Python工业项目实战03:ODS层及DWD层构建
Posted 黑马程序员官方
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python工业项目实战03:ODS层及DWD层构建相关的知识,希望对你有一定的参考价值。
知识点01:课程回顾
-
一站制造项目的数仓设计为几层以及每一层的功能是什么?
- ODS:原始数据层:存放从Oracle中同步采集的所有原始数据
- DW:数据仓库层
- DWD:明细数据层:存储ODS层进行ETL以后的数据
- DWB:轻度汇总层:对DWD层的数据进行轻度聚合:关联和聚合
- 基于每个主题构建主题事务事实表
- DWS:维度数据层:对DWD层的数据进行维度抽取
- 基于每个主题的维度需求抽取所有维度表
- ST:数据应用层
- 基于DWB和DWS的结果进行维度的聚合
- DM:数据集市层
- 用于归档存储公司所有部门需要的shuju
-
一站制造项目的数据来源是什么,核心的数据表有哪些?
- 数据来源:业务系统
- ERP:公司资产管理系统、财务数据
- 工程师信息、零部件仓储信息
- CISS:客户服务管理系统
- 工单信息、站点信息、客户信息
- 呼叫中心系统
- 来电受理信息、回访信息
-
一站制造项目中在数据采集时遇到了什么问题,以及如何解决这个问题?
- 技术选型:Sqoop
- 问题:发现采集以后生成在HDFS上文件的行数与实际Oracle表中的数据行数不一样,多了
- 原因:Sqoop默认将数据写入HDFS以普通文本格式存储,一旦遇到数据中如果包含了特殊字符\\n,将一行的数据解析为多行
- 解决
- 方案一:Sqoop删除特殊字段、替换特殊字符【一般不用】
- 方案二:更换其他数据文件存储类型:AVRO
- 数据存储:Hive
- 数据计算:SparkSQL
-
什么是Avro格式,有什么特点?
- 二进制文本:读写性能更快
- 独立的Schema:生成文件每一行所有列的信息
- 对列的扩展非常友好
- Spark与Hive都支持的类型
-
如何实现对多张表自动采集到HDFS?
-
需求
- 读取表名
- 执行Sqoop命令
-
效果:将所有增量和全量表的数据采集到HDFS上
-
全量表路径:维度表:数据量、很少发生变化
/data/dw/ods/one_make/ full_imp /表名/分区/数据 -
增量表路径:事实表:数据量不断新增,整体相对较大
/data/dw/ods/one_make/ incr_imp /表名/分区/数据 -
Schema文件的存储目录
/data/dw/ods/one_make/avsc
-
-
Shell:业务简单,Linux命令支持
-
Python:业务复杂,是否Python开发接口
- 调用了LinuxShell来运行
-
-
Python面向对象的基本应用
-
语法
-
定义类
class 类名: # 属性:变量 # 方法:函数 -
定义变量
key = value -
定义方法
def funName(参数): 方法逻辑 return
-
-
面向对象:将所有事物以对象的形式进行编程,万物皆对象
- 对象:是类的实例
-
对象类:专门用于构造对象的,一般称为Bean,代表某一种实体Entity
-
类的组成
class 类名: # 属性:变量 # 方法:函数 -
业务:实现人购买商品
-
人
class Person: # 属性 id = 1 name = zhangsan age = 18 gender = 1 …… # 方法 def eat(self,something): print(f"self.name eating something") def buy(self,something) print(f"self.name buy something")- 每个人都是一个Person类的对象
-
商品
class Product: # 属性 id = 001 price = 1000.00 size = middle color = blue …… # 方法 def changePrice(self,newPrice): self.price = newPirce
-
-
-
工具类:专门用于封装一些工具方法的,utils,代表某种操作的集合
-
类的组成:一般只有方法
class 类名: # 方法:函数 -
字符串处理工具类:拼接、裁剪、反转、长度、转大写、转小写、替换、查找
class StringUtils: def concat(split,args*): split.join(args) def reverse(sourceString) return reverse(sourceString) …… -
日期处理工具类:计算、转换
class TimeUitls: def computeTime(time1,time2): return time1-time2 def transTimestamp(timestamp): return newDateyyyy-MM-dd HH:mm:ss) def tranfData(date) return timestamp
-
-
常量类:专门用于定义一些不会发生改变的变量的类
-
类的组成:一般只有属性
class 类名: # 属性:不发生变化的属性 -
定义一个常量类
class Common: ODS_DB_NAME = "one_make_ods" ……-
file1.py:创建数据库
create database if not exists Common.ODS_DB_NAME; -
file2.py:创建表
create table if not exists Common.ODS_DB_NAME.tbname -
file3.py:插入数据到表中
insert into table Common.ODS_DB_NAME.tbname -
问题1:容易写错
-
问题2:不好修改
-
-
-
知识点02:课程目标
- 目标:自动化的ODS层与DWD层构建
- 实现
- 掌握Hive以及Spark中建表的语法规则
- 实现项目开发环境的构建
- 自己要实现所有代码注释
- ODS层与DWD层整体运行测试成功
知识点03:数仓分层回顾
-
目标:回顾一站制造项目分层设计
-
实施

-
ODS层 :原始数据层
-
来自于Oracle中数据的采集
-
数据存储格式:AVRO
-
ODS区分全量和增量
-
实现
-
数据已经采集完成
/data/dw/ods/one_make/full_imp /data/dw/ods/one_make/incr_imp -
step1:创建ODS层数据库:one_make_ods
-
step2:根据表在HDFS上的数据目录来创建分区表
-
step3:申明分区
-
-
-
DWD层
- 来自于ODS层数据
- 数据存储格式:ORC
- 不区分全量和增量的
- 实现
- step1:创建DWD层数据库:one_make_dwd
- step2:创建DWD层的每一张表
- step3:从ODS层抽取每一张表的数据写入DWD层对应的表中
-
小结
- 回顾一站制造项目分层设计
知识点04:Hive建表语法
-
目标:掌握Hive建表语法
-
实施
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name ( col1Name col1Type [COMMENT col_comment], co21Name col2Type [COMMENT col_comment], co31Name col3Type [COMMENT col_comment], co41Name col4Type [COMMENT col_comment], co51Name col5Type [COMMENT col_comment], …… coN1Name colNType [COMMENT col_comment] ) [PARTITIONED BY (col_name data_type ...)] [CLUSTERED BY (col_name...) [SORTED BY (col_name ...)] INTO N BUCKETS] [ROW FORMAT row_format] row format delimited fields terminated by lines terminated by [STORED AS file_format] [LOCATION hdfs_path] TBLPROPERTIES- EXTERNAL:外部表类型
- 内部表、外部表、临时表
- PARTITIONED BY:分区表结构
- 普通表、分区表、分桶表
- CLUSTERED BY:分桶表结构
- ROW FORMAT:指定分隔符
- 列的分隔符:\\001
- 行的分隔符:\\n
- STORED AS:指定文件存储类型
- ODS:avro
- DWD:orc
- LOCATION:指定表对应的HDFS上的地址
- 默认:/user/hive/warehouse/dbdir/tbdir
- TBLPROPERTIES:指定一些表的额外的一些特殊配置属性
- EXTERNAL:外部表类型
-
小结
- 掌握Hive建表语法
知识点05:Avro建表语法
-
目标:掌握Hive中Avro建表方式及语法
-
路径
- step1:指定文件类型
- step2:指定Schema
- step3:建表方式
-
实施
-
Hive官网:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-CreateTable
-
DataBrics官网:https://docs.databricks.com/spark/2.x/spark-sql/language-manual/create-table.html
-
Avro用法:https://cwiki.apache.org/confluence/display/Hive/AvroSerDe
-
指定文件类型
-
方式一:指定类型
stored as avro -
方式二:指定解析类
--解析表的文件的时候,用哪个类来解析 ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.avro.AvroSerDe' --读取这张表的数据用哪个类来读取 STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat' --写入这张表的数据用哪个类来写入
OUTPUTFORMAT
‘org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat’ -
-
指定Schema
-
方式一:手动定义Schema
CREATE TABLE embedded COMMENT "这是表的注释" ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.avro.AvroSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat' TBLPROPERTIES ( 'avro.schema.literal'=' "namespace": "com.howdy", "name": "some_schema", "type": "record", "fields": [ "name":"string1","type":"string"] ' ); -
方式二:加载Schema文件
CREATE TABLE embedded COMMENT "这是表的注释" ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.avro.AvroSerDe' STORED as INPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat' TBLPROPERTIES ( 'avro.schema.url'='file:///path/to/the/schema/embedded.avsc' );
-
-
建表语法
-
方式一:指定类型和加载Schema文件
create external table one_make_ods_test.ciss_base_areas comment '行政地理区域表' PARTITIONED BY (dt string) stored as avro location '/data/dw/ods/one_make/full_imp/ciss4.ciss_base_areas' TBLPROPERTIES ('avro.schema.url'='/data/dw/ods/one_make/avsc/CISS4_CISS_BASE_AREAS.avsc'); -
方式二:指定解析类和加载Schema文件
create external table one_make_ods_test.ciss_base_areas comment '行政地理区域表' PARTITIONED BY (dt string) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.avro.AvroSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat' location '/data/dw/ods/one_make/full_imp/ciss4.ciss_base_areas' TBLPROPERTIES ('avro.schema.url'='/data/dw/ods/one_make/avsc/CISS4_CISS_BASE_AREAS.avsc');create external table 数据库名称.表名 comment '表的注释' partitioned by ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.avro.AvroSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat' location '这张表在HDFS上的路径' TBLPROPERTIES ('这张表的Schema文件在HDFS上的路径')
-
-
-
小结
- 掌握Hive中Avro建表方式及语法
知识点06:ODS层构建:需求分析
-
目标:掌握ODS层构建的实现需求
-
路径
- step1:目标
- step2:问题
- step3:需求
- step4:分析
-
实施
-
目标:将已经采集同步成功的101张表的数据加载到Hive的ODS层数据表中
-
问题
-
难点1:表太多,如何构建每张表?
-
101张表的数据已经存储在HDFS上
-
建表
-
方法1:手动开发每一张表建表语句,手动运行
-
方法2:通过程序自动化建表
-
拼接建表的SQL语句
create external table 数据库名称.表名 comment '表的注释' partitioned by ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.avro.AvroSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat' location '这张表在HDFS上的路径' TBLPROPERTIES ('这张表的Schema文件在HDFS上的路径')- 表名、表的注释、表在HDFS上的路径、Schema文件在HDFS上的路径
-
将SQL语句提交给Hive或者Spark来执行
-
-
-
申明分区
alter table 表名 add partition if not exists partition(key=value)
-
-
难点2:如果使用自动建表,如何获取每张表的字段信息?
-
Schema文件:每个Avro格式的数据表都对应一个Schema文件
-
统一存储在HDFS上
-
-
-
需求:加载Sqoop生成的Avro的Schema文件,实现自动化建表
-
分析
-
step1:代码中构建一个Hive/SparkSQL的连接
-
step2:创建ODS层数据库
create database if not exists one_make_ods; -
step3:创建ODS层全量表:44张表
create external table one_make_ods_test.ciss_base_areas comment '行政地理区域表' PARTITIONED BY (dt string) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.avro.AvroSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat' location '/data/dw/ods/one_make/full_imp/ciss4.ciss_base_areas' TBLPROPERTIES ('avro.schema.url'='hdfs://bigdata.itcast.cn:9000/data/dw/ods/one_make/avsc/CISS4_CISS_BASE_AREAS.avsc');-
读取全量表表名
- 动态获取表名:循环读取文件
-
获取表的信息:表的注释
- Oracle:表的信息
- 从Oracle中获取表的注释
-
获取表的文件:HDFS上AVRO文件的地址
/data/dw/ods/one_make/full_imp -
获取表的Schema:HDFS上的Avro文件的Schema文件地址
/data/dw/ods/one_make/avsc -
拼接建表字符串
-
方式一:直接相加:简单
str1 = "I " str2 = "like China" str3 = str1 + str2 -
方式二:通过列表拼接:复杂
-
-
执行建表SQL语句
-
-
step4:创建ODS层增量表:57张表
-
读取增量表表名
- 动态获取表名:循环读取文件
-
获取表的信息:表的注释
- Oracle:表的信息
- 从Oracle中获取表的注释
-
获取表的文件:HDFS上AVRO文件的地址
/data/dw/ods/one_make/incr_imp -
获取表的Schema:HDFS上的Avro文件的Schema文件地址
/data/dw/ods/one_make/avsc -
拼接建表字符串
-
执行建表SQL语句
-
-
-
-
小结
- 掌握ODS层构建的实现需求
知识点07:ODS层构建:创建项目环境
-
目标:实现Pycharm中工程结构的构建
-
实施
- 安装Python3.7环境

- 项目使用的Python3.7的环境代码,所以需要在Windows中安装Python3.7,与原先的Python高版本不冲突,正常安装即可
- 创建Python工程

-
安装PyHive、Oracle库
-
step1:在Windows的用户家目录下创建pip.ini文件
-
例如:C:\\Users\\Frank\\pip\\pip.ini
-
内容:指定pip安装从阿里云下载
[global] index-url=http://mirrors.aliyun.com/pypi/simple/ [install] trusted-host=mirrors.aliyun.com
-
-
step2:将文件添加到Windows的Path环境变量中
-

- step3:进入项目环境目录
- 例如我的项目路径是:**D:\\PythonProject\\OneMake_Spark\\venv\\Scripts**

- 将提供的**sasl-0.2.1-cp37-cp37m-win_amd64.whl**文件放入Scripts目录下

- 在CMD中执行以下命令,切换到Scripts目录下
```shell
#切换到D盘
D:
#切换到项目环境的Scripts目录下
cd D:\\PythonProject\\OneMake_Spark\\venv\\Scripts
```

- step4:CMD中依次执行以下安装命令
```python
# 安装sasl包 -> 使用pycharm安装,会存在下载失败情况,因此提前下载好,对应python3.7版本
pip install sasl-0.2.1-cp37-cp37m-win_amd64.whl
# 安装thrift包
pip install thrift
# 安装thrift sasl包
pip install thrift-sasl
# 安装python操作oracle包
pip install cx-Oracle
# 安装python操作hive包,也可以操作sparksql
pip install pyhive
```

- step5:验证安装结果
<img src="Day1009_ODS层及DWD层构建.assets/image-20210930152732079.png" alt="image-20210930152732079" style="zoom:80%;" />
- 温馨提示:其实工作中你也可以通过Pycharm直接安装
-
小结
- 实现Pycharm中工程结构的构建
知识点08:ODS层构建:代码导入
-
目标:实现Python项目代码的导入及配置
-
实施
- Oracle本地驱动目录:将提供的instantclient_12_2目录放入D盘的根目录下
- PyHive本地连接配置:将提供的CMU目录放入C盘的根目录下
-
auto_create_hive_table包
- 创建路径包

```
auto_create_hive_table.cn.itcast.datatohive
```

- 在datatohive的init文件中放入如下代码
```python
from auto_create_hive_table.cn.itcast.datatohive import LoadData2DWD
from auto_create_hive_table.cn.itcast.datatohive.CHiveTableFromOracleTable import CHiveTableFromOracleTable
from auto_create_hive_table.cn.itcast.datatohive.CreateHiveTablePartition import CreateHiveTablePartition
```
- 其他包的init都放入如下内容
```python
#!/usr/bin/env python
# @desc :
__coding__ = "utf-8"
__author__ = "itcast"
```
- **将对应的代码文件放入对应的包或者目录中**
- step1:从提供的代码中复制config、log、resource这三个目录直接粘贴到**auto_create_hive_table**包下

- step2:从提供的代码中复制entity、utils、EntranceApp.py这三个直接粘贴到**itcast**包下

- step3:从提供的代码中复制fileformat等文件直接粘贴到**datatohive**包下

- DW归档目录:将提供的代码中的dw目录直接粘贴到项目中

-
小结
- 实现Python项目代码的导入及配置
知识点09:ODS层构建:代码结构及修改
-
目标:了解整个自动化代码的项目结构及实现配置修改
-
路径
- step1:工程代码结构
- step2:代码模块功能
- step3:代码配置修改
-
实施
- 工程代码结构

-
代码模块功能
-
auto_create_hive_table:用于实现ODS层与DWD层的建库建表的代码-
cn.itcast-
datatohive- CHiveTableFromOracleTable.py:用于创建Hive数据库、以及获取Oracle表的信息创建Hive表等
- CreateMetaCommon.py:定义了建表时固定的一些字符串数据,数据库名称、分层名称、文件类型属性等
- CreateHiveTablePartition.py:用于手动申明ODS层表的分区元数据
- LoadData2DWD.py:用于实现将ODS层的数据insert到DWD层表中
fileformat- AvroTableProperties.py:Avro文件格式对象,用于封装Avro建表时的字符串
- OrcTableProperties.py:Orc文件格式对象,用于封装Orc建表时的字符串
- OrcSnappyTableProperties.py:Orc文件格式加Snappy压缩的对象
- TableProperties.py:用于获取表的属性的类
-
-
entity-
TableMeta.py:Oracle表的信息对象:用于将表的名称、列的信息、表的注释进行封装
- ColumnMeta.py:Oracle列的信息对象:用于将列的名称、类型、注释进行封装
-
utils- OracleHiveUtil.py:用于获取Oracle连接、Hive连接
-
FileUtil.py:用于读写文件,获取所有Oracle表的名称
- TableNameUtil.py:用于将全量表和增量表的名称放入不同的列表中
-
ConfigLoader.py:用于加载配置文件,获取配置文件信息
- OracleMetaUtil.py:用于获取Oracle中表的信息:表名、字段名、类型、注释等
-
EntranceApp.py:程序运行入口,核心调度运行的程序
# todo:1-获取Oracle、Hive连接,获取所有表名 # todo:2-创建ODS层数据库 # todo:3-创建ODS层数据表 # todo:4-手动申明ODS层分区数据
todo:5-创建DWD层数据库以及数据表
todo:6-加载ODS层数据到DWD层
todo:7-关闭连接,释放资源
-
-
resource- config.txt:Oracle、Hive、SparkSQL的地址、端口、用户名、密码配置文件
-
-
config-
common.py:用于获取日志的类
- settings.py:用于配置日志记录方式的类
-
log- itcast.log:日志文件
-
-
dw:用于存储每一层构建的核心配置文件等- 重点关注:dw.ods.meta_data.tablenames.txt:存储了整个ODS层的表的名称
-
-
代码配置修改
- 修改1:auto_create_hive_table.cn.itcast.EntranceApp.py
# 51行:修改为你实际的项目路径对应的表名文件 tableList = FileUtil.readFileContent("D:\\\\PythonProject\\\\OneMake_Spark\\\\dw\\\\ods\\\\meta_data\\\\tablenames.txt")-
修改2:auto_create_hive_table.cn.itcast.utils.ConfigLoader
# 10行:修改为实际的连接属性配置文件的地址 config.read('D:\\\\PythonProject\\\\OneMake_Spark\\\\auto_create_hive_table\\\\resources\\\\config.txt')
- 小结
- 了解整个自动化代码的项目结构及实现配置修改
知识点10:ODS层构建:连接代码及测试
-
目标:阅读连接代码及实现连接代码测试
-
路径
- step1:连接代码讲解
- step2:连接代码测试
-
实施
-
为什么要获取连接?
- Python连接Oracle:获取表的元数据
- 表的信息:TableMeta
- 表名
- 表的注释
- list:[列的信息]
- 列的信息:ColumnMeta
- 列名
- 列的注释
- 列的类型
- 类型长度
- 类型精度
-
Python连接HiveServer或者Spark的ThriftServer:提交SQL语句
-
连接代码讲解
-
step1:怎么获取连接?
-
Oracle:安装Python操作Oracle库包:cx_Oracle
cx_Oracle.connect(ORACLE_USER, ORACLE_PASSWORD, dsn) -
Hive/SparkSQL:安装Python操作Hive库包:PyHive
hive.Connection(host=SPARK_HIVE_HOST, port=SPARK_HIVE_PORT, username=SPARK_HIVE_UNAME, auth='CUSTOM', password=SPARK_HIVE_PASSWORD)
-
-
step2:连接时需要哪些参数?
- Oracle:主机名、端口、用户名、密码、SID
- Hive:主机名、端口、用户名、密码
-
step3:如果有100个代码都需要构建Hive连接,怎么解决呢?
- 将所有连接参数写入一个配置文件:resource/config.txt
- 通过配置文件的工具类获取配置:ConfigLoader
-
step4:在ODS层建101张表,表名怎么动态获取呢?
- 读取表名文件:将每张表的名称都存储在一个列表中
-
step5:ODS层的表分为全量表与增量表,怎么区分呢?
- 通过对@符号的分割,将全量表和增量表的表名存储在不同的列表中
-
-
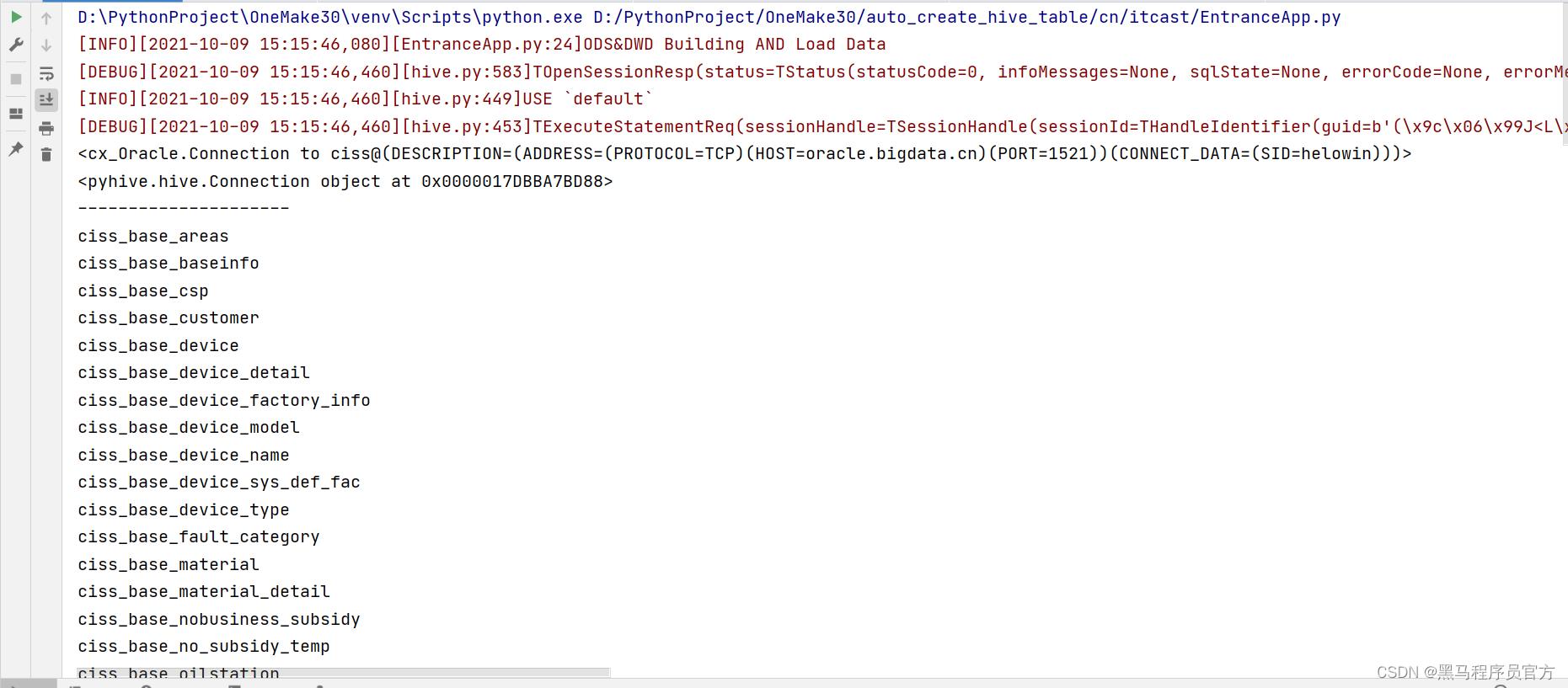
连接代码测试
- 启动虚拟运行环境
-

- 运行测试代码
- 注释掉第2 ~ 第6阶段的内容
- 取消测试代码的注释
- 执行代码观察结果
-
小结
- 阅读连接代码及实现连接代码测试
知识点11:ODS层构建:建库代码及测试
-
目标:阅读ODS建库代码及实现测试
-
路径
- step1:代码讲解
- step2:代码测试
-
实施
-
代码讲解
-
step1:ODS层的数据库名称叫什么?
one_make_ods -
step2:如何使用PyHive创建数据库?
- 第一步:先获取连接
- 第二步:拼接SQL语句,从连接对象中获取一个游标
- 第三步:使用游标执行SQL语句
- 第四步:释放资源
-
-
代码测试
- 注释掉第3 ~ 第6阶段的内容
- 运行代码,查看结果
-

-
小结
- 阅读ODS建库代码及实现测试
知识点12:ODS层构建:建表代码及测试
-
目标:阅读ODS建表代码及实现测试
-
路径
- step1:代码讲解
- step2:代码测试
-
实施
-
代码讲解
-
step1:表名怎么获取?
tableNameList【full_list,incr_list】 full_list:全量表名的列表 incr_list:增量表名的列表 -
step2:建表的语句是什么,哪些是动态变化的?
create external table 数据库名称.表名 comment '表的注释' partitioned by ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.avro.AvroSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat' location '这张表在HDFS上的路径' TBLPROPERTIES ('这张表的Schema文件在HDFS上的路径')-
表名
-
表的注释
-
表的HDFS地址
-
Schema文件的HDFS地址
-
-
step3:怎么获取表的注释?
-
从Oracle中获取:从系统表中获取某张表的信息和列的信息
select columnName, dataType, dataScale, dataPercision, columnComment, tableComment from ( select column_name columnName, data_type dataType, DATA_SCALE dataScale, DATA_PRECISION dataPercision, TABLE_NAME from all_tab_cols where 'CISS_CSP_WORKORDER' = table_name) t1 left join ( select comments tableComment,TABLE_NAME from all_tab_comments WHERE 'CISS_CSP_WORKORDER' = TABLE_NAME) t2 on t1.TABLE_NAME = t2.TABLE_NAME left join ( select comments columnComment, COLUMN_NAME from all_col_comments WHERE TABLE_NAME='CISS_CSP_WORKORDER') t3 on t1.columnName = t3.COLUMN_NAME;
-
-
-

- step4:全量表与增量表有什么区别?
- 区别1:表名不一样
- full_table_list
- incr_table_list
- 区别2:路径不一样
- `/data /dw /ods /one_make /full /Oracle库名.表名`
- `/data /dw /ods /one_make /incr /Oracle库名.表名`
- step5:如何实现自动化建表?
- 自动化创建全量表
- 获取全量表名
- 调用建表方法:数据库名称、表名、全量标记
- 通过Oracle工具类获取表的信息【表的名称、表的注释、字段信息等】
- 拼接建表语句
- 执行SQL语句
- 自动化创建增量表
- 获取增量表名
- 调用建表方法:数据库名称、表名、增量标记
- 通过Oracle工具类获取表的信息【表的名称、表的注释、字段信息等】
- 拼接建表语句
- 执行SQL语句
-
代码测试
- 注释掉第4~ 第6阶段的内容
- 运行代码,查看结果

-
小结
- 阅读ODS建表代码及实现测试
知识点13:ODS层构建:申明分区代码及测试
-
目标:阅读ODS申明分区的代码及实现测试
-
路径
- step1:代码讲解
- step2:代码测试
-
实施
-
代码讲解
-
step1:为什么要申明分区?
-
表的分区数据由Sqoop采集到HDFS生成AVRO文件
/data/dw/ods/one_make/full_imp/ciss4.ciss_base_areas/20210101/part-m-00000.avro -
HiveSQL基于表的目录实现了分区表的创建
create external table if not exists one_make_ods.ciss_base_areas partitioned by (dt string) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.avro.AvroSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat' tblproperties ('avro.schema.url'='hdfs:///data/dw/ods/one_make/avsc/CISS4_CISS_BASE_AREAS.avsc') location '/data/dw/ods/one_make/full_imp/ciss4.ciss_base_areas' -
但是Hive中没有对应分区的元数据,无法查询到数据
-
-
step2:怎么申明分区?
-
Alter Table
alter table 表名 add if not exists partition (dt='值') location 'HDFS上的分区路径' -
例如
alter table one_make_ods.ciss_base_areas add if not exists partition (dt='20210101') location '/data/dw/ods/one_make/full_imp/ciss4.ciss_base_areas/20210101'
-
-
step3:如何自动化实现每个表的分区的申明?
- 获取分区工具类实例
- 调用申明分区的方法
- 对所有全量表调用申明分区的方法:数据库名称、表名、全量标记、分区值
- 对所有增量表调用申明分区的方法:数据库名称、表名、增量标记、分区值
- 拼接SQL
- 执行SQL
-
-
代码测试
- 注释掉第5 ~ 第6阶段的内容
-
运行代码,查看结果
-
-
小结
- 阅读ODS申明分区的代码及实现测试
知识点14:ODS层与DWD层区别
-
目标:理解ODS层与DWD层的区别
-
路径
- step1:内容区别
- step2:设计区别
- step3:实现区别
-
实施
-
内容区别
- ODS:原始数据
- DWD:对ODS层ETL以后的数据
- 本次数据来源于Oracle数据库,没有具体的ETL的需求,可以直接将ODS层的数据写入DWD层
-
设计区别
- ODS层:Avro格式分区数据表
- DWD层:Orc格式分区数据表
-
实现区别
-
ODS层建表:基于avsc文件指定Schema建表
create external table if not exists one_make_ods.ciss_base_areas partitioned by (dt string) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.avro.AvroSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat' tblproperties ('avro.schema.url'='hdfs:///data/dw/ods/one_make/avsc/CISS4_CISS_BASE_AREAS.avsc') location '/data/dw/ods/one_make/full_imp/ciss4.ciss_base_areas' -
DWD层建表:自己指定每个字段的Schema建表
create external table if not exists one_make_dwd.ciss_base_areas( ID string, AREANAME string, PARENTID string, SHORTNAME string, LNG string, LAT string, RANK bigint, POSITION string, SORT bigint ) partitioned by (dt string) stored as orc location '/data/dw/dwd/one_make/ciss_base_areas';
-
-
-
小结
- 理解ODS层与DWD层的区别
知识点15:DWD层构建:需求分析
-
目标:掌握DWD层的构建需求
-
路径
- step1:整体需求
- step2:建库需求
- step3:建表需求
-
实施
-
整体需求:将ODS层的数据表直接加载到DWD层
insert into dwd partition (dt = '20210101') select * from ods where dt=20210101 -
建库需求:创建DWD层数据库one_make_dwd
-
建表需求:将ODS层中的每一张表创建一张对应的DWD层的表
-
问题1:建表的语法是什么?
create external table dwd.tbname( 字段名 字段类型 字段注释 ) partitioned by (dt string) location '/data/dw/dwd/one_make/ciss_base_areas'; -
问题2:表的名称名是什么,怎么获取?
- 不分全量和增量
- 所有表的名称都在列表中
-
问题3:表的注释怎么来?
- Oracle元数据中有
-
问题4:表的字段怎么获取?
- Oracle元数据中有
-
问题5:Oracle中的字段类型如果与Hive中的类型不一致怎么办?
- 将Oracle中Hive没有类型转换为Hive的类型
-
-
-
小结
- 掌握DWD层的构建需求
知识点16:DWD层构建:建库实现测试
-
目标:阅读DWD建库代码及实现测试
-
路径
- step1:代码讲解
- step2:代码测试
-
实施
-
代码讲解
-
step1:DWD层的数据库名称是什么,建库的语法是什么?
create database if not exists one_make_dwd; -
step2:如何实现DWD层数据库的构建?
cHiveTableFromOracleTable.executeCreateDbHQL(CreateMetaCommon.DWD_NAME)
-
-
代码测试
-
注释掉第5.2 ~ 第6阶段的内容
-
运行代码,查看结果

-
-
-
小结
- 阅读DWD建库代码及实现测试
知识点17:DWD层构建:建表实现测试
-
目标:阅读DWD建表代码及实现测试
-
路径
- step1:代码讲解
- step2:代码测试
-
实施
-
代码讲解
-
step1:如何获取所有表名?
allTableName = [i for j in tableNameList for i in j]- 列表推导式
-
step2:建表的语句是什么,哪些是动态变化的?
create external table if not exists one_make_dwd.ciss_base_areas( ID string comment '字段的注释', AREANAME string comment '字段的注释', PARENTID string comment '字段的注释', SHORTNAME string comment '字段的注释', LNG string comment '字段的注释', LAT string comment '字段的注释', RANK bigint comment '字段的注释', POSITION string comment '字段的注释', SORT bigint comment '字段的注释' ) comment '表的注释' partitioned by (dt string) stored as orc location '/data/dw/dwd/one_make/ciss_base_areas';- 动态变化的信息如下:
- 表名,表的注释
- 字段
- 路径
- 动态变化的信息如下:
-
step3:怎么获取字段信息?
-
step4:Oracle字段类型与Hive/SparkSQL字段类型不一致怎么办?
- timestamp => long
- number => bigint | dicimal
- other => String
-
step4:HDFS上的路径是什么?
/data/dw/dwd/one_make/tableName -
step5:如何实现自动化
- 遍历表名,对每张表调用自动化建表的方法:数据库名称、表的名称、None【不分全量或者增量】
- 从Oracle中获取字段名,并实现类型转换
- 添加表的注释、分区信息
- 添加表的存储格式
- 指定表的存储路径
- 执行SQL语句
-
-
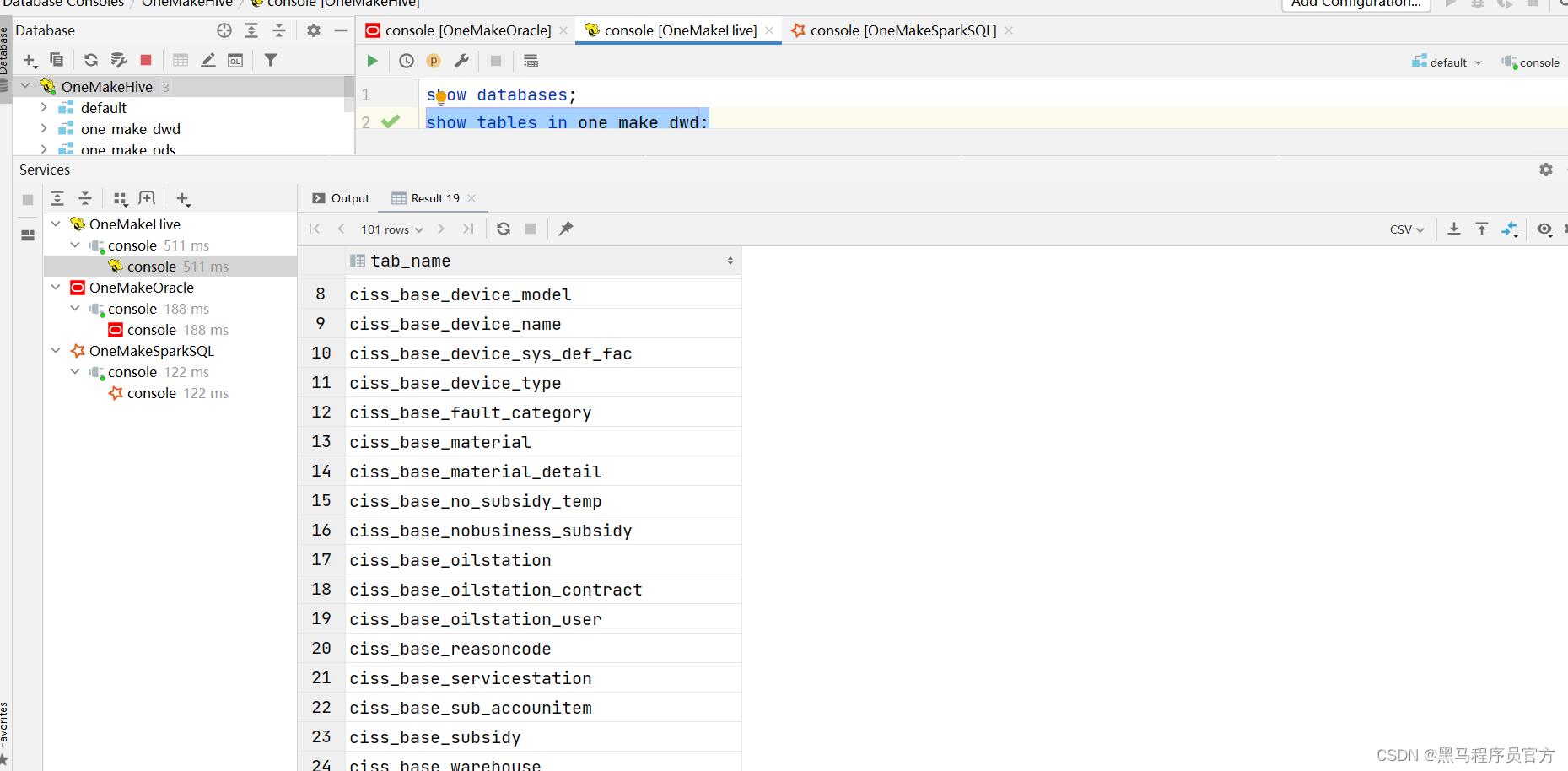
代码测试
-
注释掉 第6阶段的内容
-
运行代码,查看结果
-
-
-
小结
- 阅读DWD建表代码及实现测试
知识点18:DWD层构建:数据抽取分析
-
目标:实现DWD层的构建思路分析
-
路径
- step1
以上是关于Python工业项目实战03:ODS层及DWD层构建的主要内容,如果未能解决你的问题,请参考以下文章
- step1