spark day06 + day07(含错)
Posted 不想写bug第n天
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark day06 + day07(含错)相关的知识,希望对你有一定的参考价值。
目录
1.spark SQL 基本信息
-
1.什么是sparksql
- Spark SQL is·Apache Spark's module for working withstructured· data
sparksql主要处理结构化数据 - Spark SQL是Spark用来处理结构化数据的一个模块
它提供了一个编程抽象叫做DataFrame并且作为分布式SQL查询引擎的作用
- Spark SQL is·Apache Spark's module for working withstructured· data
-
2.strucrured data
- 半结构化数据
- csv、json、orc、parq
- 非结构化数据
- 半结构化数据
- 在spark中,spark SQL模块不仅仅是sql、dataframe
-
3.sparksql特征
- 1.sparksql dataframe、api 同sparkcore
- 2.Sparksql = sql + datafram api 处理【结构化数据】
- 3.Uniform data access【外部数据源】
- SparkSQL 能够处理多种不同的数据源
- 4.Hive integration【整合Hive】
- SparkSQL访问hive的元数据库·即可·sparksql查询hive里面的数据
- 注意
- 1.Sparksql不仅仅是sql
- hive on spark vs spark on hive
- hive on spark:hive查询引擎是mr
- spark on hive:sparksql 去hive查
-
4.概述
-
1.sparksql性能比spark rdd高
- 1..more information about the structure of.boththe data. [schema)
- 2.sparksgl架构有关
- sparksql底层跑的是Sparkcore rdd只是spark框架底层给我们做了优化
- sparkcoore:编程模型
- sparksql:rdd【数据集】 + schema[字段 字段类型] => table
-
2.Spark SQL including
-
3.Datasets and DataFrames
- Datasets
- 1.Dataset也是一个分布式数据集
- 2.比rdd多出的优势:
- 1.强类型。
- 2.算子 ds也可以使用算子
- 3.optimized executionengine,执行性能·高sparksgl架构·catelyst)
- 4.Spark1.6·之后诞生的
- 3.DatasetAPI: scalajava进行开发
- DataFrame
- 1.DataFrame也是一个dataset
A DataFrame is aDataset organizedintonamed·columns - 2.DataFrame:
structured data files, tables in·Hive, external databases, or existing ·RDDs - 3.DataFrame is represented by a Dataset of Rows
- DataFrame=Dataset[Row]
- Row=>·一行数据·仅仅包含·named·columns
- DataFrame => table
- 1.DataFrame也是一个dataset
- sparkcore => rdd数据集
- sparksql => df 数据集 【数据集 + 额外的信息[schema]】
rdd + scheam => table - Sparksql
- 编程模型
- DataFarm :schemaRDD变过来的
- DataSet :DataFrame变过来的
- 编程模型
- Datasets
-
2. 开发DF
-
1.idea开发sparksql
- 1.引入依赖
<!--spark-sql依赖--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.12</artifactId> <version>3.2.1</version> </dependency> - 2.引用代码
val spark: SparkSession = SparkSession.builder().appName("SparkSQL01").master("local[2]").getOrCreate() - 3.封装
- 1.引入依赖
-
2.交互式开发sparksql
- 1.进入spark
- 2.导入数据(数据原带)
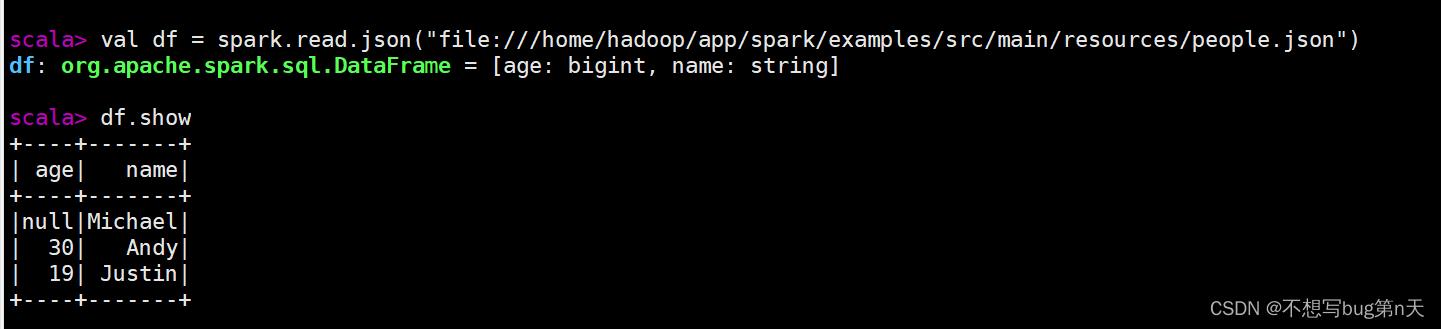
spark.read.json("file:///home/hadoop/app/spark/examples/src/main/resources/people.json") - 3.查看:df.show
3.SparkSQL进行数据分析
-
方式
- 1.sql方式 【好维护】(idea api+sql 或者 hive sql文件)
- 2.api方式 【不好维护】 (一般用户开发平台、工具)
-
1.api方式
- 1.加载df某个字段
- select(col: String, cols: String*):
- select("字段名字")
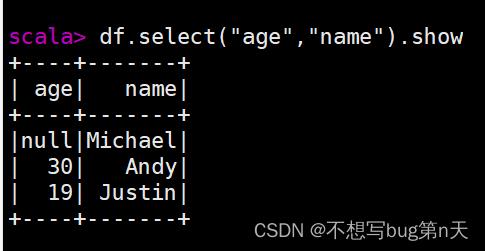
- df.select("age").show

- df.select("age","name").show
- df.select("age").show
- select($"字段名字") + 隐士转换 import spark.implicits._
- idea中
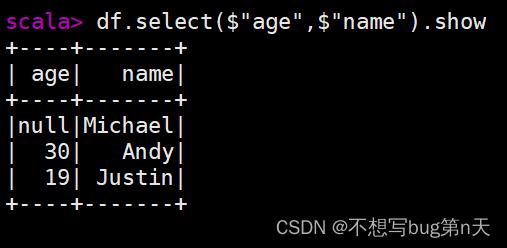
import spark.implicits._ //隐式转换 df.select($"name") - df.select("age").show
- df.select($"age",$"name").show
- idea中
- select("字段名字")
- select(cols: Column*):
- idea中
import org.apache.spark.sql.functions._ df.select(col("age")) - df.select(col("age")).show

- idea中
- select(col: String, cols: String*):
- 1.加载df某个字段
-
2.sql方式
- 1.创建test表:df.createOrReplaceTempView("test")
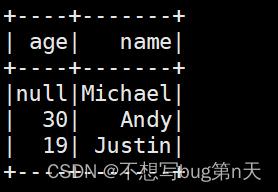
- 2.查询表格数据:spark.sql("select* from test").show
- 3.查询表格多少条数据:spark.sql("select count(1) as cont from test").show

-
案例
- 需求 :sparksql 去取json数据 做需求分析
- 1、table中数据条数
- 2.table中所有人薪资总和
- 数据
"name":"tom","salary":3000 "name":"Andy","salary":5200 "name": "Justion","salary":6600 "name": "Bertin","salary": 4300 "name": "leader","salary":60000 - 代码
object SparkSQL01 def main(args: Array[String]): Unit = val spark: SparkSession = SparkSession.builder().appName("SparkSQL01").master("local[2]").getOrCreate() val df: DataFrame = spark.read.json("file:///D:\\\\iccn\\\\software\\\\xxl\\\\untitled3\\\\untitled5\\\\Data\\\\emp.json") println("表格展示") df.show() println("表中数据条") //println(df.count) df.groupBy().count().show() df.groupBy().count().select("count").show() //api println("薪资总和") df.select("name","salary").groupBy().sum("salary").show df.groupBy().sum("salary").select("sum(salary)" ).show() //api spark.stop()
- 需求 :sparksql 去取json数据 做需求分析
4.创建dataframe
-
三种方式
- 1.existing RDD 【从已知RDD中构建】
- 2.from a Hive table
- 3. from Spark data sources.
1.existing RDD
-
1.反射方法
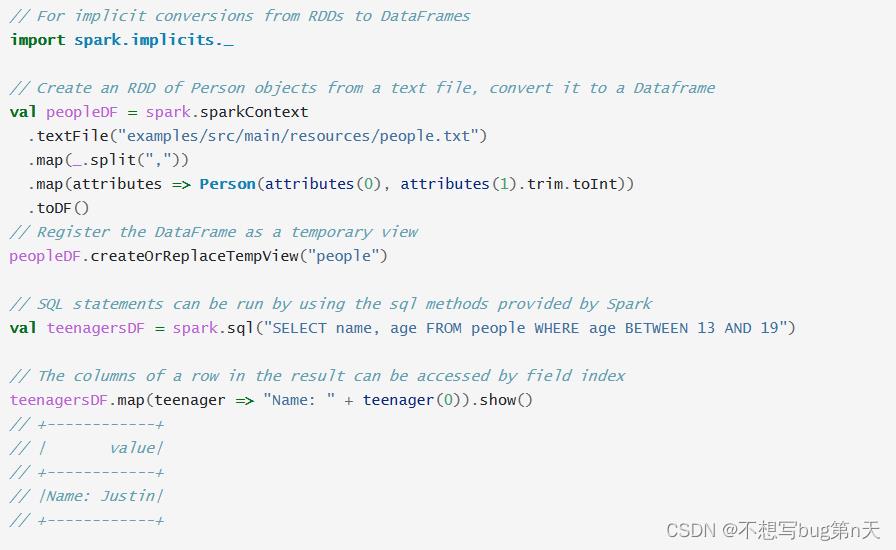
- Info代码
case class Info(uid:String,name:String,age:Int) def main(args: Array[String]): Unit = val spark: SparkSession = SparkSession.builder().appName("SparkSQL01").master("local[2]").getOrCreate() import spark.implicits._ val sc = spark.sparkContext val inputRDD: RDD[String] = sc.textFile("file:///D:\\\\iccn\\\\software\\\\xxl\\\\untitled3\\\\untitled5\\\\Data\\\\info.txt") val inputDF: DataFrame = inputRDD.map(line => val splits = line.split(",") val uid = splits(0) val name = splits(1) val age = splits(2).toInt Info(uid, name, age) ).toDF() inputDF.show(5,false) inputDF.printSchema() //查看数据类型 spark.stop() - col 代码
case class Info(uid:String,name:String,age:Int) def main(args: Array[String]): Unit = val spark: SparkSession = SparkSession.builder().appName("SparkSQL01").master("local[2]").getOrCreate() import spark.implicits._ val sc = spark.sparkContext val inputRDD: RDD[String] = sc.textFile("file:///D:\\\\iccn\\\\software\\\\xxl\\\\untitled3\\\\untitled5\\\\Data\\\\info.txt") val inputDF2: DataFrame = inputRDD.map(line => val splits = line.split(",") val uid = splits(0) val name = splits(1) val age = splits(2).toInt (uid, name, age) ).toDF("uid","name","age") inputDF2.show(5,false) inputDF2.printSchema() spark.stop()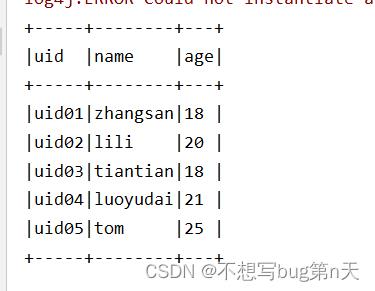
数据uid01,zhangsan,18
uid02,lili,20
uid03,tiantian,18
uid04,luoyudai,21
uid05,tom,25
- Info代码
-
2.编程方法
- 过程
- 1.RDD[Row]
(Create an RDD of Rows from the original RDD;) - 2.schema
(Create the schema represented by a StructType matching the structure of Rows in the RDD created in Step 1.) - 3.creatrDataFrame => df
(Apply the schema to the RDD of Rows via createDataFrame method provided by SparkSession.)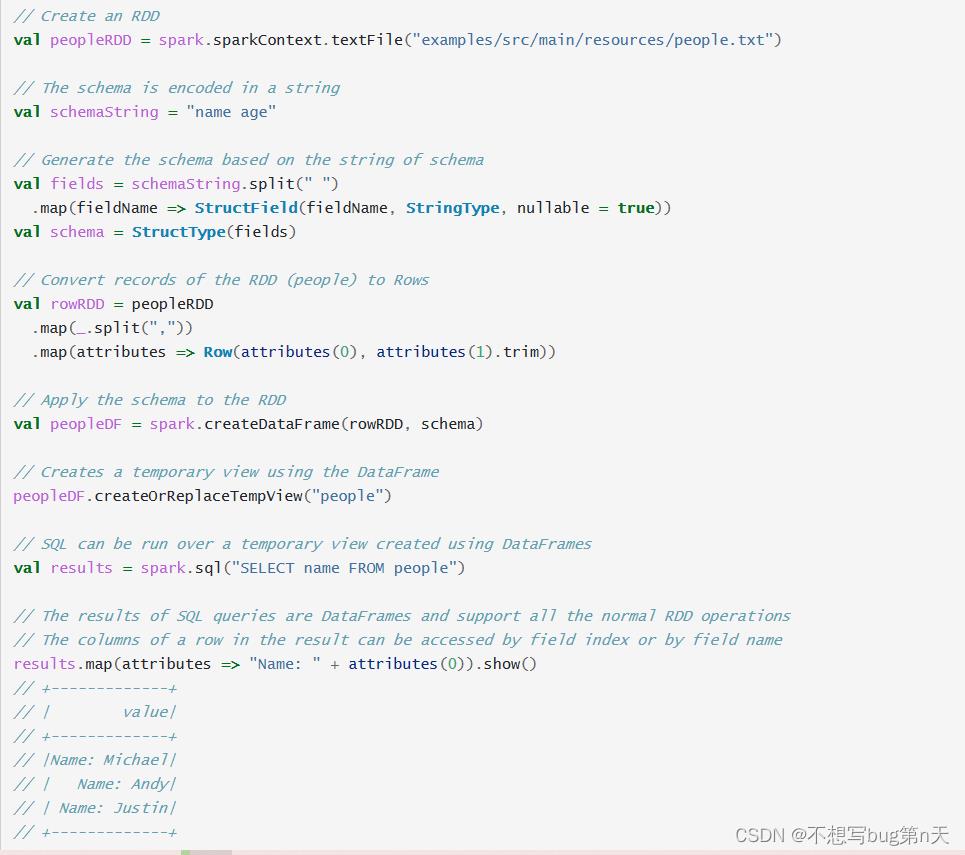
- 1.RDD[Row]
- 代码
def main(args: Array[String]): Unit = val spark: SparkSession = SparkSession.builder().appName("SparkSQL01").master("local[2]").getOrCreate() val sc = spark.sparkContext val inputRDD: RDD[String] = sc.textFile("file///D:\\\\iccn\\\\software\\\\xxl\\\\untitled3\\\\untitled5\\\\Data\\\\info.txt") //构建ROW val rowRDD: RDD[Row] = inputRDD.map(line => val splits = line.split(",") val uid = splits(0) val name = splits(1) val age = splits(2).toInt Row(uid, name, age) ) //构建schema val scheama = StructType(Array( StructField("uid",StringType), StructField("name",StringType), StructField("age",IntegerType), )) val inputDF: DataFrame = spark.createDataFrame(rowRDD, scheama) inputDF.show(10,false) inputDF.printSchema() spark.stop()
- 过程
- rdd、df、ds转变 【面试题】
- 把rdd转变成df、ds
- 转变df:toDF
- 转变ds:toDS
- 把df、ds转变成rdd
- .rdd
- 举例:val rdd: RDD[Row] = inputDF2.rdd
- df转变成ds
- df.as[数据类型] => ds
- 举例:val df: Dataset[Info] = inputDF2.as[Info]
- 把rdd转变成df、ds
2. data sources【外部数据源】
- 原理:Spark SQL 支持通过 DataFrame 接口对各种数据源进行操作。 可以使用关系转换对数据帧进行操作,也可以用于创建临时表。,将数据帧注册为临时视图允许您对其数据运行 SQL 查询。
- 重点
- 1.读数据 api
- text文件:spark.read.format("text").load(paths : _*)
例:val df: DataFrame = spark.read.text(str) 【返回的是DF类型】 - json文件:spark.read.format("json").load(paths : _*)
例:val ds: Dataset[String] = spark.read.textFile(path)
- text文件:spark.read.format("text").load(paths : _*)
- 2.写数据 api
- text文件:df.write.mode(SaveMode.Overwrite)format("text").save(path)
例:data.select("uid").write.text("file:///D:\\\\software\\\\untitled3\\\\data\\out") - json文件:df.write.mode(SaveMode.Append)format("json").save(path)
- 数据写出方式mode:
- 1.覆盖 overwrite
- 2.追加 append
- text文件:df.write.mode(SaveMode.Overwrite)format("text").save(path)
- 1.读数据 api
-
1.text文件的读写
- 官网:spark.apache.org/docs/latest/sql-data-sources-text.html
- 1.读数据
def text(spark: SparkSession, path: String) = val df: DataFrame = spark.read.text(path) /** * ds格式 * val ds: Dataset[String] = spark.read.textFile(path) */ df.show(2,false) df.printSchema() def main(args: Array[String]): Unit = val spark: SparkSession = SparkSession.builder().appName("SparkSQL01").master("local[2]").getOrCreate() import spark.implicits._ //text df text(spark,"file:///D:\\\\iccn\\\\software\\\\xxl\\\\untitled3\\\\untitled5\\\\Data\\\\info.txt") spark.stop()
本身是不带有schema信息 【字段 value string 】
- 2.解析数据
- text文件加载进来之后 需要解析数据
- 代码
def text(spark: SparkSession, str: String) = import spark.implicits._ //隐式转换 val df: DataFrame = spark.read.text(str) //数据解析 val data: DataFrame = df.map(row => val line = row.getString(0) val splits = line.split(",") val uid = splits(0) val name = splits(1) val age = splits(2) (uid, name, age) ).toDF("uid", "name", "age") data.show(false) data.printSchema() //写出数据 data.select("uid").write.text("file:///D:\\\\iccn\\\\software\\\\xxl\\\\untitled3\\\\ untitled5\\\\Data\\\\out\\\\out_text")对比:


- 3.写出数据
- 局限:仅仅支持一列输出 不支持多列输出
- 代码
data.select("uid").write.text("file:///D:\\\\iccn\\\\software\\\\xxl\\\\untitled3\\\\untitled5\\\\Data\\\\out\\\\out_text")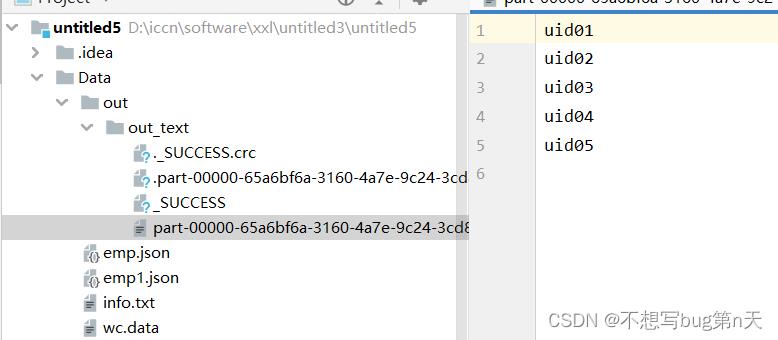
- 使用sparksql 支持text多列输出
- 1.自定义外部数据源 【有难度】
- unit中 FileUtils类报错【视频2】
- 2.df 转变成rdd方式进行输出 【常用手段】
- 1.自定义外部数据源 【有难度】
-
2.json的读写
-
1.普通json【规范】
- 数据
"city_id" : 1, "city_name" : "BEIJING" ,"area" : "NC" "city_id" : 2, "city_name" : "SHANGHAI" ,"area" : "EC" "city_id" : 3, "city_name" : "NANJING" ,"area" : "EC" "city_id" : 4, "city_name" : "GUANGZHOU" ,"area" : "SC" "city_id" : 5, "city_name" : "SANYA" ,"area" : "SC" "city_id" : 6, "city_name" : "WUHAN" ,"area" : "CC" "city_id" : 7, "city_name" : "CHANGSHA" ,"area" : "CC" "city_id" : 8, "city_name" : "XIAN" ,"area" : "NW" "city_id" : 9, "city_name" : "CHENGDU" ,"area" : "SW" "city_id" : 1, "city_name" : "HAERBIN" ,"area" : "NE" - 1.读数据
def json(spark: SparkSession, path: String) = val input: DataFrame = spark.read.format("json").load(path) input.show() input.printSchema() def main(args: Array[String]): Unit = val spark: SparkSession = SparkSession.builder().appName("SparkSQL01").master("local[2]").getOrCreate() import spark.implicits._ json(spark,"file:///D:\\\\iccn\\\\software\\\\xxl\\\\untitled3\\\\untitled5\\\\Data\\\\city_info.json") spark.stop()
json格式无需解析数据 - 2.写数据
- 写出数据
def json(spark: SparkSession, path: String) = val input: DataFrame = spark.read.format("json").load(path) input.show() input.printSchema() input.createOrReplaceTempView("city_info") spark.sql( """ |select count(1) as cnt from city_info |""".stripMargin).write.mode(SaveMode.Overwrite).format("json").save("hdfs://bigdata13:9000/out")
-
报错原因:权限原因
|权限问题解决方法 |修改hdfs上的权限 |把代码部署到linux上 |更改windows的机器名称变成hadoop |正常drwxr-xr-x |更改之后777 |hdfs路径写法:hdfs://机器名:端口/文件路径 |端口默认是9000 |文件路径是hdfs上的 |机器名是主节点的 |"""
- 解决方法:[hadoop@bigdata13 ~]$ hdfs dfs -chmod 777 /out
-
- 修改后hdfs中

- 写出数据
- 数据
-
2.嵌套json【规范】
- 数据
"store":"fruit":["weight":6,"type":"apple","weight":9,"type":"pear"],"bicycle":"price":19.95,"color":"red","email":"amy@only_for_json_udf_test.net","owner":"amy" - 直接按照解决普通json方法得出结果

- 解析两种方式
-
1.api
- 1.struct:打点
//struct jsonData = jsonData.withColumn("color",col("store.bicycle.color")) jsonData = jsonData.withColumn("price",col("store.bicycle.price")) - 2.array:expolde + struct:打点
//array jsonData = jsonData.withColumn("fruit",explode(col("store.fruit"))) jsonData = jsonData.withColumn("type",col("fruit.type")) jsonData = jsonData.withColumn("weight",col("fruit.weight"))- expolde将fruit分解为struct形式
- 整合
def json02(spark: SparkSession, path: String) = var jsonData: DataFrame = spark.read.format("json").load(path) jsonData.show() jsonData.printSchema() import org.apache.spark.sql.functions._ //struct jsonData = jsonData.withColumn("color",col("store.bicycle.color")) jsonData = jsonData.withColumn("price",col("store.bicycle.price")) //array jsonData = jsonData.withColumn("fruit",explode(col("store.fruit"))) jsonData = jsonData.withColumn("type",col("fruit.type")) jsonData = jsonData.withColumn("weight",col("fruit.weight")) //drop方法去除字段 jsonData = jsonData.drop("store","fruit") jsonData.show() jsonData.printSchema()
- 1.struct:打点
-
2.sql
- 1.struct:打点
- 2. array:expolde + struct:打点
-
lateral view explode(store.fruit) as fruit
-
- 总和
def json03(spark: SparkSession, path: String) = val data: DataFrame = spark.read.format("json").load(path) data.show() data.printSchema() data.createOrReplaceTempView("store_json") val etl = spark.sql( """ |select |email, |owner, |store.bicycle.color as color, |store.bicycle.price as price, |fruit.type as type, |fruit.weight as weight |from store_json |lateral view explode(store.fruit) as fruit |""".stripMargin) etl.show() etl.printSchema()
- 数据
- 3.不规范json (目前不用掌握)
- 通过udf函数解决
-
-
3.CSV文件
- CSV格式
- 1.可以使用excel打开
- 2.默认字段之间的分割符 , [可以进行更改]
- 读数据( 默认分割符是",")
def csv(spark: SparkSession, path: String) = val data = spark.read.format("csv").load(path) data.show() data.printSchema()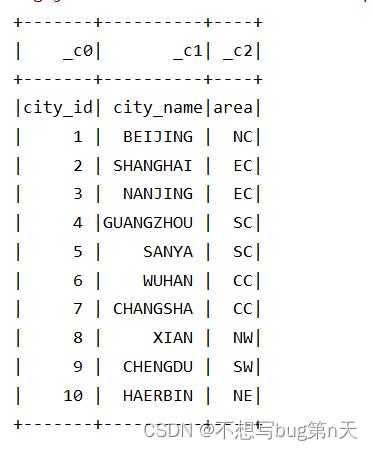

-
其他option(例 ; )
val data = spark.read.option("sep",";").option("header","true").format("csv").load(path)Property Name Default Scope 注释 sep , read/write encoding UTF-8 read/write 指定读取的csv文件的字符集utf-8 quote " read/write quoteAll false read escape \\ read/write header false read/write 第一行作为table中的字段 inferSchema false read 类型推断功能 
- 查询语句
data.createOrReplaceTempView("csv") spark.sql( """ |select |city_id,city_name,area |from csv |where city_name = "BEIJING" |""".stripMargin).show()
//where lower(city_name) = "beijing" 【用小写查询数据】
-
写数据
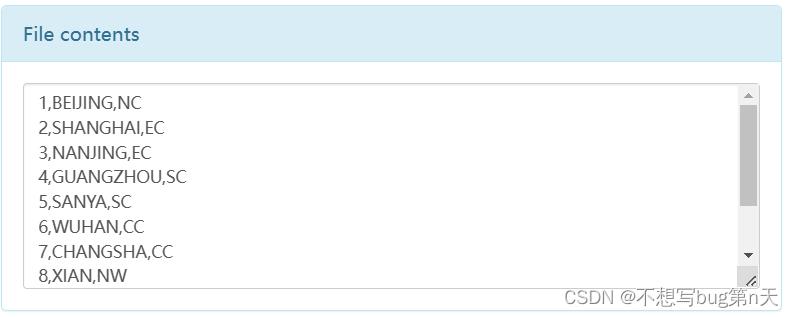
data.write.mode(SaveMode.Overwrite).format("csv").save("http://bigdata13:9870/out/csv")hdfs上
-
指定压缩格式 .option("compression","gzip")
data.write.option("compression","gzip").mode(SaveMode.Overwrite).format("csv").save("http://bigdata13:9870/out/csv")
解压:hdfs dfs -text /out/part-00000-e069775f-18e6-4aa1-bdaf-d712bd92f0fe-c000.csv.gz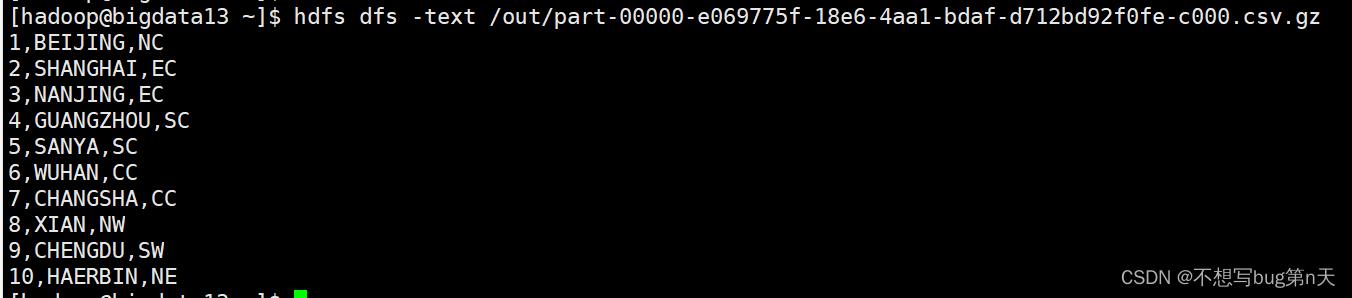
-
- CSV格式
-
4.jdbc
- 直接在数据库中读取数据
- 1.添加mysql驱动--pom依赖
<!--mysql驱动--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.49</version> </dependency> - 2.读数据

def jdbc(spark: SparkSession) = val data = spark.read.format("jdbc") .option("url", "jdbc:mysql://bigdata13/bigdata") .option("dbtable", "test") .option("user", "root") .option("password", "123456") .load() data.show() data.printSchema()

- 3.查询筛选
- 1.建表方式【一般不用与生产】
data.createOrReplaceTempView("test") spark.sql( """ |select * |from test |where age = 20 |""".stripMargin).show()缺点:直接表table 数据全部加载过来 , 再进行筛选 性能不高
- 2.谓词下压【首选】
先筛选再呈现
- 1.建表方式【一般不用与生产】
-
4.写数据
-
1.创建表
在数据库中建表CREATE TABLE `test_b` ( `id` int(3), `name` varchar(10) )
-
2.写出代码

data.createOrReplaceTempView("test_a") val rpt = spark.sql( """ |select |id,name |from test_a |""".stripMargin) //写数据 val url="jdbc:mysql://bigdata13:3306/bigdata" val table="test_b" val properties = new Properties() //封装用户名和密码 properties.setProperty("user", "root") properties.setProperty("password", "123456") rpt.write.mode(SaveMode.Append).jdbc(url,table,properties)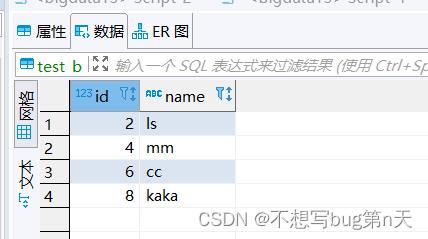
-
-
4.代码总结
def jdbc(spark: SparkSession) = //筛选内容 val inputsql= """ |select |* |from test |where age = 20 """.stripMargin //读数据 val data: DataFrame = spark.read.format("jdbc") .option("url", "jdbc:mysql://bigdata13:3306/bigdata") .option("dbtable", s"($inputsql) as tmp") .option("user", "root") .option("password", "123456") .load() data.show() data.printSchema() data.createOrReplaceTempView("test_a") val rpt = spark.sql( """ |select |id,name |from test_a |""".stripMargin) //写数据 val url="jdbc:mysql://bigdata13:3306/bigdata" val table="test_b" val properties = new Properties() //封装用户名和密码 properties.setProperty("user", "root") properties.setProperty("password", "123456") rpt.write.mode(SaveMode.Append).jdbc(url,table,properties)
- day06作业
- 数据
- emp (empno,ename,job,mgr,hiredate,sal,comm,deptno)
7369, SMITH , CLERK , 7902, 1980-12-17 , 800, null, 20 7499, ALLEN , SALESMAN , 7698, 1981-02-20 , 1600, 300, 30 7521, WARD , SALESMAN , 7698, 1981-02-22 , 1250, 500, 30 7566, JONES , MANAGER , 7839, 1981-04-02 , 2975, null, 20 7654, MARTIN , SALESMAN , 7698, 1981-09-28 , 1250, 1400, 30 7698, BLAKE , MANAGER , 7839, 1981-05-01 , 2850, null, 30 7782, CLARK , MANAGER , 7839, 1981-06-09 , 2450, null, 10 7788, SCOTT , ANALYST , 7566, 1982-12-09 , 3000, null, 20 7839, KING , PRESIDENT , null, 1981-11-17 , 5000, null, 10 7844, TURNER , SALESMAN , 7698, 1981-09-08 , 1500, 0, 30 7876, ADAMS , CLERK , 7788, 1983-01-12 , 1100, null, 20 7900, JAMES , CLERK , 7698, 1981-12-03 , 950, null, 30 7902, FORD , ANALYST , 7566, 1981-12-03 , 3000, null, 20 7934, MILLER , CLERK , 7782, 1982-01-23 , 1300, null, 10 - dept (deptno,dname ,loc)
10, ACCOUNTING , NEW YORK 20, RESEARCH , DALLAS 30, SALES , CHICAGO 40, OPERATIONS , BOSTON
- emp (empno,ename,job,mgr,hiredate,sal,comm,deptno)
- 需求
-
1. 查询出部门编号为30的所有员工的编号和姓名
-
2.找出部门编号为10中所有经理,和部门编号为20中所有销售员的详细资料。
-
3.查询所有员工详细信息,用工资降序排序,如果工资相同使用入职日期升序排序
-
4.列出薪金大于1500的各种工作及从事此工作的员工人数。
-
- 数据
以上是关于spark day06 + day07(含错)的主要内容,如果未能解决你的问题,请参考以下文章
自学it18大数据笔记-第三阶段Spark-day07——会持续更新……
自学it18大数据笔记-第三阶段Spark-day06——会持续更新……