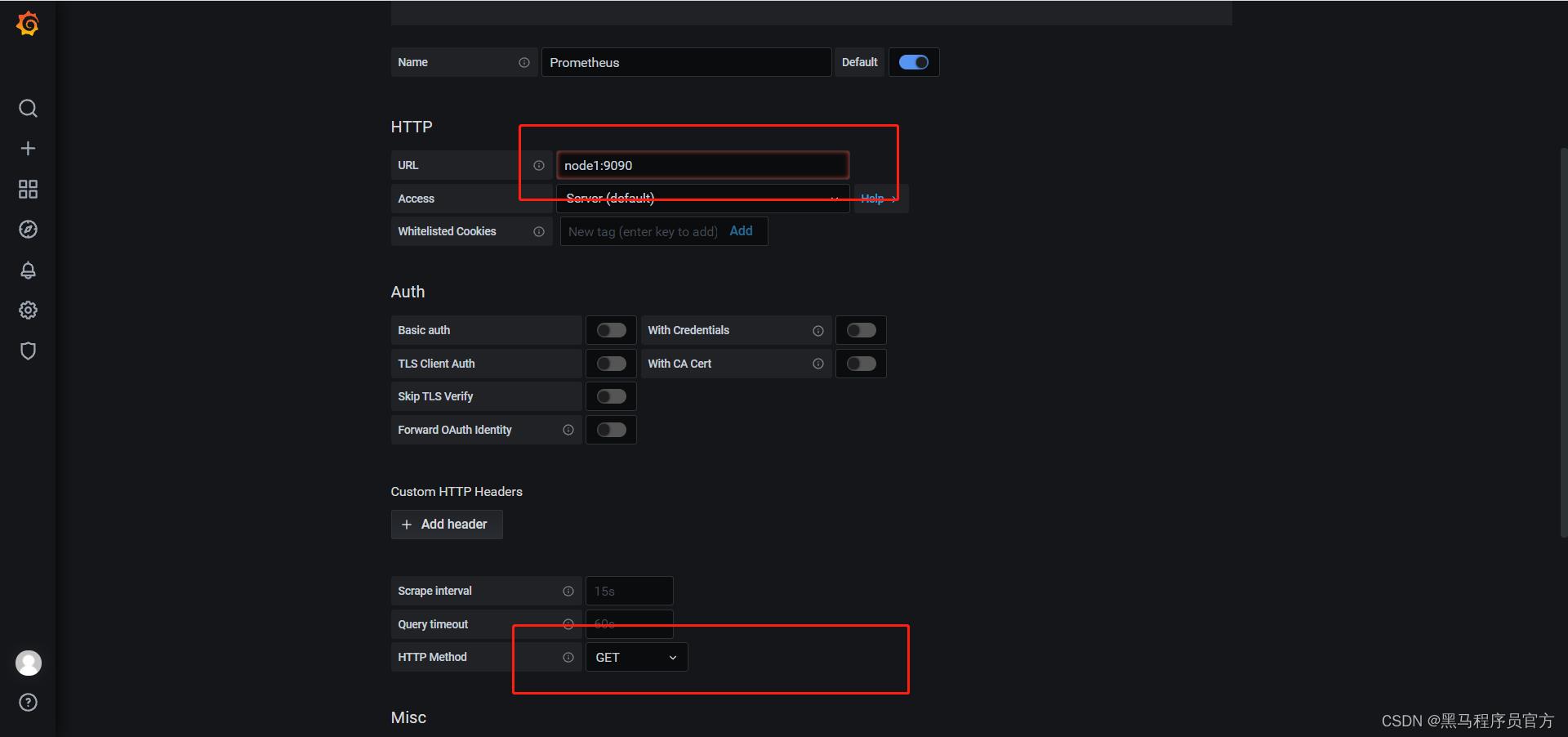
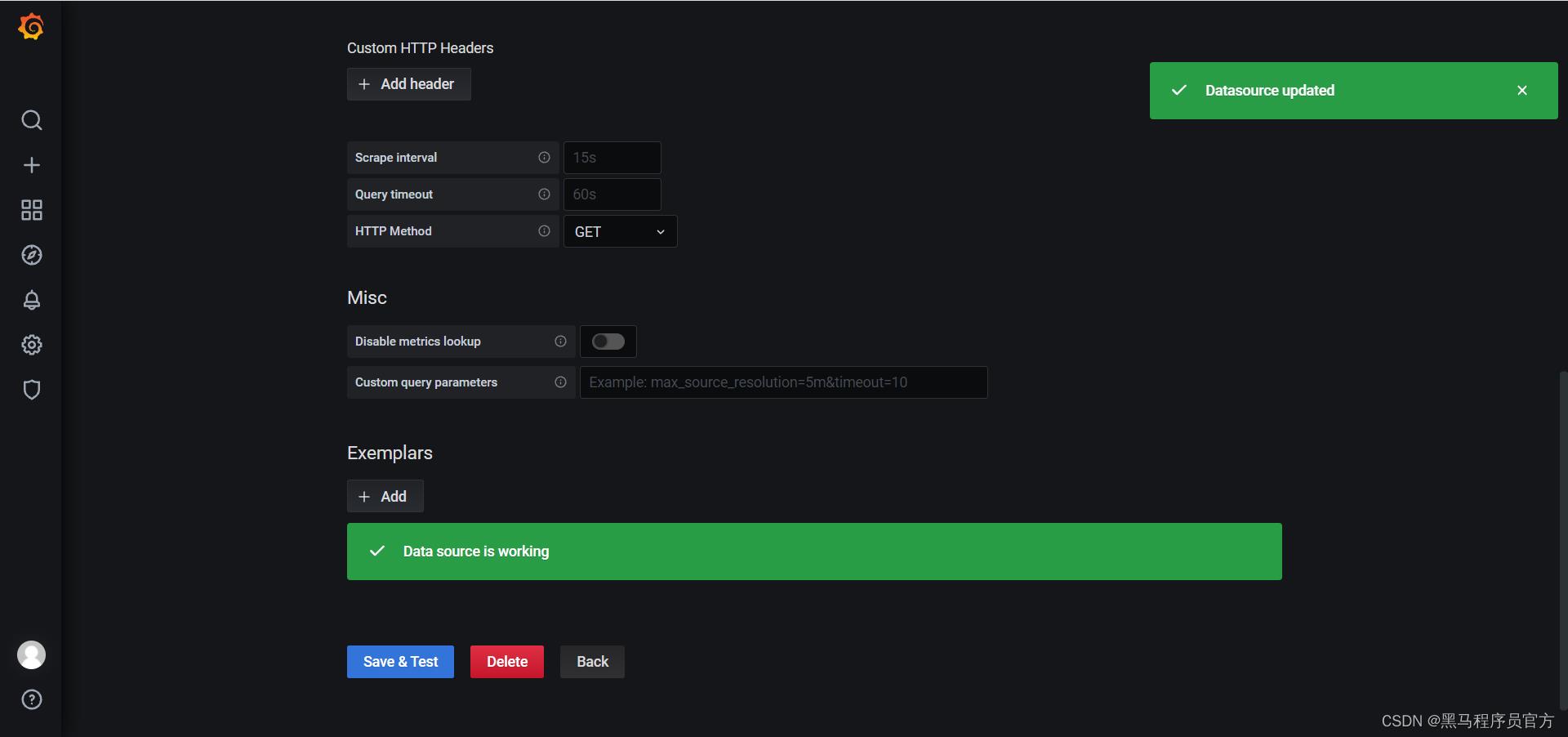
-
选择模板
- https://grafana.com/grafana/dashboards

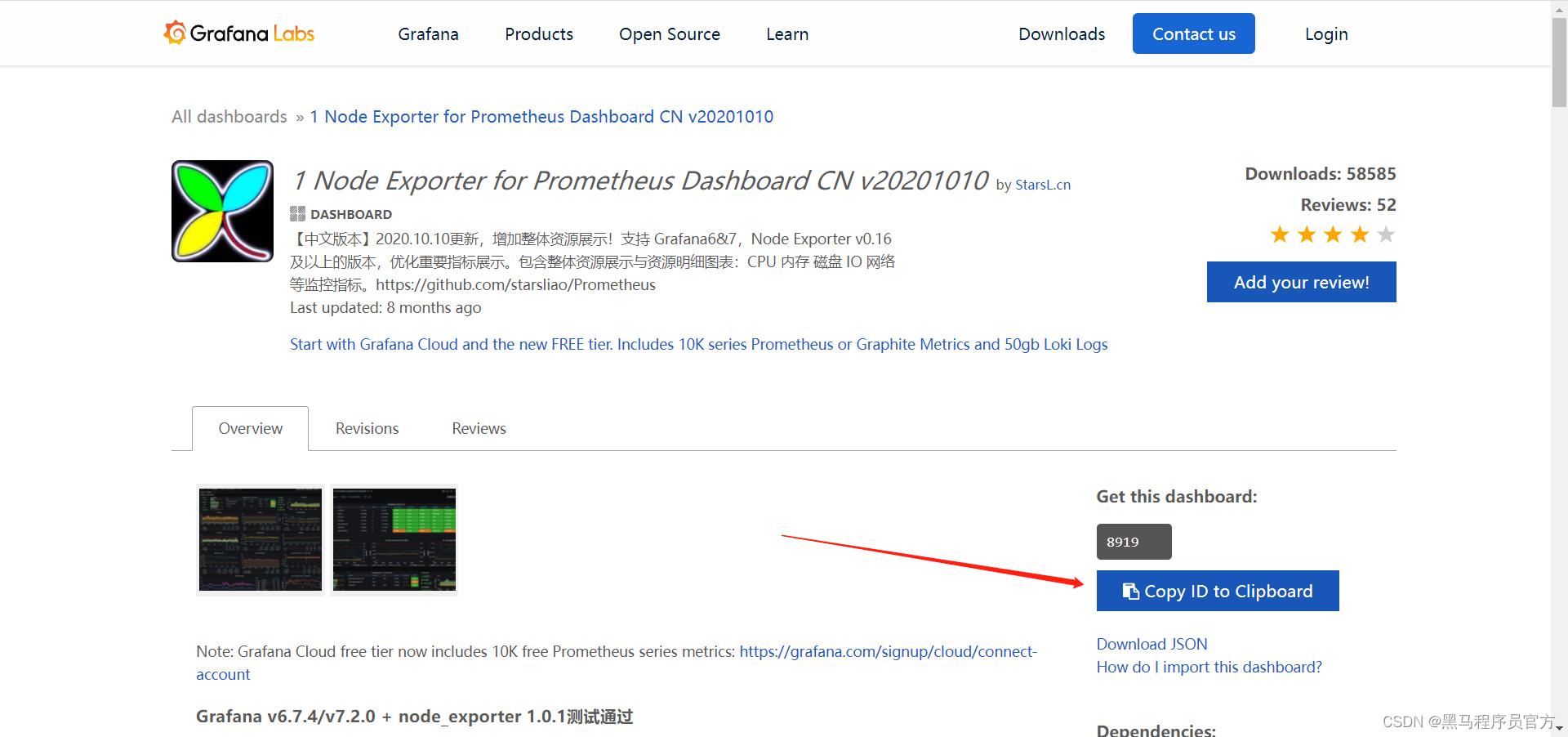
```
8919
```
- 导入报表



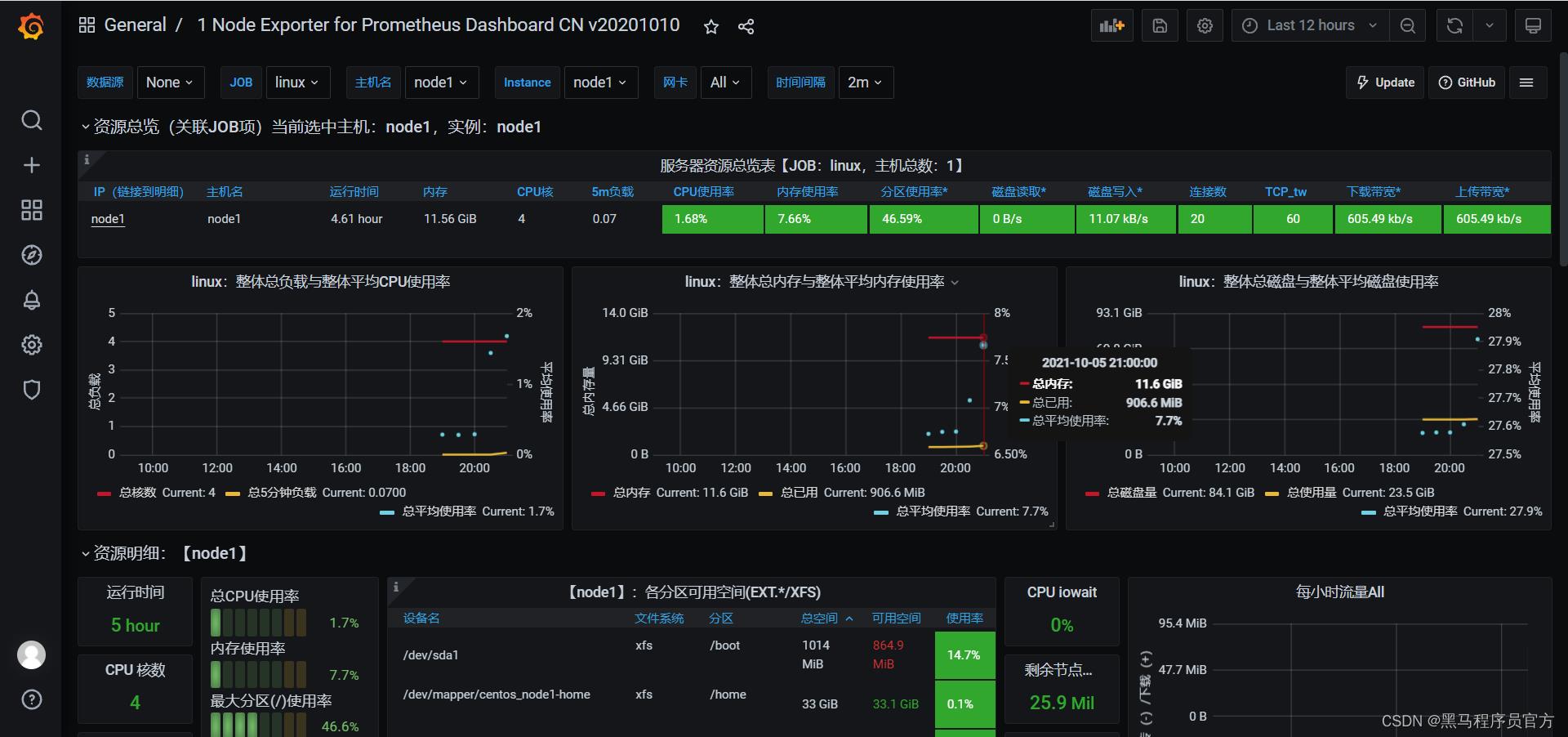
-
小结
- Grafana集成Prometheus
知识点11:Grafana集成MySQL监控
-
目标:实现Grafana集成MySQL监控
-
实施
- 选择模板

```
11323
```
- 导入报表

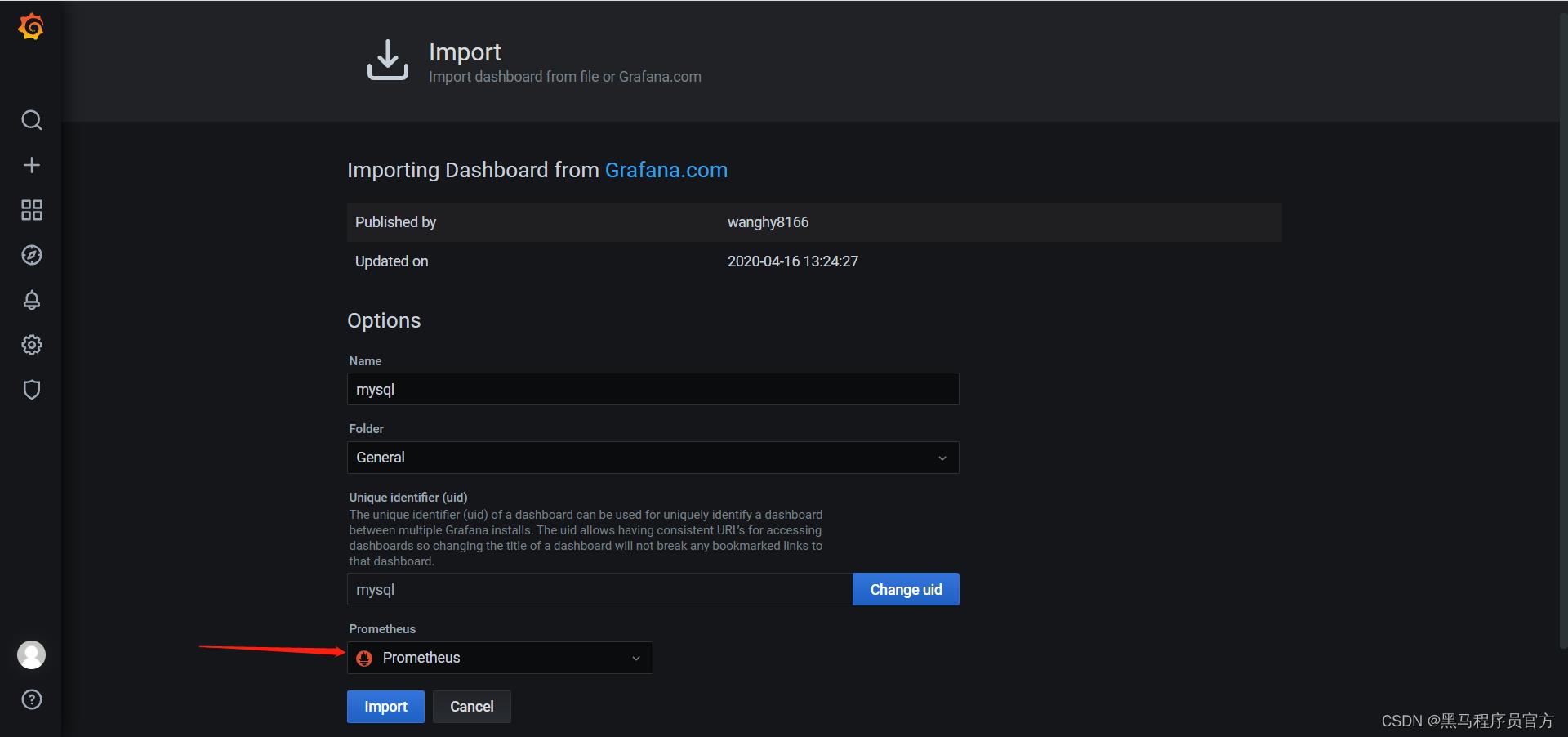
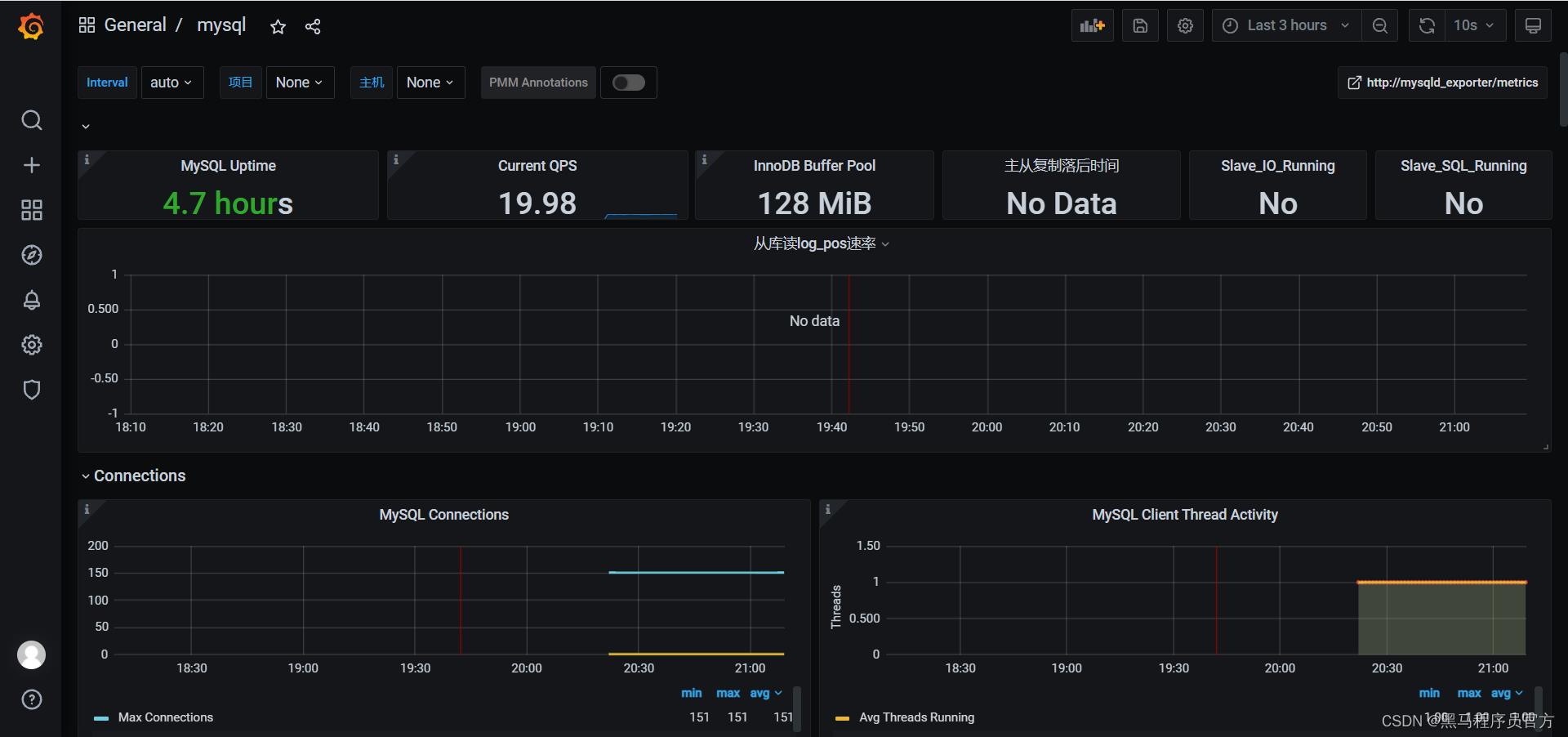
-
小结
- Grafana集成MySQL监控
知识点12:项目总结:背景需求
- 目标:掌握一站制造的项目背景及项目需求
- 路径
- step1:行业背景
- step2:项目需求
- 实施
- 项目行业:工业互联网大数据:物联网
- 项目名称:加油站服务商数据运营管理平台
- 参考别的项目:商业化大数据分析平台:神策
- 公司产品:加油机设备服务
- 公司客户:中石化,中石油,中海油、壳牌,道达尔……
- 整体需求
- 需求一:通过数据分析提高公司产品的服务质量
- 基于加油站的设备安装、维修、巡检、改造等数据进行统计分析
- 支撑加油站站点的设备维护需求以及售后服务的呼叫中心数据分析
- 需求二:通过数据分析支撑公司的成本运营核算
- 保障零部件的仓储物流及供应链的需求
- 实现服务过程中的所有成本运营核算
- 需求三:为未来自动化加油机设备做数据准备
- 获取所有用户和车辆的信息来实现自动化加油的管理
- 需求一:通过数据分析提高公司产品的服务质量
- 具体需求
- 运营分析:呼叫中心服务单数、设备工单数、参与服务工程师个数、零部件消耗与供应指标等
- 设备分析:设备油量监控、设备运行状态监控、安装个数、巡检次数、维修次数、改造次数
- 呼叫中心:呼叫次数、工单总数、派单总数、完工总数、核单次数
- 员工分析:人员个数、接单次数、评价次数、出差次数
- 费用分析:仓库物料管理分析、用户分析
- 小结
- 掌握一站制造的项目背景及项目需求
知识点13:项目总结:数据来源
-
目标:掌握一站制造的项目的业务流程和数据来源
-
路径
- step1:业务流程
- step2:数据来源
-
实施
-
业务流程
- step1:加油站服务商联系呼叫中心,申请服务:安装/巡检/维修/改造加油机
- 呼叫中心会记录这个申请信息:来电受理事务事实表
- step2:呼叫中心联系对应服务站点,分派工单:联系站点主管,站点主管分配服务人员
- 工单信息记录在:服务单信息表、工单信息表
- step3:服务人员确认工单和加油站点信息
- 具体工单信息表:安装单、维修单
- step4:服务人员在指定日期到达加油站,进行设备检修
- step5:如果为安装或者巡检服务,安装或者巡检成功,则服务完成
- step6:如果为维修或者改造服务,需要向服务站点申请物料,物料到达,实施结束,则服务完成
- step7:服务完成,与加油站站点服务商确认服务结束,完成订单核验
- step8:工程师报销过程中产生的费用
- 所有报销费用记录:差旅费用信息表,费用明细表
- step9:呼叫中心会定期对该工单中的工程师的服务做回访
- 回访信息表
- step1:加油站服务商联系呼叫中心,申请服务:安装/巡检/维修/改造加油机
-
数据来源
-
ERP系统:企业资源管理系统,存储整个公司所有资源的信息
- 所有的工程师、物品、设备产品供应链、生产、销售、财务的信息都在ERP系统中
-
CISS系统:客户服务管理系统,存储所有用户、运营数据
- 工单信息、用户信息
-
呼叫中心系统:负责实现所有客户的需求申请、调度、回访等
- 呼叫信息、分配信息、回访信息
-
核心数据表
-
-

- 运营分析
- 工单分析、安装分析、维修分析、巡检分析、改造分析、来电受理分析
- 提高服务质量
- 回访分析
- 运营成本核算
- 收入、支持分析
-
小结
- 掌握一站制造的项目的业务流程和数据来源
知识点14:项目总结:主题划分
-
目标:掌握一站制造的项目的主题划分
-
实施
- 服务域
- 安装主题:安装方式、支付费用、安装类型
- 工单主题:派工方式、工单总数、派工类型、完工总数、
- 维修主题:支付费用、零部件费用、故障类型
- 派单主题:派单数、派单平均值、派单响应时间
- 费用主题:差旅费、安装费、报销人员统计
- 回访主题:回访人员数、回访工单状态
- 油站主题:油站总数量、油站新增数量
- 客户域
- 客户主题:安装数量、维修数量、巡检数量、回访数量
- 仓储域
- 保内良品核销主题:核销数量、配件金额
- 保内不良品核销主题:核销配件数、核销配件金额
- 送修主题:送修申请、送修物料数量、送修类型
- 调拨主题:调拨状态、调拨数量、调拨设备类型
- 消耗品核销:核销总数、核销设备类型
- 服务商域
- 工单主题:派工方式、工单总数、工单类型、客户类型
- 服务商油站主题:油站数量、油站新增数量
- 运营域
- 运营主题:服务人员工时、维修站分析、平均工单、网点分布
- 市场域
- 市场主题:工单统计、完工明细、订单统计
- 服务域
-
小结
- 掌握一站制造的项目的主题划分
知识点15:项目总结:技术架构
-
目标:掌握一站制造的项目的技术架构
-
实施
-
数据生成:业务数据库系统
- Oracle:工单数据、物料数据、服务商数据、报销数据等
-
数据采集
- Sqoop:离线数据库采集
- Sqoop怎么采集Oracle数据
- Sqoop:离线数据库采集
-
数据存储
- Hive【HDFS】:离线数据仓库【表】
-
数据计算
- SparkSQL:类HiveSQL开发方式:对数据仓库中的结构化数据做处理分析
- Python | Java :SparkSQLDSL开发:使用spark-submit来提交运行
- SparkSQL SQL + ThriftServer:提交SQL开发
- SparkSQL:类HiveSQL开发方式:对数据仓库中的结构化数据做处理分析
-
数据应用
- MySQL:结果存储
- FineBI / Tableau:可视化工具
-
监控工具
- Prometheus:服务器性能指标监控工具
- Grafana:监控可视化工具
-
调度工具
- AirFlow:任务流调度工具
-
技术架构
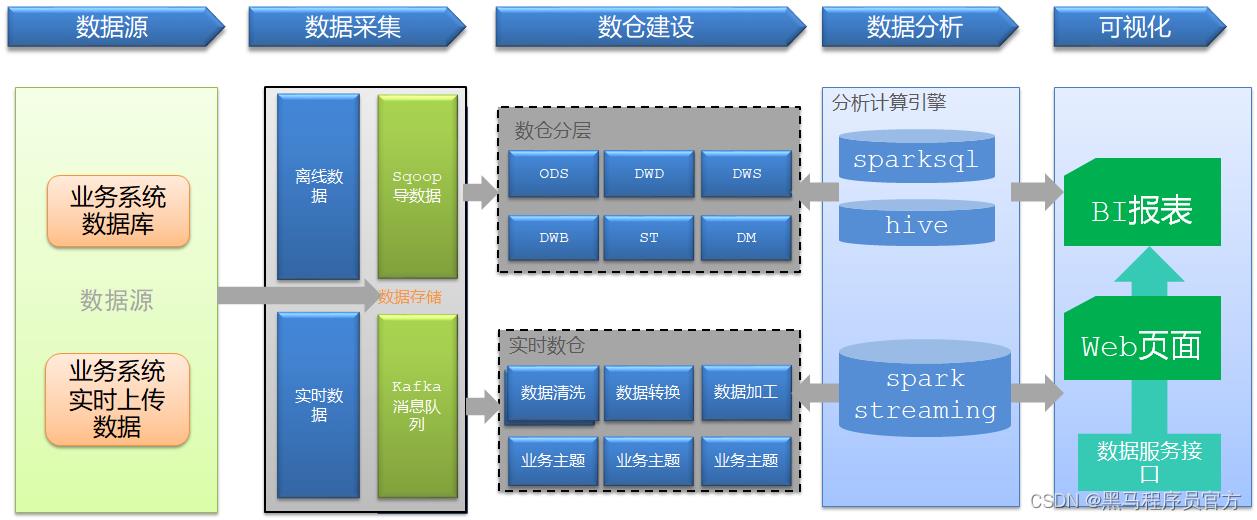
-
-
小结
- 掌握一站制造的项目的技术架构
知识点16:项目总结:数仓设计
-
目标:掌握一站制造的项目的分层设计与建模设计
-
路径
- step1:分层设计
- step2:建模设计
-
实施
- 分层设计
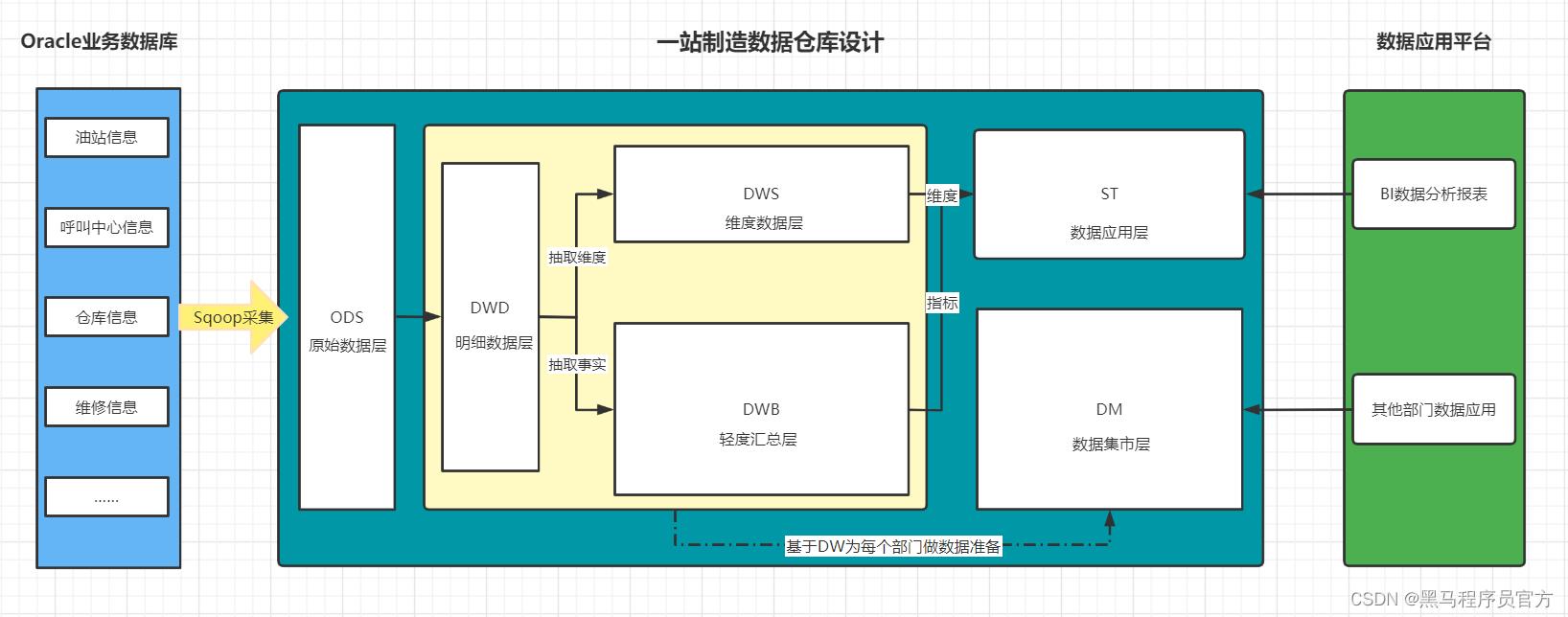
- **ODS**:原始数据层:最接近于原始数据的层次,直接采集写入层次:**原始事务事实表**
- 数据内容:存储所有原始业务数据,基本与Oracle数据库中的业务数据保持一致
- 数据来源:使用Sqoop从Oracle中同步采集
- 存储设计:Hive分区表,avro文件格式存储,保留3个月
- **DWD**:明细数据层:对ODS层的数据根据业务需求实现ETL以后的结果:ETL以后事务事实表
- 数据内容:存储所有业务数据的明细数据
- 数据来源:对ODS层的数据进行ETL扁平化处理得到
- 存储设计:Hive分区表,orc文件格式存储,保留所有数据
- **DWB**:基础数据层:类似于以前讲解的DWM,轻度聚合
- 关联:将主题事实的表进行关联,所有与这个主题相关的字段合并到一张表
- 聚合:基于主题的事务事实构建基础指标
- **主题事务事实表**
- 数据内容:存储所有事实与维度的基本关联、基本事实指标等数据
- 数据来源:对DWD层的数据进行清洗过滤、轻度聚合以后的数据
- 存储设计:Hive分区表,orc文件格式存储,保留所有数据
- **ST**:数据应用层:类似于以前讲解的APP,存储每个主题基于维度分析聚合的结果:**周期快照事实表**
- 供数据分析的报表
- 数据内容:存储所有报表分析的事实数据
- 数据来源:基于DWB和DWS层,通过对不同维度的统计聚合得到所有报表事实的指标
- **DM**:数据集市:按照不同部门的数据需求,将暂时没有实际主题需求的数据存储
- 做部门数据归档,方便以后新的业务需求的迭代开发
- 数据内容:存储不同部门所需要的不同主题的数据
- 数据来源:对DW层的数据进行聚合统计按照不同部门划分
- **DWS**:维度数据层:类似于以前讲解的DIM:存储**维度数据表**
- 数据内容:存储所有业务的维度数据:日期、地区、油站、呼叫中心、仓库等维度表
- 数据来源:对DWD的明细数据中抽取维度数据
- 存储设计:Hive普通表,orc文件 + Snappy压缩
- 特点:数量小、很少发生变化、全量采集
- 数据仓库设计方案
- 从上到下:在线教育:先明确需求和主题,然后基于主题的需求采集数据,处理数据
- 场景:数据应用比较少,需求比较简单
- **从下到上**:一站制造:将整个公司所有数据统一化在数据仓库中存储准备,根据以后的需求,动态直接获取数据
- 场景:数据应用比较多,业务比较复杂
-
建模设计
-
建模方法:维度建模
-
维度设计:星型模型
-
常用维度
- 日期时间维度
- 年维度、季度维度、月维度、周维度、日维度
- 日环比、周环比、月环比、日同比、周同比、月同比
- 环比:同一个周期内的比较
- 同比:上个个周期的比较
- 行政地区维度
- 地区级别:国家维度、省份维度、城市维度、县区维度、乡镇维度
- 服务网点维度
- 网点名称、网点编号、省份、城市、县区、所属机构
- 油站维度
- 油站类型、油站名称、油站编号、客户编号、客户名称、省份、城市、县区、油站状态、所属公司
- 组织机构维度
- 人员编号、人员名称、岗位编号、岗位名称、部门编号、部门名称
- 服务类型维度
- 类型编号、类型名称
- 设备维度
- 设备类型、设备编号、设备名称、油枪数量、泵类型、软件类型
- 故障类型维度
- 一级故障编号、一级故障名称、二级故障编号、二级故障名称
- 物流公司维度
- 物流公司编号、物流公司名称
- 日期时间维度
-
主题维度矩阵
-

-
小结
- 掌握一站制造的项目的分层设计与建模设计
知识点17:项目总结:优化及新特性
-
目标:掌握一站制造项目中的优化方案
-
实施
-
优化:参考FTP中:《就业面试》中的优化文档
-
资源优化:开启属性分配更多的资源,内存合理分配
-
开发优化:谓词下推:尽量将不需要的数据提前过滤掉【join】
- 尽量选用有Map端聚合的算子:先分区内聚合,再分区间聚合
- 尽量将不需要join的数据过滤,或者实现Broadcast Join
-
结构优化:文件存储类型、分区结构化
-
分区表:静态分区裁剪
select count(*) from table1 where daystr = '2021-10-15'; --走分区裁剪过滤查询--spark2中先join后过滤 select * from table1 join table2 on table1.id = table2.id and table1.daystr = '2021-10-15' and table2.daystr='2021-10-15';
-
-
-
新特性:Spark3.0
-
动态分区裁剪(Dynamic Partition Pruning)
-
默认的分区裁剪只有在单表查询过滤时才有效
-
开启动态分区裁剪:自动在Join时对两边表的数据根据条件进行查询过滤,将过滤后的结果再进行join
spark.sql.optimizer.dynamicPartitionPruning.enabled=true
-
-
自适应查询执行(Adaptive Query Execution)
-
基于CBO优化器引擎:实现最小代价的数据处理
-
自动根据统计信息设置Reducer【ShuffleRead】的数量来避免内存和I/O资源的浪费
-
自动选择更优的join策略来提高连接查询性能
-
自动优化join数据来避免不平衡查询造成的数据倾斜,将数据倾斜的数据自动重分区
spark.sql.adaptive.enabled=true
-
-
加速器感知调度(Accelerator-aware Scheduling)
- 添加原生的 GPU 调度支持,该方案填补了 Spark 在 GPU 资源的任务调度方面的空白
- 有机地融合了大数据处理和 AI 应用,扩展了 Spark 在深度学习、信号处理和各大数据应用的应用场景
-
-
-
小结
- 掌握一站制造项目中的优化方案
知识点18:项目总结:问题
-
目标:掌握一站制造的项目中遇到的问题及解决方案
-
实施
-
问题1:数据采集不一致问题
- 现象:Hive表中的记录数与Oracle中的记录数不一致
- 原因:Oracle的数据字段中包含了特殊字段,Sqoop采集时,以特殊字符作为换行符生成普通文本
- 解决
- 方案一:替换或者删除特殊字段【不影响数据业务】
- 方案二:更换Avro格式
-
问题2:数据倾斜问题
- 重分区:将数据重新分配到更多的分区中
- 自定义分区方式:默认Hash分区【reduceByKey】、Range分区【sortBy】
- 先过滤再join,或者用广播join
-
问题3:小文件问题
- 每个Task会产生一个结果文件
- Task个数根据分区个数来决定
- 分区多,每个分区的数据少
- 调整分区个数:repartion
-
问题4:ThriftServer资源不足,GC问题
start-thriftserver.sh \\ --name sparksql-thrift-server \\ --master yarn \\ --deploy-mode client \\ --driver-memory 1g \\ --hiveconf hive.server2.thrift.http.port=10001 \\ --num-executors 3 \\ --executor-memory 1g \\ --conf spark.sql.shuffle.partitions=2- 本质:Spark程序运行YARN上
- 进程:Driver + Executor
- 问题:这个程序的资源如果给的少了,会导致GC【内存垃圾回收】停顿以及内存溢出
- Driver进程故障,程序运行缓慢,内存溢出
- 解决
- Driver资源要给定多一些:Driver持久运行,不断解析调度分配,负责与客户端交互
- –driver-core:4core
- –driver-mem:12GB
- Executor的个数给定的多一些
- Driver资源要给定多一些:Driver持久运行,不断解析调度分配,负责与客户端交互
-
问题5:ThriftServer单点故障问题
- 类似于HiveServer2的单点故障问题
- 解决:HA高可用结构,构建两个ThriftServer
- 方案一:两台机器分别启动两个ThriftServer
- 问题:beeline只能连接某一个,连接谁?如果随便选一个,这个如果故障了怎么办呢?
- 解决:HAproxy工具,运维配置
- 方案二:利用ZK来实现辅助选举,一个Active,一个Standby
- 原生的HiveServer2可以直接修改配置来实现
- 修改源码
- 方案一:两台机器分别启动两个ThriftServer
-
-
小结
- 掌握一站制造的项目中遇到的问题及解决方案
知识点19:项目总结:数据规模
- 目标:掌握一站制造项目中的数据规模
- 实施
- 每天数据增量是多少?
- 项目中总数据表的个数:300多张表
- 核心业务的事务事实表:100张表
- 每张核心事务事实增量:17万条/天
- 每条数据量的平均大小:1KB
- 每天的总数据增量范围:16GB
- 集群大概有多少台机器?
- 每台机器存储容量:20TB
- 每台机器可用比例:80%
- 每台机器可用容量:16TB
- 整体数据存储五年:16 * 3 * 365 * 5 = 6 台DataNode/NodeManager
- 项目团队规模?
- 以12人举例:项目经理:1,产品经理:1,离线:5人,web系统:2人,测试:2人,运维:1人
- 每天数据增量是多少?
- 小结
- 掌握一站制造项目中的数据规模
知识点20:项目总结:简历模板
项目名称:一站制造大数据项目(2021年1月-2021年9月)
项目架构:
spark2.4+hive2.1+hadoop2.7+sqoop1.4+oracle11g+mysql5.7+airflow2.0
项目简介:
一站制造项目基于工业互联网行业,为解决基于传统数据存储架构无法解决的问题而开发的大数据项目。在石油制造行业存在大量运营、仓储物料数据,通过大数据技术架构解决这种复制业务情况下的数据存储和分析以及数据可视化问题。主要基于hive数据分层构建存储各个业务指标数据,基于sparksql做数据分析。核心业务涉及运营商、呼叫中心、工单、油站、仓储物料等业务。
个人职责:
1.负责将存储在关系型数据库中的业务系统数据导入hdfs上。
2.根据原始数据表,批量创建hive表,设置分区、存储格式。
3.根据业务关联关系以及分析指标,建立数仓模型。
4.实现数据模型中的各个数仓分层的数据建模,建表。
5.负责实现每个分层的数据抽取、转换、加载。
6.负责编写shell实现sqoop脚本批量导入数据。
7.负责编排sqoop导入数据的任务调度。
8.负责使用sparksql进行数据应用层指标进行分析。
- 工业大数据的应用:https://zhuanlan.zhihu.com/p/166300187
- 石油能源行业公司:https://top.chinaz.com/hangye/index_qiye_shihua.html
- 商业数据分析平台:友盟,talkingdata,神策
个数:300多张表
- 核心业务的事务事实表:100张表
- 每张核心事务事实增量:17万条/天
- 每条数据量的平均大小:1KB
- 每天的总数据增量范围:16GB
- 集群大概有多少台机器?
- 每台机器存储容量:20TB
- 每台机器可用比例:80%
- 每台机器可用容量:16TB
- 整体数据存储五年:16 * 3 * 365 * 5 = 6 台DataNode/NodeManager
- 项目团队规模?
- 以12人举例:项目经理:1,产品经理:1,离线:5人,web系统:2人,测试:2人,运维:1人
- 小结
- 掌握一站制造项目中的数据规模
知识点20:项目总结:简历模板
项目名称:一站制造大数据项目(2021年1月-2021年9月)
项目架构:
spark2.4+hive2.1+hadoop2.7+sqoop1.4+oracle11g+mysql5.7+airflow2.0
项目简介:
一站制造项目基于工业互联网行业,为解决基于传统数据存储架构无法解决的问题而开发的大数据项目。在石油制造行业存在大量运营、仓储物料数据,通过大数据技术架构解决这种复制业务情况下的数据存储和分析以及数据可视化问题。主要基于hive数据分层构建存储各个业务指标数据,基于sparksql做数据分析。核心业务涉及运营商、呼叫中心、工单、油站、仓储物料等业务。
个人职责:
1.负责将存储在关系型数据库中的业务系统数据导入hdfs上。
2.根据原始数据表,批量创建hive表,设置分区、存储格式。
3.根据业务关联关系以及分析指标,建立数仓模型。
4.实现数据模型中的各个数仓分层的数据建模,建表。
5.负责实现每个分层的数据抽取、转换、加载。
6.负责编写shell实现sqoop脚本批量导入数据。
7.负责编排sqoop导入数据的任务调度。
8.负责使用sparksql进行数据应用层指标进行分析。
- 工业大数据的应用:https://zhuanlan.zhihu.com/p/166300187
- 石油能源行业公司:https://top.chinaz.com/hangye/index_qiye_shihua.html
- 商业数据分析平台:友盟,talkingdata,神策
以上是关于工业python项目开放是啥课程的主要内容,如果未能解决你的问题,请参考以下文章